本页介绍如何使用 AutoML Tables 将自定义模型导出到 Cloud Storage,将模型下载到服务器以及使用 Docker 将模型用于预测。
导出的模型只能在支持 Advanced Vector Extensions (AVX) 指令集的 x86 架构 CPU 上运行。
简介
以下为模型导出步骤:
准备工作
在完成此任务之前,您必须首先完成以下任务:
- 按照准备工作中的说明设置您的项目。
- 训练您要下载的模型。
- 在将用于运行导出的模型的服务器上安装并初始化 Google Cloud CLI。
- 在服务器上安装 Docker。
拉取 AutoML Tables 模型服务器 Docker 映像:
sudo docker pull gcr.io/cloud-automl-tables-public/model_server
导出模型
您不能导出 2019 年 8 月 23 日之前创建的模型。
控制台
转到 Google Cloud 控制台中的 AutoML Tables 页面。
在左侧导航窗格中选择模型标签页。
在您要导出的模型的更多操作菜单中,点击导出模型。
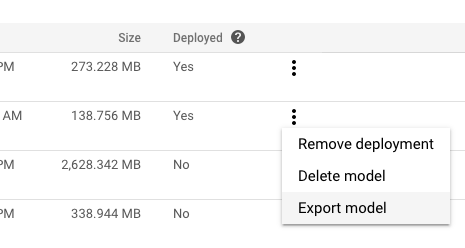
在目标位置中选择或创建 Cloud Storage 文件夹。
存储桶必须符合存储桶要求。
您无法将模型导出到顶级存储桶。您必须至少使用一级文件夹。
点击导出。
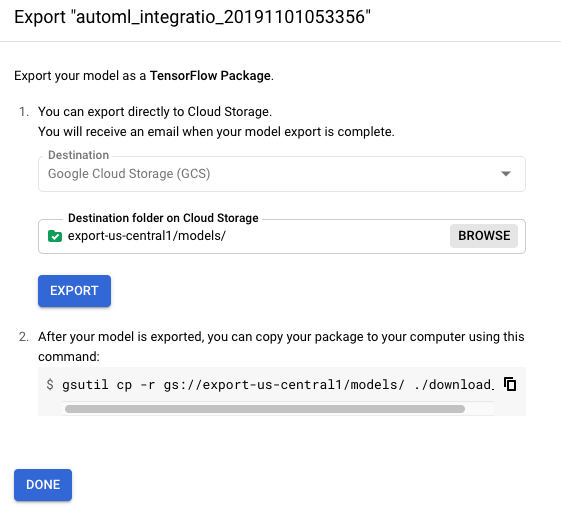
下一部分中,您需将已导出的模型下载到您的服务器。
REST
您可以使用 models.export 方法将模型导出到 Cloud Storage。在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 -
model-id:要部署的模型的 ID。例如,
TBL543。 - gcs-destination:Cloud Storage 中的目标文件夹。例如
gs://export-bucket/exports。您无法将模型导出到顶级存储桶。您必须至少使用一级文件夹。
HTTP 方法和网址:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:export
请求 JSON 正文:
{
"outputConfig": {
"modelFormat": "tf_saved_model",
"gcsDestination": {
"outputUriPrefix": "gcs-destination"
}
}
}
如需发送请求,请选择以下方式之一:
curl
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:export"
PowerShell
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:export" | Select-Object -Expand Content
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/292381/locations/us-central1/operations/TBL543",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2019-12-30T18:23:47.728373Z",
"updateTime": "2019-12-30T18:23:47.728373Z",
"worksOn": [
"projects/292381/locations/us-central1/models/TBL543"
],
"exportModelDetails": {
"outputInfo": {
"gcsOutputDirectory": "gs://export-bucket/exports/model-export/tbl/tf_saved_model-automl_integration_test_model-2019-12-30T18:23:47.461Z/"
}
},
"state": "RUNNING"
}
}
导出模型是一项长时间运行的操作。您可以轮询操作状态或等待操作返回。了解详情。
运行模型服务器
在此任务中,您将从 Cloud Storage 下载已导出的模型并启动 Docker 容器,以使您的模型可以接收预测请求。
您的模型必须在 Docker 容器内运行。
要运行模型服务器,请执行以下操作:
在要运行模型的计算机上,切换到要保存导出模型的目录。
下载导出的模型:
gsutil cp -r gcs-destination/* .
其中,gcs-destination 是 Cloud Storage 中导出模型的位置路径。例如:
gsutil cp -r gs://export-us-central1/models/* .
模型会复制到您的当前目录,即位于以下路径下:
./model-export/tbl/tf_saved_model-<model-name>-<export-timestamp>重命名包含时间戳的目录。
mv model-export/tbl/tf_saved_model-<model-name>-<export-timestamp> model-export/tbl/<new-dir-name>此时间戳格式会导致该目录对 Docker 无效。
使用您刚创建的目录名启动 Docker 容器:
docker run -v `pwd`/model-export/tbl/new_folder_name:/models/default/0000001 -p 8080:8080 -it gcr.io/cloud-automl-tables-public/model_server
您随时可以使用 Ctrl-C 停止模型服务器。
更新模型服务器 Docker 容器
因为您在导出模型时下载模型服务器 Docker 容器,所以必须明确更新模型服务器以获取更新和问题修复。您应该使用以下命令定期更新模型服务器:
docker pull gcr.io/cloud-automl-tables-public/model_server
从已导出的模型进行预测
AutoML Tables 映像容器中的模型服务器处理预测请求并返回预测结果。
批量预测不适用于导出的模型。
预测数据的格式
您对预测请求提供的数据(payload 格式)应具有以下 JSON 格式:
{ "instances": [ { "column_name_1": value, "column_name_2": value, … } , … ] }
所需的 JSON 数据类型取决于列的 AutoML Tables 数据类型。请参阅行对象格式了解详情。
以下示例展示了一个包含三列的请求:分类列、数值数组和结构。该请求包含两行。
{
"instances": [
{
"categorical_col": "mouse",
"num_array_col": [
1,
2,
3
],
"struct_col": {
"foo": "piano",
"bar": "2019-05-17T23:56:09.05Z"
}
},
{
"categorical_col": "dog",
"num_array_col": [
5,
6,
7
],
"struct_col": {
"foo": "guitar",
"bar": "2019-06-17T23:56:09.05Z"
}
}
]
}
发出预测请求
将您的请求数据放入文本文件,例如
tmp/request.json。预测请求中的数据行数(称为小批次大小)会影响预测延迟时间和吞吐量。小批次大小越大,延迟时间就越长且吞吐量就越高。要缩短延迟时间,请降低小批次大小。要提高吞吐量,请增加小批次大小。最常用的小批次大小是 1、32、64、128、256、512 和 1024。
请求预测:
curl -X POST --data @/tmp/request.json http://localhost:8080/predict
预测结果的格式
结果的格式取决于模型的类型。
分类模型结果
分类模型(二元和多类)的预测结果会为目标列的每个可能值返回一个概率分数。您必须确定如何使用这些分数。例如,要通过提供的分数获得二元分类,您需要确定阈值。假设有“A”和“B”这两类,如果“A”的得分大于所选阈值,则应将示例归为“A”类,否则应归为“B”类。对于不均衡的数据集,阈值可能接近 100% 或 0%。
分类模型的结果负载类似于以下示例:
{
"predictions": [
{
"scores": [
0.539999994635582,
0.2599999845027924,
0.2000000208627896
],
"classes": [
"apple",
"orange",
"grape"
]
},
{
"scores": [
0.23999999463558197,
0.35999998450279236,
0.40000002086278963
],
"classes": [
"apple",
"orange",
"grape"
]
}
]
}
回归模型结果
为预测请求的每个有效行返回预测值。对于导出的模型,不会返回预测间隔。
回归模型的结果负载类似于以下示例:
{
"predictions": [
3982.3662109375,
3982.3662109375
]
}