En esta página, se describe cómo usar AutoML Tables para exportar tu modelo personalizado a Cloud Storage, descargar el modelo en tu servidor y usar Docker a fin de que el modelo esté disponible para las predicciones.
El modelo exportado solo puede ejecutarse en las CPU de arquitectura x86 que admitan conjuntos de instrucciones de extensiones vectoriales avanzadas (AVX).
Introducción
Los pasos para exportar tu modelo son los siguientes:
Antes de comenzar
Antes de completar esta tarea, debes realizar las siguientes tareas:
- Configurar tu proyecto como se describe en la página sobre qué hacer antes de comenzar
- Entrenar el modelo que deseas descargar
- Instalar y, luego, inicializar la Google Cloud CLI en el servidor que usarás para ejecutar el modelo exportado
- Instalar Docker en tu servidor
Extraer la imagen de Docker del servidor de modelo de AutoML Tables:
sudo docker pull gcr.io/cloud-automl-tables-public/model_server
Exporta un modelo
No puedes exportar un modelo creado antes del 23 de agosto de 2019.
Consola
Ve a la página AutoML Tables en la consola de Google Cloud.
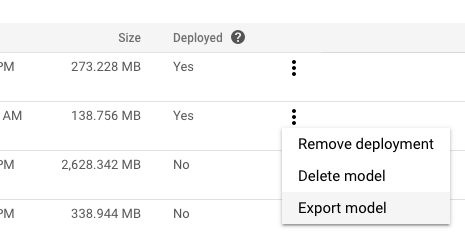
Selecciona la pestaña Modelos en el panel de navegación izquierdo.
En el menú de más acciones del modelo que deseas exportar, haz clic en Exportar modelo (Export model).
Selecciona o crea una carpeta de Cloud Storage en la ubicación deseada.
El bucket debe cumplir con los requisitos del bucket .
No puedes exportar un modelo a un bucket de nivel superior. Debes usar al menos un nivel de carpeta.
Haz clic en Exportar (Export).
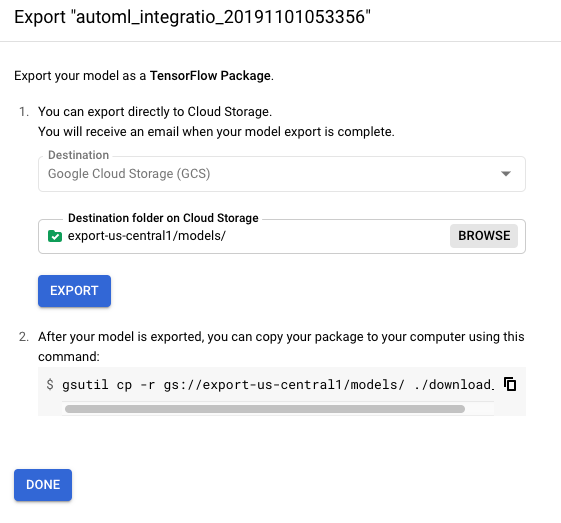
En la siguiente sección, descargarás el modelo exportado a tu servidor.
REST
Usa el método models.export para exportar un modelo a Cloud Storage.Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea -
model-id: el ID del modelo que deseas implementar. Por ejemplo:
TBL543. - gcs-destination: tu carpeta de destino en Cloud Storage. Por ejemplo,
gs://export-bucket/exportsNo puedes exportar un modelo a un bucket de nivel superior. Debes usar al menos un nivel de carpeta.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:export
Cuerpo JSON de la solicitud:
{
"outputConfig": {
"modelFormat": "tf_saved_model",
"gcsDestination": {
"outputUriPrefix": "gcs-destination"
}
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:export"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:export" | Select-Object -Expand Content
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"name": "projects/292381/locations/us-central1/operations/TBL543",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2019-12-30T18:23:47.728373Z",
"updateTime": "2019-12-30T18:23:47.728373Z",
"worksOn": [
"projects/292381/locations/us-central1/models/TBL543"
],
"exportModelDetails": {
"outputInfo": {
"gcsOutputDirectory": "gs://export-bucket/exports/model-export/tbl/tf_saved_model-automl_integration_test_model-2019-12-30T18:23:47.461Z/"
}
},
"state": "RUNNING"
}
}
Exportar un modelo es una operación de larga duración. Puedes consultar el estado de la operación o esperar a que esta se muestre. Obtener más información.
Ejecuta el servidor de modelos
En esta tarea, descargarás el modelo exportado de Cloud Storage y, luego, iniciarás el contenedor de Docker, de modo que el modelo esté listo para recibir solicitudes de predicción.
El modelo debe ejecutarse dentro de un contenedor de Docker.
Para ejecutar el servidor de modelos, haz lo siguiente:
En la máquina donde vas a ejecutar el modelo, cambia el directorio donde deseas guardar el modelo exportado.
Descarga el modelo exportado:
gsutil cp -r gcs-destination/* .
En el ejemplo anterior, gcs-destination es la ruta de acceso a la ubicación del modelo exportado en Cloud Storage. Por ejemplo:
gsutil cp -r gs://export-us-central1/models/* .
El modelo se copia en tu directorio actual, en la siguiente ruta:
./model-export/tbl/tf_saved_model-<model-name>-<export-timestamp>Cambia el nombre del directorio que contiene la marca de tiempo.
mv model-export/tbl/tf_saved_model-<model-name>-<export-timestamp> model-export/tbl/<new-dir-name>El formato de marca de tiempo hace que el directorio no sea válido para Docker.
Inicia el contenedor de Docker con el nombre del directorio que acabas de crear:
docker run -v `pwd`/model-export/tbl/new_folder_name:/models/default/0000001 -p 8080:8080 -it gcr.io/cloud-automl-tables-public/model_server
Puedes detener el servidor de modelo en cualquier momento con Ctrl-C.
Actualiza el contenedor de Docker del servidor de modelo
Debido a que descargas el contenedor de Docker del servidor de modelos cuando exportas el modelo, debes actualizar explícitamente el servidor de modelos para obtener actualizaciones y correcciones de errores. Debes actualizar el servidor del modelo de forma periódica mediante el siguiente comando:
docker pull gcr.io/cloud-automl-tables-public/model_server
Obtén predicciones de tu modelo exportado
El servidor de modelos en el contenedor de imágenes de AutoML Tables controla las solicitudes de predicción y muestra resultados de predicciones.
La predicción por lotes no está disponible para los modelos exportados.
Formato de datos de predicción
Proporciona los datos (campo payload) para tu solicitud de predicción en el siguiente formato JSON:
{ "instances": [ { "column_name_1": value, "column_name_2": value, … } , … ] }
Los tipos de datos JSON obligatorios dependen del tipo de datos AutoML Tables de la columna. Consulta la sección sobre el formato de objeto Row para obtener más detalles.
En el siguiente ejemplo, se muestra una solicitud con tres columnas: una columna categórica, un arreglo numérico y una estructura. La solicitud incluye dos filas.
{
"instances": [
{
"categorical_col": "mouse",
"num_array_col": [
1,
2,
3
],
"struct_col": {
"foo": "piano",
"bar": "2019-05-17T23:56:09.05Z"
}
},
{
"categorical_col": "dog",
"num_array_col": [
5,
6,
7
],
"struct_col": {
"foo": "guitar",
"bar": "2019-06-17T23:56:09.05Z"
}
}
]
}
Realiza la solicitud de predicción
Coloca los datos de tu solicitud en un archivo de texto, por ejemplo:
tmp/request.json.La cantidad de filas de datos en la solicitud de predicción, que se denomina tamaño del minilote, afecta la latencia de predicción y la capacidad de procesamiento. Cuanto mayor sea el tamaño del minilote, mayor será la latencia y la capacidad de procesamiento. Para reducir la latencia, usa un tamaño del minilote más pequeño. Para aumentar la capacidad de procesamiento, aumenta el tamaño del minilote. Los tamaños de minilotes más comunes son 1, 32, 64, 128, 256, 512 y 1,024.
Solicita la predicción:
curl -X POST --data @/tmp/request.json http://localhost:8080/predict
Formato de los resultados de la predicción
El formato de los resultados depende del tipo de tu modelo.
Resultados del modelo de clasificación
Los resultados de la predicción de los modelos de clasificación (binarios y de varias clases) muestran una puntuación de probabilidad para cada valor potencial de la columna objetivo. Debes determinar cómo quieres usar las puntuaciones. Por ejemplo, para obtener una clasificación binaria a partir de las puntuaciones proporcionadas, debes identificar un valor de umbral. Si hay dos clases, “A” y “B”, debes clasificar el ejemplo como “A” si la puntuación de “A” es mayor que el umbral elegido, y “B” en el caso opuesto. En el caso de los conjuntos de datos desequilibrados, el umbral podría aproximarse al 100% o al 0%.
La carga útil de los resultados de un modelo de clasificación es similar a este ejemplo:
{
"predictions": [
{
"scores": [
0.539999994635582,
0.2599999845027924,
0.2000000208627896
],
"classes": [
"apple",
"orange",
"grape"
]
},
{
"scores": [
0.23999999463558197,
0.35999998450279236,
0.40000002086278963
],
"classes": [
"apple",
"orange",
"grape"
]
}
]
}
Resultados del modelo de regresión
Se muestra un valor previsto para cada fila válida de la solicitud de predicción. No se muestran intervalos de predicción para los modelos exportados.
La carga útil de los resultados de un modelo de regresión es similar a este ejemplo:
{
"predictions": [
3982.3662109375,
3982.3662109375
]
}