Auf dieser Seite wird beschrieben, wie Sie mit AutoML Tables ein benutzerdefiniertes Modell basierend auf Ihrem Dataset trainieren. Sie müssen bereits ein Dataset erstellt und darin Daten importiert haben.
Einleitung
Wenn Sie ein benutzerdefiniertes Modell erstellen möchten, trainieren Sie es mithilfe eines vorbereiteten Datasets. Das Modell wird in AutoML Tables mithilfe der Elemente des Datasets trainiert, getestet und hinsichtlich seiner Leistung bewertet. Sie können die Ergebnisse anschließend prüfen, das Trainings-Dataset nach Bedarf anpassen und mithilfe des verbesserten Datasets ein neues Modell trainieren.
Bei der Vorbereitung zum Trainieren eines Modells aktualisieren Sie die Schemainformationen des Datasets. Diese Schemaaktualisierungen wirken sich auf alle zukünftigen Modelle aus, die dieses Dataset verwenden. Modelle, für die das Training bereits gestartet wurde, bleiben davon unberührt.
Das Trainieren eines Modells kann mehrere Stunden dauern. Sie können den Trainingsfortschritt in der Google Cloud Console oder mithilfe der Cloud AutoML API prüfen.
Da AutoML Tables bei jedem Trainingsbeginn ein neues Modell erstellt, enthält Ihr Projekt möglicherweise mehrere Modelle. Sie können eine Liste der Modelle in Ihrem Projekt abrufen und nicht mehr benötigte Modelle löschen.
Modelle müssen alle sechs Monate neu trainiert werden, damit sie weiterhin Vorhersagen bereitstellen können.
Modell trainieren
Console
Öffnen Sie bei Bedarf die Seite Datasets und klicken Sie auf das Dataset, das Sie verwenden möchten.
Dadurch wird das Dataset im Tab Train (Trainieren) geöffnet.
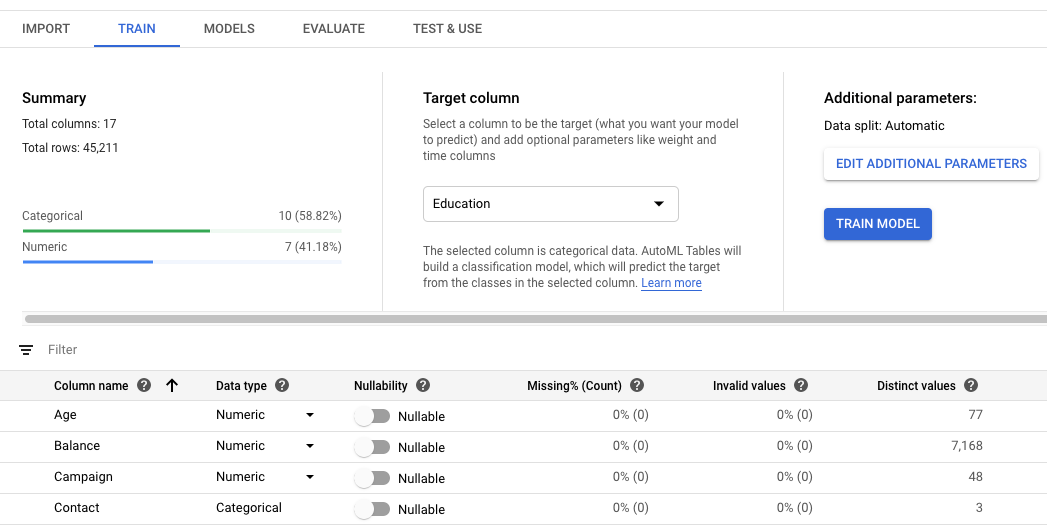
Wählen Sie die Zielspalte für Ihr Modell aus.
Dies ist der Wert, für dessen Vorhersage das Modell trainiert wird. Der zugehörige Datentyp bestimmt, ob das resultierende Modell ein Regressionsmodell (numerisch) oder ein Klassifizierungsmodell (kategorial) ist. Weitere Informationen
Wenn die Zielspalte den Datentyp „Kategorial“ hat, muss sie mindestens zwei und nicht mehr als 500 verschiedene Werte enthalten.
Prüfen Sie den Datentyp, die Null-Zulässigkeit und die Datenstatistik für jede Spalte in Ihrem Dataset.
Sie können auf einzelne Spalten klicken, um weitere Details zu dieser Spalte zu erhalten. Weitere Informationen zur Schemaüberprüfung
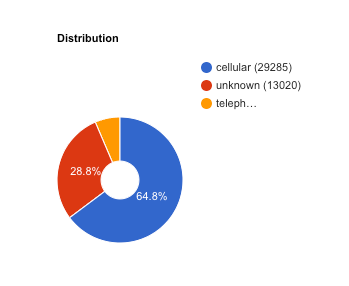
Wenn Sie Ihre Datenaufteilung steuern möchten, klicken Sie auf Edit additional parameters (Zusätzliche Parameter bearbeiten) und geben Sie eine Data split-Spalte (Datenaufteilung) oder eine Time-Spalte (Zeit) an. Weitere Informationen
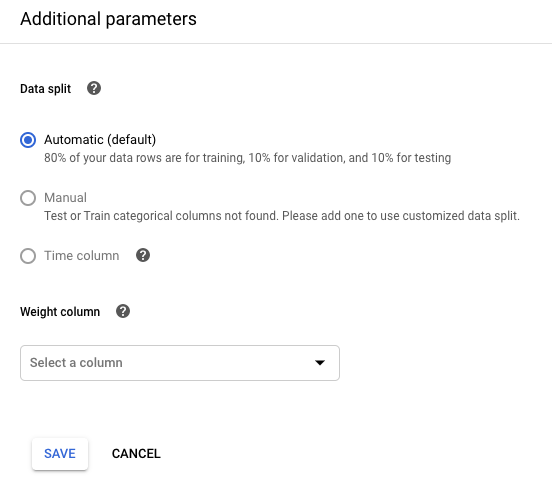
Wenn Sie Ihre Trainingsbeispiele anhand des Werts einer Spalte gewichten möchten, klicken Sie auf Edit additional parameters (Zusätzliche Parameter bearbeiten) und geben Sie die entsprechende Spalte an. Weitere Informationen
Prüfen Sie die zusammengefassten Statistiken und Details, um sicherzustellen, dass die Datenqualität Ihren Erwartungen entspricht und dass Sie alle Spalten identifiziert haben, die bei der Erstellung Ihres Modells ausgeschlossen werden müssen.
Weitere Informationen finden Sie unter Trainingsdaten analysieren.
Wenn Sie mit Ihrem Dataset-Schema zufrieden sind, klicken Sie auf Train model (Modell trainieren) oben auf dem Bildschirm.
Wenn Sie das Schema ändern, werden die zusammengefassten Statistiken in AutoML Tables aktualisiert, was einige Minuten dauern kann. Sie müssen nicht warten, bis dieser Prozess abgeschlossen ist, bevor Sie das Modelltraining starten.
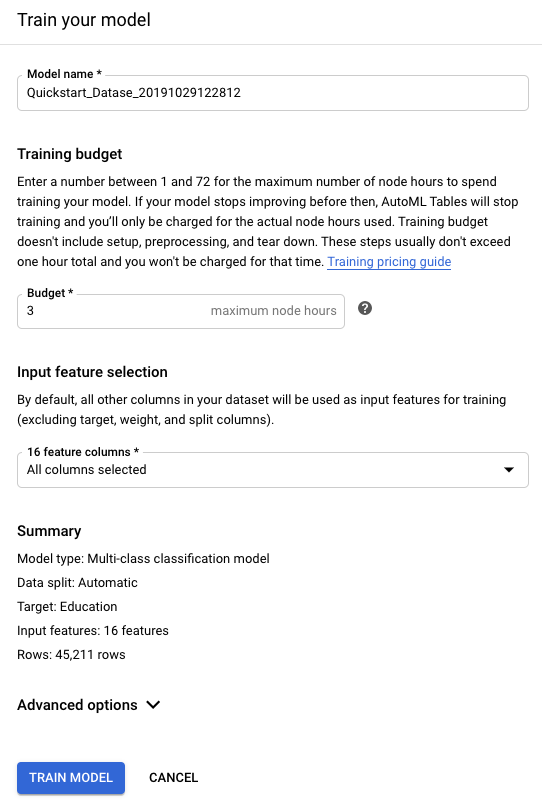
Geben Sie für Training budget (Trainingsbudget) die maximale Anzahl von Trainingsstunden für dieses Modell ein.
Das Trainingsbudget kann zwischen 1 und 72 Stunden liegen. Dies ist die maximale Trainingszeit, die Ihnen in Rechnung gestellt wird.
Die empfohlene Trainingszeit hängt von der Größe der Trainingsdaten ab. Die folgende Tabelle zeigt die empfohlene Trainingszeit nach Zeilenanzahl. Eine große Anzahl von Spalten erhöht auch die Trainingszeit.
Zeilen Vorgeschlagene Trainingszeit Unter 100.000 1–3 Stunden 100.000–1.000.000 1–6 Stunden 1.000.000–10.000.000 1–12 Stunden Über 10.000.000 3–24 Stunden Die Modellerstellung umfasst neben dem Training noch andere Aufgaben, sodass die Gesamtzeit für die Modellerstellung länger als die Trainingszeit ist. Wenn Sie beispielsweise zwei Trainingsstunden angeben, kann es drei Stunden oder länger dauern, bis das Modell einsatzbereit ist. Ihnen wird nur die tatsächliche Trainingszeit in Rechnung gestellt.
Weitere Informationen zu Trainingspreisen
Wenn AutoML Tables erkennt, dass das Modell nicht mehr verbessert wird, bevor das Trainingsbudget aufgebraucht ist, wird das Training beendet. Wenn Sie die gesamte geplante Trainingszeit verwenden möchten, öffnen Sie Advanced options (Erweiterte Optionen) und deaktivieren Sie Early stopping (Vorzeitiges Beenden).
Schließen Sie im Abschnitt Input feature selection (Auswahl des Eingabefeatures) alle Spalten aus, die Sie bereits bei der Schemaanalyse ausgeschlossen haben.
Wenn Sie das standardmäßige Optimierungsziel nicht verwenden möchten, öffnen Sie Advanced options (Erweiterte Optionen) und wählen Sie den Messwert aus, den AutoML Tables beim Trainieren Ihres Modells optimieren soll. Weitere Informationen
Abhängig vom Datentyp der Zielspalte ist unter Optimization objective (Optimierungsziel) möglicherweise nur ein Optimierungsziel angegeben.
Klicken Sie auf Modell trainieren, um mit dem Modelltraining zu beginnen.
Das Modelltraining kann je nach Umfang des Datasets und des Trainingsbudgets mehrere Stunden dauern. Der Trainingsprozess läuft auch weiter, wenn Sie das Browserfenster schließen.
Nach dem erfolgreichen Training des Modells werden im Tab Models (Modelle) allgemeine Messwerte für das Modell wie die Genauigkeit und die Trefferquote angezeigt.
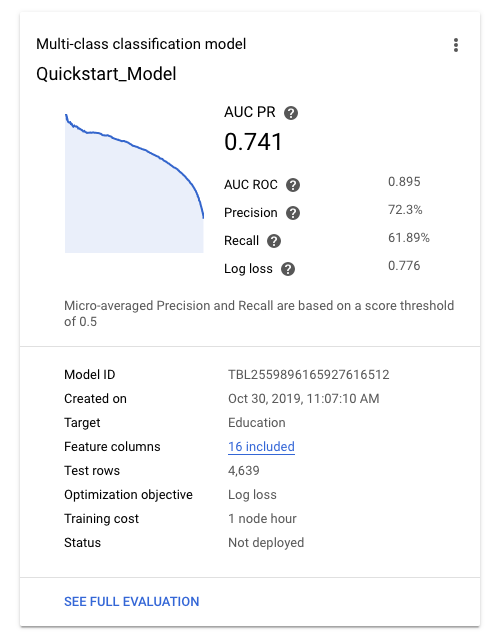
Weitere Informationen zum Bewerten der Modellqualität finden Sie unter Modelle bewerten.
REST
Das folgende Beispiel zeigt, wie Sie das Datenschema vor dem Training Ihres Modells prüfen und aktualisieren können.
Wenn sich Ihre Ressourcen in der EU-Region befinden, verwenden Sie eu für {location} und den Endpunkt eu-automl.googleapis.com. Verwenden Sie andernfalls us-central1
Weitere Informationen
Listen Sie nach Abschluss des Imports die Tabellenspezifikationen auf, um die Tabellen-ID zu erhalten.
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. -
dataset-id: Die ID des Datasets. Beispiel:
TBL6543.
HTTP-Methode und URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Die Tabellen-ID ist im Feld
namefett dargestellt.-
endpoint:
Listen Sie die Spaltenspezifikationen auf.
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. -
dataset-id: Die ID des Datasets. Beispiel:
TBL6543. - table-id: Die ID der Tabelle.
HTTP-Methode und URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
-
endpoint:
Konfigurieren Sie optional Ihre Zielspalte.
Dies ist der Wert, für dessen Vorhersage das Modell trainiert wird. Der zugehörige Datentyp bestimmt, ob das resultierende Modell ein Regressionsmodell (numerisch) oder ein Klassifizierungsmodell (kategorial) ist. Weitere Informationen
Wenn die Zielspalte den Datentyp „Kategorial“ hat, muss sie mindestens zwei und nicht mehr als 500 verschiedene Werte enthalten.
Sie können die Zielspalte auch beim Trainieren des Modells angeben. Behalten Sie dafür die Tabellen-ID und die gewünschte Zielspalten-ID für die spätere Verwendung bei.
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. - dataset-id: Die ID Ihres Datasets.
- target-column-id: Die ID Ihrer Zielspalte.
HTTP-Methode und URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
JSON-Text der Anfrage:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
-
endpoint:
Aktualisieren Sie optional das Feld
mlUseColumnSpecId, um Ihre Datenaufteilung anzugeben, und das FeldweightColumnSpecId, um eine Gewichtungsspalte zu verwenden.Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. - dataset-id: Die ID Ihres Datasets.
- split-column-id: Die ID Ihrer Zielspalte.
- weight-column-id: Die ID Ihrer Zielspalte.
HTTP-Methode und URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
JSON-Text der Anfrage:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
-
endpoint:
Prüfen Sie die Spaltenstatistiken daraufhin, dass die
dataType-Werte korrekt sind und Spalten den richtigen Wert fürnullablehaben.Wenn ein Feld so markiert ist, dass es keine Nullwerte zulässt, bedeutet dies, dass es keine Nullwerte für das Trainings-Dataset enthielt. Achten Sie darauf, dass dies auch für Ihre Vorhersagedaten gilt. Wenn eine Spalte als Spalte markiert ist, die keine Nullwerte zulässt, und wenn bei der Vorhersage kein Wert für sie bereitgestellt wird, wird für diese Zeile ein Vorhersagefehler zurückgegeben.
Prüfen Sie die Datenqualität.
Modell trainieren
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. - dataset-id: Die Dataset-ID.
- table-id: Die Tabellen-ID, mit der die Zielspalte festgelegt wird.
- target-column-id: Die ID der Zielspalte.
- model-display-name: Der Anzeigename für das neue Modell.
-
optimization-objective durch den zu optimierenden Messwert (optional).
Siehe Ziele der Modelloptimierung.
-
train-budget-milli-node-hours durch die Anzahl der Milliknoten-Stunden für das Training. Beispiel: 1.000 = 1 Stunde.
Die empfohlene Trainingszeit hängt von der Größe der Trainingsdaten ab. Die folgende Tabelle zeigt die empfohlene Trainingszeit nach Zeilenanzahl. Eine große Anzahl von Spalten erhöht auch die Trainingszeit.
Zeilen Vorgeschlagene Trainingszeit Unter 100.000 1–3 Stunden 100.000–1.000.000 1–6 Stunden 1.000.000–10.000.000 1–12 Stunden Über 10.000.000 3–24 Stunden Die Modellerstellung umfasst neben dem Training noch andere Aufgaben, sodass die Gesamtzeit für die Modellerstellung länger als die Trainingszeit ist. Wenn Sie beispielsweise zwei Trainingsstunden angeben, kann es drei Stunden oder länger dauern, bis das Modell einsatzbereit ist. Ihnen wird nur die tatsächliche Trainingszeit in Rechnung gestellt.
Weitere Informationen zu Trainingspreisen
Wenn AutoML Tables erkennt, dass das Modell nicht mehr verbessert wird, bevor das Trainingsbudget aufgebraucht ist, wird das Training beendet. Wenn Sie die gesamte geplante Trainingszeit verwenden möchten, setzen Sie das
disableEarlyStopping-Attribut destablesModelMetadata-Objekts auftrue.
HTTP-Methode und URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
JSON-Text der Anfrage:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten in etwa folgende JSON-Antwort erhalten:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }Das Trainieren eines Modells ist ein langwieriger Vorgang. Sie können den Vorgangsstatus abfragen oder warten, bis der Vorgang beendet ist. Weitere Informationen
-
endpoint:
Java
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Node.js
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Python
Die Clientbibliothek für AutoML Tables enthält zusätzliche Python-Methoden, die die Verwendung der AutoML Tables API vereinfachen. Diese Methoden verweisen auf Datasets und Modelle anhand des Namens und nicht der ID. Dataset- und Modellnamen dürfen nur einmal vorkommen. Weitere Informationen finden Sie in der Kundenreferenz.
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Schemas prüfen
AutoML Tables leitet den Datentyp und ob eine Spalte für jede Spalte zulässige Nullwerte hat, mithilfe des ursprünglichen Datentyps (wenn er von BigQuery importiert wurde) und der Werte in der Spalte ab. Sie sollten jede Spalte auf ihre Richtigkeit prüfen.
Prüfen Sie Ihr Schema anhand der folgenden Liste:
Felder, die Freitext enthalten, sollten vom Typ "Text" sein.
Textfelder werden durch UnicodeScriptTokenizer in Tokens unterteilt, wobei einzelne Tokens für das Modelltraining verwendet werden. Der UnicodeScriptTokenizer tokenisiert Text nach Leerzeichen, trennt aber auch Satzzeichen vom Text und verschiedenen Sprachen voneinander.
Wenn der Wert einer Spalte einem einer endlichen Reihe von Werten entspricht, sollte er unabhängig vom Typ der im Feld verwendeten Daten wahrscheinlich kategorial sein.
Sie könnten zum Beispiel Codes für Farben haben: 1 = rot, 2 = gelb usw. Achten Sie darauf, dass ein solches Feld als "kategorial" gekennzeichnet wurde.
Eine Ausnahme zu dieser Anleitung ist gegeben, wenn die Spalte Strings mit mehreren Wörtern enthält. In diesem Fall sollten Sie sie als Textspalte festlegen, selbst wenn sie eine geringe Kardinalität hat. AutoML Tables tokenisiert Textspalten und ist möglicherweise in der Lage, das Vorhersagesignal aus den einzelnen Tokens oder aus ihrer Reihenfolge abzuleiten.
Wenn ein Feld so markiert ist, dass es keine Nullwerte zulässt, bedeutet dies, dass es keine Nullwerte für das Trainings-Dataset enthielt. Achten Sie darauf, dass dies auch für Ihre Vorhersagedaten gilt. Wenn eine Spalte als Spalte markiert ist, die keine Nullwerte zulässt, und wenn bei der Vorhersage kein Wert für sie bereitgestellt wird, wird für diese Zeile ein Vorhersagefehler zurückgegeben.
Trainingsdaten analysieren
Wenn eine Spalte einen hohen Prozentsatz an fehlenden Werten aufweist, prüfen Sie, ob dies den Erwartungen entspricht und sich kein Datenerfassungsproblem dahinter verbirgt.
Achten Sie darauf, dass die Anzahl der ungültigen Werte relativ niedrig oder null ist.
Jede Zeile, die einen oder mehrere ungültige Werte enthält, wird automatisch für das Modelltraining ausgeschlossen.
Wenn unterschiedliche Werte für eine kategoriale Spalte sich der Anzahl der Zeilen annähern (z. B. mehr als 90 %), liefert diese Spalte nicht viel Trainingssignal. Sie sollte vom Training ausgeschlossen werden. ID-Spalten sollten immer ausgeschlossen werden.
Wenn der Wert für Correlation with Target (Korrelation mit Ziel) hoch ist, prüfen Sie, ob dies den Erwartungen entspricht und nicht etwa ein Hinweis auf ein Datenleck ist.
Wenn die Spalte beim Anfordern von Vorhersagen verfügbar ist, ist sie wahrscheinlich ein Feature mit starker Aussagekraft und kann einbezogen werden. Manchmal werden Features mit hoher Korrelation jedoch tatsächlich vom Ziel abgeleitet oder nachträglich erfasst. Diese Features müssen vom Training ausgeschlossen werden, da sie zum Zeitpunkt der Vorhersage nicht verfügbar sind, sodass das Modell in der Produktion nicht verwendet werden kann.
Die Korrelation wird für kategoriale, numerische und Zeitstempelspalten mithilfe von Cramérs V berechnet. Bei numerischen Spalten wird sie anhand der aus Quantilen generierten Bucket-Anzahl berechnet.
Ziele der Modelloptimierung
Das Optimierungsziel beeinflusst, wie das Modell trainiert wird und somit dessen Leistung in der Produktion. In der folgenden Tabelle finden Sie Details zu den Zielen, die sich am besten für ein bestimmtes Problem eignen:
| Optimierungsziel | Problemtyp | API-Wert | Zweck |
|---|---|---|---|
| AUC ROC | Klassifizierung | MAXIMIZE_AU_ROC |
Zwischen Klassen unterscheiden. Standardwert für die binäre Klassifizierung. |
| Logarithmischer Verlust | Klassifizierung | MINIMIZE_LOG_LOSS |
Möglichst genaue Vorhersagewahrscheinlichkeiten erzielen. Nur unterstütztes Ziel für die Klassifizierung mehrerer Klassen. |
| AUC PR | Klassifizierung | MAXIMIZE_AU_PRC |
Ergebnisse für Vorhersagen für die weniger gängige Klasse optimieren. |
| Präzision von Trefferquote | Klassifizierung | MAXIMIZE_PRECISION_AT_RECALL |
Optimieren Sie die Präzision bei einem bestimmten Trefferquotenwert. |
| Trefferquote von Präzision | Klassifizierung | MAXIMIZE_RECALL_AT_PRECISION |
Optimieren Sie die Trefferquote bei einem bestimmten Präzisionswert. |
| RMSE | Regression | MINIMIZE_RMSE |
Extremwerte genau erfassen. |
| MAE | Regression | MINIMIZE_MAE |
Extremwerte als Ausreißer mit geringerem Einfluss auf das Modell betrachten. |
| RMSLE | Regression | MINIMIZE_RMSLE |
Abzüge für Fehler nach der relativen Größe statt des absoluten Werts vornehmen. Dies ist besonders hilfreich, wenn sowohl die vorhergesagten als auch die tatsächlichen Werte sehr groß sein können. |
Nächste Schritte
- Modellarchitektur untersuchen
- Modell bewerten
- Batchvorhersagen mit Ihrem Modell abrufen
- Onlinevorhersagen mit Ihrem Modell abrufen
- Modell exportieren
- Mit lang andauernden Vorgängen arbeiten