En esta página se describe cómo usar AutoML Tables para entrenar un modelo personalizado en función de tu conjunto de datos. Ya debes haber creado un conjunto de datos y haberle importado datos.
Introducción
Para crear un modelo personalizado, debes entrenarlo con un conjunto de datos preparado. AutoML Tables usa los elementos del conjunto de datos para entrenar el modelo, probarlo y evaluar su rendimiento. Puedes revisar los resultados, ajustar el conjunto de datos de entrenamiento según sea necesario y entrenar un nuevo modelo con el conjunto de datos mejorado.
Como parte de la preparación para entrenar un modelo, debes actualizar la información de esquema del conjunto de datos. Estas actualizaciones de esquema afectan a cualquier modelo futuro que use ese conjunto de datos. Los modelos que ya se comenzaron a entrenar no se verán afectados.
El entrenamiento de un modelo puede tomar varias horas en completarse. Puedes verificar el progreso del entrenamiento en la consola de Google Cloud o con la API de Cloud AutoML.
Debido a que AutoML Tables crea un modelo nuevo cada vez que comienzas el entrenamiento, tu proyecto puede incluir varios modelos. Puedes obtener una lista de los modelos en tu proyecto y borrar modelos que ya no necesites.
Los modelos se deben volver a entrenar cada seis meses para que puedan seguir entregando predicciones.
El entrenamiento de un modelo.
Console
Si es necesario, abre la página Conjuntos de datos y haz clic en el conjunto de datos que deseas usar.
Se abrirá el conjunto de datos en la pestaña Entrenar (Train).
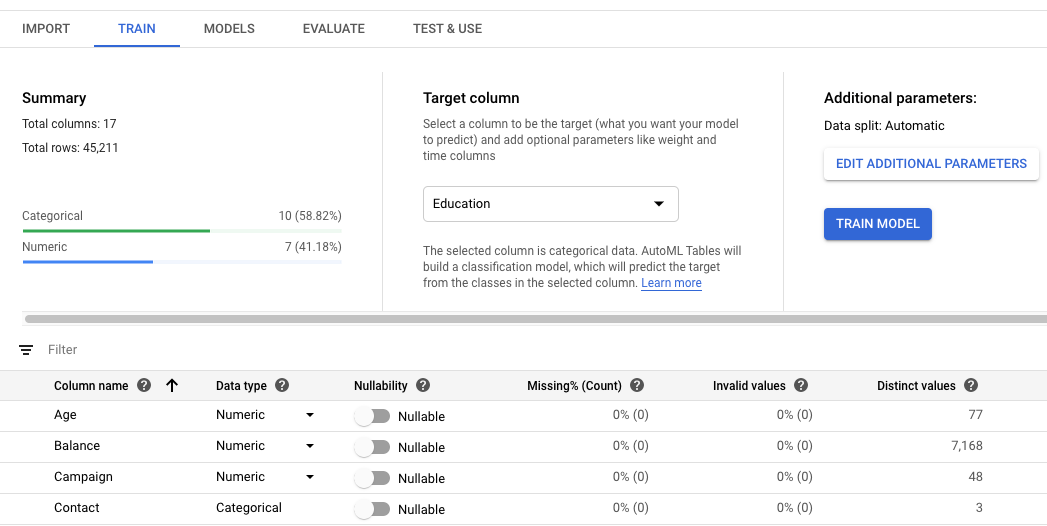
Selecciona la columna objetivo para tu modelo.
Este es el valor que el modelo está entrenado para predecir. El tipo de datos determina si el modelo resultante es un modelo de regresión (numérico) o de clasificación (categórico). Más información.
Si tu columna objetivo tiene un tipo de datos categórico, debe tener al menos dos valores distintos y no más de 500.
Revisa Tipo de datos (Data type), Nulidad (Nullability) y las estadísticas de datos de cada columna de tu conjunto de datos.
Puedes hacer clic en las columnas individuales para obtener más detalles sobre esa columna. Obtén más información acerca de la revisión del esquema.
Si deseas controlar tu división de datos, haz clic en Editar parámetros adicionales (Edit additional parameters) y especifica una columna de división de datos o una columna de tiempo. Más información.
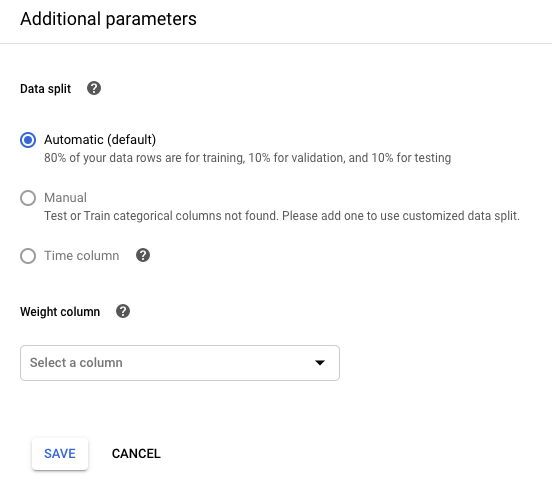
Si deseas ponderar los ejemplos de entrenamiento por el valor de una columna, haz clic en Editar parámetros adicionales (Edit additional parameters) y especifica la columna adecuada. Obtén más información.
Revisa las estadísticas y los detalles del resumen para asegurarte de que la calidad de los datos sea la esperada y de identificar las columnas que deben excluirse cuando creas tu modelo.
Para obtener más información, consulta Analiza los datos de entrenamiento.
Cuando estés satisfecho con el esquema del conjunto de datos, haz clic en Entrenar modelo (Train model) en la parte superior de la pantalla.
Cuando realizas cambios en tu esquema, AutoML Tables actualiza las estadísticas del resumen, que pueden tardar unos minutos en completarse. No es necesario esperar a que se complete este proceso antes de iniciar el entrenamiento de modelos.
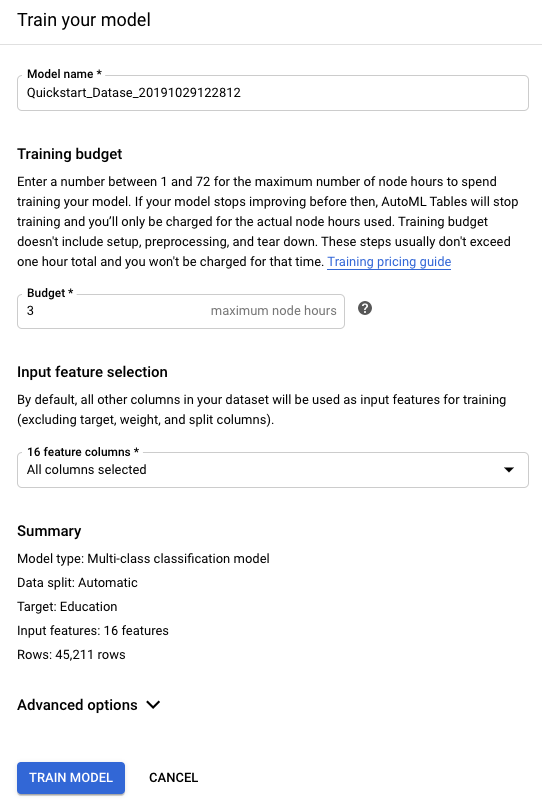
En Presupuesto de entrenamiento (Training budget), ingresa la cantidad máxima de horas de entrenamiento para este modelo.
El presupuesto de entrenamiento es de entre 1 y 72 horas. Esta es la cantidad máxima de tiempo de entrenamiento que se te cobrará.
El tiempo de entrenamiento sugerido se relaciona con el tamaño de los datos de entrenamiento. En la siguiente tabla, se muestran los intervalos de tiempo de entrenamiento sugeridos por conteo de filas; una gran cantidad de columnas también aumentará el tiempo de entrenamiento.
Filas Tiempo de entrenamiento sugerido Menor que 100,000 1-3 horas 100,000-1,000,000 1-6 horas 1,000,000-10,000,000 1-12 horas Más de 10,000,000 3-24 horas La creación del modelo incluye otras tareas aparte del entrenamiento, por lo que el tiempo total que se necesita para crear el modelo es mayor que el tiempo de entrenamiento. Por ejemplo, si especificas 2 horas de entrenamiento, podrían pasar 3 o más horas hasta que el modelo esté listo para implementarse. Solo se te cobra por el tiempo de entrenamiento real.
Obtén más información sobre los precios de entrenamiento.
Si AutoML Tables detecta que el modelo ya no mejora antes de que se agote el presupuesto de entrenamiento, este deja de entrenar. Si deseas usar todo el tiempo de entrenamiento presupuestado, abre Opciones avanzadas (Advanced options) y, luego, inhabilita Interrupción anticipada.
En la sección Seleccionar el atributo de entrada (Input feature selection), excluye las columnas a las que orientaste la exclusión en el paso de análisis del esquema.
Si no deseas usar el objetivo de optimización predeterminado, abre Opciones avanzadas (Advanced options) y selecciona la métrica que deseas que AutoML Tables optimice cuando entrene tu modelo. Más información.
Según el tipo de datos de la columna objetivo, puede haber solo una opción para el Objetivo de optimización.
Haz clic en Entrenar modelo (Train model) para comenzar el entrenamiento de modelos.
El entrenamiento de un modelo puede tardar varias horas en completarse según el tamaño del conjunto de datos y el presupuesto de entrenamiento. Puedes cerrar la ventana del navegador; esto no afectará el proceso de entrenamiento.
Una vez que el modelo se entrenó de forma correcta, la pestaña Modelos (Models) mostrará métricas de alto nivel para el modelo, como precisión y recuperación.
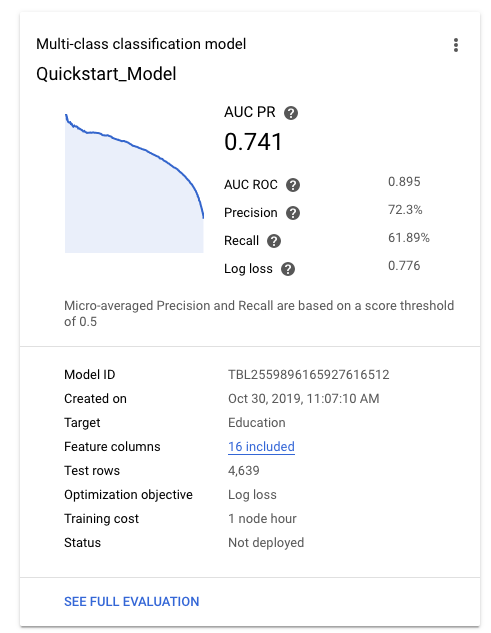
Para obtener ayuda con la evaluación de la calidad de tu modelo, consulta la página sobre cómo evaluar modelos.
REST
En el siguiente ejemplo, se muestra cómo revisar y actualizar el esquema de datos antes de entrenar el modelo.
Si tus recursos se encuentran en la región de la UE, usa eu para {location} y usa el extremo eu-automl.googleapis.com. De lo contrario, usa us-central1.
Más información.
Una vez completada la importación, enumera las especificaciones de la tabla para obtener tu ID de tabla.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea -
dataset-id: el ID del conjunto de datos. Por ejemplo:
TBL6543.
HTTP method and URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
Para enviar tu solicitud, expande una de estas opciones:
El ID de la tabla se muestra en negrita en el campo
name.-
endpoint:
Enumera tus especificaciones de columna.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea -
dataset-id: el ID del conjunto de datos. Por ejemplo:
TBL6543. - table-id: el ID de la tabla.
HTTP method and URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
Para enviar tu solicitud, expande una de estas opciones:
-
endpoint:
De manera opcional, configura tu columna objetivo.
Este es el valor que el modelo está entrenado para predecir. El tipo de datos determina si el modelo resultante es un modelo de regresión (numérico) o de clasificación (categórico). Más información.
Si tu columna objetivo tiene un tipo de datos categórico, debe tener al menos dos valores distintos y no más de 500.
También puedes especificar la columna objetivo cuando entrenes el modelo. Si planeas hacerlo, conserva el ID de la tabla y el ID de la columna objetivo que desees usar más adelante.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - dataset-id: Es el ID del conjunto de datos.
- target-column-id: el ID de la columna de destino.
HTTP method and URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Cuerpo JSON de la solicitud:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }Para enviar tu solicitud, expande una de estas opciones:
-
endpoint:
De forma opcional, actualiza el campo
mlUseColumnSpecIdpara especificar tu división de datos y el campoweightColumnSpecIdpara usar una columna de ponderación.Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - dataset-id: Es el ID del conjunto de datos.
- split-column-id: el ID de la columna de destino.
- weight-column-id: el ID de la columna de destino.
HTTP method and URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Cuerpo JSON de la solicitud:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }Para enviar tu solicitud, expande una de estas opciones:
-
endpoint:
Revisa las estadísticas de las columnas para asegurarte de que los valores
dataTypesean correctos y que las columnas tengan el valor correcto paranullable.Si un campo está marcado como no anulable, significa que no tenía valores nulos para el conjunto de datos de entrenamiento. Asegúrate de que esto también se aplique a tus datos de predicción; si una columna está marcada como no anulable y no se le proporciona un valor en el momento de la predicción, se muestra un error de predicción para esa fila.
Revisa la calidad de los datos.
Obtén más información sobre cómo analizar los datos de entrenamiento.
Entrena el modelo.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - dataset-id: El ID del conjunto de datos.
- table-id: el ID de la tabla, que se usa para establecer la columna de destino.
- target-column-id: el ID de la columna de destino.
- model-display-name: el nombre visible del modelo nuevo.
-
optimization-objective con la métrica que se debe optimizar (opcional).
Consulta Información acerca de los objetivos de optimización del modelo.
-
train-budget-milli-node-hours con la cantidad de milihora de procesamiento de nodo para el entrenamiento. Por ejemplo, 1,000 = 1 hora.
El tiempo de entrenamiento sugerido se relaciona con el tamaño de los datos de entrenamiento. En la siguiente tabla, se muestran los intervalos de tiempo de entrenamiento sugeridos por conteo de filas; una gran cantidad de columnas también aumentará el tiempo de entrenamiento.
Filas Tiempo de entrenamiento sugerido Menor que 100,000 1-3 horas 100,000-1,000,000 1-6 horas 1,000,000-10,000,000 1-12 horas Más de 10,000,000 3-24 horas La creación del modelo incluye otras tareas aparte del entrenamiento, por lo que el tiempo total que se necesita para crear el modelo es mayor que el tiempo de entrenamiento. Por ejemplo, si especificas 2 horas de entrenamiento, podrían pasar 3 o más horas hasta que el modelo esté listo para implementarse. Solo se te cobra por el tiempo de entrenamiento real.
Obtén más información sobre los precios de entrenamiento.
Si AutoML Tables detecta que el modelo ya no mejora antes de que se agote el presupuesto de entrenamiento, este deja de entrenar. Si desea usar todo el tiempo de entrenamiento presupuestado, establece la propiedad
disableEarlyStoppingen el objetotablesModelMetadataentrue.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
Cuerpo JSON de la solicitud:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }El entrenamiento de un modelo es una operación de larga duración. Puedes consultar el estado de la operación o esperar a que esta se muestre. Obtener más información.
-
endpoint:
Java
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Node.js
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Python
La biblioteca cliente de AutoML Tables incluye métodos adicionales de Python que simplifican el uso de la API de AutoML Tables. Estos métodos hacen referencia a conjuntos de datos y modelos por nombre en lugar de ID. El conjunto de datos y los nombres de los modelos deben ser únicos. Para obtener más información, consulta la página de referencia del cliente.
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Revisión del esquema
AutoML Tables infiere el tipo de datos y si una columna es anulable para cada columna según el tipo de datos original (si se importó de BigQuery) y los valores de la columna. Debes revisar cada columna y asegurarte de que sea correcta.
Usa la siguiente lista para revisar tu esquema:
Los campos que contengan texto de formato libre deben ser de texto.
Los campos de texto se separan en tokens con UnicodeScriptTokenizer, y se usan tokens individuales para el entrenamiento del modelo. UnicodeScriptTokenizer hace un token de texto por espacios en blanco, a la vez que separa la puntuación del texto y de los diferentes lenguajes entre sí.
Si el valor de una columna es uno de un conjunto finito de valores, tal vez deba ser categórico, sin importar el tipo de datos usados en el campo.
Por ejemplo, es posible que tengas códigos para los colores: 1 = rojo, 2 = amarillo, y así sucesivamente. Debes asegurarte de que dicho campo se haya designado como categórico.
Una excepción a esta guía es si la columna contiene strings de varias palabras. En este caso, debes establecerlo como una columna de texto, incluso si tiene una cardinalidad baja. AutoML Tables convierte en tokens las columnas de texto y puede derivar la señal de predicción de los tokens individuales o su orden.
Si un campo está marcado como no anulable, significa que no tenía valores nulos para el conjunto de datos de entrenamiento. Asegúrate de que esto también se aplique a tus datos de predicción; si una columna está marcada como no anulable y no se le proporciona un valor en el momento de la predicción, se muestra un error de predicción para esa fila.
Analiza los datos de entrenamiento
Si una columna tiene un alto porcentaje de valores faltantes, asegúrate de que esto sea lo esperado y no un problema de recopilación de datos.
Asegúrate de que la cantidad de valores no válidos sea relativamente baja o nula.
Cualquier fila que contenga uno o más valores no válidos se excluye de forma automática del entrenamiento de modelos.
Si los Valores distintos de una columna categórica se acercan a la cantidad de filas (por ejemplo, más del 90%), esa columna no proporcionará mucha señal de entrenamiento. Debe excluirse del entrenamiento. Las columnas de ID siempre deben excluirse.
Si el valor de Correlación con el objetivo de una columna es alto, asegúrate de que sea lo esperado y no una indicación de filtración de objetivos.
Si la columna estará disponible cuando solicites predicciones, es probable que sea un atributo con un gran poder explicativo y que se pueda incluir. Sin embargo, a veces, los atributos con una alta correlación se derivan del objetivo o se recopilan después del hecho. Estos atributos deben excluirse del entrenamiento, ya que no están disponibles en el momento de la predicción, por lo que el modelo no se puede usar en producción.
La correlación se calcula para columnas categóricas, numéricas y de marca de tiempo con la V de Cramer. En el caso de las columnas numéricas, se calcula con recuentos de bucket generados a partir de cuantiles.
Información acerca de los objetivos de optimización del modelo
El objetivo de optimización influye en la forma en la que se entrena tu modelo y, por lo tanto, en cómo es su rendimiento en la producción. En la siguiente tabla, se proporcionan algunos detalles sobre los tipos de problemas que son más adecuados para cada objetivo:
| Objetivo de optimización | Tipo de problema | Valor de la API | Usa este objetivo si quieres… |
|---|---|---|---|
| AUC ROC | Clasificación | MAXIMIZE_AU_ROC |
Distinguir las clases. Valor predeterminado para la clasificación binaria. |
| Pérdida logística | Clasificación | MINIMIZE_LOG_LOSS |
Mantener las probabilidades de predicción lo más precisas posible. Solo es compatible con la clasificación de clases múltiples. |
| AUC PR | Clasificación | MAXIMIZE_AU_PRC |
Optimizar los resultados para las predicciones de la clase menos común. |
| Precisión en recuperación | Clasificación | MAXIMIZE_PRECISION_AT_RECALL |
Optimizar la precisión en un valor de recuperación específico. |
| Recuperación en precisión | Clasificación | MAXIMIZE_RECALL_AT_PRECISION |
Optimizar la recuperación con un valor de precisión específico. |
| RMSE | Regresión | MINIMIZE_RMSE |
Captura valores más extremos con exactitud. |
| MAE | Regresión | MINIMIZE_MAE |
Observar los valores extremos como valores atípicos con un impacto menor en el modelo. |
| RMSLE | Regresión | MINIMIZE_RMSLE |
Penalizar errores de tamaño relativo en lugar de valor absoluto. De gran utilidad cuando los valores previstos y reales pueden ser bastante grandes. |
¿Qué sigue?
- Examina la arquitectura del modelo.
- Evalúa tu modelo.
- Obtén predicciones por lotes de tu modelo.
- Obtén predicciones en línea de tu modelo.
- Exporta tu modelo.
- Obtén más información sobre cómo usar las operaciones de larga duración.