Cette page décrit comment fournir plusieurs lignes de données à AutoML Tables en même temps et recevoir une prédiction pour chaque ligne.
Introduction
Après avoir créé (entraîné) un modèle, vous pouvez envoyer une requête asynchrone pour un lot de prédictions à l'aide de la méthode batchPredict. Vous fournissez les données d'entrée à la méthode batchPredict, sous forme de table.
Chaque ligne fournit les valeurs de caractéristiques que vous avez entraîné le modèle à utiliser.
La méthode batchPredict envoie ces données au modèle et renvoie des prédictions pour chaque ligne de données.
Les modèles doivent être réentraînés tous les six mois pour continuer à fournir des prédictions.
Demander une prédiction par lot
Pour les prédictions par lot, vous spécifiez une source de données et une destination des résultats dans une table BigQuery ou un fichier CSV dans Cloud Storage. Vous n'avez pas besoin d'utiliser la même technologie pour la source et la destination. Par exemple, vous pouvez utiliser BigQuery pour la source de données et un fichier CSV dans Cloud Storage pour la destination des résultats. Suivez les étapes des deux tâches indiquées ci-dessous en fonction de vos exigences.
Votre source de données doit contenir des données tabulaires dans lesquelles toutes les colonnes utilisées pour entraîner le modèle sont incluses. Vous pouvez inclure des colonnes qui ne figuraient pas dans les données d'entraînement, ou qui y figuraient mais qui ont été exclues de l'entraînement. Ces colonnes supplémentaires sont incluses dans le résultat de la prédiction, mais elles ne sont pas utilisées pour générer la prédiction.
Utiliser les tables BigQuery
Les noms de colonne et les types de données d'entrée doivent correspondre à ceux que vous avez utilisés dans les données d'entraînement. Les colonnes peuvent se présenter dans un ordre différent de celui des données d'entraînement.
Exigences relatives aux tables BigQuery
- Les tables de source de données BigQuery ne doivent pas dépasser 100 Go.
- Vous devez utiliser un ensemble de données BigQuery multirégional dans les zones
USouEU. - Si la table se trouve dans un autre projet, vous devez attribuer le rôle
BigQuery Data Editorau compte de service AutoML Tables de ce projet. En savoir plus
Demander la prédiction par lot
Console
Accédez à la page "AutoML Tables" dans la console Google Cloud.
Cliquez sur Modèles et ouvrez le modèle que vous souhaitez utiliser.
Sélectionnez l'onglet Test et utilisation.
Cliquez sur Prédiction par lot.
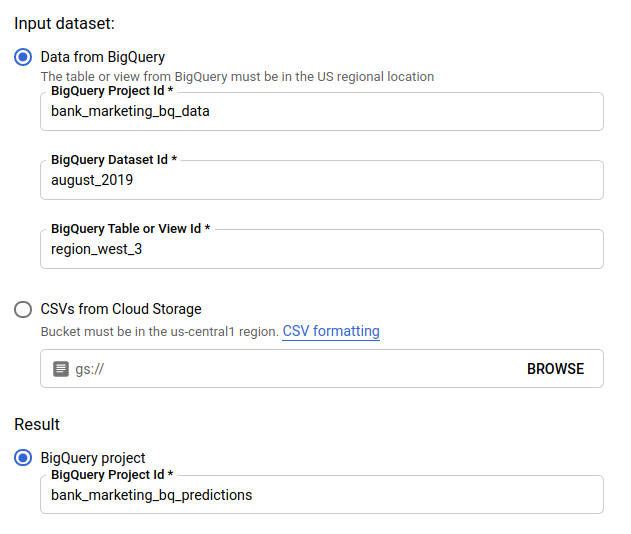
Dans Input dataset (Ensemble de données d'entrée), sélectionnez Table from BigQuery (Table de BigQuery) et indiquez les ID du projet, de l'ensemble de données et de la table correspondant à votre source de données.
Dans Result (Résultats), sélectionnez BigQuery project (projet BigQuery) et indiquez l'ID de projet pour votre destination de résultats.
Pour connaître l'incidence de chaque caractéristique sur la prédiction, cliquez sur Générer l'importance des caractéristiques.
Générer l'importance des caractéristiques augmente le temps et les ressources de calcul nécessaires pour réaliser la prédiction. L'importance des caractéristiques locales n'est pas disponible avec une destination de résultats Cloud Storage.
Cliquez sur Send batch prediction (Envoyer une prédiction par lot) pour demander une prédiction par lot.
REST
Vous demandez des prédictions par lot à l'aide de la méthode models.batchPredict.
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
-
endpoint:
automl.googleapis.compour la zone internationale eteu-automl.googleapis.compour la région UE. - project-id : ID de votre projet Google Cloud.
- location : emplacement de la ressource :
us-central1pour l'emplacement mondial oueupour l'Union européenne. - model-id : ID du modèle. Par exemple,
TBL543. - dataset-id: ID de l'ensemble de données BigQuery où se trouvent les données de prédiction.
-
table-id : ID de la table BigQuery où se trouvent les données de prédiction.
AutoML Tables crée un sous-dossier pour les résultats de prédiction nommé
prediction-<model_name>-<timestamp>dans project-id.dataset-id.table-id.
Méthode HTTP et URL :
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corps JSON de la requête :
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Vous pouvez obtenir l'importance des caractéristiques locales en ajoutant le
paramètre feature_importance aux données de la requête. Pour en savoir plus, consultez l'article
Importance des caractéristiques locales.
Java
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Node.js
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Python
La bibliothèque cliente AutoML Tables comprend des méthodes Python supplémentaires qui simplifient l'utilisation de l'API AutoML Tables. Ces méthodes référencent les ensembles de données et les modèles par nom et non par identifiant. L'ensemble de données et les noms de modèles doivent être uniques. Pour plus d'informations, consultez la documentation de référence du client.
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Utiliser des fichiers CSV dans Cloud Storage
Les noms de colonne et les types de données d'entrée doivent correspondre à ceux que vous avez utilisés dans les données d'entraînement. Les colonnes peuvent se présenter dans un ordre différent de celui des données d'entraînement.
Exigences relatives aux fichiers CSV
- La première ligne de la source de données doit contenir le nom des colonnes.
Chaque fichier de source de données ne doit pas dépasser 10 Go.
Vous pouvez inclure plusieurs fichiers, jusqu'à une taille maximale de 100 Go.
Le bucket Cloud Storage doit être conforme aux exigences de bucket.
Si le bucket Cloud Storage se trouve dans un autre projet que celui pour lequel vous utilisez AutoML Tables, vous devez attribuer le rôle
Storage Object Creatorau compte de service AutoML Tables de ce projet. En savoir plus
Console
Accédez à la page "AutoML Tables" dans la console Google Cloud.
Cliquez sur Modèles et ouvrez le modèle que vous souhaitez utiliser.
Sélectionnez l'onglet Test et utilisation.
Cliquez sur Prédiction par lot.
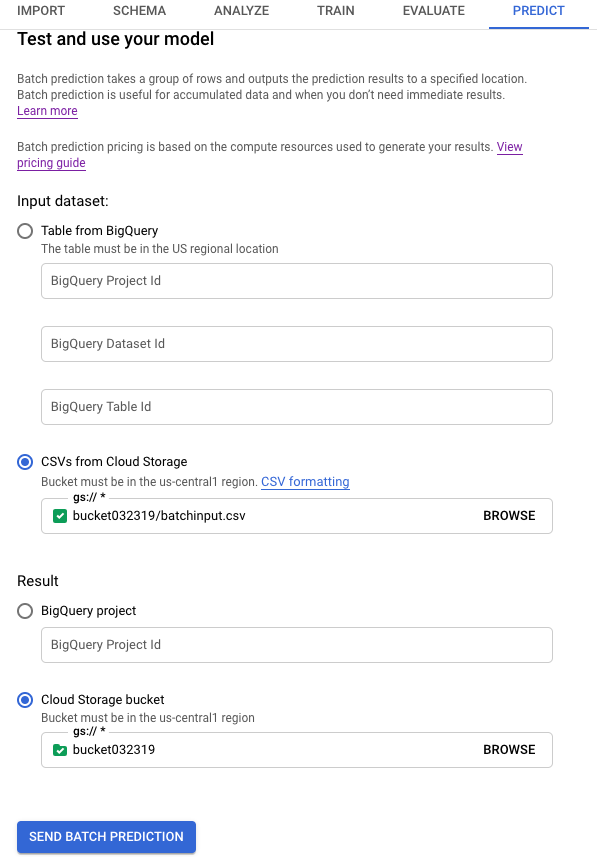
Dans Input dataset (Ensemble de données d'entrée), sélectionnez CSVs from Cloud Storage (Fichiers CSV provenant de Cloud Storage) et indiquez l'URI de bucket pour votre source de données.
Dans Result (Résultats), sélectionnez Cloud Storage bucket (bucket Cloud Storage) et indiquez l'URI de bucket pour votre bucket de destination.
Pour connaître l'incidence de chaque caractéristique sur la prédiction, cliquez sur Générer l'importance des caractéristiques.
Générer l'importance des caractéristiques augmente le temps et les ressources de calcul nécessaires pour réaliser la prédiction. L'importance des caractéristiques locales n'est pas disponible avec une destination de résultats Cloud Storage.
Cliquez sur Send batch prediction (Envoyer une prédiction par lot) pour demander une prédiction par lot.
REST
Vous demandez des prédictions par lot à l'aide de la méthode models.batchPredict.
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
-
endpoint:
automl.googleapis.compour la zone internationale eteu-automl.googleapis.compour la région UE. - project-id : ID de votre projet Google Cloud.
- location : emplacement de la ressource :
us-central1pour l'emplacement mondial oueupour l'Union européenne. - model-id : ID du modèle. Par exemple,
TBL543. - input-bucket-name : nom du bucket Cloud Storage où se trouvent les données de la prédiction.
- input-directory-name : nom du répertoire Cloud Storage où se trouvent les données de la prédiction.
- object-name : nom de l'objet Cloud Storage où se trouvent les données de la prédiction.
- output-bucket-name : nom du bucket Cloud Storage pour les résultats de la prédiction.
-
output-directory-name : nom du répertoire Cloud Storage pour les résultats de la prédiction.
AutoML Tables crée un sous-dossier pour les résultats de la prédiction nommés
prediction-<model_name>-<timestamp>dansgs://output-bucket-name/output-directory-name... Vous devez disposer des autorisations en écriture pour ce chemin.
Méthode HTTP et URL :
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corps JSON de la requête :
{
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://input-bucket-name/input-directory-name/object-name.csv"
]
},
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket-name/output-directory-name"
},
},
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Vous pouvez obtenir l'importance des caractéristiques locales en ajoutant le
paramètre feature_importance aux données de la requête. Pour en savoir plus, consultez l'article
Importance des caractéristiques locales.
Java
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Node.js
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Python
La bibliothèque cliente AutoML Tables comprend des méthodes Python supplémentaires qui simplifient l'utilisation de l'API AutoML Tables. Ces méthodes référencent les ensembles de données et les modèles par nom et non par identifiant. L'ensemble de données et les noms de modèles doivent être uniques. Pour plus d'informations, consultez la documentation de référence du client.
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Récupérer vos résultats
Récupérer les résultats de prédiction dans BigQuery
Si vous avez spécifié BigQuery comme destination de sortie, les résultats de votre requête de prédiction par lot sont affichés en tant que nouvel ensemble de données dans le projet BigQuery spécifié. Le nom de l'ensemble de données BigQuery est celui de votre modèle, précédé de "prediction_" et suivi de l'horodatage du début de la tâche de prédiction. Vous trouverez le nom de l'ensemble de données BigQuery dans Prédictions récentes sur la page Prédiction par lot de l'onglet Test et utilisation pour votre modèle.
L'ensemble de données BigQuery contient deux tables : predictions et errors. La table errors comprend une ligne pour chaque ligne de votre requête de prédiction pour laquelle AutoML Tables n'a pas pu afficher de prédiction (par exemple, une caractéristique ne pouvant être vide contient une valeur nulle). La table predictions contient une ligne pour chaque prédiction affichée.
Dans la table predictions, AutoML Tables affiche les données de prédiction et crée une colonne pour les résultats de prédiction en ajoutant "predicted_" au nom de la colonne cible. La colonne des résultats de prédiction comporte une structure BigQuery imbriquée qui contient les résultats de prédiction.
Pour extraire les résultats de prédiction, vous pouvez utiliser une requête dans la console BigQuery. Le format de la requête dépend du type de votre modèle.
Classification binaire :
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2 FROM <bq-dataset-name>.predictions
"value_1" et "value_2" sont des repères de position. Vous pouvez les remplacer par les valeurs cibles ou un équivalent.
Classification à classes multiples :
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2, predicted_<target-column-name>[OFFSET(2)].tables AS value_3, ... predicted_<target-column-name>[OFFSET(4)].tables AS value_5 FROM <bq-dataset-name>.predictions
"valeur_1", "valeur_2", etc. sont des repères de position. Vous pouvez les remplacer par les valeurs cibles ou un équivalent.
Régression :
SELECT predicted_<target-column-name>[OFFSET(0)].tables.value, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.start, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.end FROM <bq-dataset-name>.predictions
Récupérer les résultats dans Cloud Storage
Si vous avez spécifié Cloud Storage comme destination de sortie, les résultats de votre requête de prédiction par lot sont affichés sous forme de fichiers CSV dans un nouveau dossier du bucket spécifié. Le nom du dossier est celui de votre modèle, précédé de "prédiction-" et suivi de l'horodatage du début de la tâche de prédiction. Vous trouverez le nom du dossier Cloud Storage dans Prédictions récentes en bas de la page Prédiction par lot de l'onglet Test et utilisation pour votre modèle.
Le dossier Cloud Storage contient deux types de fichiers : les fichiers d'erreur et les fichiers de prédiction. Si les résultats sont volumineux, des fichiers supplémentaires sont créés.
Les fichiers d'erreur sont nommés errors_1.csv, errors_2.csv, etc. Ils contiennent une ligne d'en-tête et une ligne pour chaque ligne de votre requête de prédiction pour laquelle AutoML Tables n'a pas pu afficher de prédiction.
Les fichiers de prédiction sont nommés tables_1.csv, tables_2.csv, etc. Ils contiennent une ligne d'en-tête avec les noms de colonne et une ligne pour chaque prédiction affichée.
Dans les fichiers de prédiction, AutoML Tables affiche vos données de prédiction et crée une ou plusieurs colonnes pour les résultats de prédiction, en fonction du type de votre modèle :
Classification :
Pour chaque valeur potentielle de votre colonne cible, une colonne nommée <target-column-name>_<value>_score est ajoutée aux résultats. Cette colonne contient le score, ou estimation du niveau de confiance, pour cette valeur.
Régression :
La valeur prédite pour cette ligne est affichée dans une colonne intitulée predicted_<target-column-name>. L'intervalle de prédiction n'est pas affiché dans la sortie au format CSV.
L'importance des caractéristiques locales n'est pas disponible dans les résultats de Cloud Storage.
Interpréter vos résultats
La façon dont vous interprétez vos résultats dépend du problématique métier que vous résolvez et de la manière dont vos données sont distribuées.
Interpréter vos résultats pour les modèles de classification
Les résultats de prédiction pour les modèles de classification (binaires et multiclasses) affichent un score de probabilité pour chaque valeur potentielle de la colonne cible. Vous devez déterminer comment vous souhaitez utiliser les scores. Par exemple, pour obtenir une classification binaire à partir des scores fournis, vous devez identifier une valeur de seuil. S'il existe deux classes, A et B, vous devez classer l'exemple dans A si le score de A est supérieur au seuil choisi, et dans B dans le cas contraire. Pour les ensembles de données déséquilibrés, le seuil peut atteindre 100 % ou 0 %.
Vous pouvez utiliser le graphique de courbe de précision et de rappel, ainsi que d'autres statistiques pertinentes par étiquette sur la page Évaluer de votre modèle dans la console Google Cloud pour voir comment la modification du seuil modifie vos métriques d'évaluation. Cela vous aidera à déterminer la meilleure façon d'utiliser les valeurs de score pour interpréter vos résultats de prédiction.
Interpréter les résultats pour les modèles de régression
Pour les modèles de régression, une valeur attendue est affichée. Cette valeur peut être utilisée directement dans de nombreux cas. S'il s'affiche, et si une plage convient à votre problématique métier, vous pouvez également utiliser l'intervalle de prédiction
Interpréter les résultats de l'importance des caractéristiques locales
Pour plus d'informations sur l'interprétation des résultats de l'importance des caractéristiques locales, consultez la page Importance des caractéristiques locales.
Étapes suivantes
- Apprenez-en plus sur l'importance des caractéristiques locales.
- Apprenez-en plus sur les opérations de longue durée.