本页面介绍如何使用 AutoML Tables 根据您的数据集训练自定义模型。您必须已经创建了数据集并已向其中导入了数据。
简介
创建自定义模型的方法,是使用准备好的数据集对其进行训练。AutoML Tables 使用数据集中的条目来训练、测试模型并评估其性能。您可以查看结果、根据需要调整训练数据集,并使用改进后的数据集训练新的模型。
在准备训练模型期间,您需要更新数据集的架构信息。这些架构更新会影响将来使用该数据集的任何模型。已经开始训练的模型不受影响。
训练模型可能需要几个小时才能完成。您可以使用 Google Cloud 控制台或使用 Cloud AutoML API 查看训练进度。
每次开始训练时,AutoML Tables 都会创建新模型,因此您的项目可能包含大量模型。您可以获取项目中模型的列表并删除不再需要的模型。
模型必须每 6 个月重新训练一次,才能继续执行预测。
训练模型
控制台
您可以根据需要打开数据集页面并点击要使用的数据集。
此操作将在训练标签页中打开数据集。
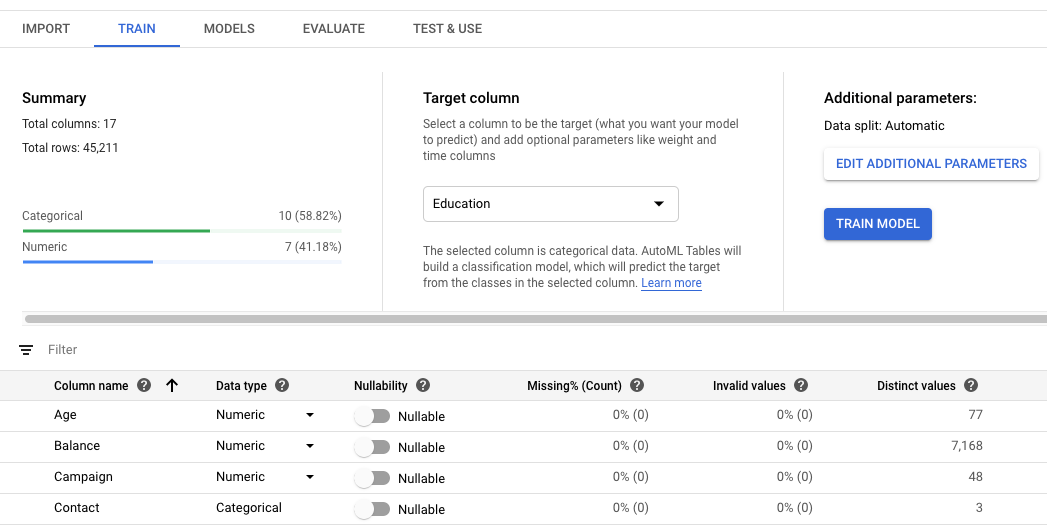
为模型选择目标列。
这是要训练模型进行预测的值。其数据类型确定生成的模型是回归(数值)模型还是分类(类别)模型。了解详情。
如果目标列的数据类型为“分类”,则必须至少包含 2 个且不超过 500 个非重复值。
查看数据集中各列的数据类型、是否可为 NULL 和数据统计信息。
您可以点击各列,获取该列的更多详情。 详细了解架构检查。
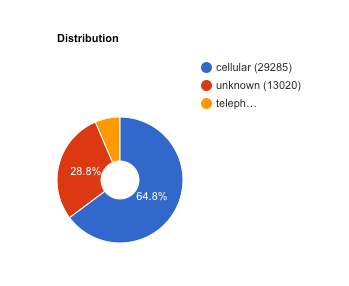
如果您想要控制数据拆分,请点击修改其他参数并指定数据拆分列或时间列。了解详情。
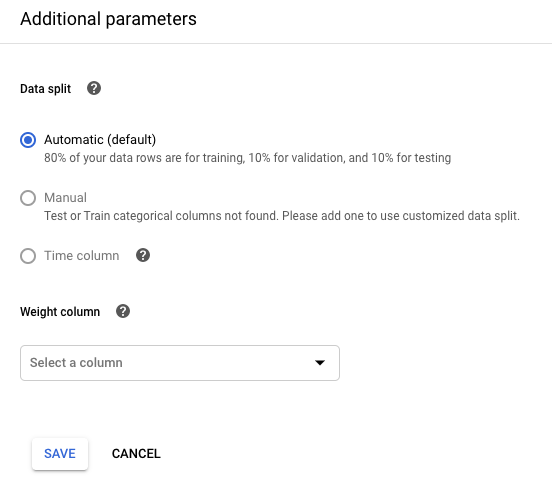
如果您想按照某列的值为训练样本分配权重,请点击修改其他参数并指定相应的列。了解详情。
查看摘要统计信息和详细信息,确保数据质量符合您的预期,并确保您已确定在创建模型时需要排除的所有列。
如需了解详情,请参阅分析训练数据。
如果对数据集架构感到满意,请点击屏幕顶部的训练模型。
在您更改架构时,AutoML Tables 会更新摘要统计信息,此过程可能需要一段时间才能完成。您无需等待该过程完成即可开始训练模型。
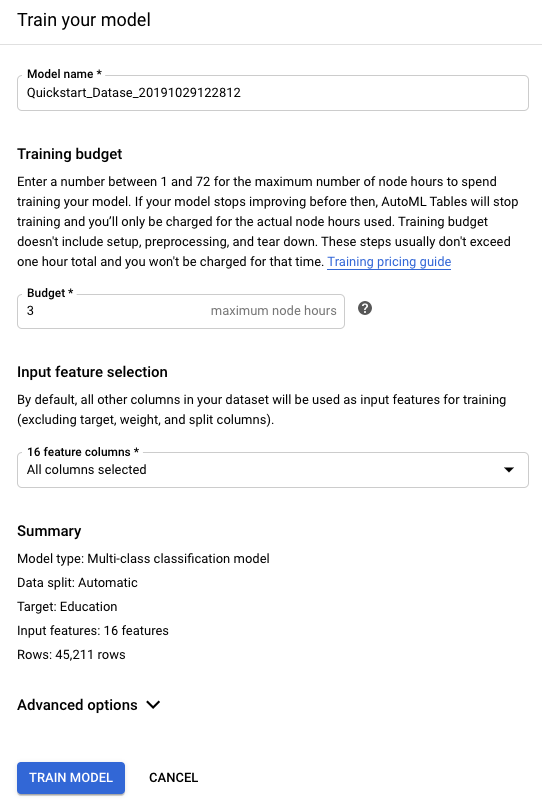
对于训练预算,请输入此模型的训练时长上限。
训练预算在 1 至 72 小时之间。这是您需要为之付费的训练时间上限。
建议的训练时间与训练数据的大小有关。下表按行数显示了建议的训练时间范围;列数较多则训练时间更长。
行数 建议的训练时间 少于 10 万 1 - 3 小时 10 万 - 100 万 1 - 6 小时 100 万 - 1000 万 1 - 12 小时 超过 1000 万 3 - 24 小时 除了训练之外,模型创建还涉及其他任务,因此创建模型所需的总时间比训练时间长。例如,如果您指定训练时间为 2 小时,则在模型可部署之前可能需要 3 个小时或更长时间。您只需为实际训练时间付费。
如果 AutoML Tables 在训练预算用尽之前检测到模型已达到改进上限,则会停止训练。如果您希望用完训练预算时长,请打开高级选项并停用早停法。
在输入特征选择部分中,排除要在架构分析步骤中排除的所有列。
如果您不想使用默认优化目标,请打开高级选项,然后选择您希望 AutoML Tables 在训练模型时进行优化的指标。了解详情。
根据目标列的数据类型,优化目标可能只有一个选项。
点击训练模型,开始训练模型。
训练模型可能需要几个小时才能完成,具体取决于数据集的大小和训练预算。关闭浏览器窗口不影响训练过程。
模型成功完成训练后,模型标签页将显示模型的概要指标,例如精确率和召回率。
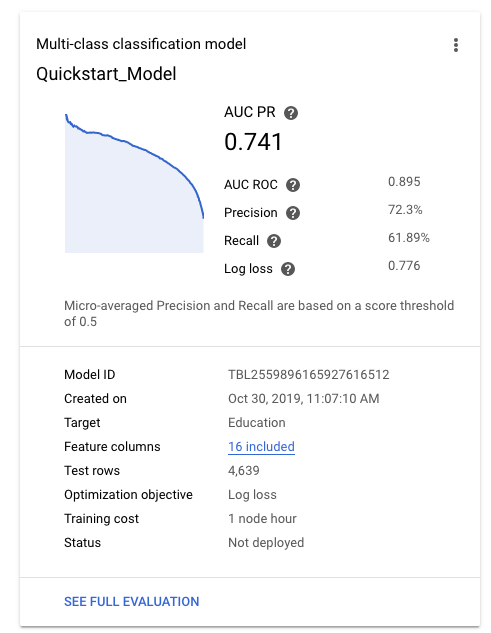
若在评估模型质量方面需要帮助,请参阅评估模型。
REST
以下示例显示了在训练模型之前如何查看和更新数据架构。
如果资源位于欧盟地区,请对 {location} 使用 eu,并使用 eu-automl.googleapis.com 端点。否则,请使用 us-central1。了解详情。
导入完成后,列出表格规范以获取您的表 ID。
在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 -
dataset-id:数据集的 ID。例如,
TBL6543。
HTTP 方法和网址:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
如需发送您的请求,请展开以下选项之一:
表 ID 在
name字段中加粗显示。-
endpoint:全球位置为
列出您的列规范。
在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 -
dataset-id:数据集的 ID。例如,
TBL6543。 - table-id:表的 ID。
HTTP 方法和网址:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
如需发送您的请求,请展开以下选项之一:
-
endpoint:全球位置为
您也可选择配置目标列。
这是要训练模型进行预测的值。其数据类型确定生成的模型是回归(数值)模型还是分类(类别)模型。了解详情。
如果目标列的数据类型为“分类”,则必须至少包含 2 个且不超过 500 个非重复值。
您还可以在训练模型时指定目标列。如果您打算采用这一方式,请保留表 ID 和所需的目标列 ID 供稍后使用。
在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 - dataset-id:您的数据集的 ID。
- target-column-id:您的目标列的 ID。
HTTP 方法和网址:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
请求 JSON 正文:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }如需发送您的请求,请展开以下选项之一:
-
endpoint:全球位置为
(可选)您可更新
mlUseColumnSpecId字段以指定数据拆分,更新weightColumnSpecId字段以使用权重列。在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 - dataset-id:您的数据集的 ID。
- split-column-id:您的目标列的 ID。
- weight-column-id:您的目标列的 ID。
HTTP 方法和网址:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
请求 JSON 正文:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }如需发送您的请求,请展开以下选项之一:
-
endpoint:全球位置为
检查列统计信息,确保
dataType值和nullable的列值正确。如果某个字段标记为“不可为 Null”,则表示它在训练数据集中没有 Null 值。确保您的预测数据也是如此;如果某列标记为“不可为 Null”,而在预测时未为其提供值,则该行会返回预测错误。
检查数据质量。
训练模型。
在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 - dataset-id:数据集 ID。
- table-id:表 ID,用于设置目标列。
- target-column-id:目标列的 ID。
- model-display-name:新模型的显示名。
-
将 optimization-objective 替换为要优化的指标(可选)。
请参阅模型优化目标简介。
-
将 train-budget-milli-node-hours 替换为训练的节点时数的 1000 倍。例如,1000 = 1 小时。
建议的训练时间与训练数据的大小有关。下表按行数显示了建议的训练时间范围;列数较多则训练时间更长。
行数 建议的训练时间 少于 10 万 1 - 3 小时 10 万 - 100 万 1 - 6 小时 100 万 - 1000 万 1 - 12 小时 超过 1000 万 3 - 24 小时 除了训练之外,模型创建还涉及其他任务,因此创建模型所需的总时间比训练时间长。例如,如果您指定训练时间为 2 小时,则在模型可部署之前可能需要 3 个小时或更长时间。您只需为实际训练时间付费。
如果 AutoML Tables 在训练预算用尽之前检测到模型已达到改进上限,则会停止训练。如果您希望用完训练预算时长,请将
tablesModelMetadata对象的disableEarlyStopping属性设置为true。
HTTP 方法和网址:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
请求 JSON 正文:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }模型训练操作运行时间较长。您可以轮询操作状态或等待操作返回。了解详情。
-
endpoint:全球位置为
Java
如果资源位于欧盟区域,您必须明确设置端点。了解详情。
Node.js
如果资源位于欧盟区域,您必须明确设置端点。了解详情。
Python
AutoML Tables 的客户端库包含其他 Python 方法,这些方法使用 AutoML Tables API 进行简化。这些方法按名称而不是 ID 来引用数据集和模型。您的数据集和模型的名称必须是唯一的。如需了解详情,请参阅客户端参考。
如果资源位于欧盟区域,您必须明确设置端点。了解详情。
检查架构
AutoML Tables 根据原始数据类型(如果是从 BigQuery 导入的)和列中的值来推断各列的数据类型以及列是否可以为 Null。您应检查每一列,确保其看起来正确。
使用以下列表来检查您的架构:
包含自由格式文本的字段应为“文本”类型。
文本字段由 UnicodeScriptTokenizer 分隔为词法单元,各个词法单元用于模型训练。UnicodeScriptTokenizer 使用空格符对文本进行分词,同时还将标点与文本分隔,并使不同语言彼此分隔。
如果列值属于一组有限值,则无论该字段中使用何种数据类型,其类型都很可能是“分类”。
例如,您可能使用代码表示颜色:1 = 红色、2 = 黄色等。您应确保将此类字段指定为“分类”。
本规则的一个例外情况是包含多字词字符串的列。在这种情况下,即便基数较低,您也应将其设置为文本列。AutoML Tables 会对文本列进行分词,并且可能能够根据单个词法单元或其顺序获取预测信号。
如果某个字段标记为“不可为 Null”,则表示它在训练数据集中没有 Null 值。确保您的预测数据也是如此;如果某列标记为“不可为 Null”,而在预测时未为其提供值,则该行会返回预测错误。
分析训练数据
如果列的缺失值所占比例较高,请确保这符合您的预期,而不是数据收集问题导致的。
请确保无效值的数量相对较少或为零。
包含一个或多个无效值的行将被自动排除,不用于模型训练。
如果某一“分类”列的非重复值接近行数(例如,超过 90%),则该列将不会提供太多训练信号。应从训练中排除该列。应始终排除 ID 列。
如果列与目标值的相关性很高,请确保这符合预期,而不是目标泄露的迹象。
如果该列在请求预测时可用,那么它可能是解释性较强的特征,因而可包含在内。然而,有时相关性较高的特征实际上来自于目标或是在事后收集的。必须从训练中排除这些特征,因为它们在预测时不可用,会导致模型无法在生产环境中使用。
相关性是通过 Cramér's V 针对分类列、数值列和时间戳列计算得出的。对于数值列,则使用分位数生成的分区数量来计算。
模型优化目标简介
优化目标会影响模型的训练方式,从而影响它在生产环境中的表现。下表提供了各个目标最适合的问题类型的一些详细信息:
| 优化目标 | 问题类型 | API 值 | 在什么情况下使用该目标 |
|---|---|---|---|
| AUC ROC | 分类 | MAXIMIZE_AU_ROC |
区分不同的类别。二元分类的默认值。 |
| 对数损失 | 分类 | MINIMIZE_LOG_LOSS |
使预测概率尽可能准确。仅限于支持的多类别分类目标。 |
| AUC PR | 分类 | MAXIMIZE_AU_PRC |
优化不常见类别的预测结果。 |
| 特定召回率下的精确率 | 分类 | MAXIMIZE_PRECISION_AT_RECALL |
优化特定召回值下的精确率。 |
| 特定精确率下的召回率 | 分类 | MAXIMIZE_RECALL_AT_PRECISION |
优化特定精确率下的召回率。 |
| RMSE | 回归 | MINIMIZE_RMSE |
准确捕捉更多极值。 |
| MAE | 回归 | MINIMIZE_MAE |
将极值视为对模型影响较小的离群值。 |
| RMSLE | 回归 | MINIMIZE_RMSLE |
根据相对误差而不是绝对误差来判错。特别适用于预测值和实际值都非常大的情况。 |