Criar modelos de machine learning no BigQuery ML
Este tutorial é uma introdução aos usuários ao BigQuery ML usando o console do Google Cloud.
Com o BigQuery ML, é possível criar e executar modelos de machine learning no BigQuery usando consultas SQL e código Python. O objetivo é democratizar o machine learning, de modo que os especialistas em SQL criem modelos usando as respectivas ferramentas e aumentem a velocidade de desenvolvimento ao eliminar a necessidade de movimentar os dados.
Neste tutorial, você usa o conjunto de dados de amostra do Google Analytics para BigQuery e cria um modelo que prevê se um visitante do site fará uma transação. Para informações sobre o esquema do conjunto de dados do Analytics, veja o esquema do BigQuery Export na Central de Ajuda do Google Analytics.
Objetivos
Neste tutorial, você usará:
- o BigQuery ML para criar um modelo de regressão binária usando a instrução
CREATE MODEL; - a função
ML.EVALUATEpara avaliar o modelo de ML; - a função
ML.PREDICTpara fazer previsões usando o modelo de ML.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud, entre eles:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery em um projeto preexistente, acesse
Ative a API BigQuery.
Criar seu conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo de ML:
No console do Google Cloud, acesse a página do BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
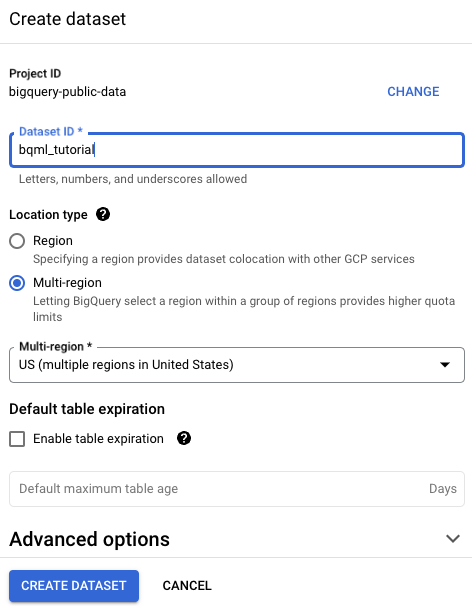
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Os conjuntos de dados públicos são armazenados na multirregião
US. Para simplificar, armazene seus conjuntos de dados no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
crie um modelo.
Em seguida, você cria um modelo de regressão logística usando o conjunto de dados de amostra do Google Analytics para o BigQuery.
SQL
Com a consulta GoogleSQL padrão a seguir você cria o modelo usado para prever se um visitante do site fará uma transação.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Além de criar o modelo, a execução de uma consulta que contém a instrução CREATE MODEL treina o modelo usando os dados recuperados pela instrução SELECT da consulta.
Detalhes da consulta
A cláusula CREATE MODEL é usada para criar e treinar o modelo chamado bqml_tutorial.sample_model.
A cláusula OPTIONS(model_type='logistic_reg') indica que você está criando um modelo de regressão logística.
Um modelo de regressão logística divide os dados de entrada em duas classes e determina a probabilidade de que eles estejam em cada uma dessas classes. Normalmente, aquilo que você está tentando detectar (por exemplo, se um e-mail pode ser classificado como spam) é representado por 1 e todo o resto é representado por 0. Se a saída do modelo de regressão logística for 0,9, há uma probabilidade de 90% da entrada ser aquilo que você quer detectar (o e-mail ser um spam, neste exemplo).
A instrução SELECT dessa consulta recupera as colunas abaixo, que são usadas pelo modelo para prever a probabilidade de um cliente concluir uma transação:
totals.transactions: o número total de transações de comércio eletrônico na sessão. Se o número de transações forNULL, o valor na colunalabelserá definido como0. Caso contrário, será definido como1. Esses valores representam os resultados possíveis. Criar um alias denominadolabelé uma alternativa à configuração da opçãoinput_label_cols=na instruçãoCREATE MODEL;device.operatingSystem: o sistema operacional do dispositivo do visitante;device.isMobile: indica se o dispositivo do visitante é um dispositivo móvel;geoNetwork.country: o país de origem das sessões com base no endereço IP;totals.pageviews: o número total de visualizações de página na sessão.
A cláusula FROM — bigquery-public-data.google_analytics_sample.ga_sessions_* — indica que você está consultando o conjunto de dados de amostra do Google Analytics.
Esse conjunto de dados está no projeto bigquery-public-data. Você está consultando um grupo de tabelas fragmentadas por data. Isso é representado pelo caractere curinga no nome da tabela: google_analytics_sample.ga_sessions_*.
A cláusula WHERE — _TABLE_SUFFIX BETWEEN '20160801' AND '20170630' — limita o número de tabelas verificadas pela consulta. O período verificado vai de 1º de agosto de 2016 até 30 de junho de 2017.
Execute a consulta CREATE MODEL
Para executar a consulta CREATE MODEL para criar e treinar seu modelo:
- No console do Google Cloud, clique no botão Escrever nova consulta. Se esse texto não estiver disponível para ser clicado, o Editor de consultas já estará aberto.

Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Clique em Executar.
A consulta leva alguns minutos para ser concluída. Depois que a primeira iteração for concluída, seu modelo (
sample_model) aparecerá no painel de navegação. Como a consulta usa uma instruçãoCREATE MODELpara criar um modelo, não é possível ver os resultados da consulta.Observe o modelo enquanto ele está sendo treinado, visualizando a guia Estatísticas do modelo. Assim que a primeira iteração for concluída, a guia será atualizada. As estatísticas continuam sendo atualizadas conforme cada iteração é concluída.
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Ver estatísticas de treinamento
Para ver os resultados do treinamento de modelo, use a função
ML.TRAINING_INFO
ou visualize as estatísticas no console do Google Cloud. Neste
tutorial, você usa o console do Google Cloud.
O machine learning pode ser definido como criar um modelo capaz de utilizar dados para fazer previsões. O modelo é basicamente uma função que recebe entradas e aplica cálculos a estas entradas para produzir um resultado: uma previsão.
Os algoritmos de aprendizado de máquina funcionam utilizando diversos exemplos em que a previsão já é conhecida (como o histórico de compras de usuários) e ajustando iterativamente vários pesos no modelo de modo que as previsões correspondam aos valores reais. Isso é feito ao minimizar as possibilidades de erro do modelo por meio de uma métrica denominada perda.
A expectativa é que a perda seja reduzida a cada iteração (idealmente até chegar a zero). Uma perda zero significa que o modelo é 100% exato.
Para ver as estatísticas de treinamento do modelo que foram geradas quando você executou a consulta CREATE MODEL:
No painel de navegação do Console do Cloud, na seção Recursos , expanda [PROJECT_ID] > bqml_tutorial e clique em sample_model.
Clique na guia Estatísticas do modelo. Os resultados terão o seguinte formato:
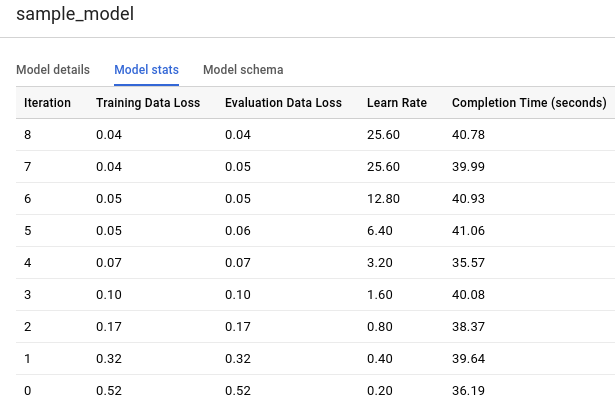
A coluna Perda de dados de treinamento representa a métrica de perda calculada após a iteração especificada no conjunto de dados de treinamento. Você executou uma regressão logística. Portanto, essa coluna é a Log Perda. A coluna Perda de dados de avaliação é a mesma métrica de perda calculada no conjunto de dados de validação, ou seja, dados do treinamento mantidos para validar o modelo.
O BigQuery ML divide automaticamente seus dados de entrada em dois conjuntos, um de treinamento e um de validação, com o objetivo de evitar o sobreajuste do modelo. Isso é necessário para que o algoritmo de treinamento não se adapte demais aos dados conhecidos, evitando que ele generalize esses dados para exemplos novos e ainda inéditos.
Os valores das colunas Perda de dados de treinamento e Perda de dados de avaliação representam valores médios de perda, calculados a partir de todos os exemplos nos seus respectivos conjuntos.
Para ver mais detalhes sobre a função
ML.TRAINING_INFO, consulte a referência de sintaxe do BigQuery ML.
Avalie o modelo
Depois de criar o modelo, utilize a função ML.EVALUATE para avaliar o desempenho do classificador. A função ML.EVALUATE avalia os valores previstos em relação aos dados reais. Para calcular métricas específicas de regressão logística, use a função SQL ML.ROC_CURVE ou a função bigframes.ml.metrics.roc_curve do BigQuery DataFrames.
Neste tutorial, você está usando um modelo de classificação binária que detecta transações. As duas classes são os valores na coluna label: 0 (sem transações) e 1 (transação realizada).
SQL
A consulta usada para avaliar o modelo é esta:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Detalhes da consulta
A principal instrução SELECT recupera as colunas do modelo.
A cláusula FROM usa a função ML.EVALUATE no modelo: bqml_tutorial.sample_model.
A cláusula FROM e a instrução SELECT aninhada desta consulta são as mesmas da consulta CREATE MODEL.
A cláusula WHERE — _TABLE_SUFFIX BETWEEN '20170701' AND '20170801' — limita o número de tabelas verificadas pela consulta. O período verificado vai de 1º de julho de 2017 a 1º de agosto de 2017. Esses são os dados usados para avaliar o desempenho preditivo do modelo. Os dados foram coletados no mês imediatamente posterior ao período abrangido pelos dados de treinamento.
Execute a consulta ML.EVALUATE
Para executar a consulta ML.EVALUATE que avalia o modelo:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão o seguinte formato:
+--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | precision | recall | accuracy | f1_score | log_loss | roc_auc | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | 0.4451901565995526 | 0.08879964301651048 | 0.9716829479411401 | 0.1480654761904762 | 0.07921781778780206 | 0.970706 | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+
Como você executou uma regressão logística, os resultados incluem as seguintes colunas:
precision: métrica para modelos de classificação. A precisão identifica a frequência de acerto de um modelo ao prever a classe positiva.recall: métrica para modelos de classificação que responde à seguinte pergunta: De todos os rótulos positivos possíveis, quantos identificaram o modelo corretamente?accuracy: precisão é a fração das previsões corretas de um modelo de classificação.f1_score: medida da precisão do modelo. A pontuação f1 é a média harmônica da precisão e do recall. O melhor valor de uma pontuação f1 é 1. O pior valor é 0.log_loss: a função de perda usada em uma regressão logística. É a medida de quanto as predições do modelo se distanciam dos rótulos corretos.roc_auc: área sob a curva de característica de operação do receptor(ROC, na sigla em inglês).. É a probabilidade de um classificador ter mais certeza de que um exemplo positivo aleatório seja de fato positivo do que um exemplo negativo aleatório seja positivo. Para mais informações, consulte Classificação no Curso intensivo de machine learning.
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
use seu modelo para prever resultados
Agora seu modelo foi avaliado, a próxima etapa é usá-lo para prever um resultado. Use seu modelo para prever o número de transações feitas pelos visitantes do site em cada país.
SQL
A consulta usada para prever o resultado é a seguinte:
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Detalhes da consulta
A principal instrução SELECT recupera a coluna country e soma a coluna predicted_label. Essa coluna é gerada pela função ML.PREDICT.
Ao usar a função ML.PREDICT, o nome da coluna de saída para o modelo é predicted_<label_column_name>. Para modelos de regressão linear, predicted_label é o valor estimado de label. Para modelos de regressão logística, predicted_label é o rótulo mais provável, que, nesse caso, é 0 ou 1.
A função ML.PREDICT é usada para prever resultados usando o modelo: bqml_tutorial.sample_model.
A cláusula FROM e a instrução SELECT aninhada desta consulta são as mesmas da consulta CREATE MODEL.
A cláusula WHERE — _TABLE_SUFFIX BETWEEN '20170701' AND '20170801' — limita o número de tabelas verificadas pela consulta. O período verificado vai de 1º de julho de 2017 a 1º de agosto de 2017. Você está fazendo predições para esses dados. Os dados foram coletados no mês imediatamente posterior ao período abrangido pelos dados de treinamento.
As cláusulas GROUP BY e ORDER BY agrupam os resultados por país e os ordenam pela soma das compras previstas em ordem decrescente.
A cláusula LIMIT é usada aqui para exibir apenas os 10 melhores resultados.
Executar a consulta ML.PREDICT
Veja como executar a consulta que usa o modelo para prever um resultado:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a seguinte aparência:
+----------------+---------------------------+ | country | total_predicted_purchases | +----------------+---------------------------+ | United States | 209 | | Taiwan | 6 | | Canada | 4 | | Turkey | 2 | | India | 2 | | Japan | 2 | | Indonesia | 1 | | United Kingdom | 1 | | Guyana | 1 | +----------------+---------------------------+
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Faça predições de compras por usuário
No próximo exemplo, você tentará prever o número de transações que os visitantes do site farão.
SQL
Essa consulta é idêntica à anterior, exceto pela cláusula GROUP BY. Aqui, a cláusula GROUP BY — GROUP BY fullVisitorId — é usada para agrupar os resultados por código de visitante.
Para executar a consulta, faça o seguinte:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT fullVisitorId, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country, fullVisitorId FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY fullVisitorId ORDER BY total_predicted_purchases DESC LIMIT 10
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a seguinte aparência:
+---------------------+---------------------------+ | fullVisitorId | total_predicted_purchases | +---------------------+---------------------------+ | 9417857471295131045 | 4 | | 2158257269735455737 | 3 | | 5073919761051630191 | 3 | | 7104098063250586249 | 2 | | 4668039979320382648 | 2 | | 1280993661204347450 | 2 | | 7701613595320832147 | 2 | | 0376394056092189113 | 2 | | 9097465012770697796 | 2 | | 4419259211147428491 | 2 | +---------------------+---------------------------+
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Limpar
Para evitar cobranças na conta do Google Cloud pelos recursos usados nesta página, siga estas etapas.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console do Google Cloud.
Na navegação, selecione o conjunto de dados bqml_tutorial criado.
Clique em Excluir conjunto de dados no lado direito da janela. Essa ação exclui o conjunto, a tabela e todos os dados.

Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial) e clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
- Para saber mais sobre machine learning, consulte o Curso intensivo de machine learning.
- Para uma visão geral do BigQuery ML, consulte Introdução ao BigQuery ML.
- Para saber mais, consulte Como usar o console do Google Cloud.