Nesta página, você verá como usar o AutoML Tables para treinar um modelo personalizado com base no seu conjunto de dados. É preciso que você já tenha criado um conjunto de dados e importado dados para ele.
Introdução
Para criar um modelo personalizado, treine-o usando um conjunto de dados preparado. O AutoML Tables usa os itens do conjunto de dados para treinar o modelo, testá-lo e avaliar o desempenho dele. Analise os resultados, ajuste o conjunto de dados de treinamento conforme necessário e treine um novo modelo usando o conjunto de dados aprimorado.
Como parte da preparação para treinar um modelo, atualize as informações de esquema do conjunto de dados. Essas atualizações de esquema afetam qualquer modelo futuro que use esse conjunto de dados. Os modelos que já começaram o treinamento não são afetados.
Esse processo pode levar várias horas para ser concluído. Verifique o progresso do treinamento no console do Google Cloud ou usando a API Cloud AutoML.
Como o AutoML Tables cria um novo modelo cada vez que você inicia o treinamento, seu projeto pode incluir vários modelos. É possível extrair uma lista dos modelos no projeto e excluir os que não forem necessários.
Os modelos precisam ser treinados novamente a cada seis meses para que possam continuar exibindo previsões.
Como treinar um modelo
Console
Se necessário, abra a página Conjuntos de dados e clique no conjunto de dados que você quer usar.
Isso abre o conjunto de dados na guia Treinar.
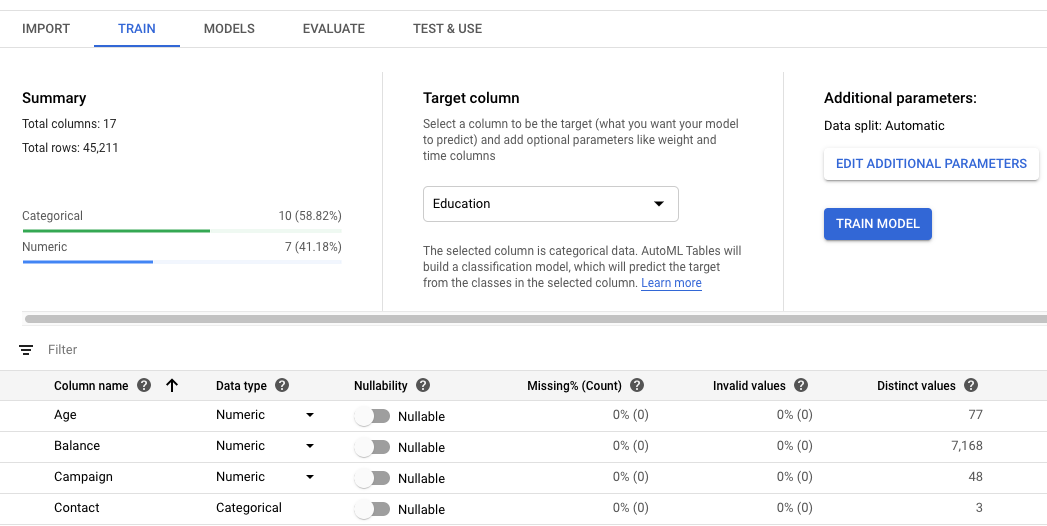
Selecione a coluna de destino do seu modelo.
Esse é o valor que o modelo é treinado para prever. O tipo de dados determina se o modelo resultante é de regressão (numérico) ou de classificação (categórico). Saiba mais.
Se a coluna de objetivo tiver um tipo de dados categórico, ela precisará ter pelo menos dois e no máximo 500 valores distintos.
Revise Tipo de dados, Nulidade e as estatísticas de dados de cada coluna do seu conjunto de dados.
Clique em colunas individuais para ver mais detalhes sobre a coluna. Saiba mais sobre revisão do esquema.
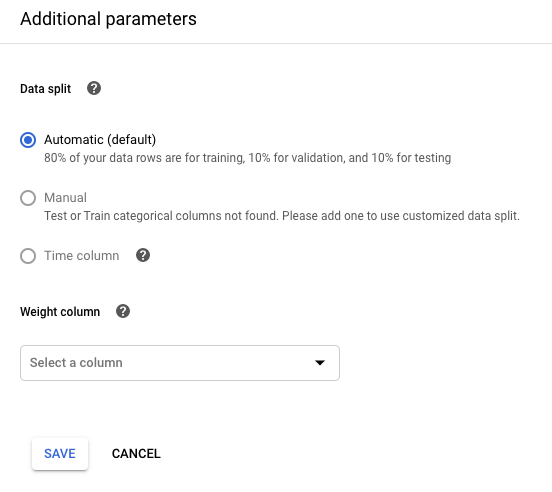
Para controlar sua divisão de dados, clique em Editar parâmetros adicionais e especifique uma coluna de divisão de dados ou uma coluna Data/hora. Saiba mais
Para ponderar seus exemplos de treinamento pelo valor de uma coluna, clique em Editar parâmetros adicionais e especifique a coluna apropriada. Saiba mais
Revise as estatísticas resumidas e os detalhes para ter certeza de que a qualidade de dados seja a esperada e que você identificou qualquer coluna que precise ser excluída ao criar seu modelo.
Para mais informações, consulte Como analisar os dados de treinamento.
Quando estiver satisfeito com seu esquema do conjunto de dados, clique em Treinar modelo, na parte superior da tela.
Quando você faz alterações no seu esquema, o AutoML Tables atualiza as estatísticas de resumo, o que pode demorar alguns minutos até a conclusão. Você não precisa aguardar a conclusão desse processo para iniciar o treinamento do modelo.
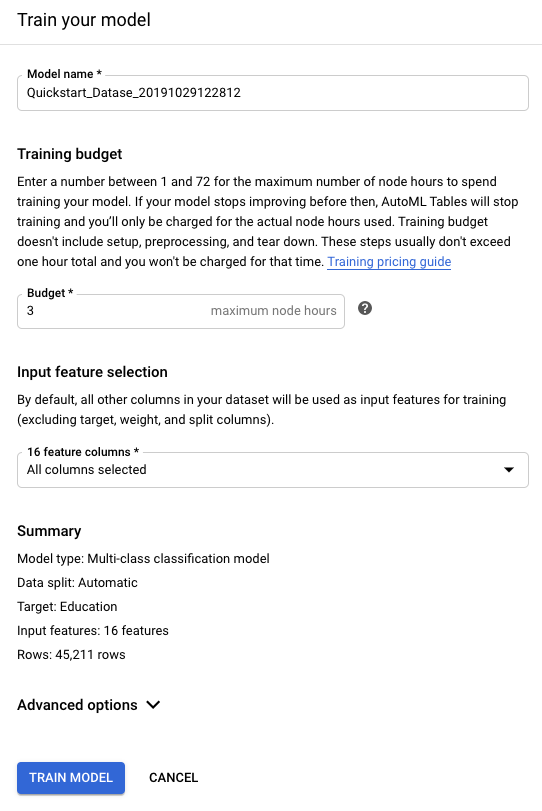
Em Orçamento do treinamento, insira o número máximo de horas de treinamento para o modelo em questão.
O orçamento de treinamento é definido entre 1 e 72 horas. Essa é a quantidade de tempo de treinamento máxima cobrada.
O tempo de treinamento sugerido está relacionado ao tamanho dos seus dados de treinamento. A tabela abaixo mostra os intervalos de tempo de treinamento sugeridos por contagem de linhas; um número de colunas muito grande também aumentará o tempo de treinamento.
Linhas Tempo de treinamento sugerido Inferior a 100.000 1 a 3 horas 100.000 a 1.000.000 1 a 6 horas 1.000.000 a 10.000.000 1 a 12 horas Superior a 10.000.000 3 a 24 horas A criação de modelos inclui outras tarefas além do treinamento. Portanto, o tempo total necessário para criar o modelo é maior que o tempo de treinamento. Por exemplo, se você especificar duas horas de treinamento, ainda poderá levar três ou mais horas para que o modelo esteja pronto para implantação. Você receberá a cobrança apenas pelo tempo de treinamento real.
Saiba mais sobre os preços de treinamento.
Se o AutoML Tables detectar que o modelo não está mais sendo aprimorado, ele interrompe o treinamento antes que o orçamento de treinamento tenha se esgotado. Se você quiser usar todo o tempo de treinamento orçado, abra Opções avançadas e desative a Parada antecipada.
Na seção Seleção de atributos de entrada, exclua todas as colunas que você identificou para remoção na etapa de análise do esquema.
Se você não quiser usar o objetivo de otimização padrão, abra Opções avançadas e selecione a métrica que você quer que o AutoML Tables otimize durante o treinamento do modelo. Saiba mais
Dependendo do tipo de dados da coluna de objetivo, talvez haja apenas uma opção de Objetivo de otimização.
Clique em Treinar modelo para iniciar o treinamento do modelo.
O processo de treinamento do modelo pode levar várias horas para ser concluído, dependendo do tamanho do conjunto de dados e do orçamento de treinamento. Fechar a janela do navegador não afetará o processo.
Após o treinamento bem-sucedido do modelo, a guia Modelos mostra métricas de alto nível do modelo, como precisão e recall.
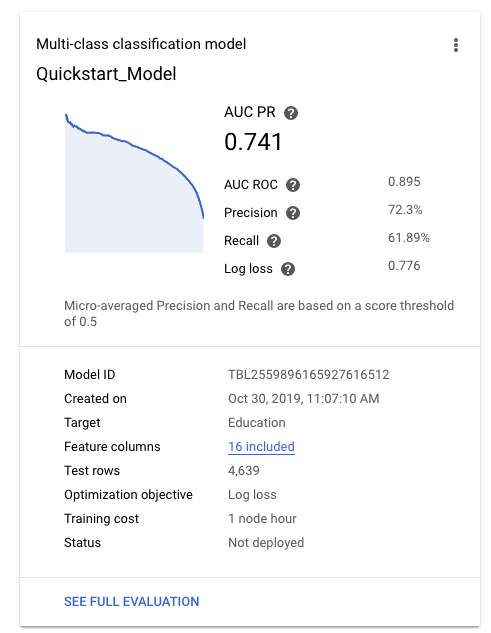
Se você precisar de ajuda para avaliar a qualidade do modelo, consulte Como avaliar modelos.
REST
O exemplo a seguir mostra como é possível revisar e atualizar seu esquema de dados antes de treinar o modelo.
Se os recursos estiverem localizados na região da UE, use eu para {location} e o endpoint eu-automl.googleapis.com. Do contrário, use us-central1.
Saiba mais.
Após a conclusão da importação, liste as especificações da tabela para receber o ID da tabela.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. -
dataset-id: o código do conjunto de dados. Por exemplo,
TBL6543.
Método HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
Para enviar a solicitação, expanda uma destas opções:
O ID da tabela é exibido em negrito no campo
name.-
endpoint:
Liste as especificações de coluna.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. -
dataset-id: o código do conjunto de dados. Por exemplo,
TBL6543. - table-id: o código da tabela.
Método HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
Para enviar a solicitação, expanda uma destas opções:
-
endpoint:
Opcionalmente, configure sua coluna de destino.
Esse é o valor que o modelo é treinado para prever. O tipo de dados determina se o modelo resultante é de regressão (numérico) ou de classificação (categórico). Saiba mais.
Se a coluna de objetivo tiver um tipo de dados categórico, ela precisará ter pelo menos dois e no máximo 500 valores distintos.
Ao treinar o modelo, também é possível especificar a coluna de destino. Se você planeja fazer isso, mantenha o ID da tabela e o ID da coluna de destino que você quer para usar posteriormente.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - dataset-id: o código do conjunto de dados.
- target-column-id: o código da coluna de destino.
Método HTTP e URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Corpo JSON da solicitação:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }Para enviar a solicitação, expanda uma destas opções:
-
endpoint:
Como opção, atualize o campo
mlUseColumnSpecIdpara especificar sua divisão de dados e o campoweightColumnSpecIdpara usar uma coluna de peso.Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - dataset-id: o código do conjunto de dados.
- split-column-id: o código da coluna de destino.
- weight-column-id: o código da coluna de destino.
Método HTTP e URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Corpo JSON da solicitação:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }Para enviar a solicitação, expanda uma destas opções:
-
endpoint:
Revise as estatísticas de coluna para garantir que os valores
dataTypeestão corretos e que as colunas tenham o valor correto paranullable.Se um campo estiver marcado como não anulável, isso quer dizer que não há valores nulos no conjunto de dados de treinamento. Garanta que isso também seja válido para os dados de previsão. Se uma coluna estiver marcada como não anulável e não for fornecido um valor para ela no momento da previsão, nenhuma previsão será retornada para essa linha.
Analise a qualidade dos seus dados.
Treine o modelo.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - dataset-id: o código do conjunto de dados.
- table-id: o código da tabela, usado para definir a coluna de destino.
- target-column-id: o código da coluna de destino.
- model-display-name: o nome de exibição do novo modelo.
-
optimization-objective pela métrica a ser otimizada (opcional).
-
train-budget-milli-node-hours pelo número de mili-node-horas para treinamento. Por exemplo, 1.000 = 1 hora.
O tempo de treinamento sugerido está relacionado ao tamanho dos seus dados de treinamento. A tabela abaixo mostra os intervalos de tempo de treinamento sugeridos por contagem de linhas; um número de colunas muito grande também aumentará o tempo de treinamento.
Linhas Tempo de treinamento sugerido Inferior a 100.000 1 a 3 horas 100.000 a 1.000.000 1 a 6 horas 1.000.000 a 10.000.000 1 a 12 horas Superior a 10.000.000 3 a 24 horas A criação de modelos inclui outras tarefas além do treinamento. Portanto, o tempo total necessário para criar o modelo é maior que o tempo de treinamento. Por exemplo, se você especificar duas horas de treinamento, ainda poderá levar três ou mais horas para que o modelo esteja pronto para implantação. Você receberá a cobrança apenas pelo tempo de treinamento real.
Saiba mais sobre os preços de treinamento.
O treinamento será interrompido se o AutoML Tables detectar que o modelo não está mais sendo aprimorado e isso ocorrer antes do esgotamento do orçamento de treinamento. Se você quiser usar todo o tempo de treinamento orçado, defina a propriedade
disableEarlyStoppingno objetotablesModelMetadatacomotrue.
Método HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
Corpo JSON da solicitação:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }O treinamento de um modelo é uma operação de longa duração. É possível pesquisar o status de uma operação ou esperar que ela seja retornada. Saiba mais.
-
endpoint:
Java
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Node.js
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Python
A biblioteca de cliente para AutoML Tables inclui outros métodos Python que simplificam o uso da API AutoML Tables. Esses métodos se referem aos conjuntos de dados e aos modelos pelos nomes e não pelos IDs. É preciso que os nomes dos conjuntos de dados e modelos sejam exclusivos. Para mais informações, consulte a Referência do cliente.
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Revisão do esquema
O AutoML Tables infere o tipo de dados e se uma coluna é anulável, para cada coluna, com base no tipo de dados original (se importado do BigQuery) e nos valores da coluna. Analise todas as colunas e verifique se elas estão corretas.
Siga a lista a seguir ao revisar o esquema:
Os campos com texto de formato livre precisam ser de texto.
Os campos de texto são separados em tokens por UnicodeScriptTokenizer, sendo que os tokens individuais são usados no treinamento do modelo. O UnicodeScriptTokenizer transforma o texto em tokens nos espaços em branco, além de separar a pontuação do texto e separar idiomas diferentes uns dos outros.
Se o valor de uma coluna for um de um conjunto finito de valores, provavelmente deverá ser categórico, independentemente do tipo de dados usado no campo.
Por exemplo, se você usar códigos para representar cores: 1 = vermelho, 2 = amarelo e assim por diante, verifique se esse campo foi designado como categórico.
Uma exceção a essa orientação é quando a coluna contém strings de várias palavras. Nesse caso, defina a coluna como de texto, mesmo que ela tenha baixa cardinalidade. O AutoML Tables transforma as colunas de texto em tokens e talvez seja capaz de derivar o sinal de previsão a partir dos tokens individuais ou da ordem deles.
Se um campo estiver marcado como não anulável, isso quer dizer que não há valores nulos no conjunto de dados de treinamento. Garanta que isso também seja válido para os dados de previsão. Se uma coluna estiver marcada como não anulável e não for fornecido um valor para ela no momento da previsão, nenhuma previsão será retornada para essa linha.
Como analisar os dados de treinamento
Se uma coluna tiver uma alta porcentagem de valores ausentes, verifique se isso é esperado e não se deve a um problema de coleta de dados.
Verifique se o número de valores inválidos é relativamente baixo ou igual a zero.
Qualquer linha com um ou mais valores inválidos é automaticamente excluída do treinamento do modelo.
Se os valores distintos de uma coluna categórica se aproximarem do número de linhas, (mais de 90%, por exemplo) essa coluna não fornecerá sinal de treinamento. Ela deve ser excluída do treinamento. As colunas de ID sempre devem ser excluídas.
Se o valor correlação com objetivo de uma coluna for alto, verifique se isso é esperado e não se deve a uma indicação de vazamento de objetivo.
Se a coluna estiver disponível quando você solicitar as predições, ela provavelmente será um atributo com forte poder explicativo e poderá ser incluída. No entanto, às vezes, os atributos com alta correlação são, na verdade, derivados do objetivo ou coletados após o fato. Esses recursos precisam ser excluídos do treinamento porque não estão disponíveis no momento da previsão, de modo que o modelo não pode ser usado na produção.
A correlação é calculada para colunas categóricas, numéricas e de carimbo de data/hora, usando o V de Camér. No caso de colunas numéricas, esse valor é calculado usando contagens de bucket geradas a partir de quantis.
Sobre os objetivos de otimização do modelo
O objetivo de otimização afeta como o modelo é treinado e, portanto, o desempenho dele em produção. Veja na tabela abaixo alguns detalhes sobre qual objetivo é mais adequado a diferentes tipos de problemas:
| Objetivo de otimização | Tipo de problema | Valor da API | Use este objetivo se você quiser... |
|---|---|---|---|
| AUC ROC | Classificação | MAXIMIZE_AU_ROC |
Distinguir entre classes. Valor padrão para classificação binária. |
| Log Perda | Classificação | MINIMIZE_LOG_LOSS |
Manter o máximo possível de precisão nas probabilidades de predição. É o único objetivo compatível com a classificação multiclasse. |
| AUC PR | Classificação | MAXIMIZE_AU_PRC |
Otimizar resultados para predições da classe menos comum. |
| Precisão em recall | Classificação | MAXIMIZE_PRECISION_AT_RECALL |
Otimize a precisão com um valor de recall específico. |
| Recall na precisão | Classificação | MAXIMIZE_RECALL_AT_PRECISION |
Otimizar recall em um valor de precisão específico. |
| REMQ | Regressão | MINIMIZE_RMSE |
Capturar valores mais extremos com mais acurácia. |
| MAE | Regressão | MINIMIZE_MAE |
Ver os valores extremos, como outliers, com menos impacto no modelo. |
| RMSLE | Regressão | MINIMIZE_RMSLE |
Penalizar o erro conforme o tamanho relativo, e não o valor absoluto. É útil, principalmente quando tanto os valores previstos quanto os reais são muito grandes. |
A seguir
- Examine a arquitetura do modelo.
- Avalie o modelo.
- Receba predições em lote do modelo.
- Receba previsões on-line do modelo.
- Exportar seu modelo.
- Saiba mais sobre como usar operações de longa duração.