Neste tutorial, você aprenderá a criar um conjunto de modelos de série temporal para
executar várias previsões de série temporal com uma única consulta. Você também aprenderá
a aplicar diferentes estratégias de treinamento rápido para acelerar significativamente a
consulta e avaliar a precisão da previsão. Você usará os dados de
new_york.citibike_trips.
Esses dados contêm informações sobre as viagens do Citi Bike na cidade de Nova York.
Antes de ler este tutorial, recomendamos que você leia Previsão de série temporal única a partir de dados do Google Analytics.
Objetivos
Neste tutorial, você usará:
- A instrução
CREATE MODEL: para criar um modelo de série temporal ou um conjunto de modelos de séries temporais. - A função
ML.ARIMA_EVALUATE: para avaliar o modelo. - A função
ML.ARIMA_COEFFICIENTS: para inspecionar os coeficientes do modelo. - A função
ML.EXPLAIN_FORECAST: para recuperar vários componentes da série temporal (como periodicidade e tendência) que podem ser usados para explicar os resultados da previsão. - Looker Studio: para visualizar os resultados da previsão.
- Opcional: a função
ML.FORECAST: para prever o total de visitas diárias.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud, entre eles:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços.
Para mais informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery em um projeto preexistente, acesse
Ative a API BigQuery.
Etapa 1: criar conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo de ML:
No console do Google Cloud, acesse a página do BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.

Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Os conjuntos de dados públicos são armazenados na multirregião
US. Para simplificar, armazene seus conjuntos de dados no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.

Etapa 2 (opcional): visualizar a série temporal que você quer prever
Antes de criar o modelo, é interessante ver como fica a série temporal de entrada. Faça isso usando o Looker Studio.
Na consulta a seguir, a cláusula FROM bigquery-public-data.new_york.citibike_trips
indica que você está consultando a tabela citibike_trips no conjunto de dados
new_york.
Na instrução SELECT, a consulta usa a
função EXTRACT
para extrair as informações de data da coluna starttime. A consulta usa a cláusula
COUNT(*) para descobrir o número total diário de viagens do Citi Bike.
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
Para executar a consulta, siga estas etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
Clique em Executar.
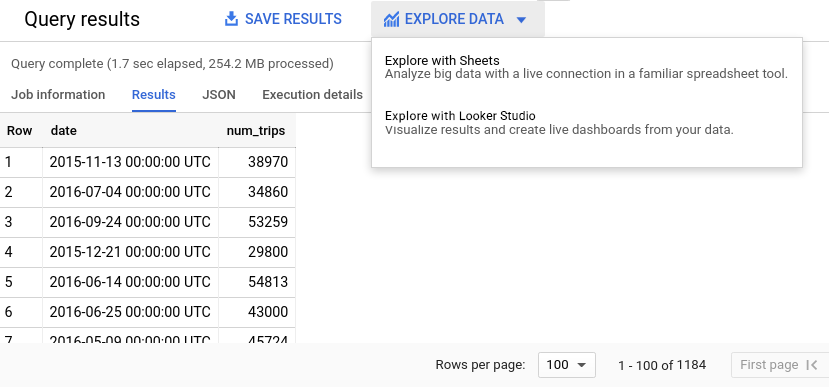
Depois que a consulta for executada, a saída será semelhante à captura de tela a seguir. Na captura de tela, é possível ver que essa série temporal tem 1.184 pontos de dados diários, que abrangem mais de quatro anos. Clique no botão Explorar dados e, em seguida, em Explorar com o Looker Studio. O Looker Studio é aberto em uma nova guia. Conclua as etapas a seguir na nova guia.
No painel Gráfico, escolha Gráfico de série temporal:
No painel Dados, abaixo do painel Gráfico, entre na seção Métrica. Adicione o campo num_trips e remova a métrica padrão Contagem de registros:
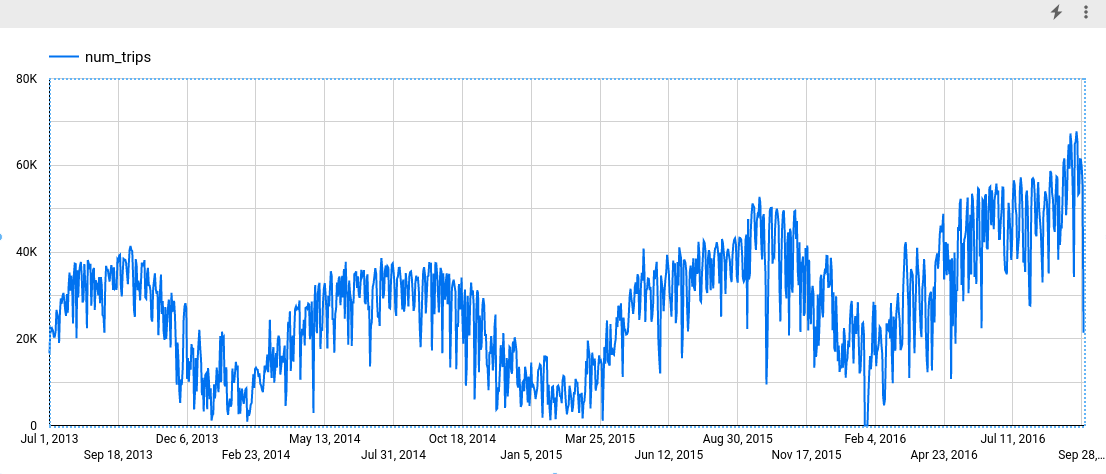
Depois de concluir a etapa acima, o gráfico a seguir será exibido. O gráfico mostra que a série temporal de entrada tem padrões semanais e anuais. A série temporal também está em alta.
Etapa 3: criar seu modelo de série temporal para realizar uma única previsão de série temporal
Em seguida, crie um modelo de série temporal com os dados de viagens do Citi Bike de Nova York.
A consulta do GoogleSQL a seguir cria um modelo usado para prever o
total de viagens diárias de bicicleta. A cláusula CREATE MODEL
cria e treina um modelo chamado bqml_tutorial.nyc_citibike_arima_model.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips' ) AS SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
A cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que você está criando um
modelo de série temporal com base em
ARIMA. Por padrão,
auto_arima=TRUE,
para que o algoritmo auto.ARIMA ajuste automaticamente os hiperparâmetros nos modelos
ARIMA_PLUS. O algoritmo se encaixa em dezenas de modelos candidatos e escolhe
o melhor com o menor
índice de informações do Akaike (AIC, na sigla em inglês).
Além disso, como o padrão é
data_frequency='AUTO_FREQUENCY', o processo de treinamento infere automaticamente
a frequência de dados da série temporal de entrada. Por fim, a instrução CREATE MODEL
usa
decompose_time_series=TRUE
por padrão, e os usuários podem entender melhor como a série temporal é prevista
buscando o método componentes de séries temporais, como períodos sazonais e
efeito de fim de ano.
Execute a consulta CREATE MODEL para criar e treinar seu modelo:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips' ) AS SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
Clique em Executar.
A consulta leva aproximadamente 17 segundos para ser concluída. Depois disso, seu modelo (
nyc_citibike_arima_model) aparece no painel de navegação. Como a consulta usa uma instruçãoCREATE MODELpara criar um modelo, não é possível ver os resultados da consulta.
Etapa 4: prever a série temporal e visualizar os resultados
Para explicar como a série temporal é prevista, visualize todos os componentes
dela, como sazonalidade e tendência, usando a função
ML.EXPLAIN_FORECAST.
Para isso, siga estas etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model`, STRUCT(365 AS horizon, 0.9 AS confidence_level))Clique em Executar.
Após a conclusão da consulta, clique no botão Explorar dados e, depois, em Explorar com o Looker Studio. Uma nova guia será aberta no navegador. Em seguida, no painel Gráfico, localize o ícone Gráfico de série temporal e clique nele, conforme mostrado na captura de tela a seguir.
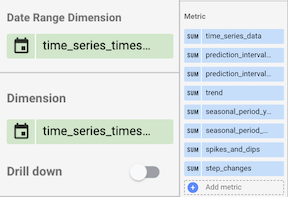
No painel Dados, faça o seguinte:
- Na seção Dimensão do período, selecione
time_series_timestamp (Date). - Na seção Dimensão, selecione
time_series_timestamp (Date). - Na seção Métrica, remova a métrica padrão
Record Counte adicione o seguinte:time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_yearlyseasonal_period_weeklyspikes_and_dipsstep_changes
- Na seção Dimensão do período, selecione
No painel Estilo, role a tela para baixo até a opção Dados ausentes e use Quebras de linha em vez de Linha até zero.
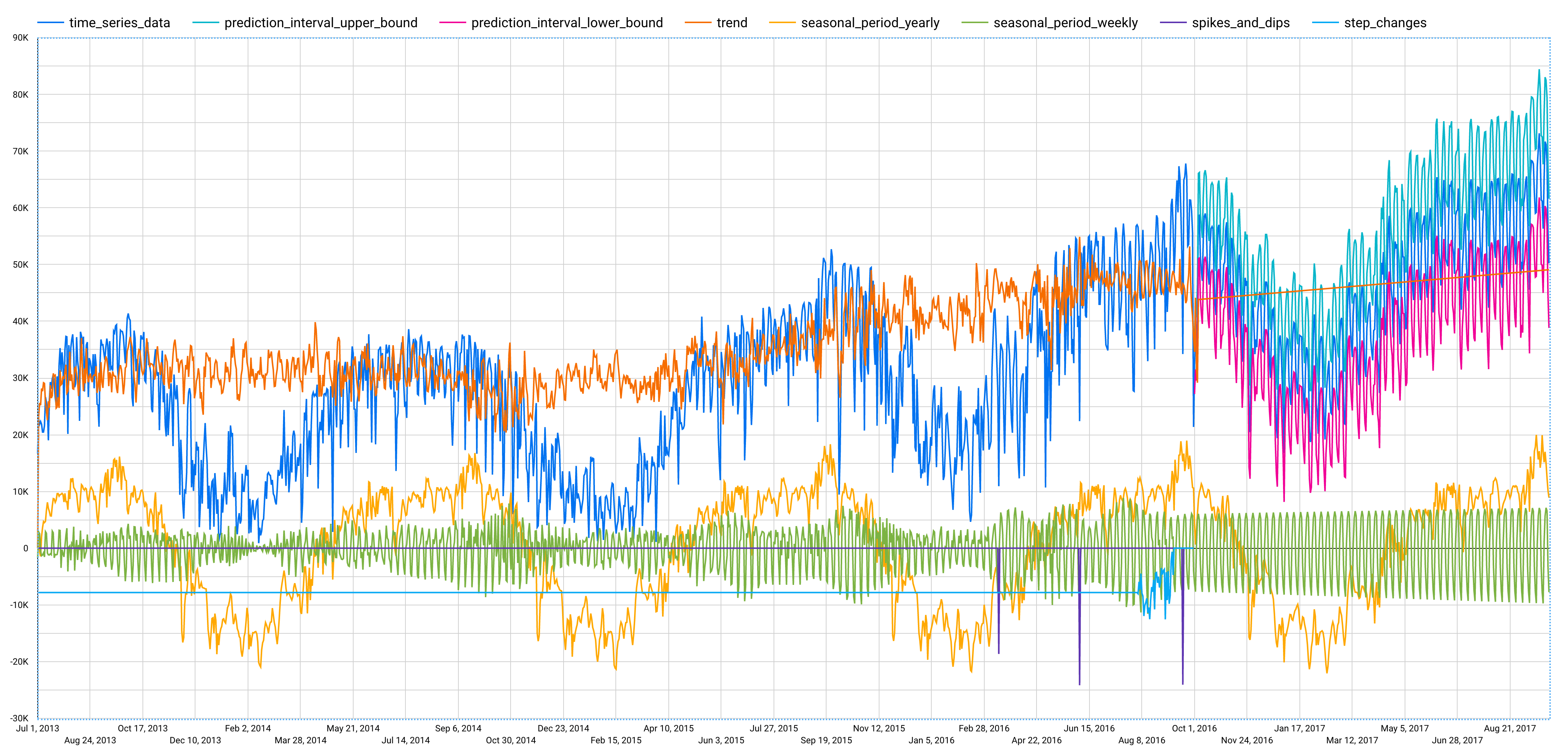
Depois de concluir essas etapas, o gráfico a seguir será exibido no painel esquerdo.
Etapa 5: prever várias séries temporais simultaneamente
Em seguida, será possível prever o número total de viagens diárias a partir de diferentes estações do Citi Bike. Para fazer isso, você precisa prever muitas séries temporais.
É possível gravar várias consultas
CREATE MODEL.
No entanto, isso pode ser um processo tedioso e demorado, especialmente quando
você tem um grande número de séries temporais.
Para melhorar esse processo, o BigQuery ML permite a criação de um conjunto de modelos de séries temporais para prever várias séries temporais com uma única consulta. Além disso, todos os modelos de séries temporais são ajustados simultaneamente.
Na consulta do GoogleSQL a seguir, a cláusula
CREATE MODEL
cria e treina um conjunto de modelos chamado
bqml_tutorial.nyc_citibike_arima_model_group.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date
A cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que você está criando um conjunto de modelos de séries temporais ARIMA_PLUS
baseados em
ARIMA. Além de time_series_timestamp_col e
time_series_data_col, é preciso especificar time_series_id_col, que é usado para
anotar diferentes séries temporais de entrada. A opção auto_arima_max_order controla o espaço de pesquisa para ajuste de hiperparâmetros no algoritmo auto.ARIMA.
Por fim, a instrução CREATE MODEL usa
decompose_time_series=TRUE
por padrão, e os usuários podem entender melhor como a série temporal é analisada no
pipeline de treinamento buscando o resultados da decomposição.
A cláusula SELECT ... FROM ... GROUP BY ... indica a formação de várias séries temporais. Cada uma delas está associada a um start_station_name diferente. Para simplificar, usamos a cláusula WHERE ... LIKE ... para
limitar as estações de início àquelas que tenham Central Park no nome.
Para executar a consulta CREATE MODEL a fim de criar e treinar seu modelo, use as seguintes etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date
Clique em Executar.
A consulta leva aproximadamente 24 segundos para ser concluída. Depois disso, seu modelo (
nyc_citibike_arima_model_group) aparece no painel de navegação. Como a consulta usa uma instruçãoCREATE MODEL, você não vê os resultados da consulta.
Etapa 6: inspecionar as métricas de avaliação do conjunto de modelos de série temporal
Depois de criar os modelos, use a função
ML.ARIMA_EVALUATE
para ver as métricas de avaliação de todos os modelos criados.
Na consulta do GoogleSQL a seguir, a cláusula FROM usa a
função ML.ARIMA_EVALUATE
no seu modelo, bqml_tutorial.nyc_citibike_arima_model_group. As
métricas de avaliação dependem apenas da entrada de treinamento. Portanto, seu modelo é a
única entrada.
Para executar a consulta ML.ARIMA_EVALUATE,
siga estas etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`)
Clique em Executar.
A consulta leva menos de um segundo para ser concluída. Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão o seguinte formato:
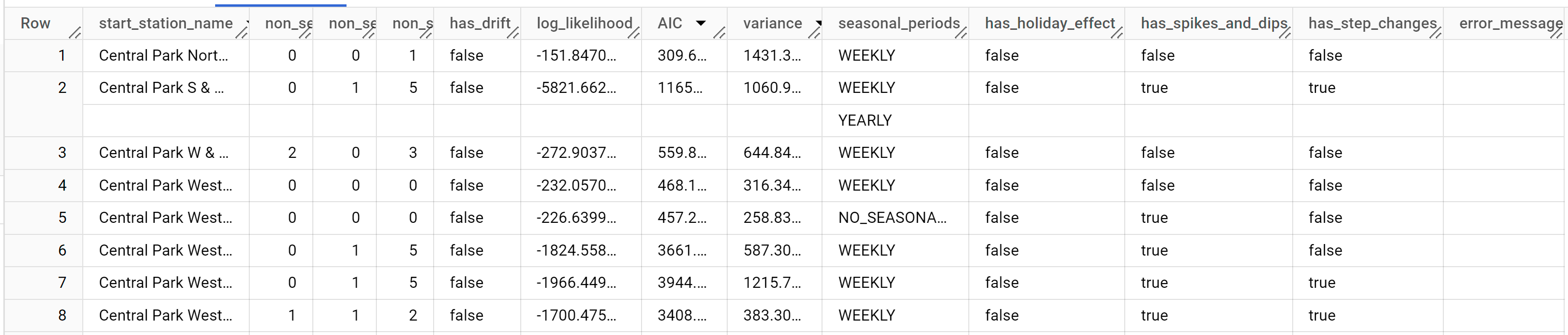
Os resultados incluem as seguintes colunas:
start_station_namenon_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
start_station_name, a primeira coluna, anota a série temporal à qual cada modelo de série temporal é ajustado. É a mesma especificada portime_series_id_col.As quatro colunas a seguir (
non_seasonal_p,non_seasonal_d,non_seasonal_qehas_drift) definem um modelo ARIMA no pipeline de treinamento. As três métricas seguintes (log_likelihood,AICevariance) são relevantes para o processo de ajuste do modelo ARIMA. O processo de ajuste determina o melhor modelo de ARIMA usando o algoritmoauto.ARIMA, um para cada série temporal.As colunas
has_holiday_effect,has_spikes_and_dipsehas_step_changessão preenchidas somente quandodecompose_time_series=TRUE.A coluna
seasonal_periodsé o padrão sazonal dentro das séries temporais de entrada. Cada série temporal pode ter diferentes padrões sazonais. Por exemplo, na figura, é possível ver que uma série temporal tem um padrão anual, enquanto outras não.
Etapa 7: inspecionar os coeficientes dos modelos
A função ML.ARIMA_COEFFICIENTS
é usada para recuperar os coeficientes do seu modelo ARIMA_PLUS,
bqml_tutorial.nyc_citibike_arima_model_group. ML.ARIMA_COEFFICIENTS usa
o modelo como a única entrada.
Para executar a consulta ML.ARIMA_COEFFICIENTS, use as seguintes etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`)
Clique em Executar.
A consulta leva menos de um segundo para ser concluída. Os resultados serão semelhantes à captura de tela a seguir:
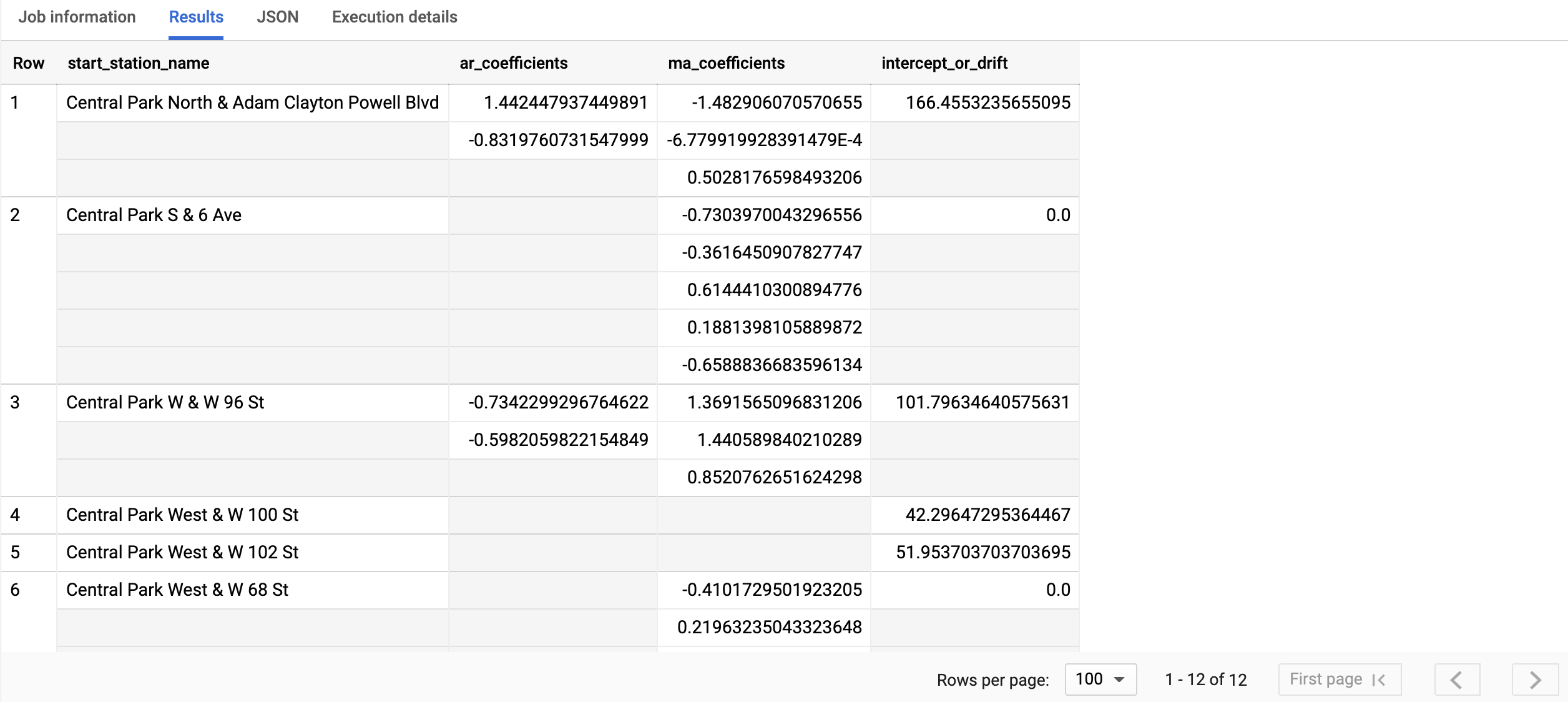
Os resultados incluem as seguintes colunas:
start_station_namear_coefficientsma_coefficientsintercept_or_drift
start_station_name, a primeira coluna, anota a série temporal à qual cada modelo de série temporal é ajustado.ar_coefficientsmostra os coeficientes do modelo da parte autoregressiva (AR) do modelo ARIMA. Da mesma forma,ma_coefficientsmostra os coeficientes do modelo da parte de média móvel (MA, na sigla em inglês). Ambos são matrizes, com comprimentos iguais anon_seasonal_penon_seasonal_q, respectivamente. Ointercept_or_drifté o termo constante no modelo ARIMA.
Etapa 8: usar o modelo para prever várias séries temporais simultaneamente com explicações
A função ML.EXPLAIN_FORECAST
prevê valores futuros da série temporal com um intervalo de previsão usando
o modelo, bqml_tutorial.nyc_citibike_arima_model_group e, ao mesmo tempo,
retorna todos os componentes separados. da série temporal.
A cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) indica que a consulta
prevê três pontos de tempo futuros e gera um intervalo de previsão
com 90% de confiança. A função ML.EXPLAIN_FORECAST usa o modelo e
alguns argumentos opcionais.
Para executar a consulta ML.EXPLAIN_FORECAST, use as seguintes etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))Clique em Executar.
A consulta leva menos de um segundo para ser concluída. Os resultados terão o seguinte formato:


Os resultados incluem as seguintes colunas:
start_station_nametime_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidual
As linhas de saída são ordenadas por
start_station_namee, para cadastart_station_name, as linhas de saída estão na ordem cronológica detime_series_timestamp. Componentes diferentes são listados como colunas da saída. Para mais informações, consulte a definição deML.EXPLAIN_FORECAST.
(Opcional) Etapa 9: usar seu modelo para prever várias séries temporais simultaneamente
A função ML.FORECAST
também pode ser usada para prever valores futuros de séries temporais com um
intervalo de previsão usando seu modelo,
bqml_tutorial.nyc_citibike_arima_model_group.
Assim como ML.EXPLAIN_FORECAST, a cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level)
indica que, para cada série temporal, a consulta prevê três pontos futuros
e gera um intervalo de previsão com 90% de confiança.
A função ML.FORECAST usa o modelo e alguns argumentos
opcionais.
Para executar a consulta ML.FORECAST, use as seguintes etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))Clique em Executar.
A consulta leva menos de um segundo para ser concluída. Os resultados terão o seguinte formato:
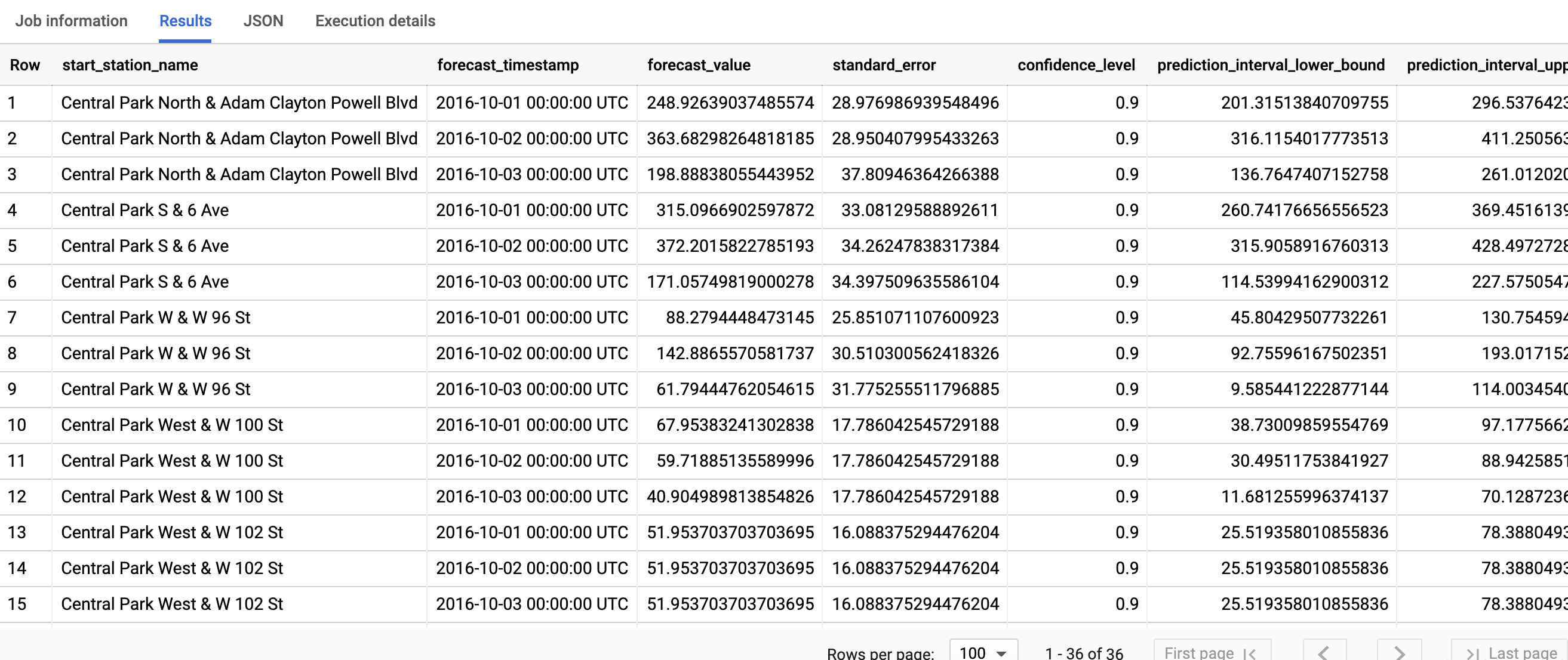
Os resultados incluem as seguintes colunas:
start_station_nameforecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_boundconfidence_interval_lower_bound(suspensa em breve)confidence_interval_upper_bound(suspensa em breve)
start_station_name, a primeira coluna, anota a série temporal à qual cada modelo de série temporal é ajustado. Cadastart_station_nametem um número horizon para os resultados da previsão.Para cada
start_station_name, as linhas de saída são ordenadas na ordem cronológica deforecast_timestamp. Na previsão de série temporal, o intervalo de previsão, capturado pelos limites mínimo e máximo, é tão importante quanto oforecast_value. Oforecast_valueé o ponto médio do intervalo de previsão. O intervalo de previsão depende destandard_erroreconfidence_level.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console do Google Cloud.
Na navegação, clique no conjunto de dados bqml_tutorial criado.
Clique em Excluir conjunto de dados para excluir o conjunto de dados, a tabela e todos os dados.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial). Em seguida, clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
- Saiba como acelerar o ARIMA_PLUS para ativar a previsão de um milhão de séries temporais em algumas horas
- Para saber mais sobre machine learning, consulte o Curso intensivo de machine learning.
- Para uma visão geral sobre ML do BigQuery, consulte Introdução ao ML do BigQuery.
- Para saber mais, consulte Como usar o console do Google Cloud.