En este instructivo aprenderás a crear un conjunto de modelos de serie temporal para realizar varias previsiones de series temporales con una sola consulta. También aprenderás a aplicar diferentes estrategias de entrenamiento rápido para acelerar significativamente la consulta y a evaluar la exactitud de la previsión. Usarás los datos de new_york.citibike_trips.
Estos datos contienen información sobre los viajes de Citi Bike en la ciudad de Nueva York.
Antes de leer este instructivo, te recomendamos que leas la Previsión de series temporales individuales a partir de datos de Google Analytics.
Objetivos
En este instructivo usarás lo siguiente:
- La declaración
CREATE MODEL, para crear un modelo de serie temporal o un conjunto de modelos de serie temporal - La función
ML.ARIMA_EVALUATE, para evaluar el modelo - La función
ML.ARIMA_COEFFICIENTS, para inspeccionar los coeficientes del modelo - La función
ML.EXPLAIN_FORECAST, que permite recuperar varios componentes de las series temporales (como la temporada y la tendencia) que se pueden usar para explicar los resultados de la previsión. - Looker Studio: para visualizar los resultados de la previsión.
- La función
ML.FORECAST, para prever el total de visitas diarias
Costos
En este instructivo se usan componentes facturables de Google Cloud, que incluyen los siguientes:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos de BigQuery, consulta la página de precios de BigQuery.
Para obtener más información sobre los costos de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
- BigQuery se habilita de forma automática en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Habilita la API de BigQuery.
Paso uno: Crea tu conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA:
En la consola de Google Cloud, ve a la página de BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
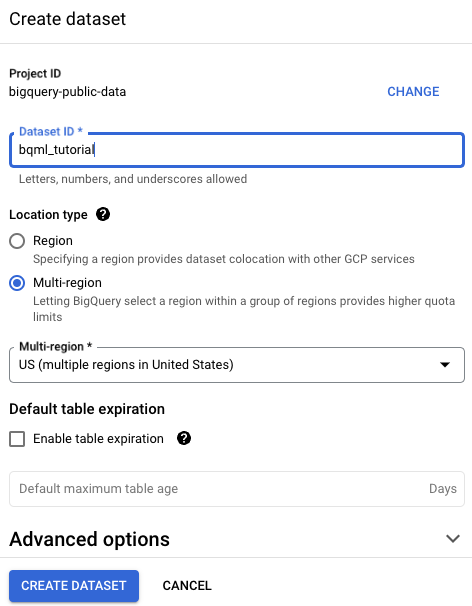
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Los conjuntos de datos públicos se almacenan en la multirregión
US. Para que sea más simple, almacena tu conjunto de datos en la misma ubicación.Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
Paso dos (opcional): Visualiza la serie temporal que deseas prever
Antes de crear el modelo, es beneficioso ver cómo se ve la serie temporal de entrada. Puedes lograr esto con Looker Studio.
En la siguiente consulta, la cláusula FROM bigquery-public-data.new_york.citibike_trips indica que consultas la tabla citibike_trips en el conjunto de datos new_york.
En la declaración SELECT, la consulta usa la función EXTRACT para extraer la información de la fecha de la columna starttime. La consulta usa la cláusula COUNT(*) para obtener la cantidad total diaria de viajes con Citi Bike.
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
Para ejecutar la consulta, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
Haz clic en Ejecutar.
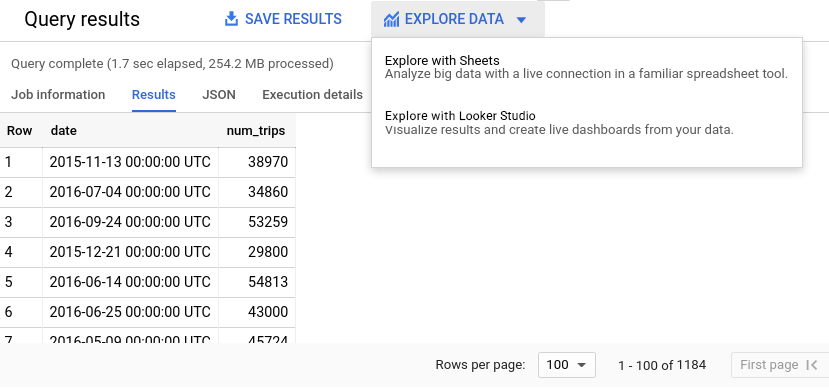
Después de que se ejecuta la consulta, el resultado es similar a la siguiente captura de pantalla. En la captura de pantalla, puedes ver que esta serie temporal tiene 1,184 datos diarios, que abarcan más de 4 años. Haz clic en el botón Explorar datos y, luego, en Explorar con Looker Studio. Looker Studio se abre en una pestaña nueva. Completa los siguientes pasos en la pestaña nueva.
En el panel Gráfico, elige Gráfico de serie temporal (Time series chart):
En el panel Datos, debajo del panel Gráfico, ve a la sección Métrica. Agrega el campo num_trips y quita la métrica predeterminada Conteo de registros (Record Count):
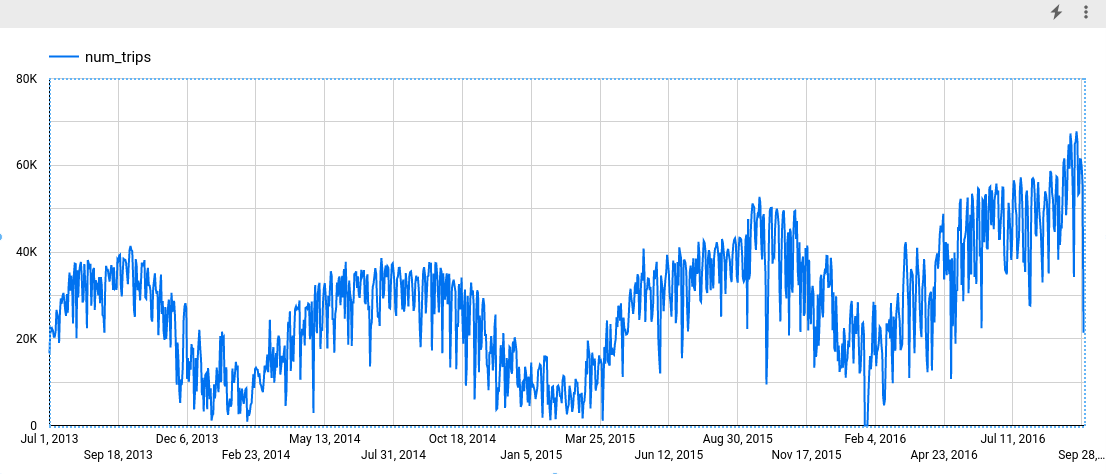
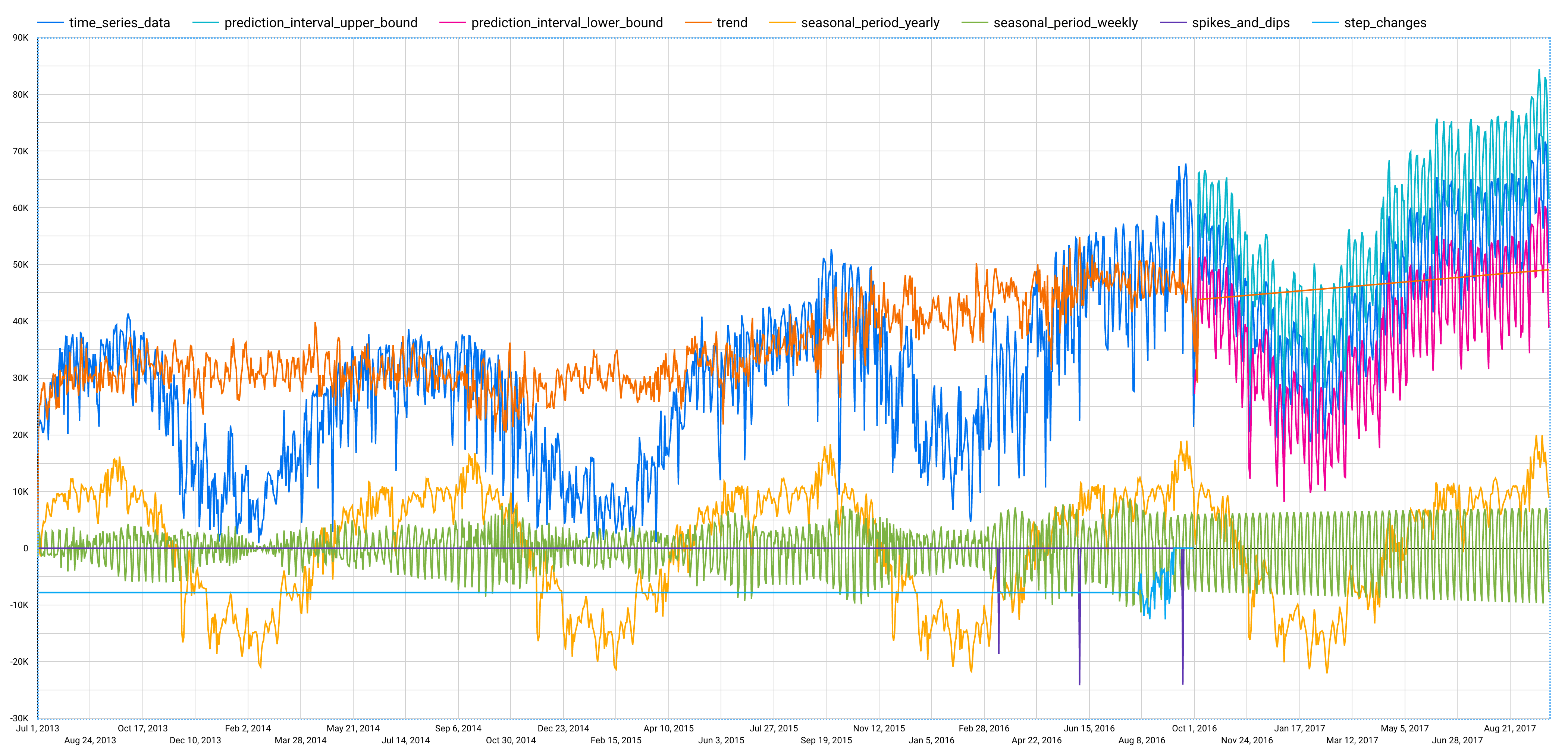
Después de completar el paso anterior, aparece el siguiente gráfico. El gráfico muestra que la serie temporal de entrada tiene patrones semanales y anuales. La serie temporal también es una tendencia en alza.
Paso tres: Crea un modelo de serie temporal para realizar una previsión de una serie temporal individual
A continuación, crea un modelo de serie temporal mediante los datos de viajes de Citi Bike en NYC.
La siguiente consulta de Google SQL crea un modelo que se usa para prever el total de viajes diarios en bicicleta. La cláusula CREATE MODEL crea y entrena un modelo llamado bqml_tutorial.nyc_citibike_arima_model.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips' ) AS SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
La cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) indica que creas un modelo de serie temporal basado en ARIMA. De forma predeterminada, auto_arima=TRUE, por lo que el algoritmo auto.ARIMA ajusta de forma automática los hiperparámetros en los modelos ARIMA_PLUS. El algoritmo se adapta a decenas de modelos de candidatos y elige el mejor con el criterio de información Akaike (AIC) más bajo.
Además, debido a que el valor predeterminado es data_frequency='AUTO_FREQUENCY', el proceso de entrenamiento infiere de forma automática la frecuencia de datos de la serie temporal de entrada. Por último, la declaración CREATE MODEL usa decompose_time_series=TRUE de forma predeterminada, y los usuarios pueden comprender mejor cómo se prevé la serie temporal mediante la recuperación de los componentes de series temporales, como períodos estacionales y el efecto de festividades.
Ejecuta la consulta CREATE MODEL para crear y entrenar el modelo:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips' ) AS SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
Haz clic en Ejecutar.
La consulta toma alrededor de 17 segundos en completarse; luego, el modelo (
nyc_citibike_arima_model) aparece en el panel de navegación. Debido a que en la consulta se usa una declaraciónCREATE MODELpara crear un modelo, no se muestran los resultados.
Paso cuatro: Realiza una previsión de las series temporales y visualiza los resultados
Para explicar cómo se prevén las series temporales, visualiza todos los componentes de las series temporales, como la estacionalidad y la tendencia, mediante la función ML.EXPLAIN_FORECAST.
Para ello, haz lo siguiente:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model`, STRUCT(365 AS horizon, 0.9 AS confidence_level))Haz clic en Ejecutar.
Una vez completada la consulta, haz clic en el botón Explorar datos y, luego, en Explorar con Looker Studio. Se abrirá una pestaña nueva en el navegador. Luego, en el panel Gráfico, busca el ícono de Gráfico de serie temporal (Time series chart) y haz clic en él, como se muestra en la siguiente captura de pantalla.
En el panel Datos (Data), haz lo siguiente:
- En la sección Dimensión del período (Date Range Dimension), selecciona
time_series_timestamp (Date). - En la sección Dimensión (Dimension), selecciona
time_series_timestamp (Date). - En la sección Métrica (Metric), quita la métrica predeterminada
Record County agrega lo siguiente:time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_yearlyseasonal_period_weeklyspikes_and_dipsstep_changes
- En la sección Dimensión del período (Date Range Dimension), selecciona
En el panel Estilo (Style), desplázate hacia abajo hasta la opción Datos faltantes (Missing Data) y usa Saltos de línea (Line Breaks) en lugar de Line to zero.
Después de completar estos pasos, aparecerá el siguiente gráfico en el panel izquierdo.
Paso cinco: Realiza una previsión de varias series temporales al mismo tiempo
A continuación, es posible que desees prever la cantidad total diaria de viajes a partir de diferentes estaciones de Citi Bike. Para ello debes prever muchas series temporales.
Puedes escribir varias consultas de CREATE MODEL, pero puede ser un proceso tedioso y lento, en especial cuando tienes una gran cantidad de series temporales.
A fin de mejorar este proceso, BigQuery ML te permite crear un conjunto de modelos de serie temporal para prever varias series temporales mediante una sola consulta. Además, todos los modelos de serie temporal se ajustan de forma simultánea.
En la siguiente consulta de Google SQL, la cláusula CREATE MODEL crea y entrena un conjunto de modelos llamado bqml_tutorial.nyc_citibike_arima_model_group.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date
La cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) indica que creas un conjunto de modelos de serie temporal ARIMA_PLUS basados en ARIMA. Además de time_series_timestamp_col y time_series_data_col, debes especificar time_series_id_col, que se usa para anotar series temporales de entrada diferentes. La opción auto_arima_max_order controla el espacio de búsqueda para el ajuste de hiperparámetros en el algoritmo auto.ARIMA.
Por último, la instrucción CREATE MODEL usa decompose_time_series=TRUE de forma predeterminada, y los usuarios pueden comprender aún más cómo se analiza la serie temporal en la canalización de entrenamiento si recuperas los resultados de la descomposición.
La cláusula SELECT ... FROM ... GROUP BY ... indica que formas varias series temporales, cada una asociada con un start_station_name diferente. Para simplificar usamos la cláusula WHERE ... LIKE ..., a fin de limitar las estaciones de inicio a aquellas con Central Park en el nombre.
A fin de ejecutar la consulta CREATE MODEL para crear y entrenar el modelo, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date
Haz clic en Ejecutar.
La consulta tarda unos 24 segundos en completarse; luego, el modelo (
nyc_citibike_arima_model_group) aparece en el panel de navegación. Como la consulta usa una declaraciónCREATE MODEL, no ves los resultados de la consulta.
Paso seis: Inspecciona las métricas de evaluación del conjunto de modelos de serie temporal
Después de crear los modelos, puedes usar la función ML.ARIMA_EVALUATE para ver las métricas de evaluación de todos los modelos creados.
En la siguiente consulta de GoogleSQL, la cláusula FROM usa la función ML.ARIMA_EVALUATE en el modelo, bqml_tutorial.nyc_citibike_arima_model_group. Las métricas de evaluación solo dependen de la entrada de entrenamiento, por lo que el modelo es la única entrada.
Para ejecutar la ML.ARIMA_EVALUATE, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`)
Haz clic en Ejecutar.
La consulta toma menos de un segundo en completarse. Cuando la consulta finalice, haz clic en la pestaña Resultados debajo del área de texto de la consulta. Los resultados deberían verse de la siguiente manera:

Los resultados incluyen las siguientes columnas:
start_station_namenon_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
start_station_name, la primera columna, anota la serie temporal en la que se ajusta cada modelo de serie temporal. Es lo mismo que especificatime_series_id_col.Las siguientes cuatro columnas (
non_seasonal_p,non_seasonal_d,non_seasonal_qyhas_drift) definen un modelo ARIMA en la canalización de entrenamiento. Las tres métricas posteriores (log_likelihood,AICyvariance) son relevantes para el proceso de ajuste del modelo ARIMA. El proceso de ajuste determina el mejor modelo ARIMA con el algoritmoauto.ARIMA, uno para cada serie temporal.Las columnas
has_holiday_effect,has_spikes_and_dipsyhas_step_changessolo se propagan cuandodecompose_time_series=TRUE.La columna
seasonal_periodses el patrón estacional dentro de la serie temporal de entrada. Cada serie temporal puede tener diferentes patrones estacionales. Por ejemplo, en la figura, puedes ver que una serie temporal tiene un patrón anual, mientras que otras no.
Paso siete: Inspecciona los coeficientes de los modelos
La función ML.ARIMA_COEFFICIENTS se usa para recuperar los coeficientes del modelo ARIMA_PLUS, bqml_tutorial.nyc_citibike_arima_model_group. ML.ARIMA_COEFFICIENTS toma el modelo como la única entrada.
Para ejecutar la consulta ML.ARIMA_COEFFICIENTS, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`)
Haz clic en Ejecutar.
La consulta toma menos de un segundo en completarse. Los resultados deberían ser similares a los de la siguiente captura de pantalla:
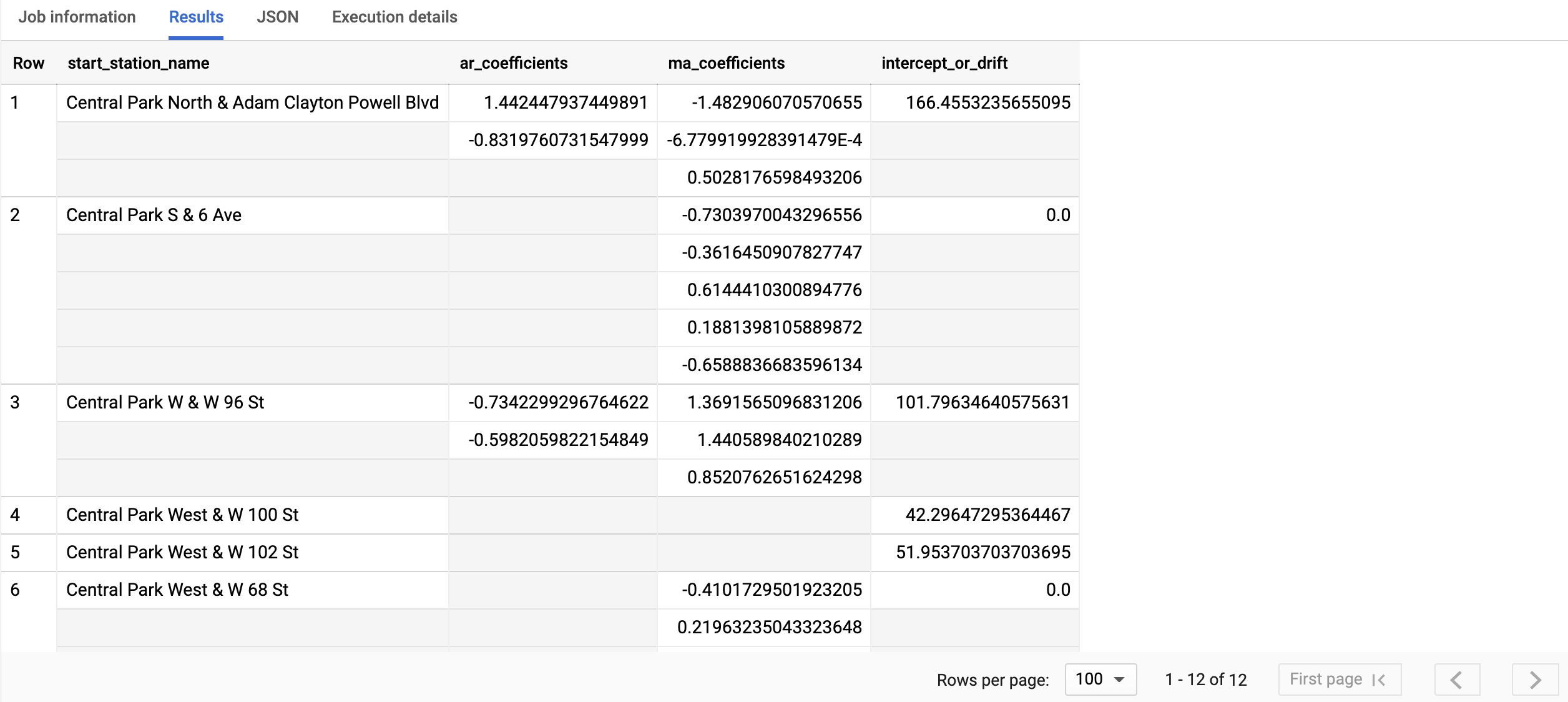
Los resultados incluyen las siguientes columnas:
start_station_namear_coefficientsma_coefficientsintercept_or_drift
start_station_name, la primera columna, anota la serie temporal en la que se ajusta cada modelo de serie temporal.ar_coefficientsmuestra los coeficientes del modelo de la parte autorregresiva (AR) del modelo ARIMA. De manera similar,ma_coefficientsmuestra los coeficientes del modelo de la parte de promedio móvil (MA). Ambos son arreglos, cuyas longitudes son iguales anon_seasonal_pynon_seasonal_q, respectivamente. Elintercept_or_driftes el término constante en el modelo ARIMA.
Paso ocho: Usa el modelo para prever varias series temporales de forma simultánea con explicaciones
La función ML.EXPLAIN_FORECAST prevé valores de series temporales futuras con un intervalo de predicción mediante el modelo bqml_tutorial.nyc_citibike_arima_model_group y, al mismo tiempo, muestra todos los componentes separados de la serie temporal.
La cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) indica que la consulta prevé tres puntos de tiempo futuros y genera un intervalo de predicción con una confianza del 90%. La función ML.EXPLAIN_FORECAST toma el modelo, así como algunos argumentos opcionales.
Para ejecutar la consulta ML.EXPLAIN_FORECAST, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))Haz clic en Ejecutar.
La consulta toma menos de un segundo en completarse. Los resultados deberían verse como estos:


Los resultados incluyen las siguientes columnas:
start_station_nametime_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidual
Las filas de salida se ordenan por
start_station_name, y para cadastart_station_name, las filas de salida están en orden cronológico detime_series_timestamp. Los diferentes componentes se enumeran como columnas del resultado. Para obtener más información, consulta la definición deML.EXPLAIN_FORECAST.
Paso nueve: Usa el modelo para prever varias series temporales de forma simultánea (opcional)
La función ML.FORECAST también se puede usar para predecir valores de series temporales futuras con un intervalo de predicción mediante tu modelo, bqml_tutorial.nyc_citibike_arima_model_group.
Al igual que ML.EXPLAIN_FORECAST, la cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) indica que, para cada serie temporal, la consulta predice tres puntos futuros y genera un intervalo de predicción con un 90% de confianza.
La función ML.FORECAST toma el modelo, así como algunos argumentos opcionales.
Para ejecutar la consulta ML.FORECAST, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))Haz clic en Ejecutar.
La consulta toma menos de un segundo en completarse. Los resultados deberían verse de la siguiente manera:
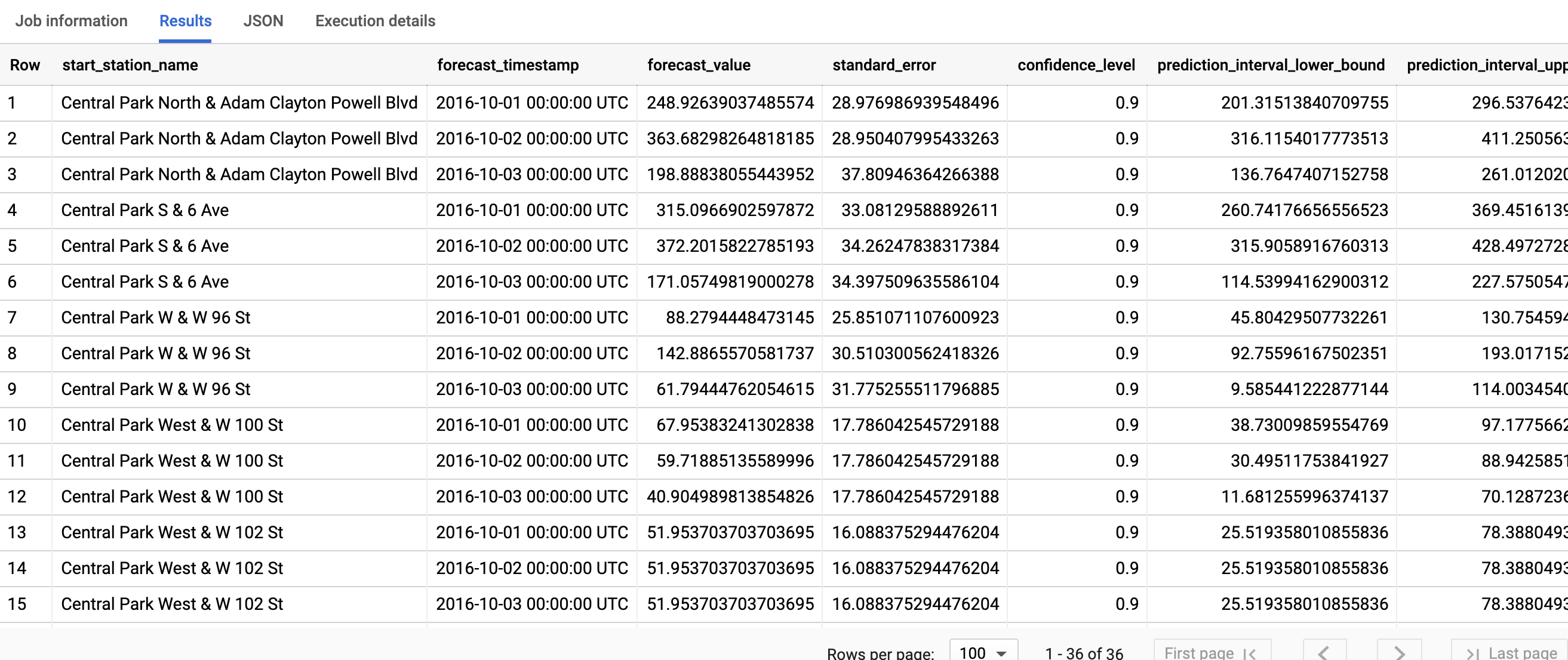
Los resultados incluyen las siguientes columnas:
start_station_nameforecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_boundconfidence_interval_lower_bound(próximamente dejará de estar disponible)confidence_interval_upper_bound(próximamente dejará de estar disponible)
start_station_name, la primera columna, anota la serie temporal en la que se ajusta cada modelo de serie temporal. Cadastart_station_nametiene una cantidad de filas de horizonte para los resultados de previsión.Para cada
start_station_name, las filas de salida se ordenan en el orden cronológico deforecast_timestamp. En la previsión de series temporales, el intervalo de confianza, que capturan los límites inferior y superior, es tan importante como elforecast_value. Elforecast_valuees el punto medio del intervalo de confianza. El intervalo de confianza depende delstandard_errory elconfidence_level.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola de Google Cloud.
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos para borrar el conjunto de datos, la tabla y todos los datos.
En el cuadro de diálogo Borrar conjunto de datos, escribe el nombre del conjunto de datos (
bqml_tutorial) para confirmar el comando de borrado y, luego, haz clic en Borrar.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
¿Qué sigue?
- Obtén información sobre cómo acelerar ARIMA_PLUS para habilitar la previsión de 1 millón de series temporales en horas
- Para obtener más información sobre el aprendizaje automático, consulta el Curso intensivo de aprendizaje automático.
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para obtener más información sobre la consola de Google Cloud, consulta Usa la consola de Google Cloud.