In questo tutorial imparerai ad accelerare l'addestramento di un set di modelli di serie temporali per eseguire più previsioni di serie temporali con una singola query. Imparerai inoltre a valutare la precisione delle previsioni.
Per tutti i passaggi tranne l'ultimo, utilizzerai i dati di new_york.citibike_trips.
Questi dati contengono informazioni sulle corse Citi Bike a New York. Questo set di dati contiene solo poche centinaia di serie temporali. Viene usato per illustrare
varie strategie per accelerare l'addestramento del modello.
Nell'ultimo passaggio, utilizzerai i dati di iowa_liquor_sales.sales per prevedere più di un milione di serie temporali.
Prima di leggere questo tutorial, dovresti leggere Eseguire previsioni di più serie temporali con una singola query dai dati delle corse NYC Citi Bike. Dovresti anche leggere l'articolo Best practice per la previsione di serie temporali su larga scala.
Obiettivi
In questo tutorial, utilizzerai:
- L'istruzione
CREATE MODELcrea un modello di serie temporale o un insieme di modelli di serie temporali. - La funzione
ML.EVALUATEvaluta l'accuratezza della previsione. - Opzioni di addestramento di
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTHeMAX_TIME_SERIES_LENGTH: per ridurre notevolmente il tempo di addestramento dei modelli.
Per semplicità, questo tutorial non spiega come utilizzare ML.FORECAST o ML.EXPLAIN_FORECAST
per generare previsioni (spiegabili). Per informazioni su come utilizzare queste funzioni, consulta
Esecuzione di più previsioni di serie temporali con una singola query dai dati delle corse NYC Citi Bike.
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi, consulta la pagina Prezzi di BigQuery e la pagina Prezzi di BigQuery ML.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
- BigQuery viene abilitato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Attiva l'API BigQuery.
Passaggio 1: crea il set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML:
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.

Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Più regioni e poi Stati Uniti (più regioni negli Stati Uniti).
I set di dati pubblici sono archiviati in
USpiù regioni. Per semplicità, memorizza il set di dati nella stessa posizione.Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.

Passaggio 2: crea le serie temporali di cui eseguire la previsione
Nella query seguente, la clausola FROM bigquery-public-data.new_york.citibike_trips indica che stai eseguendo una query sulla tabella citibike_trips nel new_yorkset di dati.
CREATE OR REPLACE TABLE
`bqml_tutorial.nyc_citibike_time_series` AS
WITH input_time_series AS
(
SELECT
start_station_name,
EXTRACT(DATE FROM starttime) AS date,
COUNT(*) AS num_trips
FROM
`bigquery-public-data.new_york.citibike_trips`
GROUP BY
start_station_name, date
)
SELECT table_1.*
FROM input_time_series AS table_1
INNER JOIN (
SELECT start_station_name, COUNT(*) AS num_points
FROM input_time_series
GROUP BY start_station_name) table_2
ON
table_1.start_station_name = table_2.start_station_name
WHERE
num_points > 400
Per eseguire la query, segui questi passaggi:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la query GoogleSQL riportata sopra nell'area di testo Editor query.
Fai clic su Esegui.
L'istruzione SELECT nella query utilizza la
funzione EXTRACT
per estrarre le informazioni sulla data dalla colonna starttime. La query utilizza la clausola COUNT(*) per ottenere il numero totale giornaliero di corse Citi Bike.
table_1 ha 679 serie temporali. La query utilizza una logica INNER JOIN aggiuntiva per selezionare tutte le serie temporali che hanno più di 400 punti temporali, per un totale di 383 serie temporali.
Passaggio 3: esegui previsioni simultanee di più serie temporali con parametri predefiniti
In questo passaggio puoi prevedere il numero totale giornaliero di corse a partire da diverse stazioni di Citi Bike. A tal fine, devi prevedere molte serie temporali.
Potresti scrivere più query CREATE MODEL, ma questo può essere un processo noioso e dispendioso in termini di tempo, soprattutto se hai un numero elevato di serie temporali.
Per migliorare questo processo, BigQuery ML consente di creare un insieme di modelli di serie temporali per prevedere più serie temporali utilizzando una singola query. Inoltre, tutti i modelli delle serie temporali vengono adattati contemporaneamente.
Nella seguente query GoogleSQL, la clausola CREATE MODEL crea e addestra un insieme di modelli denominati bqml_tutorial.nyc_citibike_arima_model_default.
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01'
Per eseguire la query CREATE MODEL al fine di creare e addestrare il modello, segui questi passaggi:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la query GoogleSQL riportata sopra nell'area di testo Editor query.
Fai clic su Esegui.
Il completamento della query richiede circa 14 minuti e 25 secondi.
La clausola OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica che stai creando un insieme di modelli
delle serie temporali ARIMA_PLUS basati su
ARIMA. Oltre a time_series_timestamp_col e
time_series_data_col, devi specificare time_series_id_col, che viene utilizzato per
annotare diverse serie temporali di input.
Questo esempio esclude i punti temporali delle serie temporali successive al 1° giugno 2016 in modo che possano essere utilizzati per valutare l'accuratezza della previsione in un secondo momento utilizzando la funzione ML.EVALUATE.
Passaggio 4: valuta l'accuratezza delle previsioni per ogni serie temporale
In questo passaggio, potrai valutare l'accuratezza della previsione per ogni serie temporale utilizzando la seguente query ML.EVALUATE.
SELECT *
FROM
ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`,
TABLE `bqml_tutorial.nyc_citibike_time_series`,
STRUCT(7 AS horizon, TRUE AS perform_aggregation))
Per eseguire la query precedente, segui questi passaggi:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la query GoogleSQL riportata sopra nell'area di testo Editor query.
Fai clic su Esegui. Questa query riporta diverse metriche di previsione, tra cui:
- errore assoluto medio
- errore quadratico medio
- errore percentuale assoluto medio
- errore percentuale assoluto simmetrico medio
I risultati dovrebbero avere il seguente aspetto:
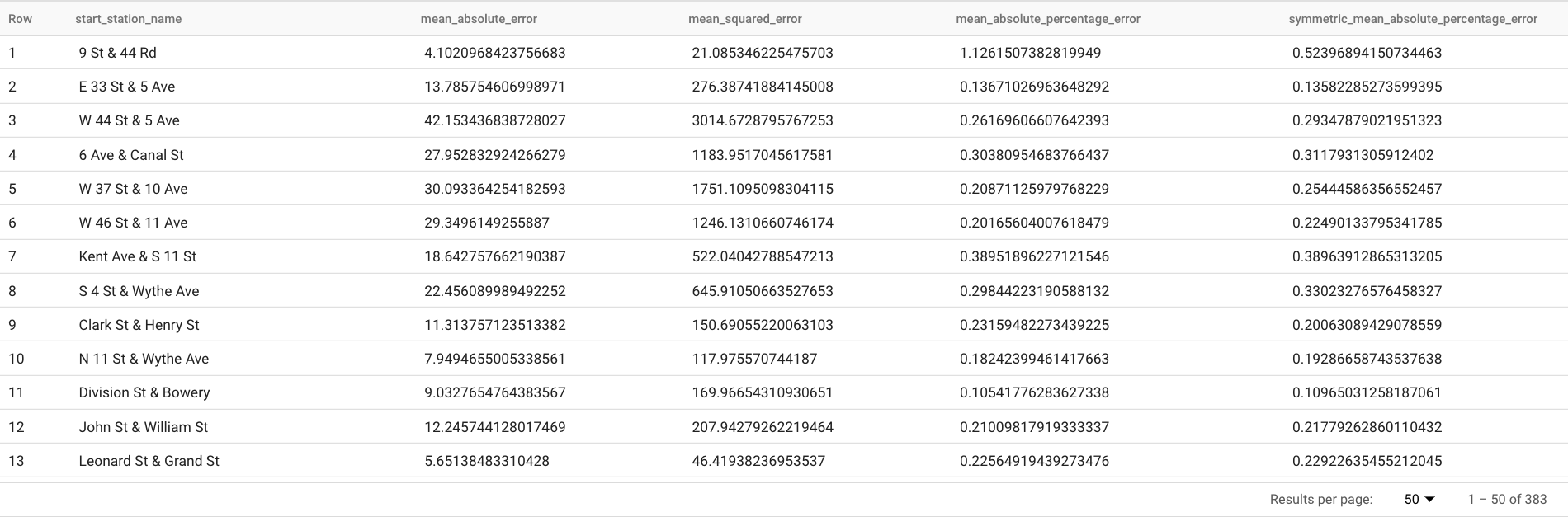
ML.EVALUATE prende come primo argomento il modello ARIMA_PLUS addestrato nel passaggio precedente.
Il secondo argomento è una tabella contenente dati empirici reali. I risultati delle previsioni vengono confrontati con dati empirici reali per calcolare le metriche di accuratezza. In questo caso, l'elemento nyc_citibike_time_series contiene sia
i punti delle serie temporali precedenti al 1° giugno 2016 sia quelli successivi al 1° giugno 2016. I punti successivi al 1° giugno 2016 sono i dati empirici reali. I punti precedenti al 1° giugno 2016 vengono utilizzati per addestrare il modello per generare previsioni dopo questa data.
Per calcolare le metriche sono necessari solo i punti successivi al 1° giugno 2016. I punti precedenti al 1° giugno 2016 vengono ignorati nel calcolo delle metriche.
Il terzo argomento è un elemento STRUCT che contiene due parametri. L'orizzonte è 7, il che significa che la query calcola l'accuratezza della previsione in base alla previsione a 7 punti. Tieni presente che, se i dati empirici reali hanno meno di 7 punti per il confronto, le metriche di accuratezza vengono calcolate solo in base ai punti disponibili. perform_aggregation ha un valore di TRUE, il che significa che le metriche di accuratezza della previsione vengono aggregate sopra le metriche sulla base del punto temporale. Se specifichi perform_aggregation come FALSE, viene restituita la precisione della previsione per ogni punto temporale previsto.
Passaggio 5: valuta l'accuratezza generale delle previsioni per tutte le serie temporali
In questo passaggio, valuterai la precisione della previsione per l'intera serie temporale 383 utilizzando la seguente query:
SELECT
AVG(mean_absolute_percentage_error) AS MAPE,
AVG(symmetric_mean_absolute_percentage_error) AS sMAPE
FROM
ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`,
TABLE `bqml_tutorial.nyc_citibike_time_series`,
STRUCT(7 AS horizon, TRUE AS perform_aggregation))
Delle metriche di previsione restituite da ML.EVALUATE, solo l'errore percentuale assoluto medio e l'errore percentuale assoluto medio simmetrico sono indipendenti dal valore delle serie temporali. Pertanto, per valutare l'intera precisione delle previsioni di un insieme di serie temporali, è significativo solo l'aggregazione di queste due metriche.
Questa query restituisce i seguenti risultati: MAPE è 0,3471, sMAPE è 0,2563.
Passaggio 6: prevedi più serie temporali contemporaneamente utilizzando uno spazio di ricerca degli iperparametri più piccolo
Nel passaggio 3, abbiamo utilizzato i valori predefiniti per tutte le opzioni di addestramento, incluso auto_arima_max_order. Questa opzione controlla lo spazio di ricerca per l'ottimizzazione degli iperparametri nell'algoritmo auto.ARIMA.
In questo passaggio, utilizzerai uno spazio di ricerca più ridotto per gli iperparametri.
CREATE OR REPLACE MODELbqml_tutorial.nyc_citibike_arima_model_max_order_2OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROMbqml_tutorial.nyc_citibike_time_seriesWHERE date < '2016-06-01'
Questa query riduce auto_arima_max_order da 5 (valore predefinito) a 2.
Per eseguire la query, segui questi passaggi:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la query GoogleSQL riportata sopra nell'area di testo Editor query.
Fai clic su Esegui.
Il completamento della query richiede circa 1 minuto e 45 secondi. Ricorda che il completamento della query richiede 14 minuti e 25 secondi se
auto_arima_max_orderè 5. L'aumento della velocità è di circa 7 volte impostandoauto_arima_max_ordersu 2. Se ti chiedi perché il guadagno di velocità non è 5/2=2,5 volte, è perché, quando si aumenta l'ordine diauto_arima_max_order, non solo aumenta il numero di modelli candidati, ma anche la complessità per cui aumenta il tempo di addestramento dei modelli.
Passaggio 7: valuta l'accuratezza della previsione in base a uno spazio di ricerca iperparametri più piccolo
SELECT
AVG(mean_absolute_percentage_error) AS MAPE,
AVG(symmetric_mean_absolute_percentage_error) AS sMAPE
FROM
ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`,
TABLE `bqml_tutorial.nyc_citibike_time_series`,
STRUCT(7 AS horizon, TRUE AS perform_aggregation))
Questa query restituisce i seguenti risultati: MAPE è 0,3337 e sMAPE è 0,2337.
Nel passaggio cinque, utilizzando uno spazio di ricerca iperparametri più grande, auto_arima_max_order = 5, ha generato MAPE 0,3471 e sMAPE 0,2563.
Pertanto, in questo caso, uno spazio di ricerca degli iperparametri più piccolo offre effettivamente una maggiore precisione delle previsioni. Uno
dei motivi è che l'algoritmo auto.ARIMA esegue l'ottimizzazione degli iperparametri solo
per il modulo delle tendenze dell'intera pipeline di modellazione. Il miglior modello ARIMA selezionato dall'algoritmo auto.ARIMA potrebbe non generare i risultati di previsione migliori per l'intera pipeline.
Passaggio 8: prevedi molte serie temporali contemporaneamente con uno spazio di ricerca degli iperparametri più ridotto e strategie di addestramento rapido intelligente
In questo passaggio, utilizzerai sia uno spazio di ricerca iperparametri più piccolo sia la strategia di addestramento rapido intelligente utilizzando una o più opzioni di addestramento max_time_series_length, max_time_series_length o time_series_length_fraction.
Mentre la modellazione periodica come la stagionalità richiede un determinato numero di punti temporali, la modellazione delle tendenze richiede meno punti temporali. Nel frattempo, la modellazione delle tendenze è molto più costosa dal punto di vista del calcolo rispetto ad altri componenti delle serie temporali, come la stagionalità. Utilizzando le opzioni di addestramento rapido sopra riportate, puoi modellare in modo efficiente il componente di tendenza con un sottoinsieme della serie temporale, mentre gli altri componenti della serie temporale utilizzano l'intera serie temporale.
Questo esempio utilizza max_time_series_length per ottenere un addestramento rapido.
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01'
L'opzione max_time_series_length ha un valore pari a 30, pertanto per ciascuna delle 383 serie temporali vengono utilizzati solo i 30 punti temporali più recenti per modellare il componente di tendenza. Tutte le serie temporali vengono comunque utilizzate per modellare i componenti non di tendenza.
Per eseguire la query, segui questi passaggi:
Nella console Google Cloud, fai clic sul pulsante Crea nuova query.
Inserisci la query GoogleSQL riportata sopra nell'area di testo Editor query.
Fai clic su Esegui.
Il completamento della query richiede circa 35 secondi. È tre volte più veloce rispetto alla query di addestramento che non utilizza una strategia di addestramento veloce (ovvero, richiede 1 minuto e 45 secondi). Tieni presente che a causa del costante overhead per la parte della query non di addestramento, come la pre-elaborazione dei dati e così via, l'aumento della velocità sarà molto più elevato se il numero di serie temporali è molto maggiore rispetto a questo caso. Per un milione di serie temporali, il guadagno di velocità si avvicinerà al rapporto tra la durata della serie temporale e il valore max_time_series_length. In questo caso, il guadagno di velocità sarà maggiore di 10x.
Passaggio 9: valuta l'accuratezza delle previsioni per un modello con uno spazio di ricerca degli iperparametri più ridotto e strategie di addestramento rapido intelligente
SELECT
AVG(mean_absolute_percentage_error) AS MAPE,
AVG(symmetric_mean_absolute_percentage_error) AS sMAPE
FROM
ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`,
TABLE `bqml_tutorial.nyc_citibike_time_series`,
STRUCT(7 AS horizon, TRUE AS perform_aggregation))
Questa query restituisce i seguenti risultati: MAPE è 0,3515 e sMAPE è 0,2473.
Ricorda che senza l'uso di strategie di addestramento rapido, i risultati di accuratezza della previsione sono MAPE 0,3337 e sMAPE 0,2337. La differenza tra le due serie di valori delle metriche rientra nel 3%, il che non è statisticamente significativo.
In breve, hai utilizzato uno spazio di ricerca degli iperparametri più ridotto e strategie di addestramento rapido intelligente per rendere l'addestramento del modello più di 20 volte più veloce senza sacrificare l'accuratezza della previsione. Come accennato in precedenza, con più serie temporali, l'aumento della velocità derivante dalle strategie di addestramento rapido intelligente può essere notevolmente maggiore. Inoltre, la libreria ARIMA di base utilizzata da ARIMA_PLUS è stata ottimizzata per un'esecuzione 5 volte più veloce rispetto a prima. Insieme, questi vantaggi consentono di prevedere milioni di serie temporali nell'arco di ore.
Passaggio 10: fai previsioni su un milione di serie temporali
In questo passaggio, prevedi le vendite di liquori di oltre 1 milione di liquori in negozi diversi utilizzando i dati pubblici sulle vendite di liquori dell'Iowa.
CREATE OR REPLACE MODEL
`bqml_tutorial.liquor_forecast_by_product`
OPTIONS(
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'item_description'],
HOLIDAY_REGION = 'US',
AUTO_ARIMA_MAX_ORDER = 2,
MAX_TIME_SERIES_LENGTH = 30
) AS
SELECT
store_number,
item_description,
date,
SUM(bottles_sold) as total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31")
GROUP BY store_number, item_description, date
L'addestramento del modello utilizza ancora un piccolo spazio di ricerca degli iperparametri e la strategia di addestramento rapido intelligente. Il completamento della query richiede circa 1 ora e 16 minuti.
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi mantenere il progetto ed eliminare il set di dati.
Elimina il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati che hai creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella console Google Cloud.
Nella barra di navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati per eliminare il set di dati, la tabella e tutti i dati.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial), quindi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Per saperne di più sul machine learning, consulta il Corso intensivo sul machine learning.
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per saperne di più sulla console Google Cloud, consulta Utilizzo della console Google Cloud.