このページでは、AutoML Tables を使用してデータセットに基づいてカスタムモデルをトレーニングする方法について説明します。事前にデータセットを作成してデータをインポートしておく必要があります。
はじめに
準備したデータセットを使用してモデルをトレーニングし、カスタムモデルを作成します。AutoML Tables では、データセットの項目を使用してモデルをトレーニングしてテストし、モデルのパフォーマンスを評価します。その結果を確認し、必要に応じてトレーニング データセットを調整して、改善されたデータセットで新しいモデルをトレーニングします。
モデルのトレーニングの準備の一環として、データセットのスキーマ情報を更新します。これらのスキーマの更新は、そのデータセットを使用する将来のモデルに影響します。すでにトレーニングを開始しているモデルには影響がありません。
モデルのトレーニングが完了するまで数時間かかることがあります。トレーニングの進行状況は、Google Cloud コンソールか、Cloud AutoML API を使用して確認できます。
AutoML Tables ではトレーニングを開始するたびに新しいモデルが作成されるため、プロジェクトに多数のモデルが含まれる場合があります。プロジェクト内のモデルを一覧表示したり、不要になったモデルを削除したりすることが可能です。
予測の実行を継続するには、モデルを 6 か月ごとに再トレーニングする必要があります。
モデルのトレーニング
Console
必要に応じて、[データセット] ページを開き、使用するデータセットをクリックします。
これにより、[トレーニング] タブでデータセットが開きます。
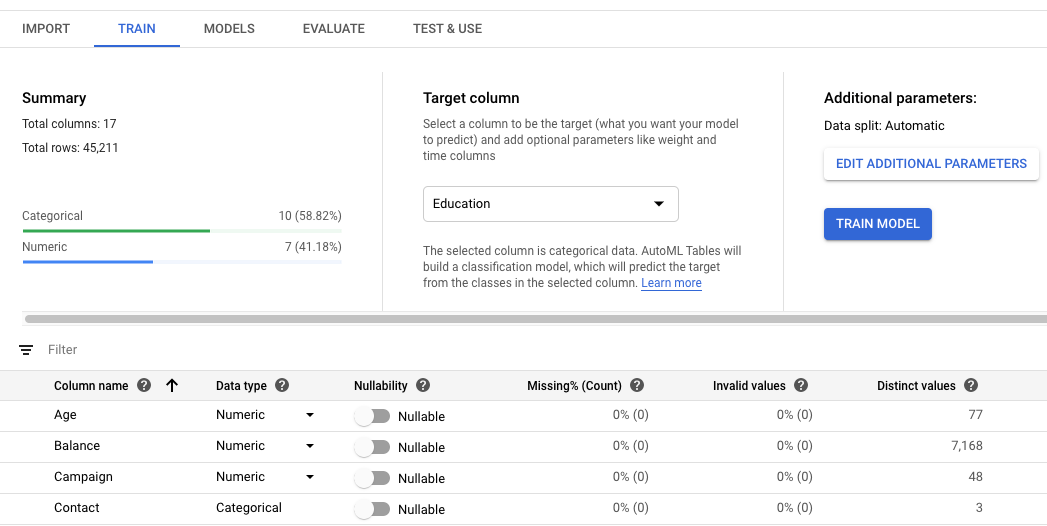
モデルのターゲット列を選択します。
これは、モデルが予測するようにトレーニングされている値です。そのデータ型によって、結果として得られるモデルが回帰(数値)モデルか分類(カテゴリ)モデルかが決まります。詳細
ターゲット列のデータ型がカテゴリの場合、2~500 個の固有の値が必要です。
データセットの各列の [データ型]、[null 値許容]、データ統計を確認します。
個々の列をクリックすると、その列の詳細が表示されます。スキーマの確認の詳細をご覧ください。
データ分割を制御する場合は、[他のパラメータを編集] をクリックし、データ分割列または時間列を指定します。詳細
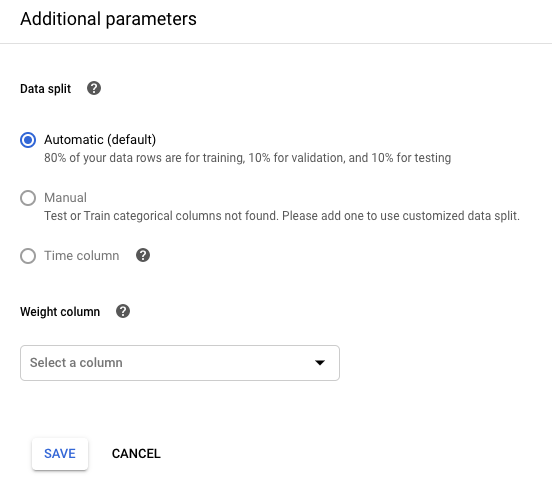
トレーニング サンプルを列の値で重み付けする場合は、[他のパラメータを編集] をクリックし、該当する列を指定します。詳細
要約統計と詳細を確認して、データ品質が期待どおりであること、およびモデルの作成時に除外する必要がある列を特定したことを確認します。
詳細については、トレーニング データの分析をご覧ください。
データセットのスキーマに問題がなければ、画面上部の [モデル トレーニング] をクリックします。
スキーマに変更を加えると、AutoML Tables は要約統計を更新します。完了までに数分かかることがあります。モデルのトレーニングを開始する前に、このプロセスが完了するのを待つ必要はありません。
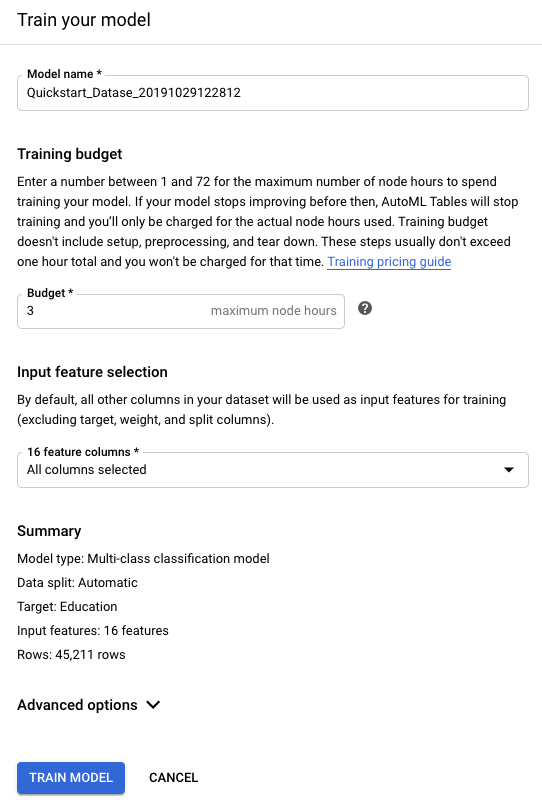
[トレーニングの予算] に、そのモデルの最長トレーニング時間数を入力します。
トレーニングの予算は 1~72 時間までです。これが、請求対象になる最長トレーニング時間数です。
推奨されるトレーニング時間は、トレーニング データのサイズに応じて変わります。次の表に、行数別の推奨トレーニング時間を示します。列の数が多いとトレーニング時間も長くなります。
行数 推奨トレーニング時間 100,000 未満 1~3 時間 100,000~1,000,000 1~6 時間 1,000,000~10,000,000 1~12 時間 10,000,001 以上 3~24 時間 モデルの作成にはトレーニング以外のタスクも含まれるため、作成全体にかかる合計時間はトレーニング時間より多くなります。たとえば、トレーニング時間を 2 時間と指定しても、モデルのデプロイ準備ができるまでにさらに 3 時間以上かかる可能性があります。料金は実際のトレーニング時間に対してのみかかります。
AutoML Tables では、トレーニング予算がなくなる前にモデルに改善がみられなくなると、トレーニングが停止されます。予算のトレーニング時間を全部使用する場合は、[詳細オプション] を開き、[早期停止] を無効にします。
[入力特徴の選択] セクションで、スキーマ分析手順で除外対象とした列を除外します。
デフォルトの最適化の目標を使用しない場合は、[詳細オプション] を開き、モデルのトレーニング時に AutoML Tables で最適化する指標を選択します。詳細
ターゲット列のデータ型によっては、[最適化の目標] の選択肢が 1 つしかない場合があります。
[モデル トレーニング] をクリックしてモデルのトレーニングを開始します。
モデルのトレーニングが完了するまで、データセットのサイズとトレーニングの予算に応じて数時間かかる場合があります。ブラウザ ウィンドウを閉じても、トレーニング プロセスに影響しません。
モデルのトレーニングが正常に完了すると、[モデル] タブにモデルの主な指標(適合率や再現率など)が表示されます。
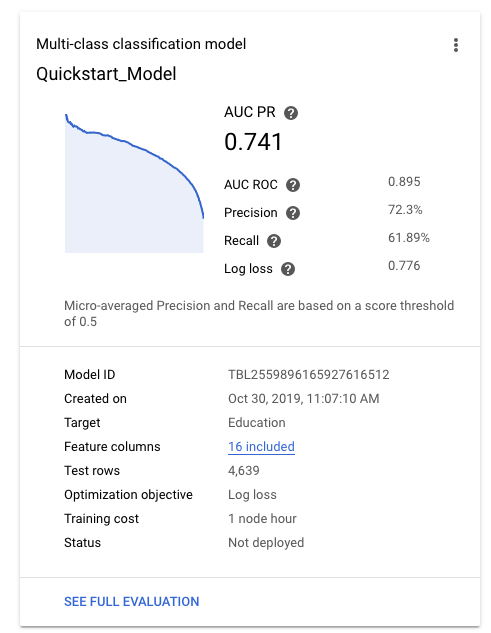
モデルの品質の評価については、モデルの評価をご覧ください。
REST
次の例は、モデルをトレーニングする前にデータスキーマを確認して更新する方法を示しています。
リソースが EU リージョンにある場合は、{location} に eu を使用し、eu-automl.googleapis.com エンドポイントを使用します。それ以外の場合は、us-central1 を使用します。詳細
インポートが完了したら、テーブルの仕様を一覧表示してテーブル ID を取得します。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 -
dataset-id: データセットの ID例:
TBL6543。
HTTP メソッドと URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
リクエストを送信するには、次のいずれかのオプションを展開します。
テーブル ID は、
nameフィールドに太字で表示されます。-
endpoint: グローバル ロケーションの場合は
列の仕様をリストします。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 -
dataset-id: データセットの ID例:
TBL6543。 - table-id: テーブルの ID。
HTTP メソッドと URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
リクエストを送信するには、次のいずれかのオプションを展開します。
-
endpoint: グローバル ロケーションの場合は
必要に応じて、ターゲット列を構成します。
これは、モデルが予測するようにトレーニングされている値です。そのデータ型によって、結果として得られるモデルが回帰(数値)モデルか分類(カテゴリ)モデルかが決まります。詳細
ターゲット列のデータ型がカテゴリの場合、2~500 個の固有の値が必要です。
モデルをトレーニングするときに、ターゲット列を指定することもできます。その場合は、後で使用するためにテーブル ID と対象のターゲット列 ID を保持します。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 - dataset-id: データセットの ID
- target-column-id: ターゲット列の ID。
HTTP メソッドと URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
リクエストの本文(JSON):
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }リクエストを送信するには、次のいずれかのオプションを展開します。
-
endpoint: グローバル ロケーションの場合は
必要に応じて、
mlUseColumnSpecIdフィールドを更新してデータ分割を指定し、weightColumnSpecIdフィールドを更新して重み列を使用します。リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 - dataset-id: データセットの ID
- split-column-id: ターゲット列の ID。
- weight-column-id: ターゲット列の ID。
HTTP メソッドと URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
リクエストの本文(JSON):
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }リクエストを送信するには、次のいずれかのオプションを展開します。
-
endpoint: グローバル ロケーションの場合は
列の統計を調べて、
dataTypeの値が正しいこと、そして列に正しいnullableの値があることを確認します。フィールドが null 値許容でないとマークされている場合は、トレーニング データセットに null 値がなかったことを意味します。これが予測データにも当てはまることを確認してください。列が null 値許容でないとマークされていて、予測時にその列に値が指定されていない場合、その行について予測エラーが返されます。
データ品質を確認します。
トレーニング データの分析の詳細をご覧ください。
モデルをトレーニングします。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 - dataset-id: データセット ID。
- table-id: ターゲット列の設定に使用するテーブル ID。
- target-column-id: ターゲット列の ID。
- model-display-name: 新しいモデルの表示名。
-
optimization-objective は最適化する指標に置き換えます(任意)。
モデルの最適化の目標についてをご覧ください。
-
train-budget-milli-node-hours は、トレーニングのミリ単位のノード時間数に置き換えます。たとえば、1000 は 1 時間です。
推奨されるトレーニング時間は、トレーニング データのサイズに応じて変わります。次の表に、行数別の推奨トレーニング時間を示します。列の数が多いとトレーニング時間も長くなります。
行数 推奨トレーニング時間 100,000 未満 1~3 時間 100,000~1,000,000 1~6 時間 1,000,000~10,000,000 1~12 時間 10,000,001 以上 3~24 時間 モデルの作成にはトレーニング以外のタスクも含まれるため、作成全体にかかる合計時間はトレーニング時間より多くなります。たとえば、トレーニング時間を 2 時間と指定しても、モデルのデプロイ準備ができるまでにさらに 3 時間以上かかる可能性があります。料金は実際のトレーニング時間に対してのみかかります。
AutoML Tables では、トレーニング予算がなくなる前にモデルに改善がみられなくなると、トレーニングが停止されます。予算のトレーニング時間を全部使用する場合は、
tablesModelMetadataオブジェクトのdisableEarlyStoppingプロパティをtrueに設定します。
HTTP メソッドと URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
リクエストの本文(JSON):
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }モデルのトレーニングは長時間実行オペレーションです。オペレーションのステータスをポーリングするか、オペレーションが完了するまで待つことができます。詳細
-
endpoint: グローバル ロケーションの場合は
Java
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Node.js
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Python
AutoML Tables のクライアント ライブラリには、AutoML Tables API を簡単に使用できるようにする追加の Python メソッドが含まれています。これらのメソッドは、ID ではなく名前でデータセットとモデルを参照します。データセット名とモデル名は一意である必要があります。詳細については、クライアント リファレンスをご覧ください。
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
スキーマの確認
AutoML Tables は、データ型と各列の列が null 値許容かどうかを、元のデータ型(BigQuery からインポートされた場合)とその列の値に基づいて推測します。各列を確認して、正しい状態にあることを確認してください。
以下のリストを使ってスキーマを確認してください。
自由形式のテキストを含むフィールドは「テキスト」であること。
テキスト フィールドは UnicodeScriptTokenizer によりトークンに分離され、個々のトークンがモデルのトレーニングに使用されます。UnicodeScriptTokenizer はテキストを空白文字でトークン化し、句読点をテキストから分離し、異なる言語を互いに分離します。
列の値が有限の値セットのいずれかである場合は、フィールドで使用されるデータの種類に関係なく、これはカテゴリになります。
たとえば、1 = 赤、2 = 黄などの色を表すコードがある場合は、そのようなフィールドが「カテゴリ」として指定されているようにします。
ただし、列に複数単語の文字列が含まれている場合は例外です。この場合、カーディナリティが低かったとしても、この列をテキスト列として設定する必要があります。AutoML Tables はテキスト列をトークン化し、個々のトークンまたはそれらの順序から予測シグナルを導き出せることがあります。
フィールドが null 値許容でないとマークされている場合は、トレーニング データセットに null 値がなかったことを意味します。これが予測データにも当てはまることを確認してください。列が null 値許容でないとマークされていて、予測時にその列に値が指定されていない場合、その行について予測エラーが返されます。
トレーニング データの分析
列の欠落値の割合が高い場合は、それが予期されたものであり、データ収集の問題によるものでないことを確認します。
無効な値の数が相対的に少ないかゼロであることを確認します。
無効な値が 1 つ以上ある行は自動的にモデルのトレーニングには使用されません。
カテゴリ列の [固有の値] が行数に近づくと(たとえば 90% 以上)、その列はトレーニング シグナルを提供しなくなります。トレーニングから除外する必要があります。ID 列は常に除外する必要があります。
列の [ターゲットとの相関] の値が高い場合は、それが予期されたものであり、ターゲットの漏出を示すものでないことを確認します。
予測をリクエストする際にその列が利用可能な場合、それはおそらく説明力が強いという特徴であり、トレーニングに含めることができます。ただし、相関性の高いという特徴がターゲットから導出されることや、事後に収集されることがあります。これらの特徴は予測時に使用できないため、トレーニングから除外する必要があります。したがって、このモデルは本番環境では使用できません。
相関関係は、クラメールの V を使用してカテゴリ列、数値列、タイムスタンプ列に対して計算されます。数値列の場合は、変位値から生成されたバケット数を使用して計算されます。
モデルの最適化の目標について
最適化の目標はモデルをどのようにトレーニングするかに影響し、ひいては本番環境でのモデルの品質に影響します。次の表に、各目標がどのような問題に適しているか詳しく示します。
| 最適化の目標 | 問題のタイプ | API 値 | この目標が適している問題 |
|---|---|---|---|
| AUC ROC | 分類 | MAXIMIZE_AU_ROC |
クラス間を区別する。バイナリ分類のデフォルト値。 |
| ログ損失 | 分類 | MINIMIZE_LOG_LOSS |
予測確率をできるだけ正確に維持する。マルチクラス分類でサポートされている目標のみ。 |
| AUC PR | 分類 | MAXIMIZE_AU_PRC |
あまり一般的でないクラスの予測結果を最適化する。 |
| 再現率での適合率 | 分類 | MAXIMIZE_PRECISION_AT_RECALL |
特定の再現率の値で適合率を最適化する。 |
| 適合率での再現率 | 分類 | MAXIMIZE_RECALL_AT_PRECISION |
特定の適合率の値で再現率を最適化する。 |
| RMSE | 回帰 | MINIMIZE_RMSE |
より極端な値を正確に取り込む。 |
| MAE | 回帰 | MINIMIZE_MAE |
モデルへの影響を抑えて、極端な値を外れ値として表示する。 |
| RMSLE | 回帰 | MINIMIZE_RMSLE |
絶対値ではなく、相対サイズに基づいてエラーにペナルティを適用する。予測値と実際の値の両方がかなり大きくなる可能性がある場合に特に役立ちます。 |
次のステップ
- モデル アーキテクチャを調査する。
- モデルを評価する。
- モデルからバッチ予測を取得する。
- モデルからオンライン予測を取得する。
- モデルをエクスポートする。
- 長時間実行オペレーションの使用について学ぶ。