Halaman ini menjelaskan cara menyediakan beberapa baris data ke AutoML Tables sekaligus, dan menerima prediksi untuk setiap baris.
Pengantar
Setelah membuat (melatih) model, Anda dapat membuat permintaan asinkron untuk sekumpulan prediksi menggunakan metode batchPredict. Anda memberikan data input ke metode batchPredict, dalam format tabel.
Setiap baris memberikan nilai untuk fitur yang Anda latih model untuk digunakan.
Metode batchPredict mengirim data tersebut ke model dan menampilkan prediksi untuk setiap baris data.
Model harus dilatih ulang setiap enam bulan agar dapat terus menyajikan prediksi.
Meminta prediksi batch
Untuk prediksi batch, tentukan sumber data dan tujuan hasil dalam tabel BigQuery atau file CSV di Cloud Storage. Anda tidak perlu menggunakan teknologi yang sama untuk sumber dan tujuan. Misalnya, Anda dapat menggunakan BigQuery untuk sumber data dan file CSV di Cloud Storage untuk tujuan hasil. Gunakan langkah-langkah yang sesuai dari dua tugas di bawah ini, bergantung pada kebutuhan Anda.
Sumber data Anda harus berisi data tabel yang mencakup semua kolom yang digunakan untuk melatih model. Anda dapat menyertakan kolom yang tidak ada dalam data pelatihan, atau yang ada dalam data pelatihan, tetapi dikecualikan dari penggunaan untuk pelatihan. Kolom tambahan ini disertakan dalam output prediksi, tetapi tidak digunakan untuk menghasilkan prediksi.
Menggunakan tabel BigQuery
Nama kolom dan jenis data data input harus cocok dengan data yang Anda gunakan dalam data pelatihan. Kolom dapat berada dalam urutan yang berbeda dari data pelatihan.
Persyaratan tabel BigQuery
- Ukuran tabel sumber data BigQuery tidak boleh lebih dari 100 GB.
- Anda harus menggunakan set data BigQuery multi-regional di lokasi
USatauEU. - Jika tabel tersebut berada dalam project yang berbeda, Anda harus memberikan peran
BigQuery Data Editorke akun layanan AutoML Tables dalam project tersebut. Pelajari lebih lanjut.
Meminta prediksi batch
Konsol
Buka halaman AutoML Tables di Konsol Google Cloud.
Pilih Model dan buka model yang ingin Anda gunakan.
Pilih tab Pengujian & Penggunaan.
Klik Prediksi batch.
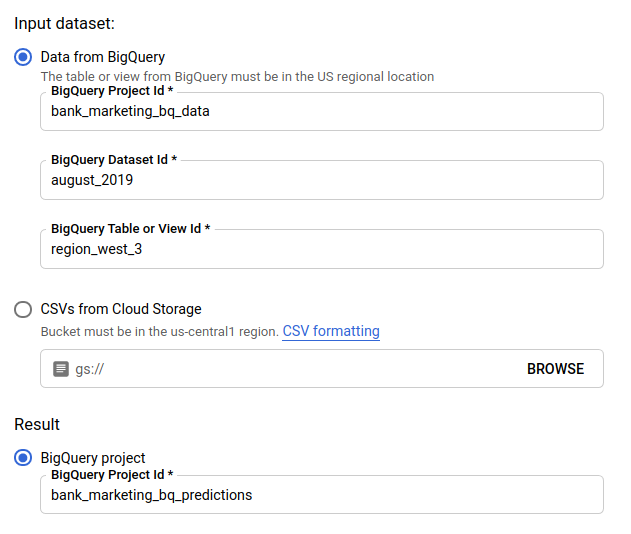
Untuk Set data input, pilih Tabel dari BigQuery dan berikan ID project, set data, dan tabel untuk sumber data Anda.
Untuk Result, pilih project BigQuery, lalu masukkan project ID untuk tujuan hasil Anda.
Jika Anda ingin melihat pengaruh setiap fitur terhadap prediksi, pilih Membuat tingkat kepentingan fitur.
Menghasilkan nilai penting fitur akan meningkatkan waktu dan resource komputasi yang diperlukan untuk prediksi Anda. Tingkat kepentingan fitur lokal tidak tersedia dengan tujuan hasil Cloud Storage.
Klik Kirim prediksi batch untuk meminta prediksi batch.
REST
Anda meminta prediksi batch menggunakan metode models.batchPredict.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. - model-id: ID model. Contoh,
TBL543. - dataset-id: ID set data BigQuery tempat data prediksi berada.
-
table-id: ID tabel BigQuery tempat data prediksi berada.
AutoML Tables membuat subfolder untuk hasil prediksi yang bernama
prediction-<model_name>-<timestamp>dalam project-id.dataset-id.table-id.
Metode HTTP dan URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Isi JSON permintaan:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
lalu jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Anda bisa mendapatkan nilai penting fitur lokal dengan menambahkan parameter feature_importance
ke data permintaan. Untuk informasi selengkapnya, lihat
Tingkat kepentingan fitur lokal.
Java
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Node.js
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Python
Library klien untuk AutoML Tables menyertakan metode Python tambahan yang menyederhanakan penggunaan AutoML Tables API. Metode ini merujuk pada set data dan model berdasarkan nama, bukan ID. Nama set data dan model Anda harus unik. Untuk mengetahui informasi selengkapnya, lihat Referensi klien.
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Menggunakan file CSV di Cloud Storage
Nama kolom dan jenis data data input harus cocok dengan data yang Anda gunakan dalam data pelatihan. Kolom dapat berada dalam urutan yang berbeda dari data pelatihan.
Persyaratan file CSV
- Baris pertama sumber data harus berisi nama kolom.
Ukuran setiap file sumber data tidak boleh lebih dari 10 GB.
Anda dapat menyertakan beberapa file, hingga jumlah maksimum 100 GB.
Bucket Cloud Storage harus sesuai dengan persyaratan bucket.
Jika bucket Cloud Storage berada di project yang berbeda dengan tempat Anda menggunakan AutoML Tables, Anda harus memberikan peran
Storage Object Creatorke akun layanan AutoML Tables dalam project tersebut. Pelajari lebih lanjut.
Konsol
Buka halaman AutoML Tables di Konsol Google Cloud.
Pilih Model dan buka model yang ingin Anda gunakan.
Pilih tab Pengujian & Penggunaan.
Klik Prediksi batch.
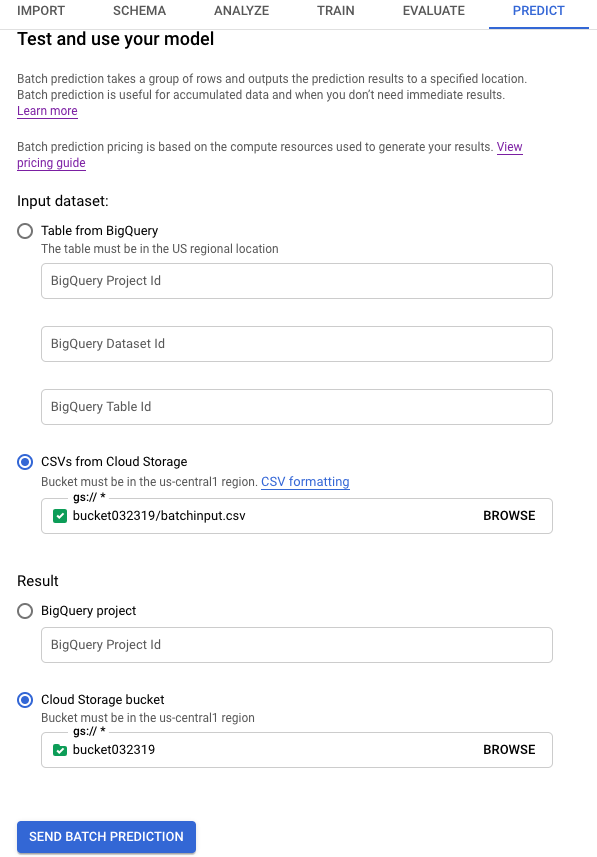
Untuk Set data input, pilih CSV dari Cloud Storage dan berikan URI bucket untuk sumber data Anda.
Untuk Result, pilih Cloud Storage bucket dan berikan URI bucket untuk bucket tujuan Anda.
Jika Anda ingin melihat pengaruh setiap fitur terhadap prediksi, pilih Membuat tingkat kepentingan fitur.
Menghasilkan nilai penting fitur akan meningkatkan waktu dan resource komputasi yang diperlukan untuk prediksi Anda. Tingkat kepentingan fitur lokal tidak tersedia dengan tujuan hasil Cloud Storage.
Klik Kirim prediksi batch untuk meminta prediksi batch.
REST
Anda meminta prediksi batch menggunakan metode models.batchPredict.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
-
endpoint:
automl.googleapis.comuntuk lokasi global, daneu-automl.googleapis.comuntuk region Uni Eropa. - project-id: Project ID Google Cloud Anda.
- location: lokasi untuk resource:
us-central1untuk Global ataueuuntuk Uni Eropa. - model-id: ID model. Contoh,
TBL543. - input-bucket-name: nama bucket Cloud Storage tempat data prediksi berada.
- input-directory-name: nama direktori Cloud Storage tempat data prediksi berada.
- object-name: nama objek Cloud Storage tempat data prediksi berada.
- output-bucket-name: nama bucket Cloud Storage untuk hasil prediksi.
-
output-directory-name: nama direktori Cloud Storage untuk hasil prediksi.
AutoML Tables membuat subfolder untuk hasil prediksi yang bernama
prediction-<model_name>-<timestamp>dalamgs://output-bucket-name/output-directory-name. Anda harus memiliki izin tulis ke jalur ini.
Metode HTTP dan URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Isi JSON permintaan:
{
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://input-bucket-name/input-directory-name/object-name.csv"
]
},
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket-name/output-directory-name"
},
},
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
lalu jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Anda bisa mendapatkan nilai penting fitur lokal dengan menambahkan parameter feature_importance
ke data permintaan. Untuk informasi selengkapnya, lihat
Tingkat kepentingan fitur lokal.
Java
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Node.js
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Python
Library klien untuk AutoML Tables menyertakan metode Python tambahan yang menyederhanakan penggunaan AutoML Tables API. Metode ini merujuk pada set data dan model berdasarkan nama, bukan ID. Nama set data dan model Anda harus unik. Untuk mengetahui informasi selengkapnya, lihat Referensi klien.
Jika resource Anda berada di region Uni Eropa, Anda harus menetapkan endpoint secara eksplisit. Pelajari lebih lanjut.
Mengambil hasil Anda
Mengambil hasil prediksi di BigQuery
Jika Anda menentukan BigQuery sebagai tujuan output, hasil permintaan prediksi batch akan ditampilkan sebagai set data baru di project BigQuery yang Anda tentukan. Set data BigQuery adalah nama model Anda yang diawali dengan "prediksi_" dan ditambah dengan stempel waktu saat tugas prediksi dimulai. Anda dapat menemukan nama set data BigQuery dalam Prediksi terbaru di halaman Prediksi batch di tab Test & Use untuk model Anda.
Set data BigQuery berisi dua tabel: predictions dan errors. Tabel errors memiliki satu baris untuk setiap baris dalam permintaan prediksi Anda, yang mana AutoML Tables tidak dapat menampilkan prediksi (misalnya, jika fitur non-nullable bernilai null). Tabel predictions berisi satu baris untuk setiap prediksi yang ditampilkan.
Dalam tabel predictions, Tabel AutoML menampilkan data prediksi Anda, dan membuat kolom baru untuk hasil prediksi dengan menambahkan "Predicted_" di awal nama kolom target. Kolom hasil prediksi berisi struktur BigQuery bertingkat yang berisi hasil prediksi.
Untuk mengambil hasil prediksi, Anda dapat menggunakan kueri di konsol BigQuery. Format kueri bergantung pada jenis model Anda.
Klasifikasi biner:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2 FROM <bq-dataset-name>.predictions
"value_1" dan "value_2", adalah penanda tempat, Anda dapat menggantinya dengan nilai target atau yang setara.
Klasifikasi multi-kelas:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2, predicted_<target-column-name>[OFFSET(2)].tables AS value_3, ... predicted_<target-column-name>[OFFSET(4)].tables AS value_5 FROM <bq-dataset-name>.predictions
"value_1", "value_2", dan seterusnya adalah penanda tempat, Anda dapat menggantinya dengan nilai target atau yang setara.
Regresi:
SELECT predicted_<target-column-name>[OFFSET(0)].tables.value, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.start, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.end FROM <bq-dataset-name>.predictions
Mengambil hasil di Cloud Storage
Jika Anda menentukan Cloud Storage sebagai tujuan output, hasil permintaan prediksi batch akan ditampilkan sebagai file CSV dalam folder baru di bucket yang Anda tentukan. Nama folder adalah nama model Anda, diawali dengan "prediksi-" dan ditambah dengan stempel waktu saat tugas prediksi dimulai. Anda dapat menemukan nama folder Cloud Storage di Prediksi terbaru di bagian bawah halaman Prediksi batch pada tab Uji & Penggunaan untuk model Anda.
Folder Cloud Storage berisi dua jenis file: file error dan file prediksi. Jika hasilnya besar, file tambahan akan dibuat.
File error diberi nama errors_1.csv, errors_2.csv, dan seterusnya. Tabel tersebut berisi baris header, dan satu baris untuk setiap baris dalam permintaan prediksi Anda yang mana AutoML Tables tidak dapat menampilkan prediksi.
File prediksi diberi nama tables_1.csv, tables_2.csv, dan seterusnya. Kolom ini berisi baris header dengan nama kolom, dan baris untuk setiap prediksi yang ditampilkan.
Dalam file prediksi, Tabel AutoML menampilkan data prediksi Anda, dan membuat satu atau beberapa kolom baru untuk hasil prediksi, bergantung pada jenis model Anda:
Klasifikasi:
Untuk setiap nilai potensial kolom target, kolom bernama <target-column-name>_<value>_score ditambahkan ke hasil. Kolom ini berisi skor, atau estimasi keyakinan, untuk nilai tersebut.
Regresi:
Nilai yang diprediksi untuk baris tersebut ditampilkan dalam kolom bernama predicted_<target-column-name>. Interval prediksi tidak ditampilkan untuk output CSV.
Tingkat kepentingan fitur lokal tidak tersedia untuk hasil di Cloud Storage.
Menafsirkan hasil
Cara menafsirkan hasil bergantung pada masalah bisnis yang Anda selesaikan dan bagaimana data Anda didistribusikan.
Menafsirkan hasil Anda untuk model klasifikasi
Hasil prediksi untuk model klasifikasi (biner dan multi-class) menampilkan skor probabilitas untuk setiap nilai potensial kolom target. Anda harus menentukan cara menggunakan skor. Misalnya, untuk mendapatkan klasifikasi biner dari skor yang diberikan, Anda harus mengidentifikasi nilai batas. Jika ada dua kelas, "A" dan "B", Anda harus mengklasifikasikan contoh tersebut sebagai "A" jika skor untuk "A" lebih besar dari nilai minimum yang dipilih, dan "B" jika tidak. Untuk {i>dataset<i} yang tidak seimbang, ambang batasnya mungkin mendekati 100% atau 0%.
Anda dapat menggunakan diagram kurva perolehan presisi, diagram kurva operator penerima, dan statistik per label lainnya yang relevan di halaman Evaluate untuk model Anda di Google Cloud Console guna melihat bagaimana perubahan nilai minimum akan mengubah metrik evaluasi Anda. Hal ini dapat membantu Anda menentukan cara terbaik untuk menggunakan nilai skor guna menafsirkan hasil prediksi Anda.
Menafsirkan hasil Anda untuk model regresi
Untuk model regresi, nilai yang diharapkan akan ditampilkan, dan untuk banyak masalah, Anda dapat menggunakan nilai tersebut secara langsung. Anda juga dapat menggunakan interval prediksi jika ditampilkan, dan jika rentang tersebut sesuai untuk masalah bisnis Anda.
Menafsirkan hasil nilai penting fitur lokal Anda
Untuk informasi tentang cara menafsirkan hasil nilai penting fitur lokal, lihat Tingkat kepentingan fitur lokal.
Langkah selanjutnya
- Pelajari lebih lanjut nilai penting fitur lokal.
- Pelajari operasi yang berjalan lama lebih lanjut.