Diese Anleitung bietet eine Einführung zum Matrixfaktorisierungsmodell in BigQuery ML für Datenanalysten. Mit BigQuery ML haben Nutzer die Möglichkeit, mit SQL-Abfragen Modelle für maschinelles Lernen in BigQuery zu erstellen und auszuführen. Da SQL-Experten mithilfe von BigQuery ML Modelle unter Verwendung vorhandener Tools erstellen und schneller entwickeln können, ohne dabei Daten bewegen zu müssen, wird das maschinelle Lernen demokratisiert.
In dieser Anleitung wird gezeigt, wie Sie mithilfe des Datasets movielens1m ein Modell mit explizitem Feedback erstellen, um mithilfe einer Film-ID und einer Nutzer-ID Empfehlungen abzugeben.
Das MovieLens-Dataset enthält die von Nutzern abgegebenen Bewertungen zu Filmen auf einer Skala von 1 bis 5 sowie Metadaten zum Film, z. B. sein Genre.
Lernziele
In dieser Anleitung verwenden Sie:
- BigQuery ML zum Erstellen eines expliziten Empfehlungsmodells mithilfe der
CREATE MODEL-Anweisung - Die
ML.EVALUATE-Funktion zum Bewerten der ML-Modelle - Die
ML.WEIGHTS-Funktion zum Prüfen der während des Trainings generierten Gewichtungen für latente Faktoren - Die
ML.RECOMMEND-Funktion zum Erstellen von Empfehlungen für einen Nutzer
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloud verwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten für BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweis
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Zum Aktivieren von BigQuery in einem vorhandenen Projekt wechseln Sie zu
BigQuery API aktivieren.
.
Schritt 1: Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Die öffentlichen Datasets sind am multiregionalen Standort
USgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Standort speichern.Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.

Schritt 2: MovieLens-Dataset in BigQuery laden
Führen Sie die folgenden Schritte aus, um das Dataset "1m MovieLens" mithilfe der BigQuery-Befehlszeilentools in BigQuery zu laden.
Dabei wird ein Dataset mit dem Namen movielens erstellt und die erforderlichen MovieLens-Tabellen werden darin gespeichert.
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
Da die Filmtitel Doppelpunkte, Kommas und senkrechte Striche enthalten, muss ein anderes Trennzeichen genutzt werden. Zum Laden der Filmtitel wird eine geringfügig veränderte Variante der letzten beiden Befehle verwendet.
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
Schritt 3: Explizites Empfehlungsmodell erstellen
Als Nächstes erstellen Sie ein explizites Empfehlungsmodell mithilfe der MovieLens-Beispieltabelle, die im vorherigen Schritt geladen wurde. Mit der folgenden GoogleSQL-Abfrage wird das Modell erstellt, mit dem eine Bewertung für jedes Nutzer/Artikel-Paar vorhergesagt wird.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Durch Ausführen des Befehls CREATE MODEL wird das Modell, das Sie erstellen, außerdem trainiert.
Abfragedetails
Das Modell bqml_tutorial.my_explicit_mf_model wird mit der Klausel CREATE MODEL erstellt und trainiert.
Die Klausel OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) gibt an, dass ein Matrixfaktorisierungsmodell angelegt wird. Standardmäßig wird dadurch ein explizites Matrixfaktorisierungsmodell erstellt, sofern nicht feedback_type='IMPLICIT' festgelegt ist. Ein Beispiel für das Erstellen eines impliziten Matrixfaktorisierungsmodells wird unter Mit BigQuery ML Empfehlungen für implizites Feedback abgeben erläutert.
Die SELECT-Anweisung dieser Abfrage generiert Empfehlungen anhand der folgenden Spalten:
user_id: Die Nutzer-ID (INT64).item_id: Die Film-ID (INT64).rating: Die explizite Bewertung von 1 bis 5, dieuser_idfüritem_id(FLOAT64) abgegeben hat.
Die FROM-Klausel – movielens.movielens_1m – gibt an, dass Sie die Tabelle movielens_1m im Dataset movielens abfragen.
Dieses Dataset befindet sich in Ihrem BigQuery-Projekt, wenn Sie Schritt 2 der Anleitung ausgeführt haben.
Abfrage CREATE MODEL ausführen
So führen Sie die Abfrage CREATE MODEL zum Erstellen und Trainieren des Modells aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Klicken Sie auf Ausführen.
Die Abfrage dauert etwa zehn Minuten. Anschließend wird das Modell (
my_explicit_mf_model) im Navigationsbereich der Google Cloud Console angezeigt. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, werden keine Abfrageergebnisse ausgegeben.
Schritt 4 (optional): Trainingsstatistiken abrufen
Mit der Funktion ML.TRAINING_INFO können Sie die Ergebnisse des Modelltrainings abrufen. Alternativ lassen sich die Statistiken auch in der Google Cloud Console abrufen. In dieser Anleitung verwenden Sie die Google Cloud Console.
Ein Algorithmus für maschinelles Lernen erstellt ein Modell durch Analyse vieler Beispiele. Ziel ist es, ein Modell zu finden, das den Verlust so weit wie möglich minimiert. Dieser Vorgang wird als empirische Risikominimierung bezeichnet.
So können Sie die Statistiken zum Modelltraining ansehen, die beim Ausführen der CREATE MODEL-Abfrage erzeugt wurden:
Maximieren Sie im Navigationsbereich der Google Cloud Console im Abschnitt Ressourcen den Bereich [PROJECT_ID] > bqml_tutorial und klicken Sie dann auf my_explicit_mf_model.
Klicken Sie auf den Tab Training und dann auf Tabelle. Das Ergebnis sollte in etwa so aussehen:

Die Spalte Trainingsdatenverlust enthält den Verlustmesswert, der berechnet wird, nachdem das Modell mit dem Trainings-Dataset trainiert wurde. Da Sie die Matrixfaktorisierung ausgeführt haben, enthält diese Spalte die mittlere quadratische Abweichung. Standardmäßig werden die Daten bei Matrixfaktorisierungsmodellen nicht aufgeteilt, sodass die Spalte Evaluationsdatenverlust nur dann vorhanden ist, wenn ein Holdout-Dataset angegeben wird. Dies liegt daran, dass durch Aufteilung der Daten alle Bewertungen eines Nutzers oder Artikels verloren gehen können. Daher enthält das Modell keine Informationen zu latenten Faktoren über fehlende Nutzer oder Artikel.
Weitere Informationen zur Funktion
ML.TRAINING_INFOfinden Sie in der Syntaxreferenz zu BigQuery ML.
Schritt 5: Modell bewerten
Nachdem Sie das Modell erstellt haben, können Sie mit der Funktion ML.EVALUATE die Leistung des Recommenders bewerten. Die ML.EVALUATE-Funktion bewertet die vorhergesagten Bewertungen gegenüber den tatsächlichen Bewertungen.
Zur Bewertung des Modells wird folgende Abfrage verwendet:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id,
item_id,
rating
FROM
`movielens.movielens_1m`))
Abfragedetails
Die oberste SELECT-Anweisung ruft die Spalten aus dem Modell ab.
In der FROM-Klausel wird die Funktion ML.EVALUATE für das Modell bqml_tutorial.my_explicit_mf_model verwendet.
Die geschachtelte SELECT-Anweisung und die FROM-Klausel dieser Abfrage sind dieselben wie in der Abfrage CREATE MODEL.
Sie können ML.EVALUATE auch aufrufen, ohne die Eingabedaten anzugeben. Es werden dann die Bewertungsmesswerte verwendet, die während des Trainings berechnet wurden:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
Abfrage ML.EVALUATE ausführen
So führen Sie die ML.EVALUATE-Abfrage zur Bewertung des Modells aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
(Optional) Klicken Sie auf More (Mehr) > Query settings (Abfrageeinstellungen), um den Verarbeitungsstandort festzulegen. Wählen Sie als Verarbeitungsstandort
USaus. Dieser Schritt ist optional, da der Verarbeitungsstandort anhand des Standorts des Datasets automatisch erkannt wird.
Klicken Sie auf Ausführen.
Sobald die Abfrage abgeschlossen ist, klicken Sie unterhalb des Textbereichs der Abfrage auf den Tab Ergebnisse. Die Ergebnisse sollten in etwa so aussehen:

Da Sie eine explizite Matrixfaktorisierung durchgeführt haben, enthalten die Ergebnisse die folgenden Spalten:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Ein wichtiger Messwert in den Bewertungsergebnissen ist der R2-Wert. Der R2-Wert ist ein statistisches Maß dafür, ob sich die Vorhersagen der linearen Regression den tatsächlichen Daten annähern. 0 gibt an, dass das Modell keine Erklärung für die Variabilität der Antwortdaten um den Mittelwert liefert. 1 gibt an, dass das Modell eine Erklärung für die gesamte Variabilität der Antwortdaten um den Mittelwert liefert.
Schritt 6: Anhand des Modells Bewertungen vorhersagen und Empfehlungen abgeben
Alle Artikelbewertungen für eine Gruppe von Nutzern suchen
Für ML.RECOMMEND sind neben dem Modell keine weiteren Argumente erforderlich. Es kann aber optional eine Tabelle verwendet werden. Wenn die Eingabetabelle nur eine Spalte enthält, die mit dem Namen der Eingabespalte für den user oder item übereinstimmt, werden alle vorhergesagten Artikelbewertungen für jeden user ausgegeben (und umgekehrt). Wenn sich alle users oder alle items in der Eingabetabelle befinden, werden die gleichen Ergebnisse wie ohne optionales Argument für ML.RECOMMEND ausgegeben.
Das folgende Beispiel zeigt eine Abfrage zum Abrufen aller vorhergesagten Filmbewertungen für fünf Nutzer:
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id
FROM
`movielens.movielens_1m`
LIMIT 5))
Abfragedetails
Die obere SELECT-Anweisung ruft die Spalten user, item und predicted_rating ab.
Die letzte Spalte wird von der ML.RECOMMEND-Funktion generiert. Wenn Sie die ML.RECOMMEND-Funktion verwenden, lautet der Name der Ausgabespalte für das Modell predicted_<rating_column_name>. Bei expliziten Matrixfaktorisierungsmodellen ist predicted_rating der geschätzte Wert von rating.
Mit der ML.RECOMMEND-Funktion werden Bewertungen anhand des Modells bqml_tutorial.my_explicit_mf_model vorhergesagt.
Die verschachtelte SELECT-Anweisung dieser Abfrage wählt nur die Spalte user_id aus der ursprünglichen Tabelle aus, die für das Training verwendet wird.
Die LIMIT-Klausel – LIMIT 5 – filtert nach dem Zufallsprinzip fünf user_id aus, die an ML.RECOMMEND gesendet werden sollen.
Bewertungen für alle Nutzer/Artikel-Paare suchen
Nachdem Sie nun Ihr Modell bewertet haben, wird damit im nächsten Schritt eine Bewertung von Nutzern/Artikeln vorhergesagt. Sie verwenden dieses Modell, um die Bewertung jeder einzelnen Nutzer/Artikel-Kombination in der folgenden Abfrage vorherzusagen:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Abfragedetails
Die obere SELECT-Anweisung ruft die Spalten user, item und predicted_rating ab.
Die letzte Spalte wird von der ML.RECOMMEND-Funktion generiert. Wenn Sie die ML.RECOMMEND-Funktion verwenden, lautet der Name der Ausgabespalte für das Modell predicted_<rating_column_name>. Bei expliziten Matrixfaktorisierungsmodellen ist predicted_rating der geschätzte Wert von rating.
Mit der ML.RECOMMEND-Funktion werden Bewertungen anhand des Modells bqml_tutorial.my_explicit_mf_model vorhergesagt.
Sie können beispielsweise so das Ergebnis in der Tabelle speichern:
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Wenn der Fehler Query Exceeded Resource Limits für ML.RECOMMEND auftritt, versuchen Sie es mit einer höheren Abrechnungsstufe. Diese kann im BigQuery-Befehlszeilentool mit dem Flag --maximum_billing_tier festgelegt werden.
Empfehlungen generieren
Mit der vorherigen Empfehlungsabfrage können wir nach der vorhergesagten Bewertung sortieren und die am häufigsten vorhergesagten Artikel für jeden Nutzer ausgeben. Die folgende Abfrage verknüpft item_ids mit movie_ids aus der zuvor hochgeladenen Tabelle movielens.movie_titles und gibt die fünf am häufigsten empfohlenen Filme pro Nutzer aus.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
Abfragedetails
Die innere SELECT-Anweisung führt einen Inner Join für item_id aus der Tabelle mit den Empfehlungsergebnissen und für movie_id aus der Tabelle movielens.movie_titles aus. movielens.movie_titles ordnet movie_id nicht nur einem Filmnamen zu, sondern enthält auch die von der IMDB angegebenen Genres des Films.
Die obere SELECT-Anweisung aggregiert die Ergebnisse der verschachtelten SELECT-Anweisung. Dazu führt sie movie_title,
genre, und predicted_rating mithilfe von GROUPS BY user_id in absteigender Reihenfolge zusammen und behält nur die ersten fünf Filme bei.
Abfrage ML.RECOMMEND ausführen
So führen Sie die ML.RECOMMEND-Abfrage aus, die die fünf am häufigsten empfohlenen Filme pro Nutzer ausgibt:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Klicken Sie auf Ausführen.
Wenn die Abfrage abgeschlossen ist, wird im Navigationsbereich
bqml_tutorial.recommend_1mangezeigt. Da die Abfrage zum Erstellen einer Tabelle eineCREATE TABLE-Anweisung verwendet, werden die Abfrageergebnisse nicht ausgegeben.Erstellen Sie eine weitere neue Abfrage. Geben Sie die folgende GoogleSQL-Abfrage in den Textbereich des Abfrageeditors ein, sobald die vorherige Abfrage ausgeführt wurde.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
(Optional) Klicken Sie auf More (Mehr) > Query settings (Abfrageeinstellungen), um den Verarbeitungsstandort festzulegen. Wählen Sie als Verarbeitungsstandort
USaus. Dieser Schritt ist optional, da der Verarbeitungsstandort anhand des Standorts des Datasets automatisch erkannt wird. Klicken Sie auf Ausführen.
Sobald die Abfrage abgeschlossen ist, klicken Sie unterhalb des Textbereichs der Abfrage auf den Tab Ergebnisse. Die Ergebnisse sollten in etwa so aussehen:
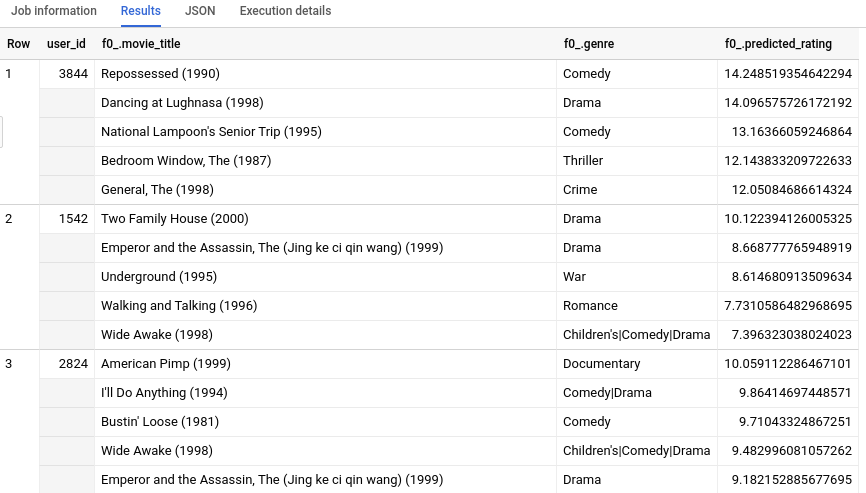
Da neben einem INT64-Wert zusätzliche Metadaten zu jeder movie_id verfügbar waren, können wir Informationen wie das Genre zu den fünf am häufigsten empfohlenen Filmen für jeden Nutzer abrufen. Wenn Sie keine entsprechende movietitles-Tabelle für Ihre Trainingsdaten haben, sind die Ergebnisse möglicherweise für Menschen nicht verständlich, da sie dann nur Zahlen-IDs oder Hashes enthalten.
Top-Genres pro Faktor
Wenn Sie wissen möchten, zu welchem Genre die einzelnen latenten Faktoren gehören, können Sie die folgende Abfrage ausführen:
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
Abfragedetails
Die innere SELECT-Anweisung ruft die item_id oder das Array mit den Gewichtungen für Filmfaktoren ab und verknüpft die Werte mit der Tabelle movielens.movie_titles, um das Genre jeder Artikel-ID abzurufen.
Das Ergebnis dieser Anweisung wird dann per CROSS JOIN mit jedem factor_weights-Array verbunden, das als Ergebnis ORDER BY feature, weight DESC ausgibt.
Schließlich fasst die obere SELECT-Anweisung die Ergebnisse aus der inneren Anweisung nach factor zusammen und erstellt ein Array für jeden Faktor, sortiert nach der Gewichtung der einzelnen Genres.
Abfrage ausführen
So führen Sie die obige Abfrage aus, die die zehn beliebtesten Filmgenres pro Faktor ausgibt:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
(Optional) Klicken Sie auf More (Mehr) > Query settings (Abfrageeinstellungen), um den Verarbeitungsstandort festzulegen. Wählen Sie als Verarbeitungsstandort
USaus. Dieser Schritt ist optional, da der Verarbeitungsstandort anhand des Standorts des Datasets automatisch erkannt wird. Klicken Sie auf Ausführen.
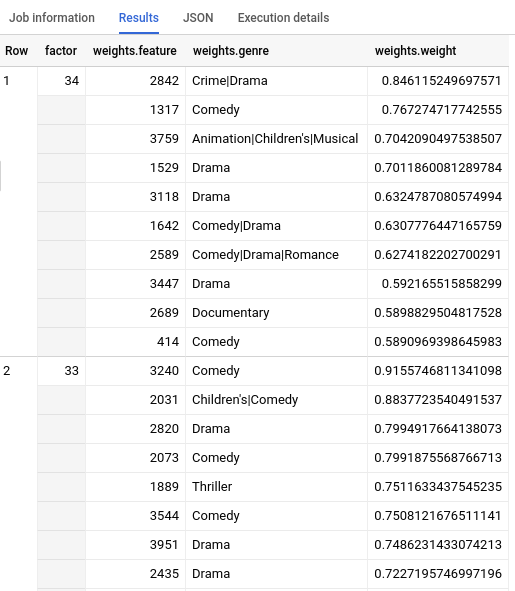
Sobald die Abfrage abgeschlossen ist, klicken Sie unterhalb des Textbereichs der Abfrage auf den Tab Ergebnisse. Die Ergebnisse sollten in etwa so aussehen:
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite "BigQuery" in der Google Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Dataset löschen. Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Weitere Informationen über das maschinelle Lernen im Machine Learning Crash Course lesen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in BigQuery ML.
- Weitere Informationen zur Google Cloud Console finden Sie unter Google Cloud Console verwenden.