Nesta página, descrevemos como você pode usar a importância do recurso para ter visibilidade de como o modelo faz as previsões.
Para mais informações sobre as explicações do AI, consulte Introdução às explicações do AI para o AI Platform.
Introdução
Quando você usa um modelo de machine learning para tomar decisões de negócios, é importante entender como os dados de treinamento contribuíram para o modelo final e como o modelo chegou a previsões individuais. Esse entendimento ajuda você a garantir que seu modelo seja justo e preciso.
O AutoML Tables fornece a importância do recurso, às vezes chamado de atribuições de recurso, que permite ver quais recursos contribuíram mais para o treinamento do modelo (importância do recurso do modelo) e previsões individuais (importância do recurso local ).
O AutoML Tables calcula a importância do recurso usando o método Sampled Shapley. Para mais informações sobre a explicabilidade do modelo, consulte Introdução ao AI Explanations.
Importância do recurso do modelo
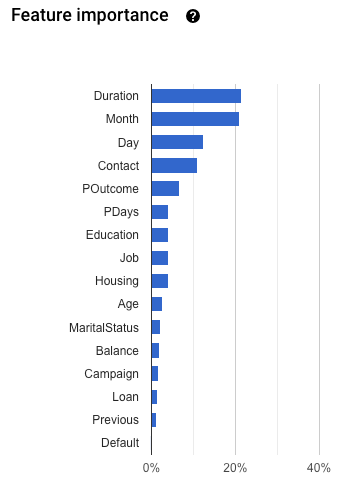
A importância do recurso do modelo ajuda a garantir que os recursos do treinamento de modelo informado sejam coerentes com dados e problemas comerciais. É preciso que todos os recursos com um alto valor de importância representem um indicador válido de previsão e possam ser incluídos de maneira consistente nas solicitações de previsão.
A importância do recurso de modelo é fornecida como uma porcentagem para cada recurso: quanto maior o percentual, mais forte o impacto no treinamento do modelo.
Importar a importância do recurso do modelo
Console
Para conferir os valores de importância dos atributos do seu modelo usando o console do Google Cloud:
Acesse a página do AutoML Tables no console do Google Cloud.
Selecione a guia Modelos no painel de navegação à esquerda e depois selecione um modelo para ver as métricas de avaliação.
Abra a guia Avaliar.
Role para baixo para ver o gráfico Importância do recurso.
REST
Para receber os valores de importância do recurso para um modelo, use o método model.get.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. -
model-id: o código do modelo para o qual você quer receber as informações de importância do recurso.
Por exemplo,
TBL543.
Método HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id
Para enviar a solicitação, escolha uma destas opções:
curl
execute o seguinte comando:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id"
PowerShell
execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id" | Select-Object -Expand Content
{
"name": "projects/292381/locations/us-central1/models/TBL543",
"displayName": "Quickstart_Model",
...
"tablesModelMetadata": {
"targetColumnSpec": {
...
},
"inputFeatureColumnSpecs": [
...
],
"optimizationObjective": "MAXIMIZE_AU_ROC",
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/331",
"columnDisplayName": "Contact",
"featureImportance": 0.093201876
},
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/638",
"columnDisplayName": "Month",
"featureImportance": 0.215029223
},
...
],
"trainBudgetMilliNodeHours": "1000",
"trainCostMilliNodeHours": "1000",
"classificationType": "BINARY",
"predictionSampleRows": [
...
],
"splitPercentageConfig": {
...
}
},
"creationState": "CREATED",
"deployedModelSizeBytes": "1160941568"
}
Java
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Node.js
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Python
A biblioteca de cliente para AutoML Tables inclui outros métodos Python que simplificam o uso da API AutoML Tables. Esses métodos se referem aos conjuntos de dados e aos modelos pelos nomes e não pelos IDs. É preciso que os nomes dos conjuntos de dados e modelos sejam exclusivos. Para mais informações, consulte a Referência do cliente.
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Importância do recurso local
A importância do recurso local dá visibilidade sobre como os recursos individuais em uma solicitação de previsão específica afetaram a previsão resultante.
Para chegar ao valor de importância do recurso de cada local, primeiramente é calculado o valor de referência da pontuação de previsão. Os valores de referência são calculados com base nos dados de treinamento e a utilização do valor mediano para recursos numéricos e do modo para recursos categóricos. A previsão gerada a partir dos valores de referência é o valor de referência da pontuação de previsão.
Para os modelos de classificação, a importância do recurso local informa quanto cada recurso foi adicionado ou subtraído da probabilidade atribuída à classe com pontuação mais alta, em comparação com o valor de referência da pontuação de previsão. Os valores da pontuação estão entre 0,0 e 1,0. Portanto, a importância do recurso local para modelos de classificação está sempre entre -1,0 e 1,0 (inclusive).
Para modelos de regressão, a importância do recurso local de uma previsão informa quanto cada recurso foi adicionado ou subtraído do resultado, em comparação com o valor de referência da pontuação de previsão.
A importância do recurso local está disponível para previsões on-line e em lote.
Importância do recurso local para previsões on-line
Console
Para receber os valores de importância do atributo local de uma previsão on-line usando o console do Google Cloud, siga as etapas em Como fazer uma previsão on-line, marcando a caixa de seleção Gerar importância do atributo.
REST
Para receber a importância do recurso local para uma solicitação de previsão on-line, use o método model.predict, definindo o parâmetro feature_importance como "true".
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - model-id: o código do modelo. Por exemplo,
TBL543. - valueN: os valores de cada coluna, na ordem correta.
Método HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict
Corpo JSON da solicitação:
{
"payload": {
"row": {
"values": [
value1, value2,...
]
}
}
"params": {
"feature_importance": "true"
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict" | Select-Object -Expand Content
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/4704",
"columnDisplayName": "Promo",
"featureImportance": 1626.5464
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/6800",
"columnDisplayName": "Open",
"featureImportance": -7496.5405
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/9824",
"columnDisplayName": "StateHoliday"
}
],
Quando uma coluna tem um valor de importância do atributo de 0, a importância do atributo não é exibida nessa coluna.
Java
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Node.js
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Python
A biblioteca de cliente para AutoML Tables inclui outros métodos Python que simplificam o uso da API AutoML Tables. Esses métodos se referem aos conjuntos de dados e aos modelos pelos nomes e não pelos IDs. É preciso que os nomes dos conjuntos de dados e modelos sejam exclusivos. Para mais informações, consulte a Referência do cliente.
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Como receber a importância do recurso local para previsões em lote
Console
Para receber os valores de importância do atributo local de uma previsão em lote usando o Console do Google Cloud, siga as etapas em Como solicitar uma previsão em lote, marcando a caixa de seleção Gerar importância do atributo.
A importância do recurso é retornada adicionando uma nova coluna para cada recurso, chamada feature_importance.<feature_name>.
REST
Para receber a importância do recurso local para uma solicitação de previsão em lote, use o método model.batchPredict, definindo o parâmetro feature_importance como "true".
O exemplo a seguir usa o BigQuery para os dados da solicitação e os resultados. Você usa o mesmo parâmetro adicional para solicitações que usam o Cloud Storage.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - model-id: o código do modelo. Por exemplo,
TBL543. - dataset-id: o ID do conjunto de dados do BigQuery em que os dados de previsão estão localizados.
-
table-id: o código da tabela do BigQuery em que os dados de previsão estão localizados.
O AutoML Tables cria uma subpasta para os resultados da previsão chamada
prediction-<model_name>-<timestamp>em project-id.dataset-id.table-id.
Método HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corpo JSON da solicitação:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
"params": {"feature_importance": "true"}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
A importância do recurso é retornada adicionando uma nova coluna para cada recurso, chamada feature_importance.<feature_name>.
Considerações sobre o uso da importância do recurso local:
Os resultados da importância do atributo local estão disponíveis somente para modelos treinados a partir de 15 de novembro de 2019.
Não é possível ativar a importância do recurso local em uma solicitação de previsão em lote com mais de 1.000.000 linhas ou 300 colunas.
O valor de importância do recurso local mostra apenas quanto o recurso afetou a previsão para essa linha. Para entender o comportamento geral do modelo, use a importância do recurso do modelo.
Os valores de importância do recurso local sempre estão relacionados ao valor de referência. Lembre-se de consultar o valor de referência ao avaliar os resultados de importância do recurso local. O valor de referência está disponível apenas no console do Google Cloud.
Os valores de importância do recurso local dependem totalmente do modelo e dos dados usados para treinar o modelo. Eles conseguem apenas informar os padrões que o modelo encontrou e não podem detectar relações fundamentais nos dados. Assim, a presença de uma característica de alta importância para um determinado recurso não demonstra uma relação entre esse recurso e o destino. Mostra simplesmente que o modelo está usando o recurso nas previsões.
Se uma previsão incluir dados completamente fora do intervalo dos dados de treinamento, a importância do recurso local pode não fornecer resultados significativos.
A geração de importância de atributos aumenta o tempo e calcula os atributos necessários para sua previsão. Além disso, sua solicitação usa uma cota diferente de solicitações de previsão sem importância de recurso. Saiba mais.
Os valores de importância do recurso não informam se o modelo é justo, imparcial ou de boa qualidade. Você deve avaliar cuidadosamente o conjunto de dados de treinamento, o procedimento e as métricas de avaliação, além da importância do recurso.