このチュートリアルでは、epa_historical_air_quality データセットの次のサンプル テーブルを使用して、多変量時系列モデル(ARIMA_PLUS_XREG)を作成し、時系列予測を行う方法を学習します。
epa_historical_air_quality.pm25_nonfrm_daily_summaryサンプル テーブルepa_historical_air_quality.wind_daily_summaryサンプル テーブルepa_historical_air_quality.temperature_daily_summaryサンプル テーブル
epa_historical_air_quality データセットには、米国の複数の都市から毎日収集された PM 2.5、温度、風速の情報が含まれています。
目標
このチュートリアルでは、以下を使用します。
CREATE MODELステートメント: 時系列モデルを作成します。ML.ARIMA_EVALUATE関数: モデル内の ARIMA 関連の評価情報を検査します。ML.ARIMA_COEFFICIENTS関数: モデルの係数を検査します。ML.FORECAST関数: 毎日の PM 2.5 を予測します。ML.EVALUATE関数: 実際のデータでモデルを評価します。ML.EXPLAIN_FORECAST関数: 予測結果の説明に使用できる時系列のさまざまなコンポーネント(季節性、トレンド、特徴アトリビューションなど)を取得します。
料金
このチュートリアルでは、Google Cloud の課金対象となる次のコンポーネントを使用します。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
- Google Cloud アカウントにログインします。Google Cloud を初めて使用する場合は、アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
BigQuery API を有効にします。
にアクセスします。
ステップ 1: データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。

[データセットの作成] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(multiple regions in United States)] を選択します。
一般公開データセットは
USマルチリージョンに保存されています。わかりやすくするため、データセットを同じロケーションに保存します。残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
![[データセットの作成] ページ。](https://cloud.google.com/static/bigquery/images/create-dataset-bqml.png?hl=ja)
ステップ 2: 追加特徴を使用して時系列テーブルを作成する
PM2.5、気温、風速のデータは、別々のテーブルにあります。次のクエリを簡素化するために、これらのテーブルを次の列で結合して、新しいテーブル bqml_tutorial.seattle_air_quality_daily を作成します。
- date: 観測日
- PM2.5: 各日の PM2.5 の平均値
- wind_speed: 各日の平均風速
- temperature: 各日の最高気温
新しいテーブルには、2009 年 8 月 11 日から 2022 年 1 月 31 日までの日次データが含まれます。
次の GoogleSQL クエリでは、FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary 句で epa_historical_air_quality データセット内の *_daily_summary テーブルに対してクエリを実行しています。これらのテーブルはパーティション分割テーブルです。
#standardSQL
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily`
AS
WITH
pm25_daily AS (
SELECT
avg(arithmetic_mean) AS pm25, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary`
WHERE
city_name = 'Seattle'
AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass'
GROUP BY date_local
),
wind_speed_daily AS (
SELECT
avg(arithmetic_mean) AS wind_speed, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.wind_daily_summary`
WHERE
city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant'
GROUP BY date_local
),
temperature_daily AS (
SELECT
avg(first_max_value) AS temperature, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.temperature_daily_summary`
WHERE
city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature'
GROUP BY date_local
)
SELECT
pm25_daily.date AS date, pm25, wind_speed, temperature
FROM pm25_daily
JOIN wind_speed_daily USING (date)
JOIN temperature_daily USING (date)
クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、前述の GoogleSQL クエリを入力します。
[実行] をクリックします。
ステップ 3(省略可): 予測する時系列を可視化する
モデルを作成する前に、入力時系列がどのように表示されるかを確認しておきましょう。これは、Looker Studio を使用して行います。
次の GoogleSQL クエリでは、FROM bqml_tutorial.seattle_air_quality_daily 句は作成した bqml_tutorial データセットの seattle_air_quality_daily テーブルに対してクエリを実行しています。
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
[実行] をクリックします。
クエリを実行すると、次のスクリーンショットのような出力が表示されます。スクリーンショットを見ると、この時系列には 3,960 個のデータポイントがあります。[データを探索] ボタンをクリックして、[Looker Studio で調べる] をクリックします。Looker Studio が新しいタブで開きます。新しいタブで次の操作を行います。
[グラフ] パネルで [時系列グラフ] を選択します。
[設定] パネルで、[グラフ] パネルの下にある [指標] セクションに移動します。pm25、temperature、wind_speed の各フィールドを追加してから、デフォルトの指標であるレコード数を削除します。カスタムの期間を設定することもできます。たとえば、時系列を短くして、2019 年 1 月 1 日から 2021 年 12 月 31 日までに設定できます。次の図のようになります。
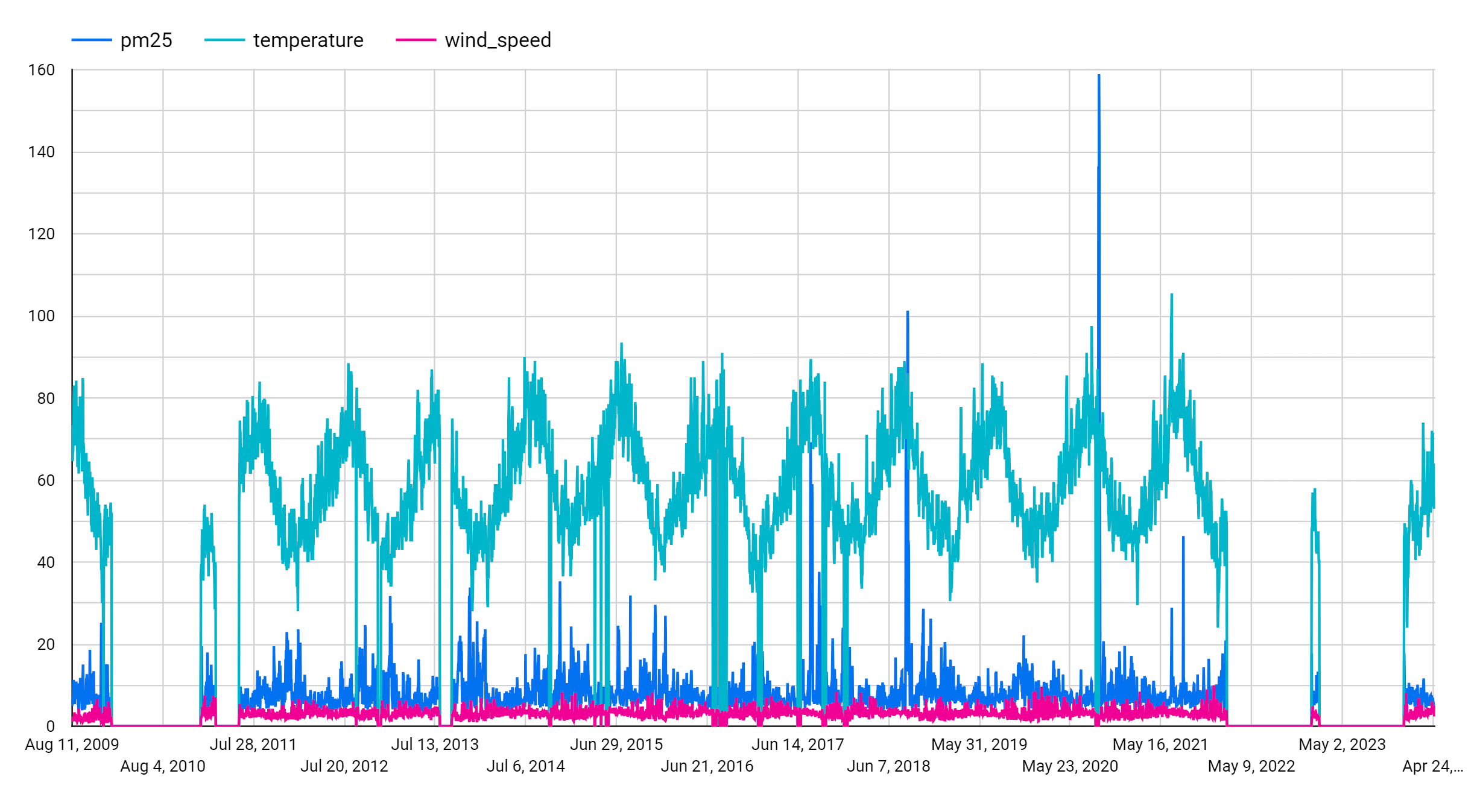
これらの手順を完了すると、次のグラフが表示されます。このグラフでは、入力時系列が週単位のパターンで表示されています。
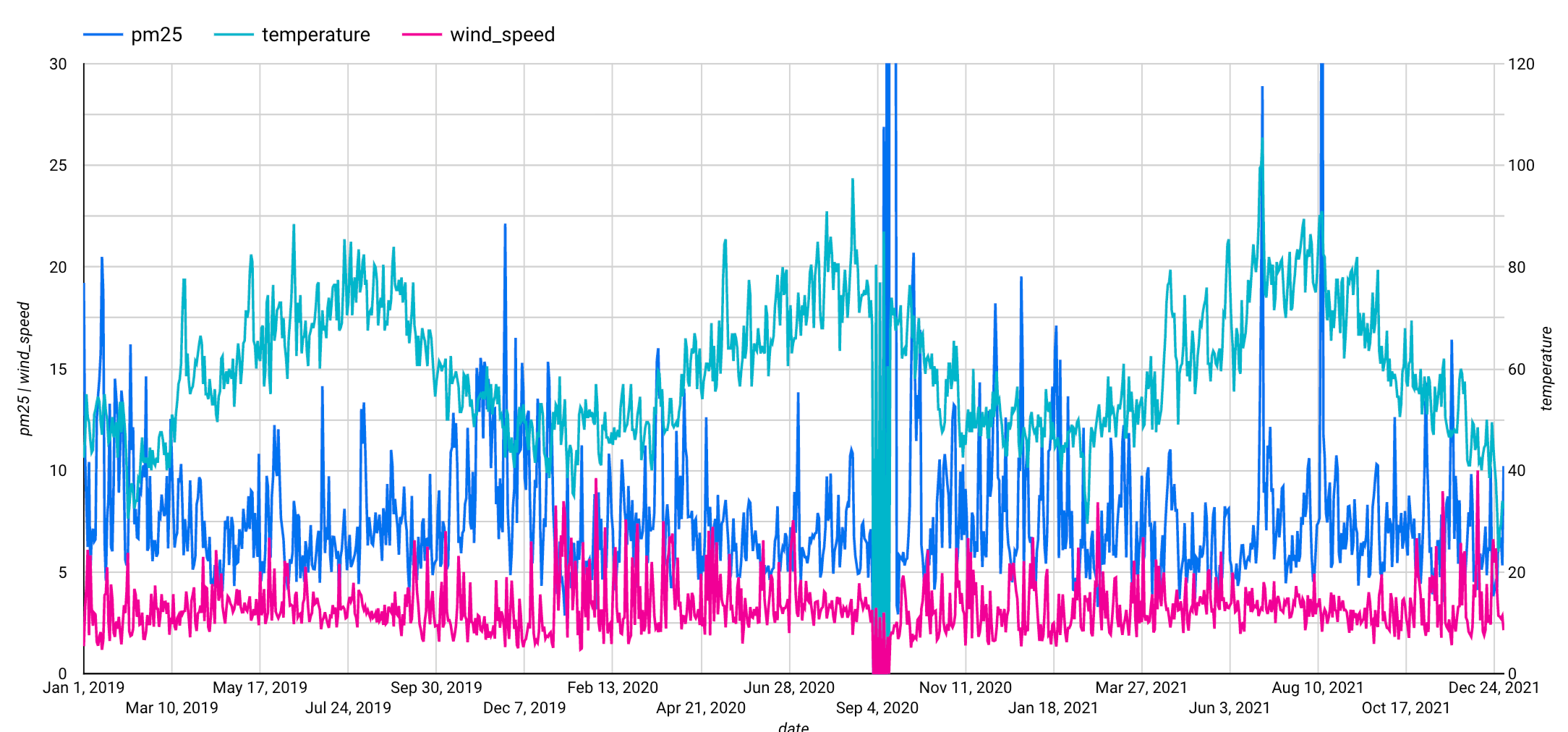
ステップ 4: 時系列モデルを作成する
次に、前述の大気質データを使用して時系列モデルを作成します。次の GoogleSQL クエリでは、pm25 の予測に使用するモデルを作成します。
CREATE MODEL 句で bqml_tutorial.seattle_pm25_xreg_model という名前のモデルを作成してトレーニングします。
#standardSQL
CREATE OR REPLACE
MODEL
`bqml_tutorial.seattle_pm25_xreg_model`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS_XREG',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25')
AS
SELECT
date,
pm25,
temperature,
wind_speed
FROM
`bqml_tutorial.seattle_air_quality_daily`
WHERE
date
BETWEEN DATE('2012-01-01')
AND DATE('2020-12-31')
OPTIONS(model_type='ARIMA_PLUS_XREG', time_series_timestamp_col='date', ...) 句は、外部リグレッサー モデルの ARIMA を作成することを示します。デフォルトは auto_arima=TRUE であるため、auto.ARIMA アルゴリズムによって ARIMA_PLUS_XREG モデルのハイパーパラメータが自動的に調整されます。アルゴリズムが多数の候補モデルを学習し、Akaike information criterion(AIC)が最も低い最適なモデルを選択します。また、data_frequency='AUTO_FREQUENCY' がデフォルトのため、トレーニング プロセスでは入力時系列のデータ頻度が自動的に推定されます。
CREATE MODEL クエリを実行してモデルを作成し、トレーニングします。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、前述の GoogleSQL クエリを入力します。
[実行] をクリックします。
クエリが完了するまでに 20 秒ほどかかります。完了後、モデル(
seattle_pm25_xreg_model)がナビゲーション パネルに表示されます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果は表示されません。
ステップ 5: 評価されたすべてのモデルの評価指標を調べる
モデルを作成した後、ML.ARIMA_EVALUATE 関数を使用すると、ハイパーパラメータの自動調整中に評価されたすべての候補モデルの評価指標を確認できます。
次の GoogleSQL クエリでは、FROM 句でモデル bqml_tutorial.seattle_pm25_xreg_model に対して ML.ARIMA_EVALUATE 関数を使用します。デフォルトでは、このクエリはすべての候補モデルの評価指標を返します。
ML.ARIMA_EVALUATE クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
[実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のスクリーンショットのようになります。

結果には次の列が含まれます。
non_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
次の 4 つの列(
non_seasonal_{p,d,q}、has_drift)でトレーニング パイプライン内の ARIMA モデルを定義します。その後の 3 つの指標(log_likelihood、AIC、variance)は ARIMA モデルの適合プロセスに関連しています。まず、
auto.ARIMAアルゴリズムは KPSS テストを使用して、non_seasonal_dの最適値を 1 に決定します。non_seasonal_dが 1 の場合、auto.ARIMA は 42 の ARIMA 候補モデルを並行してトレーニングします。non_seasonal_dが 1 でない場合、auto.ARIMA は 21 の異なる候補モデルをトレーニングします。この例では、42 個の候補モデルがすべて有効です。したがって、出力には 42 行が含まれ、各行は ARIMA 候補モデルに関連付けられています。一部の時系列では、非反転または非静止の候補モデルが無効になります。無効なモデルは出力から除外されるため、出力行数は 42 行未満になります。これらの候補モデルは AIC の昇順で並べ替えられます。最初の行のモデルは AIC が最も低く、最適なモデルとみなされます。この最適モデルが最終モデルとして保存され、次に示すようにML.FORECAST、ML.EVALUATE、ML.ARIMA_COEFFICIENTSを呼び出すときに使用されます。seasonal_periods列は、入力時系列内の季節パターンに関するものです。ARIMA モデリングとは関係がないため、すべての出力行で同じ値になります。前述のステップ 2 で説明したように、1 週間のパターンが報告されますが、これは想定内です。has_holiday_effect、has_spikes_and_dips、has_step_changes列は、decompose_time_series=TRUEの場合にのみ入力されます。これらは ARIMA モデリングとは関係のない、休日効果、スパイクと低下、ステップ変更に関するものです。したがって、失敗したモデルを除き、すべての出力行で同じです。error_message列は、auto.ARIMAの適合プロセス中に発生した可能性のあるエラーを示します。考えられる原因は、選択したnon_seasonal_p、non_seasonal_d、non_seasonal_q、has_drift列で時系列が固定できていないことです。すべての候補モデルの可能性のあるエラー メッセージを取得するには、show_all_candidate_models=trueを設定します。
ステップ 6: モデルの係数を調べる
ML.ARIMA_COEFFICIENTS 関数は、ARIMA_PLUS モデル bqml_tutorial.seattle_pm25_xreg_model のモデル係数を取得します。ML.ARIMA_COEFFICIENTS は、唯一の入力としてモデルを受け取ります。
ML.ARIMA_COEFFICIENTS クエリを実行します。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
[実行] をクリックします。
結果は次のようになります。
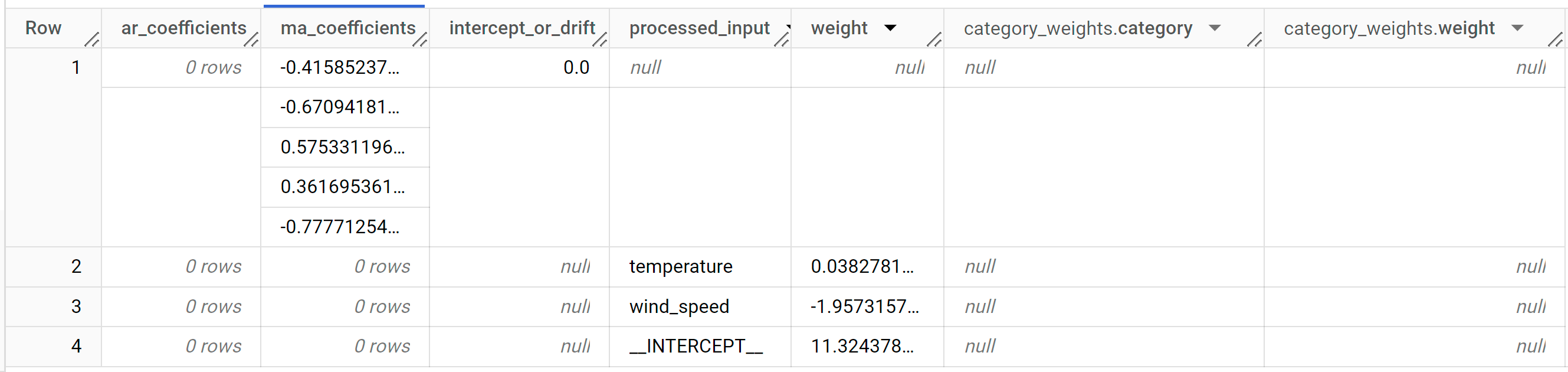
結果には次の列が含まれます。
ar_coefficientsma_coefficientsintercept_or_driftprocessed_inputweightcategory_weights.categorycategory_weights.weight
ar_coefficientsは、ARIMA モデルの自己回帰(AR)部分のモデル係数を示します。同様に、ma_coefficientsは移動平均(MA)部分のモデル係数を示します。どちらも配列で、長さはそれぞれnon_seasonal_pとnon_seasonal_qです。ML.ARIMA_EVALUATEの出力から、一番上の行のnon_seasonal_pは 0 で、non_seasonal_qは 5 です。したがって、ar_coefficientsは空の配列、ma_coefficientsは長さ 5 の配列です。intercept_or_driftは、ARIMA モデルの定数項です。processed_inputと対応するweight列とcategory_weights列に、線形回帰モデルの各特徴とインターセプトの重みが表示されます。特徴が数値特徴である場合、重みはweight列にあります。特徴がカテゴリ特徴の場合、category_weightsはSTRUCTのARRAYであり、STRUCTにはカテゴリの名前と重みが含まれます。
ステップ 7: モデルを使用して時系列を予測する
ML.FORECAST 関数は、モデル bqml_tutorial.seattle_pm25_xreg_model と将来の特徴値を使用して、予測間隔で将来の時系列値を予測します。
次の GoogleSQL クエリの STRUCT(30 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度レベル 80% の予測間隔を生成するように指示します。ML.FORECAST は、モデル、将来の特徴値、およびいくつかのオプションの引数を取ります。
ML.FORECAST クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))[実行] をクリックします。
結果は次のようになります。
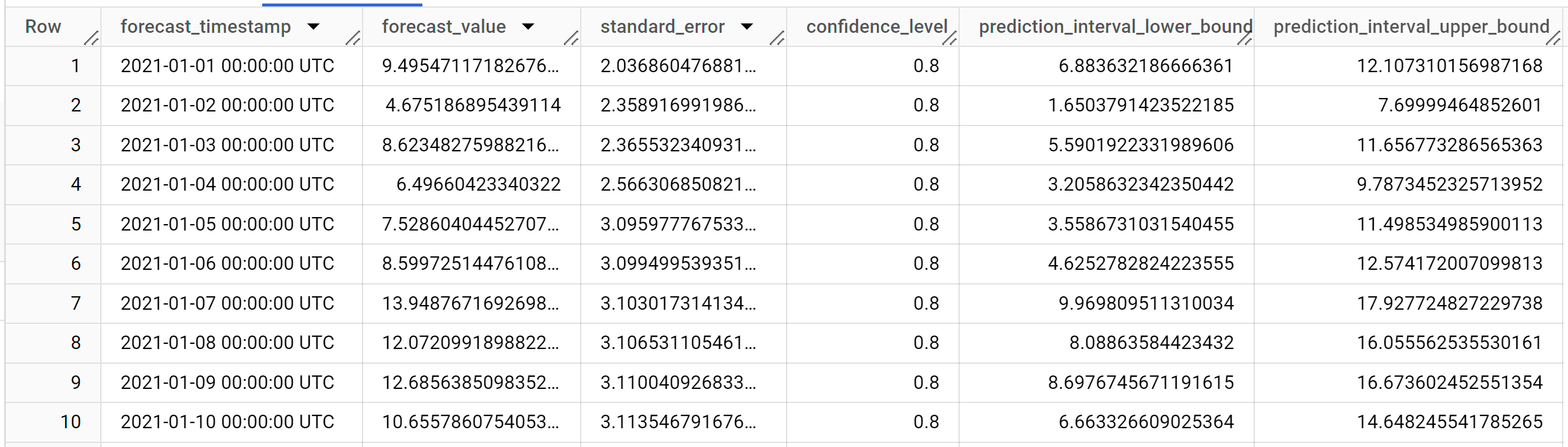
結果には次の列が含まれます。
forecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_bound
出力行は
forecast_timestampの日付順に表示されます。時系列予測の場合、下限と上限で取得される予測間隔はforecast_valueと同じくらい重要です。forecast_valueは予測間隔の中間点です。予測間隔はstandard_errorとconfidence_levelによって異なります。
ステップ 8: 実際のデータで予測の精度を評価する
実際のデータで予測の精度を評価するには、ML.EVALUATE 関数をモデル、bqml_tutorial.seattle_pm25_xreg_model、実際のデータテーブルとともに使用します。
ML.EVALUATE クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタのテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon))2 つ目のパラメータは、将来の特徴を含む実際のデータです。これは、将来の値と予測値を比較するために使用されます。3 つ目のパラメータは、この関数のパラメータの構造体です。
[実行] をクリックします。
結果は次のようになります。

ステップ 9: 予測結果を説明する
時系列がどのように予測されるかを理解するため、ML.EXPLAIN_FORECAST 関数は、モデル bqml_tutorial.seattle_pm25_xreg_model を使用して、予測区間を持つ将来の時系列値を予測し、同時に時系列の個別のコンポーネントすべてを返します。
ML.FORECAST 関数と同様に、STRUCT(30 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度 80% の予測間隔を生成するように指示します。ML.EXPLAIN_FORECAST 関数は、モデル、将来の特徴値、いくつかのオプションの引数を入力として受け取ります。
ML.EXPLAIN_FORECAST クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))[実行] をクリックします。
クエリが完了するまでに 1 秒もかかりません。結果は次のようになります。
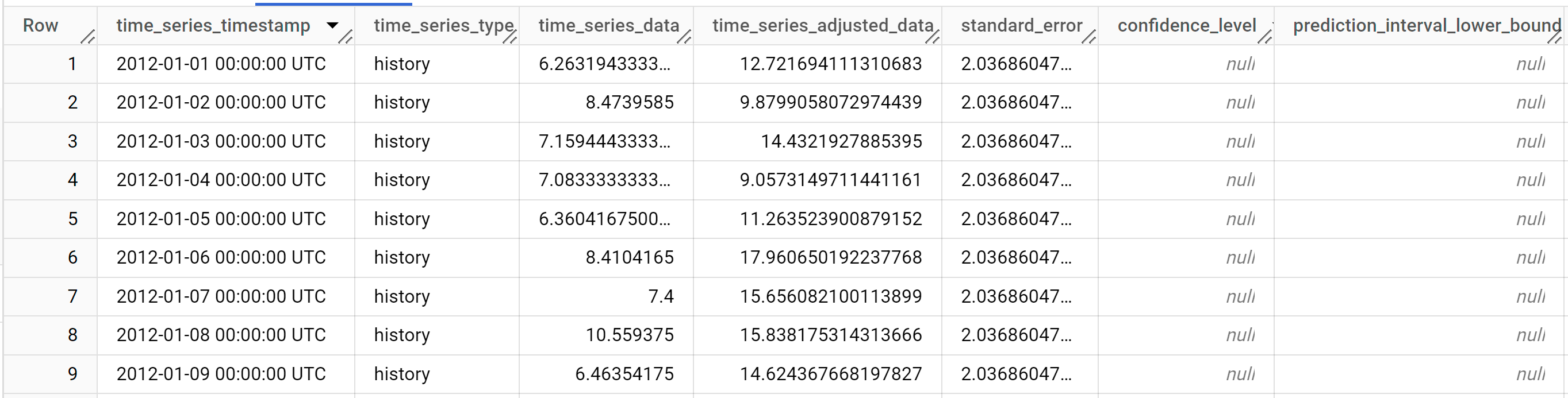
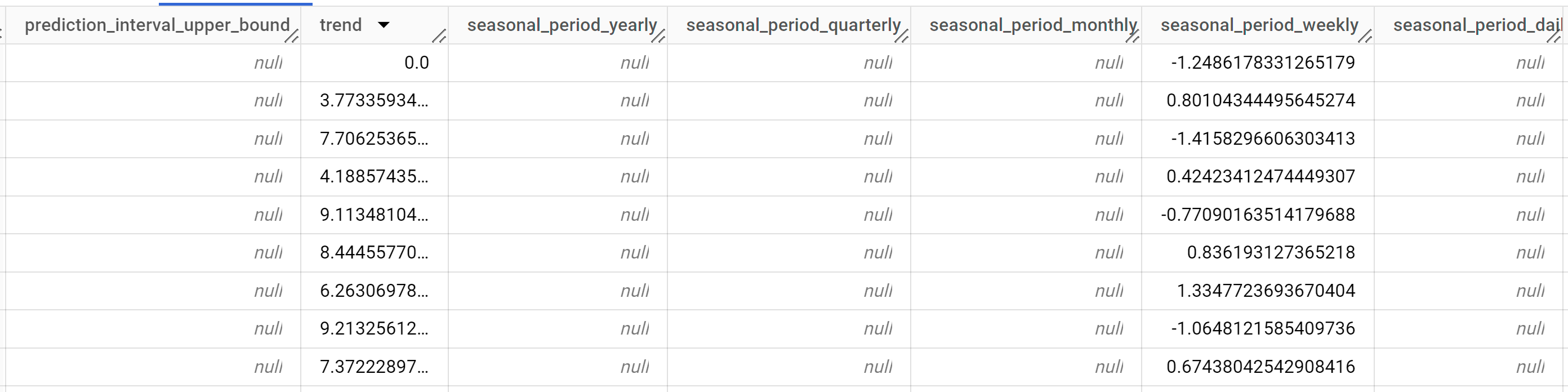
結果には次の列が含まれます。
time_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidualattribution_temperatureattribution_wind_speedattribution___INTERCEPT__
出力行は
time_series_timestampの日付順に表示されます。さまざまなコンポーネントが出力の列として一覧表示されます。詳細については、ML.EXPLAIN_FORECASTをご覧ください。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセット、テーブル、すべてのデータが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力して、[削除] をクリックします。
プロジェクトを削除する
プロジェクトを削除するには:
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
次のステップ
- 1 つのクエリでニューヨーク市のシティバイクの利用データから複数の時系列を予測する方法を学習する。
- ARIMA_PLUS を高速化して 100 万時系列を数時間で予測する方法を学習する。
- 機械学習集中講座で機械学習について学習する。
- BigQuery ML の概要で BigQuery ML の概要を確認する。
- Google Cloud コンソールの使用で、Google Cloud コンソールの詳細を確認する。