Créer des modèles de machine learning dans BigQuery ML
Ce tutoriel présente l'utilisation de BigQuery ML à l'aide de Google Cloud Console.
BigQuery ML permet aux utilisateurs de créer et d'exécuter des modèles de machine learning dans BigQuery à l'aide de requêtes SQL et de code Python. L'objectif est de démocratiser le machine learning en permettant aux utilisateurs SQL de créer des modèles à l'aide de leurs propres outils et d'accélérer le rythme de développement en leur évitant d'avoir à transférer des données.
Dans ce tutoriel, vous allez vous servir de l'exemple d'ensemble de données Google Analytics pour BigQuery afin de créer un modèle capable de prévoir si un internaute effectuera une transaction. Pour en savoir plus sur le schéma de l'ensemble de données Analytics, consultez la page Schéma de BigQuery Export dans le centre d'aide Google Analytics.
Objectifs
Dans ce tutoriel, vous allez utiliser :
- BigQuery ML pour créer un modèle de régression logistique binaire à l'aide de l'instruction
CREATE MODEL; - La fonction
ML.EVALUATEpour évaluer le modèle de ML ; - la fonction
ML.PREDICTpour effectuer des prédictions à l'aide du modèle de ML.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud dont :
- BigQuery
- BigQuery ML
Pour en savoir plus sur le coût de BigQuery, consultez la page Tarifs de BigQuery.
Pour en savoir plus sur le coût de BigQuery ML, consultez la page Tarifs de BigQuery ML.
Avant de commencer
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
- BigQuery est automatiquement activé dans les nouveaux projets.
Pour activer BigQuery dans un projet préexistant, accédez à
Activez l'API BigQuery
Créer votre ensemble de données
Vous allez créer un ensemble de données BigQuery pour stocker votre modèle de ML :
Dans la console Google Cloud, accédez à la page "BigQuery".
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
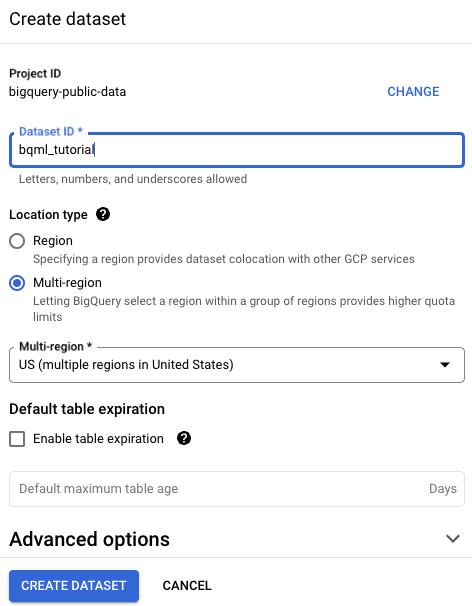
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Les ensembles de données publics sont stockés dans l'emplacement multirégional
US. Par souci de simplicité, stockez votre ensemble de données dans le même emplacement.Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
Créer votre modèle
Vous devez ensuite créer un modèle de régression logistique à l'aide de l'exemple d'ensemble de données Analytics pour BigQuery.
SQL
La requête en GoogleSQL présentée ci-dessous permet de créer le modèle dont vous vous servez pour prévoir si un internaute effectuera une transaction.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Outre la création du modèle, l'exécution d'une requête contenant l'instruction CREATE MODEL entraîne le modèle à l'aide des données récupérées par l'instruction SELECT de votre requête.
Détails de la requête
La clause CREATE MODEL permet de créer et d'entraîner le modèle nommé bqml_tutorial.sample_model.
La clause OPTIONS(model_type='logistic_reg') indique que vous créez un modèle de régression logistique.
Un modèle de régression logistique tente de scinder les données d'entrée en deux classes et détermine leur probabilité d'appartenance à l'une d'elles. Généralement, ce que vous essayez de déterminer (par exemple, si un e-mail est un spam) est représenté par un 1 et tout le reste par un 0. Si le modèle de régression logistique renvoie la valeur 0,9, il est probable à 90 % que l'entrée soit ce que vous essayez de déterminer (l'e-mail est un spam).
L'instruction SELECT de cette requête extrait les colonnes suivantes qui permettent au modèle de réaliser une prédiction sur la probabilité qu'un client effectue une transaction :
totals.transactions: nombre total de transactions e-commerce au cours de la session. Si le nombre de transactions estNULL, la valeur de la colonnelabelest définie sur0. Sinon, la valeur est égale à1. Ces valeurs correspondent aux résultats possibles. Plutôt que de définir l'optioninput_label_cols=dans l'instructionCREATE MODEL, vous pouvez créer un alias nommélabel.device.operatingSystem: système d'exploitation de l'appareil du visiteur.device.isMobile: indique si l'appareil du visiteur est un appareil mobile.geoNetwork.country: pays d'origine des sessions, sur la base de l'adresse IP.totals.pageviews: nombre total de pages vues au cours de la session.
La clause FROM – bigquery-public-data.google_analytics_sample.ga_sessions_* – indique que vous interrogez l'exemple d'ensemble de données Google Analytics.
Cet ensemble de données se trouve dans le projet bigquery-public-data. Vous interrogez un ensemble de tables segmentées par date. Il est représenté par le caractère générique dans le nom de la table : google_analytics_sample.ga_sessions_*.
La clause WHERE – _TABLE_SUFFIX BETWEEN '20160801' AND '20170630' – limite le nombre de tables analysées par la requête. La plage de dates analysée est comprise entre le 1er août 2016 et le 30 juin 2017.
Exécuter la requête CREATE MODEL
Pour exécuter la requête CREATE MODEL qui permet de créer et d'entraîner votre modèle, procédez comme suit :
- Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête. Si ce texte n'est pas disponible, l'Éditeur de requête est déjà ouvert.

Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Cliquez sur Exécuter.
L'exécution de la requête prend plusieurs minutes. Une fois la première itération terminée, votre modèle (
sample_model) s'affiche dans le panneau de navigation. Étant donné que la requête utilise une instructionCREATE MODELpour créer un modèle, les résultats de la requête ne sont pas affichés.Vous pouvez observer le modèle pendant l'entraînement dans l'onglet Statistiques du modèle. Dès que la première itération est terminée, l'onglet est mis à jour. Les statistiques sont actualisées à la fin de chaque itération.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Obtenir des statistiques d'entraînement
Pour afficher les résultats de l'entraînement du modèle, vous pouvez utiliser la fonction ML.TRAINING_INFO ou afficher les statistiques dans la console Google Cloud. Dans ce tutoriel, vous utilisez la console Google Cloud.
Le machine learning consiste à créer un modèle capable d'utiliser des données pour réaliser une prédiction. Le modèle est avant tout une fonction qui sélectionne des entrées et leur applique des calculs afin de générer un résultat, à savoir une prédiction.
Les algorithmes de machine learning prennent plusieurs exemples pour lesquels la prédiction est déjà connue (comme les données de l'historique des achats des utilisateurs) et ajustent plusieurs pondérations de manière itérative dans le modèle afin que les prédictions de ce dernier correspondent aux valeurs réelles. Les algorithmes effectuent cette opération en limitant l'utilisation inappropriée d'une métrique par le modèle (aussi appelée "perte").
Le but est de réduire la perte à chaque itération (idéalement à zéro). Une perte de zéro signifie que le modèle est précis à 100 %.
Pour afficher les statistiques d'entraînement du modèle qui ont été générées lors de l'exécution de la requête CREATE MODEL, procédez comme suit :
Dans le panneau de navigation de la console Google Cloud, dans la section Ressources, développez [PROJECT_ID] > bqml_tutorial, puis cliquez sur sample_model.
Cliquez sur l'onglet Model stats (Statistiques sur le modèle). Les résultats doivent se présenter sous la forme suivante :
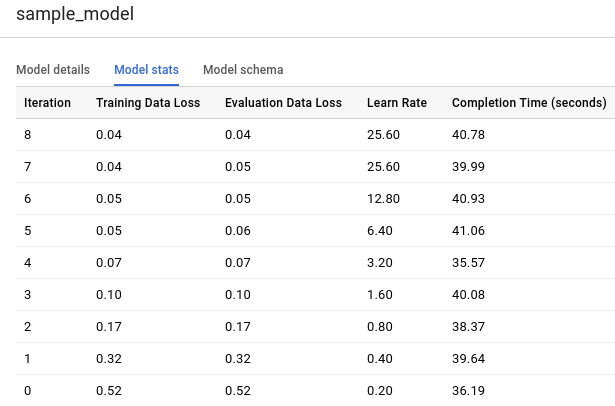
La colonne Training Data Loss (Perte de données d'entraînement) représente la métrique de perte calculée après une itération spécifique dans l'ensemble de données d'entraînement. Étant donné que vous avez effectué une régression logistique, cette colonne correspond à la perte logistique. La colonne Evaluation Data Loss (Perte de données d'évaluation) représente la même métrique de perte calculée sur l'ensemble de données exclues (données bloquées lors de l'entraînement pour valider le modèle).
BigQuery ML scinde automatiquement vos données d'entrée en ensembles de données d'entraînement et de données exclues pour éviter le surapprentissage du modèle. Cette étape est nécessaire pour que l'algorithme d'entraînement ne s'adapte pas trop étroitement aux données connues et afin d'éviter qu'il les généralise pour de nouveaux exemples.
La "Perte de données d'entraînement" et la "Perte de données d'évaluation" sont des valeurs de perte moyennes, calculées à partir de tous les exemples des ensembles correspondants.
Pour en savoir plus sur la fonction
ML.TRAINING_INFO, consultez la documentation de référence sur la syntaxe BigQuery ML.
Évaluer votre modèle
Après avoir créé votre modèle, vous évaluez les performances du classificateur à l'aide de la fonction ML.EVALUATE. La fonction ML.EVALUATE compare les valeurs estimées aux données réelles. Pour calculer des métriques spécifiques à la régression logistique, utilisez la fonction SQL ML.ROC_CURVE ou la fonction BigQuery DataFrames bigframes.ml.metrics.roc_curve.
Dans ce tutoriel, vous utilisez un modèle de classification binaire qui détecte les transactions. Les deux classes sont les valeurs de la colonne label : 0 (aucune transaction) et 1 (transaction effectuée).
SQL
La requête permettant d'évaluer le modèle est la suivante :
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Détails de la requête
La toute première instruction SELECT récupère les colonnes de votre modèle.
La clause FROM utilise la fonction ML.EVALUATE basée sur votre modèle : bqml_tutorial.sample_model.
L'instruction SELECT et la clause FROM imbriquées de cette requête sont identiques à celles de la requête CREATE MODEL.
La clause WHERE – _TABLE_SUFFIX BETWEEN '20170701' AND '20170801' – limite le nombre de tables analysées par la requête. La plage de dates analysée est comprise entre le 1er juillet 2017 et le 1er août 2017. Il s'agit des données dont vous vous servez pour évaluer les prévisions de performances du modèle. Elles ont été recueillies dans le mois qui a suivi la période couverte par les données d'entraînement.
Exécuter la requête ML.EVALUATE
Pour exécuter la requête ML.EVALUATE permettant d'évaluer le modèle, procédez comme suit :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Cliquez sur Exécuter.
Lorsque la requête est terminée, cliquez sur l'onglet Results (Résultats) sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
+--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | precision | recall | accuracy | f1_score | log_loss | roc_auc | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | 0.4451901565995526 | 0.08879964301651048 | 0.9716829479411401 | 0.1480654761904762 | 0.07921781778780206 | 0.970706 | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+
Étant donné que vous avez effectué une régression logistique, les résultats incluent les colonnes suivantes :
precision: statistique des modèles de classification. La précision correspond à la fréquence à laquelle le modèle prédit correctement la classe positive.recall: statistique des modèles de classification qui répond à la question suivante : parmi toutes les étiquettes positives possibles, combien d'entre elles le modèle a-t-il correctement identifiées ?accuracy: la justesse correspond à la fraction de prédictions correctement identifiées par un modèle de classification.f1_score: mesure de la justesse du modèle. Le score f1 est la moyenne harmonique de la précision et du rappel. La meilleure valeur d'un score f1 est 1. La pire valeur est 0.log_loss: fonction de perte utilisée dans une régression logistique. Il s'agit de la mesure de l'écart entre les prédictions du modèle et les étiquettes correctes.roc_auc: aire sous la courbe ROC. Elle correspond à la probabilité que le niveau de confiance d'un classificateur soit supérieur pour un exemple positif choisi aléatoirement comparé à un exemple négatif choisi aléatoirement. Pour en savoir plus, consultez la page Classification dans le Cours d'initiation au Machine Learning.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Utiliser votre modèle pour prédire les résultats
Maintenant que vous avez évalué le modèle, l'étape suivante consiste à vous en servir pour prédire un résultat. Votre modèle vous permet d'estimer le nombre de transactions effectuées par les internautes de chaque pays.
SQL
La requête exécutée pour prédire le résultat est la suivante :
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Détails de la requête
La toute première instruction SELECT récupère la colonne country et ajoute la colonne predicted_label. Cette colonne est générée par la fonction ML.PREDICT.
Lorsque vous utilisez la fonction ML.PREDICT, le nom de la colonne de résultats du modèle est predicted_<label_column_name>. Pour les modèles de régression linéaire, predicted_label est la valeur estimée de label. Pour les modèles de régression logistique, l'étiquette predicted_label est la plus susceptible d'être utilisée. Ici, la valeur est 0 ou 1.
La fonction ML.PREDICT sert à prédire les résultats à l'aide de votre modèle : bqml_tutorial.sample_model.
L'instruction SELECT et la clause FROM imbriquées de cette requête sont identiques à celles de la requête CREATE MODEL.
La clause WHERE – _TABLE_SUFFIX BETWEEN '20170701' AND '20170801' – limite le nombre de tables analysées par la requête. La plage de dates analysée est comprise entre le 1er juillet 2017 et le 1er août 2017. Il s'agit des données pour lesquelles vous réalisez des prédictions. Elles ont été recueillies dans le mois qui a suivi la période couverte par les données d'entraînement.
Les clauses GROUP BY et ORDER BY regroupent les résultats par pays, puis les trient en fonction de la somme d'achats prévus par ordre décroissant.
La clause LIMIT permet ici de n'afficher que les 10 premiers résultats.
Exécuter la requête ML.PREDICT
Pour exécuter la requête permettant de prédire un résultat à l'aide votre modèle, procédez comme suit :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Cliquez sur Exécuter.
Lorsque la requête est terminée, cliquez sur l'onglet Results (Résultats) sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
+----------------+---------------------------+ | country | total_predicted_purchases | +----------------+---------------------------+ | United States | 209 | | Taiwan | 6 | | Canada | 4 | | Turkey | 2 | | India | 2 | | Japan | 2 | | Indonesia | 1 | | United Kingdom | 1 | | Guyana | 1 | +----------------+---------------------------+
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Prédire les achats pour chaque utilisateur
Dans cet exemple, vous tentez de prévoir le nombre de transactions que chaque internaute effectuera.
SQL
Cette requête est identique à la précédente, à l'exception de la clause GROUP BY. La clause GROUP BY – GROUP BY fullVisitorId – saisie ici permet de regrouper les résultats par ID de visiteur.
Pour exécuter la requête, procédez comme suit :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL SELECT fullVisitorId, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country, fullVisitorId FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY fullVisitorId ORDER BY total_predicted_purchases DESC LIMIT 10
Cliquez sur Exécuter.
Lorsque la requête est terminée, cliquez sur l'onglet Results (Résultats) sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
+---------------------+---------------------------+ | fullVisitorId | total_predicted_purchases | +---------------------+---------------------------+ | 9417857471295131045 | 4 | | 2158257269735455737 | 3 | | 5073919761051630191 | 3 | | 7104098063250586249 | 2 | | 4668039979320382648 | 2 | | 1280993661204347450 | 2 | | 7701613595320832147 | 2 | | 0376394056092189113 | 2 | | 9097465012770697796 | 2 | | 4419259211147428491 | 2 | +---------------------+---------------------------+
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Effectuer un nettoyage
Pour éviter que les ressources utilisées sur cette page soient facturées sur votre compte Google Cloud, procédez comme suit :
- Supprimez le projet que vous avez créé.
- Ou conservez le projet et supprimez l'ensemble de données.
Supprimer l'ensemble de données
La suppression de votre projet entraîne celle de tous les ensembles de données et de toutes les tables qui lui sont associés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans Cloud Console.
Dans le panneau de navigation, sélectionnez l'ensemble de données bqml_tutorial que vous avez créé.
Cliquez sur Delete dataset (Supprimer l'ensemble de données) dans la partie droite de la fenêtre. Cette action supprime l'ensemble de données, la table et toutes les données.

Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
bqml_tutorial), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Étape suivante
- Pour en savoir plus sur le machine learning, consultez le Cours d'initiation au Machine Learning.
- Pour obtenir plus d'informations sur BigQuery ML, consultez la page Présentation de BigQuery ML.
- Pour en savoir plus sur la console Google Cloud, consultez la page Utiliser la console Google Cloud.