本页面介绍如何在训练模型后使用模型的评估指标,并提供了一些基本建议来帮助您提高模型性能。
简介
在训练模型之后,AutoML Tables 使用测试数据集来评估新模型的质量和准确率,并提供一组评估指标来说明模型在测试数据集上的性能。
您的业务需求以及训练模型用于解决什么问题,决定了如何使用评估指标来确定模型的质量。例如,假正例的成本可能高于假负例,或者反之。对于回归模型,预测结果和正确答案之间的差值是否重要?这些问题会影响您如何看待模型评估指标。
如果您在训练数据中包含权重列,它对评估指标没有影响。权重仅在训练阶段有用。
分类模型的评估指标
分类模型提供以下指标:
AUC PR:精确率-召回率 (PR) 曲线下的面积。此值的范围在 0 到 1 之间,值越大表示模型质量越高。
AUC ROC:接收者操作特征 (ROC) 曲线下的面积。 此值的范围在 0 到 1 之间,值越大表示模型质量越高。
准确率:模型生成的正确分类预测所占的比例。
对数损失:模型预测与目标值之间的交叉熵。此值的范围在零到无穷大之间,值越小表示模型质量越高。
F1 得分:精确率和召回率的调和平均数。如果您希望在精确率和召回率之间取得平衡,而类别分布又不均匀,F1 指标会非常有用。
精确率:模型生成的正确正例预测所占的比例。(正例预测为假正例和真正例组合)。
召回率:模型正确预测的具有此标签的行所占的比例。也称为“真正例率”。
假正例率:模型预测为目标标签、但事实上不是的行(假正例)所占的比例。
对目标列每个不同的值会返回这些指标。对于多类别分类模型,这些指标均为微均值,并作为摘要指标返回。对于二元分类模型,使用少数类的指标作为摘要指标。微平均指标是数据集随机样本上各个指标的预期值。
除上述指标外,AutoML Tables 还提供其他两种了解分类模型的方法:混淆矩阵和特征重要性图。
混淆矩阵:混淆矩阵可帮助您了解分类错误的出现位置(哪些类与其他类“混淆”)。每一行代表特定标签的标准答案,每一列显示模型预测的标签。
只有目标列的值不超过 10 个的分类模型才提供混淆矩阵。

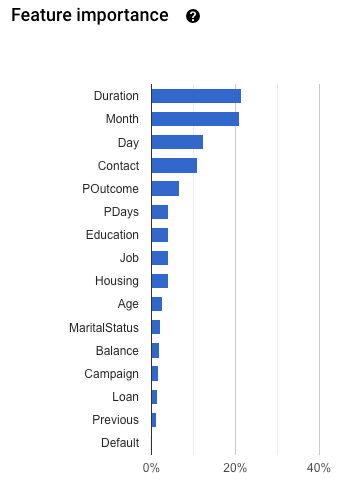
特征重要性:AutoML Tables 告诉您每个特征对此模型的影响程度。它显示在特征重要性图中。这些值是以每个特征的百分比形式提供的:百分比越高,特征对模型训练的影响就越大。
您应该查看此信息,以确保所有最重要的特征对您的数据和业务问题都有所帮助。详细了解可解释性。
如何计算微平均精确率
微平均精确率计算方法:目标列每个潜在值的真正例 (TP) 总个数除以每个潜在值真正例 (TP) 和真负例 (TN) 个数之和。
\[ precision_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
其中:
- \(TP_1 + \ldots + TP_n\) 是每个类(共 n 个类)真正例的总和
- \(FP_1 + \ldots + FP_n\) 是每个类(共 n 个类)真负例的总和
分数阈值
分数阈值是一个介于 0 到 1 之间的数字。它提供了一种指定最小置信度的方法,达到此置信度的给定预测值应被视为 true。例如,如果您有一个不太可能是实际值的类,那么您应该降低该类的阈值;使用 0.5 或更高的阈值会导致该类极少(或从不)被预测。
阈值较高会减少假正例,但会造成更多的假负例。阈值较低会减少假负例,但会造成更多的假正例。
换言之,分数阈值会影响精确率和召回率。较高的阈值会导致精确率提高(因为模型除非在极为确定时,否则绝不会做出预测),但召回率(模型正确获取正例的百分比)会降低。
回归模型的评估指标
回归模型提供以下指标:
MAE:平均绝对误差 (MAE) 指的是目标值与预测值之间的平均绝对差。此指标的范围在零到无穷大之间;值越小表示模型质量越高。
RMSE:均方根误差是一个常用的衡量指标,用来衡量模型预测值或估计值与观察值之间的差异。此指标的范围在零到无穷大之间;值越小表示模型质量越高。
RMSLE:均方根对数误差指标与 RMSE 类似,不同的是它使用预测值和实际值加 1 的自然对数。RMSLE 对预测不足的罚分比过度预测更重。如果您不希望对大预测值误差的罚分比对小预测值的更重,则此指标也非常适合您的需求。此指标的范围在零到无穷大之间;值越小表示模型质量越高。只有当所有标签值和预测值均为非负值时,才会返回 RMSLE 评估指标。
r^2:r 平方 (r^2) 是标签值与预测值之间的皮尔逊相关系数的平方,该指标的范围介于 0 和 1 之间;值越高表示模型质量越高。
MAPE:平均绝对百分比误差 (MAPE) 指的是标签与预测值之间的平均绝对百分比差。该指标的范围介于 0 到无穷大之间;值越低表示模型质量越高。
如果目标列包含任何为 0 的值,则 MAPE 不会显示。在这种情况下,MAPE 未经定义。
特征重要性:AutoML Tables 告诉您每个特征对此模型的影响程度。它显示在特征重要性图中。这些值是以每个特征的百分比形式提供的:百分比越高,特征对模型训练的影响就越大。
您应该查看此信息,以确保所有最重要的特征对您的数据和业务问题都有所帮助。详细了解可解释性。
获取模型的评估指标
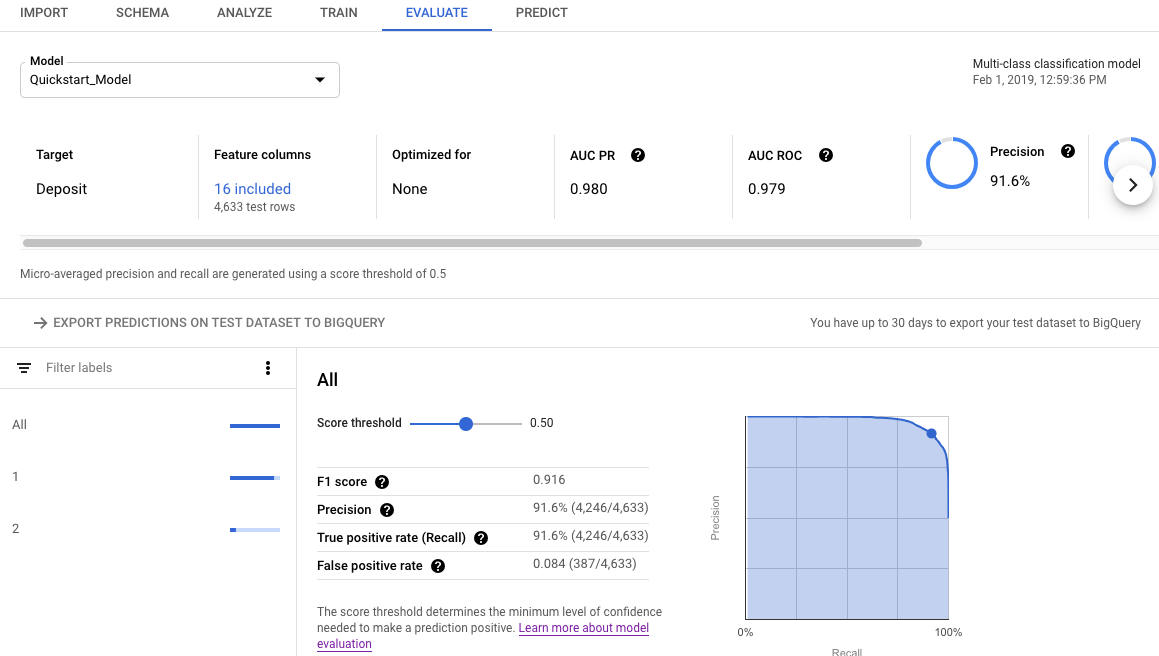
如需评估模型在测试数据集上的表现,请检查模型的评估指标。
控制台
如需使用 Google Cloud 控制台查看模型的评估指标,请执行以下操作:
转到 Google Cloud 控制台中的 AutoML Tables 页面。
选择左侧导航窗格中的模型标签页,然后选择要获取评估指标的模型。
打开评估标签页。
摘要评估指标显示在屏幕顶部。对于二元分类模型,摘要指标是少数类的指标。对于多类别分类模型,摘要指标为微均值指标。
对于分类指标,您可以点击各个目标值来查看该值的指标。
REST
若要使用 Cloud AutoML API 获取模型的评估指标,请使用 modelEvaluations.list 方法。
在使用任何请求数据之前,请先进行以下替换:
-
endpoint:全球位置为
automl.googleapis.com,欧盟地区为eu-automl.googleapis.com。 - project-id:您的 Google Cloud 项目 ID。
- location:资源的位置:全球位置为
us-central1,欧盟位置为eu。 -
model-id:您要评估的模型的 ID。例如
TBL543。
HTTP 方法和网址:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
如需发送请求,请选择以下方式之一:
curl
执行以下命令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
如果资源位于欧盟区域,您必须明确设置端点。了解详情。
Node.js
如果资源位于欧盟区域,您必须明确设置端点。了解详情。
Python
AutoML Tables 的客户端库包含其他 Python 方法,这些方法使用 AutoML Tables API 进行简化。这些方法按名称而不是 ID 来引用数据集和模型。您的数据集和模型的名称必须是唯一的。如需了解详情,请参阅客户端参考。
如果资源位于欧盟区域,您必须明确设置端点。了解详情。
使用 API 了解评估结果
使用 Cloud AutoML API 获取模型评估指标时,系统会返回大量信息。了解指标结果的结构有助于您解读结果并使用结果来评估模型。
分类结果
对于分类模型,结果包含多个 ModelEvaluation 对象,每个对象包含多个 ConfidenceMetricsEntry 对象。了解结果的结构有助于您在评估模型时选择正确的对象。
对训练数据中存在的目标列的每个不同值返回两个 ModelEvaluation 对象。此外,还有两个 ModelEvaluation 摘要对象和一个可以忽略的空 ModelEvaluation 对象。
对特定标签值返回的两个 ModelEvaluation 对象显示 displayName 字段中的标签值。它们各自使用不同的位置阈值:1 和 MAX_INT(可能的最大值)。位置阈值决定着对一个预测考虑多少个结果。对于分类问题,使用位置阈值 1 通常是最合理的,因为仅为每个输入选择一个标签。对于多标签问题,可以为每个输入选择多个标签,因此针对 MAX_INT 位置阈值返回的评估指标可能更有用。您应根据模型的特定用例确定要使用的指标。
除作为混淆矩阵的一部分时,这两个 ModelEvaluation 概要对象不包含 displayName 字段。此外,它们的 evaluatedExampleCount 字段值是训练数据的总行数。对于多类别分类模型,摘要对象会根据所有各个标签指标提供微均值指标。对于二元分类模型,使用少数类的指标作为摘要指标。将位置阈值为 1 的 ModelEvaluation 对象用于摘要指标。
每个 ModelEvaluation 对象最多包含 100 个 ConfidenceMetricsEntry 对象,具体取决于训练数据。每个 ConfidenceMetricsEntry 对象都会为置信度阈值(也称为得分阈值)提供一个不同的值。
摘要 ModelEvaluation 对象与以下示例类似。请注意,字段显示顺序可能有所不同。
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
特定于标签的 ModelEvaluation 对象与以下示例类似。请注意,字段显示顺序可能有所不同。
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
回归结果
对于回归模型,您应该会看到类似于如下示例的输出:
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
排查模型问题
模型评估指标应该是良好的,但不应该是完美的。模型性能低下和性能完美都表示训练过程出现了问题。
性能不佳
如果模型效果没有达到您的预期,您可以尝试以下操作。
检查您的架构。
确保所有列都具有正确的类型,并且将所有不具有预测性的列(例如 ID 列)排除在训练之外。
检查您的数据
如果不可为 Null 的列中出现缺失值,缺失值对应的行会被忽略。 确保您的数据没有太多错误。
导出并检查测试数据集。
当模型进行了不正确的预测时,检查数据并进行分析,让您有可能确认需要更多训练数据针对某个特定结果,或者训练数据中引入了泄露。
增加训练数据量。
如果您没有足够多的训练数据,模型质量会受到影响。 确保您的训练数据尽可能无偏差。
增加训练时间。
如果训练时间很短,您可以延长训练时间来获得质量更高的模型。
性能完美
如果您的模型返回了近乎完美的评估指标,那么您的训练数据可能存在问题。以下是一些可以检查的事项:
目标泄露
目标泄露是指训练数据中包含有在训练时本应无法知晓的基于结果的特征。 例如,如果您训练一个用于确定新用户是否会进行购买的模型,并在其中包括了“频繁买家”编号,则该模型的评估指标将极其优异,但在真实数据上的性能会很差,因为真实数据中不可能包括频繁买家编号。
若要检查是否存在目标泄露,请查看模型的评估标签页上的特征重要性图。确保具有高重要性的列确实具有预测功能,并且不会泄露关于目标的信息。
时间列
如果数据的时间很重要,请确保使用时间列或基于时间的手动拆分。不这样做可能会导致您的评估指标出现偏差。了解详情。
将测试数据集下载到 BigQuery
您可以下载测试数据集(包括目标列),以及每行的模型结果。检查那些模型预测错误的行,可以为改进模型提供线索。
在 Google Cloud 控制台中打开 AutoML Tables。
在左侧导航窗格中选择模型,然后点击您的模型。
打开评估标签页,然后点击将基于测试数据集的预测导出至 BigQuery。
导出完成后,点击在 BigQuery 中查看您的评估结果以查看数据。