Nesta página, você aprenderá como usar as métricas de avaliação do modelo depois do treinamento. Esta página contém algumas sugestões básicas sobre como melhorar o desempenho do modelo.
Introdução
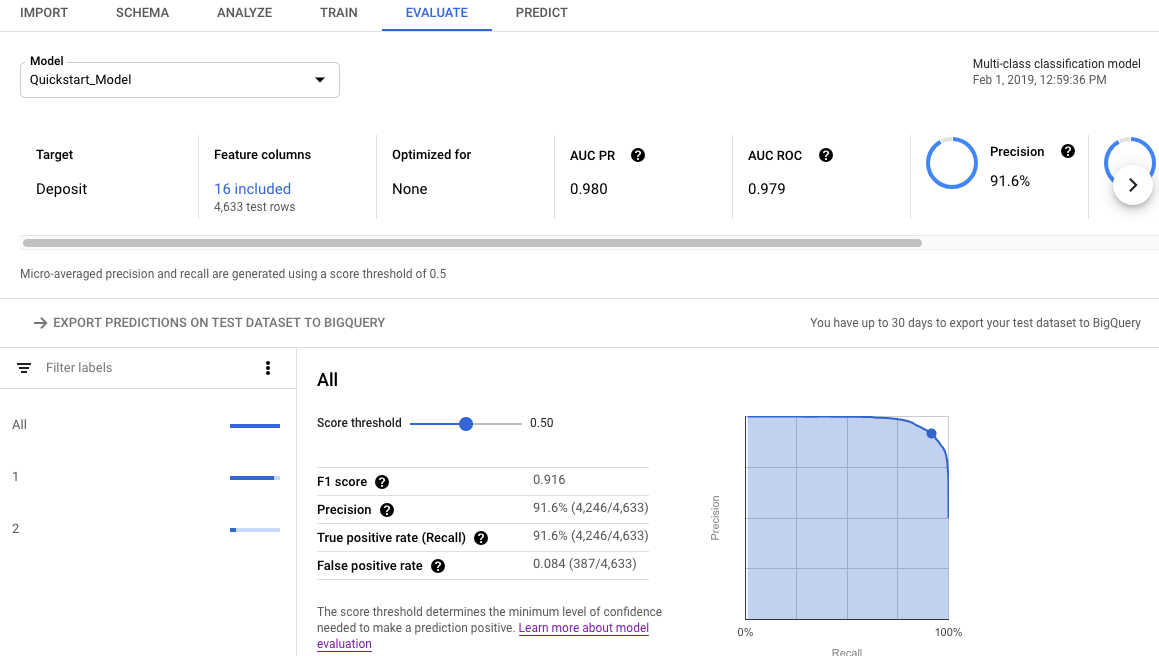
Após treinar um modelo, o AutoML Tables usa o conjunto de dados de teste para avaliar a qualidade e a acurácia do modelo novo. Além disso, ele fornece um conjunto agregado de métricas de avaliação que indicam como foi o desempenho do modelo com o conjunto de dados de teste.
Usar as métricas de avaliação para determinar a qualidade do modelo depende das necessidades do seu negócio e do problema que seu modelo foi treinado para solucionar. Por exemplo, talvez resultados de falso positivo gerem um custo maior do que os de falso negativo, ou vice-versa. No caso dos modelos de regressão, o delta entre a previsão e a resposta correta é importante ou não? Esses tipos de perguntas afetam a maneira como você analisará as métricas de avaliação do modelo.
Se você incluiu uma coluna de peso nos dados de treinamento, isso não afeta as métricas de avaliação. Os pesos são considerados apenas durante a fase de treinamento.
Métricas de avaliação de modelos de classificação
Os modelos de classificação geram as seguintes métricas:
AUC PR: a área sob curva de precisão-recall (PR, na sigla em inglês). Ela varia de 0 a 1. Um valor maior indica um modelo de melhor qualidade.
AUC ROC: a área sob a curva de característica de operação do receptor (ROC, na sigla em inglês). Ela varia de 0 a 1. Um valor maior indica um modelo de melhor qualidade.
Acurácia: a fração de predições de classificação produzidas pelo modelo que estavam corretas.
Log Perda: a entropia cruzada entre as predições do modelo e os valores do objetivo. Ela varia de zero a infinito. Um valor menor indica um modelo de melhor qualidade.
Pontuação F1: a média harmônica de precisão e recall. F1 é uma métrica útil se você está procurando um equilíbrio entre precisão e recall, e a distribuição de classes é desigual.
Precisão: a fração de previsões positivas produzidas pelo modelo que estavam corretas. Previsões positivas são os falsos positivos e os verdadeiros positivos combinados.
Recall: a fração de linhas com esse rótulo que o modelo previu corretamente. Também chamada de “taxa de verdadeiro positivo”.
Taxa de falso positivo: a fração de linhas previstas pelo modelo para ser o rótulo do objetivo, mas que não são (falso positivo).
Essas métricas são retornadas para cada valor distinto da coluna de destino. Para modelos de classificação multiclasses, essas métricas são microcalculadas e retornadas como métricas de resumo. Para modelos de classificação binária, as métricas de classe minoritária são usadas como métricas de resumo. Os microcálculos das métricas são os valores esperados de cada métrica em uma amostra aleatória do conjunto de dados.
Além das métricas acima, o AutoML Tables fornece outras duas maneiras de entender seu modelo de classificação: a matriz de confusão e um gráfico de importância do recurso.
Matriz de confusão: a matriz de confusão ajuda a entender onde ocorrem as classificações erradas (quais classes são confundidas com outras). Cada linha representa as informações empíricas de um rótulo específico, e cada coluna mostra os rótulos previstos pelo modelo.
Matrizes de confusão são fornecidas somente para modelos de classificação com 10 ou menos valores para a coluna de destino.

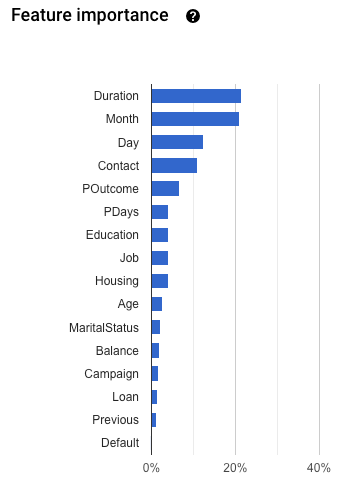
Importância do recurso: o AutoML Tables informa quanto cada recurso afeta esse modelo. Ele é mostrado no gráfico Importância do recurso. Os valores são fornecidos como uma porcentagem para cada recurso: quanto maior a porcentagem, mais forte o recurso afetou o treinamento do modelo.
Analise essas informações para garantir que todos os recursos mais importantes façam sentido para seus dados e problemas empresariais. Saiba mais sobre explicabilidade.
Como a micromédia de precisão é calculada
A micromédia de precisão é calculada pela soma do número de verdadeiros positivos (TP, na sigla em inglês) para cada valor potencial da coluna de destino, dividida pelo número de verdadeiros positivos (TP) e verdadeiros negativos (TN) para cada valor potencial.
\[ precision_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
onde
- \(TP_1 + \ldots + TP_n\) é a soma dos verdadeiros positivos para cada uma das n classes
- \(FP_1 + \ldots + FP_n\) é a soma dos falsos positivos para cada uma das n classes
Limite de pontuação
O limite de pontuação é um número que varia de 0 a 1. Ele é usado para especificar o nível de confiança mínimo em que um dado valor de previsão deve ser considerado verdadeiro. Por exemplo, se você tiver uma classe com pouca probabilidade de ser o valor real, é mais conveniente diminuir o limite dela. Usar um limite de 0,5 ou superior resultaria nessa classe sendo prevista muito raramente (ou nunca).
Um limite maior diminui os falsos positivos às custas de mais falsos negativos. Um limite maior diminui os falsos negativos às custas de mais falsos positivos.
Ou seja, o limite de pontuação afeta a precisão e o recall. Um limite maior resulta no aumento da precisão (porque o modelo nunca faz uma previsão, a não ser que seja extremamente seguro), mas o recall (porcentagem de exemplos positivos que o modelo acerta) diminui.
Métricas de avaliação de modelos de regressão
Os modelos de regressão geram as seguintes métricas:
MAE: erro médio absoluto (MAE, na sigla em inglês) é a diferença média absoluta entre valores desejados e valores previstos. Essa métrica varia de zero a infinito. Um valor menor indica um modelo de qualidade superior.
REMQ: a métrica de raiz do erro médio quadrado é uma medida, usada com frequência, das diferenças entre os valores previstos por um modelo ou um estimator e os valores observados. Essa métrica varia de zero a infinito. Um valor menor indica um modelo de qualidade superior.
RMSLE: a métrica de raiz do erro médio quadrado e logarítmico é semelhante à RMSE. A diferença é que é usado o logaritmo natural de valores previstos e valores reais mais 1. A RMSLE penaliza com mais intensidade a subestimação do que a superestimação. Também pode ser uma boa métrica quando você não quer penalizar as diferenças de grandes valores de previsão com mais intensidade do que para pequenos valores de previsão. Essa métrica varia de zero a infinito. Um valor menor indica um modelo de qualidade superior. A métrica de avaliação RMSLE é retornada somente se todos os rótulos e valores previstos forem não negativos.
r²: r ao quadrado (r²) é o quadrado do coeficiente de correlação de Pearson entre os valores observados e previstos. Essa métrica varia de zero a um. Um valor maior indica um modelo de qualidade superior.
MAPE: o erro absoluto médio percentual (MAPE, na sigla em inglês) é a diferença percentual absoluta média entre os rótulos e os valores previstos. Varia de zero a infinito. Um valor menor indica um modelo de qualidade superior.
O MAPE não é exibido se na coluna de destino houver algum valor zero. Nesse caso, o MAPE será indefinido.
Importância do recurso: o AutoML Tables informa quanto cada recurso afeta esse modelo. Ele é mostrado no gráfico Importância do recurso. Os valores são fornecidos como uma porcentagem para cada recurso: quanto maior a porcentagem, mais forte o recurso afetou o treinamento do modelo.
Analise essas informações para garantir que todos os recursos mais importantes façam sentido para seus dados e problemas empresariais. Saiba mais sobre explicabilidade.
Como visualizar as métricas de avaliação de um modelo
Para avaliar o desempenho do modelo com conjunto de dados de teste, é necessário inspecionar as métricas de avaliação.
Console
Para ver as métricas de avaliação do modelo usando o console do Google Cloud:
Acesse a página do AutoML Tables no console do Google Cloud.
Selecione a guia Modelos no painel de navegação à esquerda e depois selecione um modelo para ver as métricas de avaliação.
Abra a guia Avaliar.
As métricas de avaliação de resumo são exibidas na parte superior da tela. Para modelos de classificação binária, as métricas de resumo são as métricas da classe minoritária. Para modelos de classificação multiclasses, as métricas de resumo são as métricas de microcálculos.
Para métricas de classificação, clique nos valores individuais para ver as métricas desse valor.
REST
Para receber métricas de avaliação do modelo com a API Cloud AutoML, use o método modelEvaluations.list.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. -
model-id: o código do modelo que você quer avaliar. Por exemplo,
TBL543.
Método HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
Para enviar a solicitação, escolha uma destas opções:
curl
execute o seguinte comando:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Node.js
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Python
A biblioteca de cliente para AutoML Tables inclui outros métodos Python que simplificam o uso da API AutoML Tables. Esses métodos se referem aos conjuntos de dados e aos modelos pelos nomes e não pelos IDs. É preciso que os nomes dos conjuntos de dados e modelos sejam exclusivos. Para mais informações, consulte a Referência do cliente.
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Como entender os resultados de avaliação usando a API
Quando você usa a API Cloud AutoML para receber as métricas de avaliação do modelo, uma grande quantidade de informações é retornada. Entender como os resultados das métricas são estruturados ajuda a interpretar os resultados e usá-los para avaliar seu modelo.
Resultados da classificação
Para um modelo de classificação, os resultados incluem vários objetos ModelEvaluation, cada um contendo vários objetos ConfidenceMetricsEntry. O entendimento de como os resultados são estruturados ajuda a escolher os objetos corretos para uso na avaliação do seu modelo.
Dois objetos ModelEvaluation são retornados para cada valor distinto da coluna de destino, presente nos dados de treinamento. Além disso, há dois objetos ModelEvaluation de resumo e um objeto ModelEvaluation vazio que podem ser ignorados.
Os dois objetos ModelEvaluation retornados para um valor específico do rótulo mostram o valor do rótulo no campo displayName. Cada um deles usa valores diferentes de limite de posicionamento: um e MAX_INT (o maior número possível). O limite de posicionamento determina quantos resultados serão considerados para uma previsão.
Para um problema de classificação, usar um limite de posição geralmente faz
mais sentido, porque há apenas um rótulo escolhido para cada entrada. Para
problemas com vários rótulos, mais de um rótulo pode ser escolhido por entrada. Dessa forma,
as métricas de avaliação retornadas para o limite de posição MAX_INT podem ser mais
úteis. Determine quais métricas usar com base no caso de uso
específico do modelo.
Os dois objetos ModelEvaluation de resumo não incluem o campo displayName, exceto como parte da matriz de confusão. O valor do campo evaluatedExampleCount também é o número total de linhas nos dados de treinamento.
Para modelos de classificação multiclasses, os objetos de resumo fornecem as métricas de microcálculos com base em todas as métricas por rótulo.
Para modelos de classificação binária, as métricas de classe minoritária são usadas como métricas de resumo. Use o objeto ModelEvaluation com um limite de posicionamento de um para suas métricas de resumo.
Cada objeto ModelEvaluation tem até 100 objetos ConfidenceMetricsEntry, dependendo dos dados de treinamento. Cada objeto ConfidenceMetricsEntry fornece um valor diferente para o limite de confiança, também chamado de limite de pontuação.
Os objetos ModelEvaluation de resumo são semelhantes ao seguinte exemplo. Observe que a ordem de exibição do campo pode ser diferente.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
Os objetos ModelEvaluation específicos de rótulo são semelhantes ao exemplo a seguir. Observe que a ordem de exibição do campo pode ser diferente.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
Resultados de regressão
No caso de modelos de regressão, a saída será semelhante ao exemplo a seguir:
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
Resolução de problemas de modelos
As métricas de avaliação do modelo precisam ser adequadas, mas não perfeitas. Tanto um desempenho fraco quanto perfeito são indicadores de que algo de errado ocorreu no processo de treinamento.
Desempenho fraco
Se o modelo não tem um desempenho tão bom quanto desejado, tente as opções abaixo.
Revise o esquema.
Verifique se todas as colunas têm o tipo correto e exclua do treinamento todas aquelas que não sejam preditivas, como colunas de ID.
Analise os dados.
Valores ausentes em colunas não anuláveis fazem com que a linha seja ignorada. Garanta que os dados não tenham muitos erros.
Exporte o conjunto de dados de teste e examine-o.
Ao inspecionar os dados e analisar quando o modelo está realizando predições incorretas, é possível que você chegue à conclusão que são necessários mais dados de treinamento para alcançar um determinado resultado ou que os dados de treinamento introduziram vazamentos.
Aumente a quantidade dos dados de treinamento.
Se os dados de treinamento forem insuficientes, a qualidade do modelo será prejudicada. Verifique se os dados de treinamento são os mais imparciais possíveis.
Aumente o tempo de treinamento.
Se o tempo de treinamento for curto, treiná-lo por um período maior poderá resultar em um modelo de melhor qualidade.
Desempenho perfeito
Se o modelo retornou métricas de avaliação quase perfeitas, talvez haja algo de errado com os dados de treinamento. Veja abaixo o que é preciso observar:
Vazamento de objetivo
O vazamento de objetivo ocorre quando é incluído nos dados de treinamento um atributo que não pode ser conhecido no momento de treinamento e é baseado no resultado. Por exemplo, se você incluísse o número de um comprador frequente em um modelo treinado para decidir se um usuário iniciante faria uma compra, esse modelo teria métricas de avaliação muito altas, mas um desempenho deficiente com dados reais, porque o número de comprador frequente não poderia ser incluído.
Para verificar se há vazamento no destino, revise o gráfico Importância de atributos, na guia Avaliar do modelo. Verifique se as colunas com alta importância são realmente preditivas e não estão vazando informações sobre o objetivo.
Coluna Data/hora
Se a passagem do tempo for importante para os dados, verifique se você usou a coluna Data/hora ou fez uma divisão manual com base nesse requisito. Ignorar isso pode resultar na distorção das métricas de avaliação. Saiba mais.
Como fazer download do conjunto de dados de teste para o BigQuery
É possível fazer o download do conjunto de dados de teste, incluindo a coluna de objetivo, junto com o resultado do modelo para cada linha. Inspecionar as linhas que o modelo respondeu incorretamente pode fornecer algumas pistas sobre como melhorá-lo.
Abra o AutoML Tables no console do Google Cloud.
Selecione Modelos, no painel de navegação à esquerda e clique no modelo.
Abra a guia Avaliar e clique em Exportar previsões do conjunto de dados de teste para o BigQuery.
Após a conclusão da exportação, clique em Ver os resultados da avaliação no BigQuery para ver seus dados.
A seguir
- Implante o modelo para receber previsões on-line.
- Receba previsões em lote do modelo.