Tutorial ini memperkenalkan analis data pada model faktorisasi matriks di BigQuery ML. BigQuery ML memungkinkan pengguna membuat dan menjalankan model machine learning di BigQuery menggunakan kueri SQL. Tujuannya adalah mendemokrasikan machine learning dengan memungkinkan praktisi SQL membuat model menggunakan alat yang ada dan meningkatkan kecepatan pengembangan dengan meniadakan kebutuhan akan pemindahan data.
Dalam tutorial ini, Anda akan mempelajari cara membuat model dari masukan eksplisit menggunakan set data movielens1m untuk membuat rekomendasi berdasarkan ID film dan ID pengguna
Set data movielens berisi rating dari skala 1 hingga 5 yang diberikan pengguna pada film, beserta metadata film seperti genre.
Tujuan
Dalam tutorial ini, Anda akan menggunakan:
- BigQuery ML untuk membuat model rekomendasi eksplisit menggunakan pernyataan
CREATE MODEL - Fungsi
ML.EVALUATEuntuk mengevaluasi model ML - Fungsi
ML.WEIGHTSuntuk memeriksa bobot faktor laten yang dihasilkan selama pelatihan. - Fungsi
ML.RECOMMENDuntuk menghasilkan rekomendasi bagi pengguna.
Biaya
Tutorial ini menggunakan komponen Google Cloud yang dapat dikenai biaya, termasuk:
- BigQuery
- BigQuery ML
Untuk informasi selengkapnya tentang biaya BigQuery, lihat halaman harga BigQuery.
Untuk informasi selengkapnya tentang biaya BigQuery ML, lihat harga BigQuery ML.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
- BigQuery secara otomatis diaktifkan dalam project baru.
Untuk mengaktifkan BigQuery dalam project yang sudah ada, buka
Enable the BigQuery API.
Langkah pertama: Buat set data Anda
Buat set data BigQuery untuk menyimpan model ML Anda:
Di konsol Google Cloud, buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.

Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
bqml_tutorial.Untuk Location type, pilih Multi-region, lalu pilih US (multiple regions in United States).
Set data publik disimpan di
USmulti-region. Untuk mempermudah, simpan set data Anda di lokasi yang sama.Jangan ubah setelan default yang tersisa, lalu klik Create dataset.

Langkah kedua: Muat set data Movielens ke BigQuery
Berikut adalah langkah-langkah untuk memuat 1 juta set data movielens ke BigQuery menggunakan alat command line BigQuery.
Set data bernama movielens akan dibuat dan tabel movielens yang relevan akan disimpan di dalamnya.
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
Karena judul film berisi titik dua, koma, dan pipa, kita perlu menggunakan pembatas yang berbeda. Untuk memuat judul film, gunakan varian yang sedikit berbeda dari dua perintah terakhir.
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
Langkah ketiga: Buat model rekomendasi eksplisit
Selanjutnya, Anda membuat model rekomendasi eksplisit menggunakan tabel contoh lensa film yang dimuat pada langkah sebelumnya. Kueri GoogleSQL berikut digunakan untuk membuat model yang akan digunakan untuk memprediksi rating setiap pasangan item pengguna.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Selain membuat model, menjalankan perintah CREATE MODEL akan melatih model yang Anda buat.
Detail kueri
Klausa CREATE MODEL
digunakan untuk membuat dan melatih model bernama bqml_tutorial.my_explicit_mf_model.
Klausa OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) menunjukkan bahwa Anda membuat model faktorisasi matriks. Secara default, tindakan ini akan membuat model faktorisasi matriks eksplisit, kecuali jika feedback_type='IMPLICIT' ditentukan. Contoh cara membuat model faktorisasi matriks implisit akan dijelaskan dalam artikel Menggunakan BigQuery ML untuk membuat rekomendasi untuk masukan implisit.
Pernyataan SELECT kueri ini menggunakan kolom berikut untuk membuat
rekomendasi.
user_id—ID pengguna (INT64).item_id—ID film (INT64).rating—Rating eksplisit dari 1 hingga 5 yang diberikanuser_idkepadaitem_id(FLOAT64).
Klausul FROM—movielens.movielens_1m —
menunjukkan bahwa Anda membuat kueri tabel movielens_1m dalam set data movielens.
Set data ini ada di proyek BigQuery jika petunjuk pada langkah kedua telah diikuti.
Menjalankan kueri CREATE MODEL
Untuk menjalankan kueri CREATE MODEL guna membuat dan melatih model Anda:
Di konsol Google Cloud, klik tombol Buat kueri baru.
Masukkan kueri GoogleSQL berikut di area teks Query editor.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Klik Jalankan.
Pemrosesan kueri ini memerlukan waktu sekitar 10 menit, setelah itu model Anda (
my_explicit_mf_model) akan muncul di panel navigasi Konsol Google Cloud. Karena kueri tersebut menggunakan pernyataanCREATE MODELuntuk membuat model, Anda tidak akan melihat hasil kueri.
Langkah keempat (opsional): Dapatkan statistik pelatihan
Untuk melihat hasil pelatihan model, Anda dapat menggunakan fungsi ML.TRAINING_INFO, atau Anda dapat melihat statistik di konsol Google Cloud. Dalam tutorial ini, Anda akan menggunakan konsol Google Cloud.
Algoritma machine learning membuat model dengan memeriksa banyak contoh dan mencoba menemukan model yang meminimalkan kerugian. Proses ini disebut minimalisasi risiko empiris.
Untuk melihat statistik pelatihan model yang dihasilkan saat Anda menjalankan kueri CREATE MODEL:
Di panel navigasi konsol Google Cloud, di bagian Resource, luaskan [PROJECT_ID] > bqml_tutorial, lalu klik my_implicit_mf_model.
Klik tab Pelatihan, lalu klik Tabel. Hasilnya akan terlihat seperti berikut:
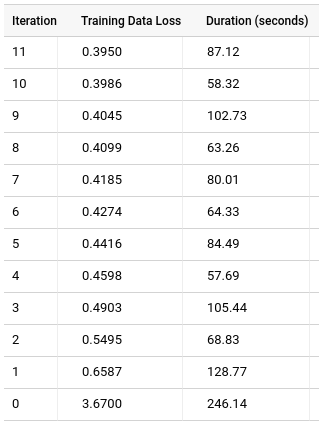
Kolom Training Data Loss menunjukkan metrik kerugian yang dihitung setelah model dilatih menggunakan set data pelatihan. Karena Anda melakukan faktorisasi matriks, kolom ini adalah rataan kuadrat galat (RKG). Secara default, model faktorisasi matriks tidak akan membagi data, sehingga kolom Evaluation Data Loss tidak akan ditampilkan kecuali jika set data holdout ditentukan karena pembagian data berpotensi menghilangkan semua peringkat untuk pengguna atau item. Akibatnya, model tidak akan memiliki informasi faktor laten tentang pengguna atau item yang tidak ada.
Untuk mengetahui detail selengkapnya tentang fungsi
ML.TRAINING_INFO, lihat referensi sintaksis ML BigQuery.
Langkah kelima: Evaluasi model Anda
Setelah membuat model, Anda mengevaluasi performa pemberi rekomendasi menggunakan fungsi ML.EVALUATE. Fungsi ML.EVALUATE mengevaluasi prediksi rating terhadap rating yang sebenarnya.
Kueri yang digunakan untuk mengevaluasi model adalah sebagai berikut:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id,
item_id,
rating
FROM
`movielens.movielens_1m`))
Detail kueri
Pernyataan SELECT paling atas mengambil kolom dari model Anda.
Klausa FROM menggunakan fungsi ML.EVALUATE
terhadap model Anda: bqml_tutorial.my_explicit_mf_model.
Pernyataan SELECT dan klausa FROM bertingkat dari kueri ini sama dengan
pernyataan dalam kueri CREATE MODEL.
Anda juga dapat memanggil ML.EVALUATE tanpa memberikan data input. Pelatihan ini akan
menggunakan metrik evaluasi yang dihitung selama pelatihan:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
Menjalankan kueri ML.EVALUATE
Untuk menjalankan kueri ML.EVALUATE yang mengevaluasi model:
Di konsol Google Cloud, klik tombol Buat kueri baru.
Masukkan kueri GoogleSQL berikut di area teks Query editor.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
(Opsional) Untuk menetapkan lokasi pemrosesan, klik More > Query settings. Untuk Processing location, pilih
US. Langkah ini bersifat opsional karena lokasi pemrosesan terdeteksi secara otomatis berdasarkan lokasi set data.
Klik Run.
Setelah kueri selesai, klik tab Results di bawah area teks kueri. Hasilnya akan terlihat seperti berikut:

Karena Anda melakukan faktorisasi matriks eksplisit, hasilnya mencakup kolom berikut:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Metrik penting dalam hasil evaluasi adalah skor R2. Skor R2 adalah ukuran statistik yang menentukan apakah prediksi regresi linear memperkirakan data sebenarnya. 0 menunjukkan bahwa model tidak menjelaskan variabilitas data respons di sekitar nilai rata-rata. 1 menunjukkan bahwa model menjelaskan semua variabilitas data respons di sekitar nilai rata-rata.
Langkah keenam: Gunakan model Anda untuk memprediksi rating dan membuat rekomendasi
Menemukan semua rating item untuk sekumpulan pengguna
ML.RECOMMEND tidak perlu menggunakan argumen tambahan selain model, tetapi dapat menggunakan tabel opsional. Jika tabel input hanya memiliki satu kolom yang
cocok dengan nama kolom input user atau item input, semua
prediksi rating item untuk setiap user akan dihasilkan dan sebaliknya. Perlu
diketahui bahwa jika semua users atau semua items berada dalam tabel input, hasil
yang akan ditampilkan adalah tidak meneruskan argumen opsional ke ML.RECOMMEND.
Berikut adalah contoh kueri untuk mengambil semua prediksi rating film untuk 5 pengguna:
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id
FROM
`movielens.movielens_1m`
LIMIT 5))
Detail kueri
Pernyataan SELECT paling atas mengambil kolom user, item, dan predicted_rating.
Kolom terakhir ini dihasilkan oleh fungsi ML.RECOMMEND. Saat Anda menggunakan fungsi ML.RECOMMEND, nama kolom output untuk model adalah predicted_<rating_column_name>. Untuk model faktorisasi matriks eksplisit, predicted_rating adalah estimasi nilai rating.
Fungsi ML.RECOMMEND
digunakan untuk memprediksi rating menggunakan model Anda: bqml_tutorial.my_explicit_mf_model.
Pernyataan SELECT bertingkat pada kueri ini hanya memilih kolom user_id dari tabel asli yang digunakan untuk pelatihan.
Klausul LIMIT—LIMIT 5—akan memfilter 5
user_id secara acak untuk dikirim ke ML.RECOMMEND.
Menemukan rating untuk semua pasangan item pengguna
Setelah mengevaluasi model, langkah berikutnya adalah menggunakannya untuk memprediksi rating. Anda menggunakan model Anda untuk memprediksi rating setiap kombinasi item pengguna di kueri berikut:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Detail kueri
Pernyataan SELECT paling atas mengambil kolom user, item, dan predicted_rating.
Kolom terakhir ini dihasilkan oleh fungsi ML.RECOMMEND. Saat Anda menggunakan fungsi ML.RECOMMEND, nama kolom output untuk model adalah predicted_<rating_column_name>. Untuk model faktorisasi matriks eksplisit, predicted_rating adalah estimasi nilai rating.
Fungsi ML.RECOMMEND
digunakan untuk memprediksi rating menggunakan model Anda: bqml_tutorial.my_explicit_mf_model.
Salah satu cara untuk menyimpan hasilnya ke tabel adalah:
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Jika terjadi error Query Exceeded Resource Limits untuk ML.RECOMMEND, coba lagi
dengan tingkat penagihan yang lebih tinggi. Di alat command line BigQuery, hal ini dapat ditetapkan menggunakan flag --maximum_billing_tier.
Buat rekomendasi.
Dengan kueri rekomendasi sebelumnya, kita dapat mengurutkan berdasarkan rating yang diprediksi dan menampilkan item prediksi teratas untuk setiap pengguna. Kueri berikut menggabungkan
item_ids dengan movie_ids yang ada dalam tabel movielens.movie_titles
yang diupload sebelumnya dan menghasilkan 5 film teratas yang direkomendasikan per pengguna.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
Detail kueri
Pernyataan SELECT bagian dalam menjalankan inner join pada item_id dari
tabel hasil rekomendasi dan movie_id dari tabel
movielens.movie_titles. movielens.movie_titles tidak hanya memetakan movie_id ke nama film, tetapi
juga menyertakan genre film seperti yang dicantumkan oleh IMDB.
Pernyataan SELECT level atas menggabungkan hasil dari pernyataan
SELECT bertingkat menggunakan GROUPS BY user_id untuk menggabungkan movie_title,
genre, dan predicted_rating dalam urutan menurun dan hanya mempertahankan 5 film teratas.
Menjalankan kueri ML.RECOMMEND
Untuk menjalankan kueri ML.RECOMMEND yang menghasilkan 5 film teratas yang direkomendasikan per pengguna:
Di konsol Google Cloud, klik tombol Buat kueri baru.
Masukkan kueri GoogleSQL berikut di area teks Query editor.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Klik Jalankan.
Setelah kueri selesai berjalan, (
bqml_tutorial.recommend_1m) akan muncul di panel navigasi. Karena kueri ini menggunakan pernyataanCREATE TABLEuntuk membuat tabel, Anda tidak akan melihat hasil kueri.Tulis kueri baru lainnya. Masukkan kueri GoogleSQL berikut di area teks Query editor setelah kueri sebelumnya selesai berjalan.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
(Opsional) Untuk menetapkan lokasi pemrosesan, klik More > Query settings. Untuk Processing location, pilih
US. Langkah ini bersifat opsional karena lokasi pemrosesan terdeteksi secara otomatis berdasarkan lokasi set data. Klik Run.
Setelah kueri selesai, klik tab Results di bawah area teks kueri. Hasilnya akan terlihat seperti berikut:
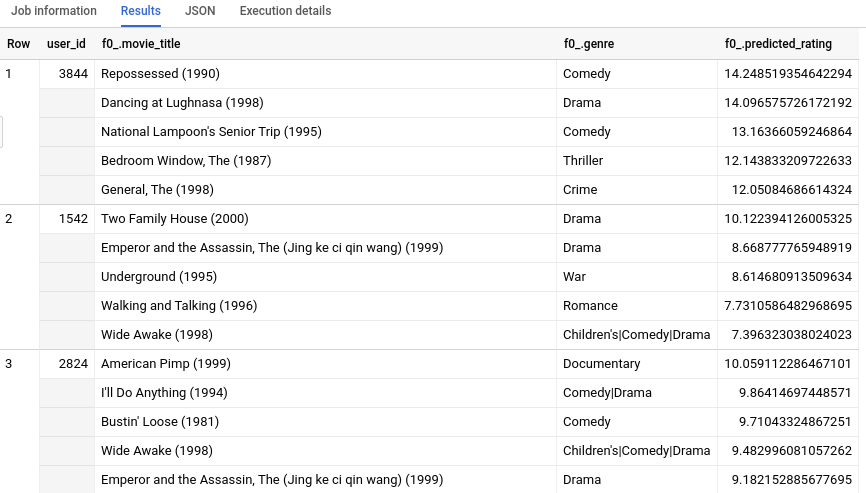
Karena kita memiliki informasi metadata tambahan tentang setiap movie_id selain
INT64, kita dapat melihat info seperti genre tentang 5 film teratas yang direkomendasikan untuk setiap
pengguna. Jika Anda tidak memiliki tabel movietitles yang setara untuk data pelatihan, hasilnya mungkin tidak dapat ditafsirkan secara manusia hanya dengan ID atau hash angka.
Genre teratas per faktor
Jika Anda ingin tahu dengan genre apa setiap faktor laten yang mungkin berkorelasi, Anda dapat menjalankan kueri berikut:
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
Detail kueri
Pernyataan SELECT paling dalam mendapatkan array bobot item_id atau faktor film,
lalu menggabungkannya dengan tabel movielens.movie_titles untuk mendapatkan
genre setiap ID item.
Hasilnya kemudian CROSS JOIN dengan setiap array factor_weights yang hasilnya kemudian ORDER BY feature, weight DESC.
Terakhir, pernyataan SELECT level teratas menggabungkan hasil dari pernyataan internalnya dengan factor dan membuat array untuk setiap faktor yang diurutkan berdasarkan bobot setiap genre.
Menjalankan kueri
Untuk menjalankan kueri di atas yang menghasilkan 10 genre film teratas per faktor:
Di konsol Google Cloud, klik tombol Buat kueri baru.
Masukkan kueri GoogleSQL berikut di area teks Query editor.
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
(Opsional) Untuk menetapkan lokasi pemrosesan, klik More > Query settings. Untuk Processing location, pilih
US. Langkah ini bersifat opsional karena lokasi pemrosesan terdeteksi secara otomatis berdasarkan lokasi set data. Klik Run.
Setelah kueri selesai, klik tab Results di bawah area teks kueri. Hasilnya akan terlihat seperti berikut ini:
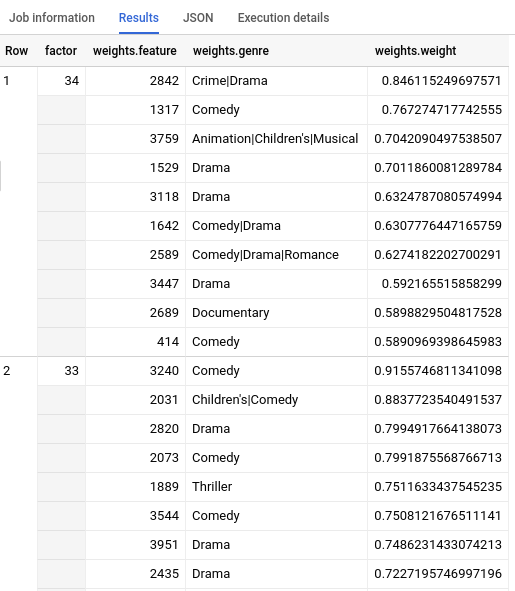
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus resource satu per satu.
- Anda dapat menghapus project yang dibuat.
- Atau, Anda dapat menyimpan project dan menghapus set data.
Menghapus set data
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan project tersebut lagi, Anda dapat menghapus set data yang Anda buat dalam tutorial ini:
Jika perlu, buka halaman BigQuery di konsol Google Cloud.
Di navigasi, klik set data bqml_tutorial yang telah Anda buat.
Klik Delete dataset di sisi kanan jendela. Tindakan ini akan menghapus set data, tabel, dan semua data.
Di kotak dialog Delete dataset, konfirmasi perintah hapus dengan mengetikkan nama set data Anda (
bqml_tutorial), lalu klik Delete.
Menghapus project Anda
Untuk menghapus project:
- Di konsol Google Cloud, buka halaman Manage resource.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Langkah selanjutnya
- Untuk mempelajari machine learning lebih lanjut, lihat Kursus singkat machine learning.
- Untuk ringkasan BigQuery ML, lihat Pengantar BigQuery ML.
- Untuk mempelajari konsol Google Cloud lebih lanjut, lihat Menggunakan konsol Google Cloud.