Creare modelli di machine learning in BigQuery ML
Questo tutorial introduce gli utenti a BigQuery ML utilizzando la console Google Cloud.
BigQuery ML consente agli utenti di creare ed eseguire modelli di machine learning in BigQuery utilizzando query SQL e codice Python. L'obiettivo è democratizzare il machine learning consentendo ai professionisti SQL di creare modelli utilizzando i loro strumenti esistenti e di aumentare la velocità di sviluppo eliminando la necessità di spostare i dati.
In questo tutorial, utilizzerai il set di dati di esempio di Google Analytics per BigQuery per creare un modello che prevede se un visitatore del sito web effettuerà una transazione. Per informazioni sullo schema del set di dati di Analytics, consulta lo schema di esportazione di BigQuery nel Centro assistenza Analytics.
Obiettivi
In questo tutorial utilizzerai:
- BigQuery ML per creare un modello di regressione logistica binaria utilizzando l'istruzione
CREATE MODEL - La funzione
ML.EVALUATEper valutare il modello ML - La funzione
ML.PREDICTper fare previsioni utilizzando il modello ML
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi di BigQuery, consulta la pagina Prezzi di BigQuery.
Per ulteriori informazioni sui costi di BigQuery ML, consulta Prezzi di BigQuery ML.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
- BigQuery viene abilitato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Attiva l'API BigQuery.
crea il tuo set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML:
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
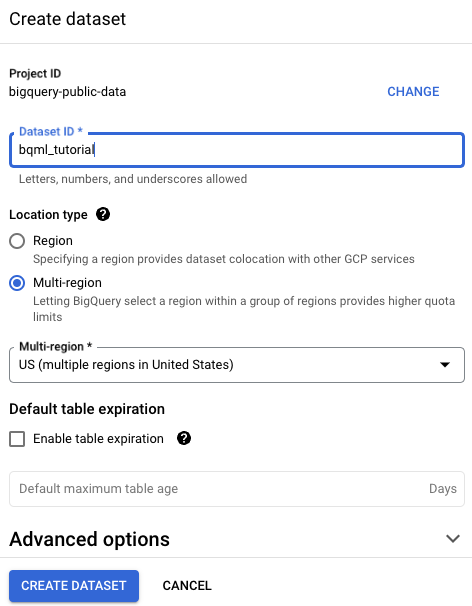
Nella pagina Crea set di dati, segui questi passaggi:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Più regioni e poi Stati Uniti (più regioni negli Stati Uniti).
I set di dati pubblici vengono archiviati in
USpiù regioni. Per semplicità, memorizza il set di dati nella stessa posizione.Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
crea il tuo modello
Poi, crei un modello di regressione logistica utilizzando il set di dati di esempio di Analytics per BigQuery.
SQL
La seguente query GoogleSQL viene utilizzata per creare il modello utilizzato per prevedere se un visitatore del sito web eseguirà una transazione.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Oltre a creare il modello, l'esecuzione di una query contenente l'istruzione CREATE MODEL addestra il modello utilizzando i dati recuperati dall'istruzione SELECT della query.
Dettagli query
La clausola CREATE MODEL
viene utilizzata per creare e addestrare il modello denominato bqml_tutorial.sample_model.
La clausola OPTIONS(model_type='logistic_reg') indica che stai creando un modello di regressione logistica.
Un modello di regressione logistica cerca di suddividere i dati di input in due classi e fornisce
la probabilità che i dati si trovino in una delle classi. Di solito, quello che stai cercando di rilevare (ad esempio se un'email è spam) è rappresentato da 1, mentre tutto il resto è rappresentato da 0. Se il modello di regressione logistica restituisce 0.9, c'è una probabilità del 90% che l'input sia ciò che stai cercando di rilevare (l'email è spam).
L'istruzione SELECT di questa query recupera le seguenti colonne utilizzate dal modello per prevedere la probabilità che un cliente completi una transazione:
totals.transactions: il numero totale di transazioni e-commerce nella sessione. Se il numero di transazioni èNULL, il valore nella colonnalabelè impostato su0. In caso contrario, viene impostato su1. Questi valori rappresentano i possibili risultati. La creazione di un alias denominatolabelè un'alternativa all'impostazione dell'opzioneinput_label_cols=nell'istruzioneCREATE MODEL.device.operatingSystem: il sistema operativo del dispositivo del visitatore.device.isMobile: indica se il dispositivo del visitatore è un dispositivo mobile.geoNetwork.country: il paese da cui hanno avuto origine le sessioni, in base all'indirizzo IP.totals.pageviews: il numero totale di visualizzazioni di pagina nella sessione.
La clausola FROM - bigquery-public-data.google_analytics_sample.ga_sessions_*
indica che stai eseguendo una query sul set di dati di esempio di Google Analytics.
Questo set di dati si trova nel progetto bigquery-public-data. Stai eseguendo una query su un insieme di tabelle
suddivise in base alla data. È rappresentato dal carattere jolly nel nome della tabella:
google_analytics_sample.ga_sessions_*.
La clausola WHERE - _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
limita il numero di tabelle analizzate dalla query. L'intervallo di date scansionato va dal 1° agosto 2016 al 30 giugno 2017.
Esegui la query CREATE MODEL
Per eseguire la query CREATE MODEL al fine di creare e addestrare il modello:
- Nella console Google Cloud, fai clic sul pulsante Crea nuova query. Se non è possibile fare clic su questo testo, significa che l'editor query è già aperto.

Inserisci la seguente query GoogleSQL nell'area di testo Editor query.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Fai clic su Esegui.
Il completamento della query richiede diversi minuti. Al termine della prima iterazione, il modello (
sample_model) viene visualizzato nel pannello di navigazione. Poiché la query utilizza un'istruzioneCREATE MODELper creare un modello, non vedrai i risultati della query.Puoi osservare il modello durante l'addestramento visualizzando la scheda Statistiche modello. Non appena la prima iterazione viene completata, la scheda viene aggiornata. Le statistiche continuano ad aggiornarsi al termine di ogni iterazione.
DataFrame BigQuery
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida rapida di BigQuery sull'utilizzo di BigQuery DataFrames. Per saperne di più, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Ricevere statistiche di addestramento
Per visualizzare i risultati dell'addestramento del modello, puoi utilizzare la funzione ML.TRAINING_INFO oppure puoi visualizzare le statistiche nella console Google Cloud. In questo tutorial utilizzerai la console Google Cloud.
Il machine learning consiste nel creare un modello che può utilizzare i dati per fare una previsione. Il modello è essenzialmente una funzione che accetta input e applica calcoli agli input per produrre un output, ovvero una previsione.
Gli algoritmi di machine learning utilizzano diversi esempi in cui la previsione è già nota (ad esempio i dati storici degli acquisti degli utenti) e modificano iterativamente le varie ponderazioni nel modello in modo che le previsioni del modello corrispondano ai valori reali. Questo lo fa riducendo al minimo il modo in cui il modello sta utilizzando una metrica chiamata perdita.
Per ogni iterazione la perdita dovrebbe diminuire (idealmente pari a zero). Una perdita pari a zero indica che il modello è preciso al 100%.
Per visualizzare le statistiche di addestramento del modello generate quando hai eseguito la query CREATE MODEL:
Nel pannello di navigazione della console Google Cloud, nella sezione Risorse, espandi [PROJECT_ID] > bqml_tutorial, quindi fai clic su sample_model.
Fai clic sulla scheda Statistiche modello. I risultati dovrebbero essere simili ai seguenti:
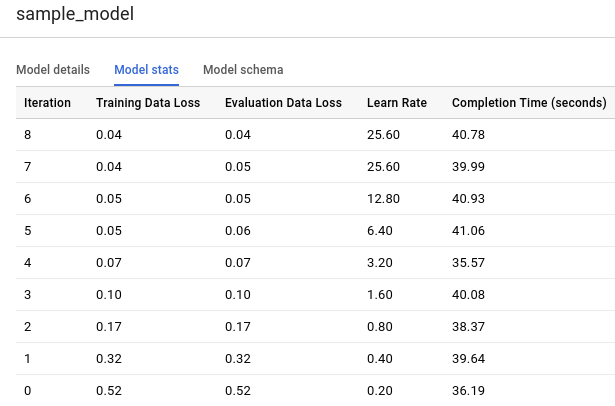
La colonna Perdita di dati di addestramento rappresenta la metrica di perdita calcolata dopo l'iterazione specificata nel set di dati di addestramento. Poiché hai eseguito una regressione logistica, questa colonna indica la perdita di log. La colonna Valutazione perdita di dati è la stessa metrica di perdita calcolata sul set di dati di holdout (dati esclusi dall'addestramento per convalidare il modello).
BigQuery ML suddivide automaticamente i dati di input in un set di addestramento e in un set di holdout per evitare di superare il modello. Questo è necessario per fare in modo che l'algoritmo di addestramento non si adatti ai dati noti così da non essere generalizzati a nuovi esempi non considerati.
Perdita dei dati di addestramento e perdita di dati di valutazione sono valori di perdita medi, calcolati in media su tutti gli esempi nei rispettivi insiemi.
Per ulteriori dettagli sulla funzione
ML.TRAINING_INFO, consulta Riferimento per la sintassi di BigQuery ML.
valuta il modello
Dopo aver creato il modello, valuti le prestazioni del classificatore utilizzando la funzione ML.EVALUATE. La funzione ML.EVALUATE valuta i valori previsti in base ai dati effettivi. Per calcolare metriche specifiche per la regressione logistica, utilizza la funzione SQL di ML.ROC_CURVE
o la funzione bigframes.ml.metrics.roc_curve DataFrames di BigQuery.
In questo tutorial userai un modello di classificazione binario
che rileva le transazioni. Le due classi sono i valori nella colonna label:
0 (nessuna transazione) e 1 (transazione effettuata).
SQL
La query utilizzata per valutare il modello è la seguente:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Dettagli query
L'istruzione SELECT più in alto recupera le colonne dal modello.
La clausola FROM utilizza la funzione ML.EVALUATE
nel modello: bqml_tutorial.sample_model.
L'istruzione SELECT nidificata e la clausola FROM di questa query sono uguali a quelle
nella query CREATE MODEL.
La clausola WHERE - _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
limita il numero di tabelle analizzate dalla query. L'intervallo di date scansionato va dal 1° luglio 2017 al 1° agosto 2017. Questi sono i dati che utilizzerai per
valutare il rendimento predittivo del modello. Sono stati raccolti nel mese immediatamente successivo al periodo di tempo specificato dai dati di addestramento.
Esegui la query ML.EVALUATE
Per eseguire la query ML.EVALUATE che valuta il modello:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la seguente query GoogleSQL nell'area di testo Editor query.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Fai clic su Esegui.
Quando la query è completa, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
+--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | precision | recall | accuracy | f1_score | log_loss | roc_auc | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | 0.4451901565995526 | 0.08879964301651048 | 0.9716829479411401 | 0.1480654761904762 | 0.07921781778780206 | 0.970706 | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+
Poiché hai eseguito una regressione logistica, i risultati includono le seguenti colonne:
precision: una metrica per i modelli di classificazione. La precisione identifica la frequenza con cui un modello era corretto durante la previsione della classe positiva.recall- Una metrica per i modelli di classificazione che risponde alla seguente domanda: Tra tutte le possibili etichette positive, quante sono state identificate correttamente dal modello?accuracy- L'accuratezza è la frazione di previsioni corrette da un modello di classificazione.f1_score: una misura dell'accuratezza del modello. Il punteggio f1 è la media armonica della precisione e del richiamo. Il valore migliore di un punteggio f1 è 1. Il valore peggiore è 0.log_loss: la funzione di perdita utilizzata in una regressione logistica. Questa è la misura di quanto distano le previsioni del modello dalle etichette corrette.roc_auc: l'area sotto la curva ROC. Questa è la probabilità che un classificatore abbia maggiore sicurezza che un esempio positivo scelto in modo casuale sia effettivamente positivo rispetto a un esempio negativo scelto casualmente è positivo. Per maggiori informazioni, consulta la sezione Classificazione nel Corso accelerato sul machine learning.
DataFrame BigQuery
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida rapida di BigQuery sull'utilizzo di BigQuery DataFrames. Per saperne di più, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
usa il tuo modello per prevedere i risultati
Ora che hai valutato il modello, il passaggio successivo è utilizzarlo per prevedere un risultato. Devi usare il modello per prevedere il numero di transazioni effettuate dai visitatori del sito web di ogni paese.
SQL
La query utilizzata per prevedere il risultato è la seguente:
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Dettagli query
L'istruzione SELECT più in alto recupera la colonna country e somma la colonna predicted_label. Questa colonna viene generata dalla funzione ML.PREDICT.
Quando utilizzi la funzione ML.PREDICT, il nome della colonna di output del modello è
predicted_<label_column_name>. Per i modelli di regressione lineare, predicted_label
è il valore stimato di label. Per i modelli di regressione logistica, predicted_label è l'etichetta più probabile, che in questo caso è 0 o 1.
La funzione ML.PREDICT
viene utilizzata per prevedere risultati utilizzando il modello: bqml_tutorial.sample_model.
L'istruzione SELECT nidificata e la clausola FROM di questa query sono uguali a quelle
nella query CREATE MODEL.
La clausola WHERE - _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
limita il numero di tabelle analizzate dalla query. L'intervallo di date scansionato va dal 1° luglio 2017 al 1° agosto 2017. Questi sono i dati per i quali esegui
le previsioni. Sono stati raccolti nel mese immediatamente successivo al periodo
di tempo specificato dai dati di addestramento.
Le clausole GROUP BY e ORDER BY raggruppano i risultati per paese e li ordinano in base alla somma degli acquisti previsti in ordine decrescente.
La clausola LIMIT viene utilizzata qui per visualizzare solo i primi 10 risultati.
Esegui la query ML.PREDICT
Per eseguire la query che utilizza il modello per prevedere un risultato:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la seguente query GoogleSQL nell'area di testo Editor query.
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Fai clic su Esegui.
Quando la query è completa, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
+----------------+---------------------------+ | country | total_predicted_purchases | +----------------+---------------------------+ | United States | 209 | | Taiwan | 6 | | Canada | 4 | | Turkey | 2 | | India | 2 | | Japan | 2 | | Indonesia | 1 | | United Kingdom | 1 | | Guyana | 1 | +----------------+---------------------------+
DataFrame BigQuery
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida rapida di BigQuery sull'utilizzo di BigQuery DataFrames. Per saperne di più, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Previsione degli acquisti per utente
In questo esempio, cerchi di prevedere il numero di transazioni che eseguirà ogni visitatore del sito web.
SQL
Questa query è identica alla query precedente, ad eccezione della clausola GROUP BY. In questo caso, la clausola GROUP BY, GROUP BY fullVisitorId, viene utilizzata per raggruppare i risultati per ID visitatore.
Per eseguire la query:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la seguente query GoogleSQL nell'area di testo Editor query.
#standardSQL SELECT fullVisitorId, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country, fullVisitorId FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY fullVisitorId ORDER BY total_predicted_purchases DESC LIMIT 10
Fai clic su Esegui.
Quando la query è completa, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
+---------------------+---------------------------+ | fullVisitorId | total_predicted_purchases | +---------------------+---------------------------+ | 9417857471295131045 | 4 | | 2158257269735455737 | 3 | | 5073919761051630191 | 3 | | 7104098063250586249 | 2 | | 4668039979320382648 | 2 | | 1280993661204347450 | 2 | | 7701613595320832147 | 2 | | 0376394056092189113 | 2 | | 9097465012770697796 | 2 | | 4419259211147428491 | 2 | +---------------------+---------------------------+
DataFrame BigQuery
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida rapida di BigQuery sull'utilizzo di BigQuery DataFrames. Per saperne di più, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura Credenziali predefinite dell'applicazione. Per maggiori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questa pagina, segui questi passaggi:
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi mantenere il progetto ed eliminare il set di dati.
Elimina il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati che hai creato in questo tutorial:
Se necessario, apri la pagina di BigQuery nella console Google Cloud.
Nella barra di navigazione, seleziona il set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati sul lato destro della finestra. Questa azione elimina il set di dati, la tabella e tutti i dati.

Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial), quindi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Per saperne di più sul machine learning, consulta Machine Learning Crash Course.
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per scoprire di più sulla console Google Cloud, consulta Utilizzo della console Google Cloud.