Auf dieser Seite wird beschrieben, wie Sie das Modell nach dem Training mithilfe von Messwerten bewerten. Außerdem erhalten Sie Tipps zur grundlegenden Verbesserung der Modellleistung.
Einführung
Im Anschluss an das Modelltraining werden die Qualität und die Genauigkeit des neuen Modells in AutoML Tables mithilfe des Test-Datasets bewertet. Ein aggregierter Satz von Bewertungsmesswerten gibt außerdem Auskunft darüber, wie gut das Modell mit dem Test-Dataset funktioniert hat.
Wie Sie mithilfe der Bewertungsmesswerte die Modellqualität ermitteln, hängt von Ihren geschäftlichen Anforderungen und dem Problem ab, für dessen Lösung das Modell trainiert wurde. Falsch positive Ergebnisse können beispielsweise höhere Kosten als falsch negative Ergebnisse verursachen oder umgekehrt. Spielt bei Regressionsmodellen das Delta zwischen der Vorhersage und der richtigen Antwort eine Rolle? Diese Aspekte beeinflussen, wie Sie die Messwerte bei der Modellbewertung betrachten.
Wenn Sie in die Trainingsdaten eine Gewichtungsspalte einbezogen haben, wirkt sich diese nicht auf die Bewertungsmesswerte aus. Gewichtungen werden nur während der Trainingsphase berücksichtigt.
Bewertungsmesswerte für Klassifizierungsmodelle
Klassifizierungsmodelle bieten die folgenden Messwerte:
AUC PR: der Bereich unter der Genauigkeits-/Trefferquotenkurve (Precision-Recall, PR). Dieser reicht von null bis eins, wobei ein höherer Wert auf ein Modell von höherer Qualität verweist.
AUC ROC: der Bereich unter der Grenzwertoptimierungskurve (Receiver Operating Curve, ROC). Dieser reicht von null bis eins, wobei ein höherer Wert auf ein Modell von höherer Qualität verweist.
Genauigkeit: der Anteil an Klassifizierungsvorhersagen des Modells, die richtig waren.
Logarithmischer Verlust: cie Kreuzentropie zwischen den Modellvorhersagen und den Zielwerten. Diese hat einen Bereich von null bis unendlich, wobei ein niedrigerer Wert auf ein Modell von höherer Qualität hinweist.
F1-Wert: der harmonische Mittelwert von Precision und Recall. F1 ist ein hilfreicher Messwert, wenn Sie ein Gleichgewicht zwischen Genauigkeit und Trefferquote herstellen möchten und eine ungleiche Klassenverteilung besteht.
Präzision: Der Anteil an Klassifizierungsvorhersagen des Modells, die richtig waren. (Positive Vorhersagen sind die falsch und die richtig positiven Werte zusammengerechnet.)
Trefferquote: Der Anteil an Zeilen mit diesem Label, die das Modell korrekt vorhergesagt hat. Sie wird auch als Rate der "echt positiven Ergebnisse" bezeichnet.
Rate falsch positiver Ergebnisse: Der Anteil der Zeilen, die vom Modell fälschlicherweise als Ziellabel vorhergesagt wurden.
Diese Messwerte werden für jeden unterschiedlichen Wert der Zielspalte zurückgegeben. Bei Klassifizierungsmodellen mit mehreren Klassen wird für diese Messwerte Micro-Averaging durchgeführt. Sie werden dann als zusammengefasste Messwerte zurückgegeben. Bei binären Klassifizierungsmodellen werden die Messwerte für die Minderheitsklasse als zusammengefasste Messwerte verwendet. Die Micro-Averaging-Messwerte sind der erwartete Wert jedes Messwerts in einer zufälligen Stichprobe aus dem Dataset.
Zusätzlich zu den oben genannten Messwerten bietet AutoML Tables zwei weitere Möglichkeiten zum besseren Verständnis Ihres Klassifizierungsmodells: die Wahrheitsmatrix und eine Grafik zur Merkmalwichtigkeit.
Wahrheitsmatrix:: Diese sorgt für ein besseres Verständnis der Fehlklassifizierungen, z. B. welche Klassen „verwechselt” werden. Jede Zeile stellt die Ground-Truth-Daten für ein bestimmtes Label dar und jede Spalte zeigt die vom Modell vorhergesagten Labels an.
Wahrheitsmatrizes werden nur für Klassifizierungsmodelle mit zehn oder weniger Werten für die Zielspalte bereitgestellt.

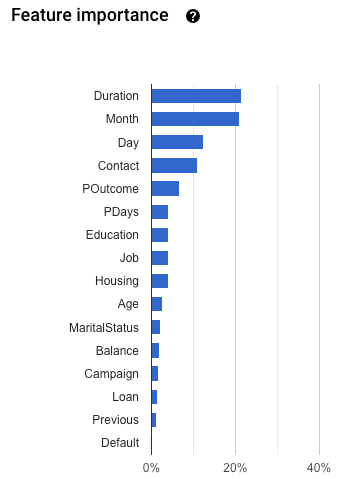
Merkmalwichtigkeit: AutoML Tables gibt an, wie stark sich jedes Merkmal auf dieses Modell auswirkt. Sie wird in der Grafik Merkmalwichtigkeit angezeigt. Die Werte werden für jedes Merkmal als Prozentsatz angegeben. Je höher der Prozentsatz, desto stärker hat sich das Merkmal auf das Modelltraining ausgewirkt.
Sie sollten diese Informationen lesen, um sicherzustellen, dass alle wichtigen Merkmale für Ihre Daten- und Geschäftsprobleme sinnvoll sind. Weitere Informationen zur Erklärbarkeit
Berechnung von Micro-Averaging für Genauigkeit
Micro-Averaging für Genauigkeit wird berechnet, indem die Anzahl der richtig positiven Werte (TP) für jeden potenziellen Wert der Zielspalte addiert und durch die Anzahl der richtig positiven Werte (TP) und richtig negativen Werte (TN) für jeden potenziellen Wert geteilt wird.
\[ precision_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
Wobei Folgendes gilt:
- \(TP_1 + \ ldots + TP_n \) ist die Summe der richtig positiven Werte für jede der n Klassen
- \(FP_1 + \ ldots + FP_n \) ist die Summe der falsch positiven Werte für jede der n Klassen
Punktzahl-Schwellenwert
Der Punktzahl-Schwellenwert ist eine Zahl zwischen 0 und 1. Er bietet eine Möglichkeit, das minimale Konfidenzniveau anzugeben, bei dem ein bestimmter Vorhersagewert als wahr angenommen werden soll. Wenn Sie beispielsweise eine Klasse haben, bei der es recht unwahrscheinlich ist, dass sie der tatsächliche Wert ist, sollten Sie den Schwellenwert für diese Klasse senken. Wenn Sie einen Schwellenwert von 0,5 oder höher verwenden, wird diese Klasse extrem selten oder nie vorhergesagt.
Durch einen höheren Schwellenwert werden falsch positive Werte verringert, jedoch falsch negative Werte erhöht. Ein niedriger Schwellenwert verringert falsch negative Werte, jedoch erhöht er falsch positive Werte.
Anders ausgedrückt wirkt sich der Punktzahl-Schwellenwert auf die Genauigkeit und die Trefferquote aus. Ein höherer Schwellenwert führt zu einer Erhöhung der Genauigkeit, da das Modell nie eine Vorhersage trifft, es sei denn, es ist extrem sicher. Die Trefferquote (der Prozentsatz positiver Beispiele, die das Modell richtig abruft) nimmt jedoch ab.
Bewertungsmesswerte für Regressionsmodelle
Regressionsmodelle bieten die folgenden Messwerte:
MAE: Der mittlere absolute Fehler (Mean Absolute Error) ist die durchschnittliche absolute Differenz zwischen den Zielwerten und den vorhergesagten Werten. Dieser Messwert reicht von null bis unendlich. Ein niedrigerer Wert gibt ein höheres Qualitätsmodell an.
RMSE: Dieser Messwert der Wurzel des mittleren quadratischen Fehlers (Root Mean Square Error) wird häufig zur Messung des Unterschieds zwischen den von einem Modell oder einem Estimator vorhergesagten Werten und den beobachteten Werten verwendet. Dieser Messwert reicht von null bis unendlich. Ein niedrigerer Wert gibt ein höheres Qualitätsmodell an.
RMSLE: Dieser Messwert der Wurzel des mittleren quadratischen logarithmischen Fehlers ähnelt RMSE, verwendet jedoch den natürlichen Logarithmus der vorhergesagten und tatsächlichen Werte plus 1. RMSLE bestraft eine unterdurchschnittliche Vorhersage stärker als eine überdurchschnittliche Vorhersage. Er kann auch ein guter Messwert sein, wenn Sie nicht möchten, dass Unterschiede bei großen Vorhersagewerten stärker als bei kleinen Vorhersagewerten bestraft werden. Dieser Messwert reicht von null bis unendlich. Ein niedrigerer Wert gibt ein höheres Qualitätsmodell an. Der RMSLE-Bewertungsmesswert wird nur zurückgegeben, wenn alle Label- und Vorhersagewerte nicht negativ sind.
r^2Das Bestimmtheitsmaß (r^2) ist das Quadrat des Pearson-Korrelationskoeffizienten zwischen den Labels und vorhergesagten Werten. Dieser Messwert liegt zwischen null und eins. Ein höherer Wert gibt ein höheres Qualitätsmodell an.
MAPE: Der mittlere absolute prozentuale Fehler (Mean Absolute Percentage Error) ist die durchschnittliche absolute prozentuale Differenz zwischen den Labels und den vorhergesagten Werten. Dieser Messwert liegt zwischen null und unendlich. Ein niedrigerer Wert gibt ein höheres Qualitätsmodell an.
MAPE wird nicht angezeigt, wenn die Zielspalte Nullwerte enthält. In diesem Fall ist MAPE nicht definiert.
Merkmalwichtigkeit: AutoML Tables gibt an, wie stark sich jedes Merkmal auf dieses Modell auswirkt. Sie wird in der Grafik Merkmalwichtigkeit angezeigt. Die Werte werden für jedes Merkmal als Prozentsatz angegeben. Je höher der Prozentsatz, desto stärker hat sich das Merkmal auf das Modelltraining ausgewirkt.
Sie sollten diese Informationen lesen, um sicherzustellen, dass alle wichtigen Merkmale für Ihre Daten- und Geschäftsprobleme sinnvoll sind. Weitere Informationen zur Erklärbarkeit
Bewertungsmesswerte für das Modell abrufen
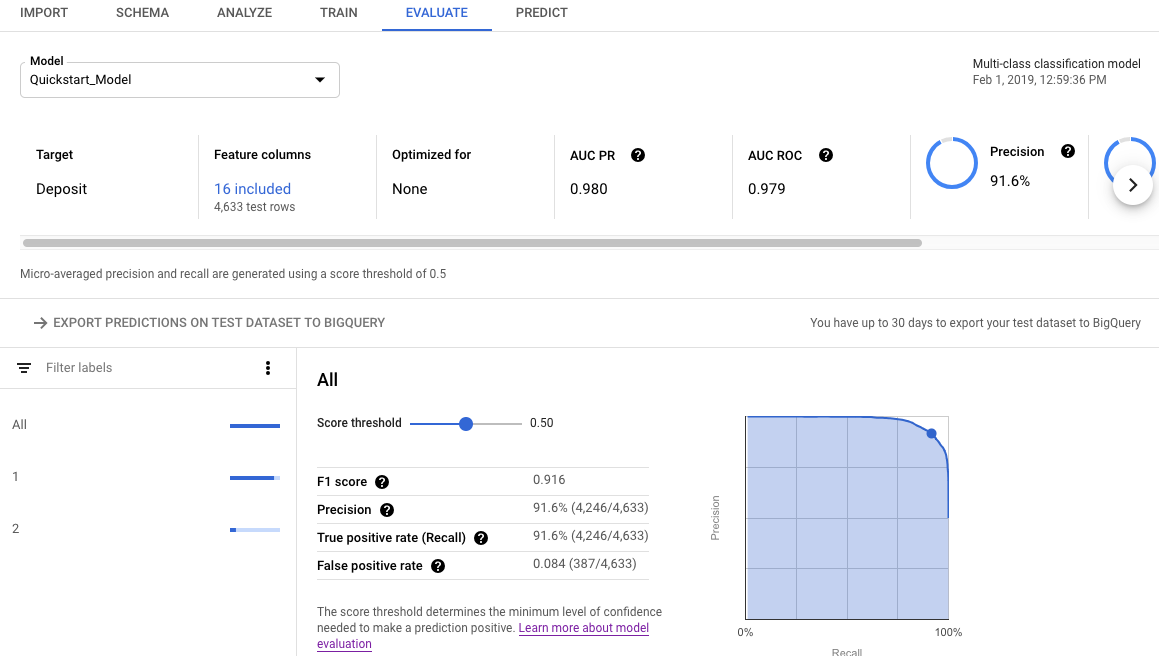
Anhand der Bewertungsmesswerte des Modells können Sie bewerten, wie gut es mit dem Test-Dataset abgeschnitten hat.
Console
So rufen Sie die Bewertungsmesswerte Ihres Modells über die Google Cloud Console auf:
Rufen Sie in der Google Cloud Console die Seite „AutoML Tables“ auf.
Wählen Sie im linken Navigationsbereich den Tab Model (Modell) aus und klicken Sie auf das Modell, für das die Bewertungsmesswerte abgerufen werden sollen.
Öffnen Sie den Tab Evaluate (Bewerten).
Die zusammengefassten Bewertungsmesswerte werden oben auf dem Bildschirm angezeigt. Bei binären Klassifizierungsmodellen sind die zusammengefassten Messwerte die Messwerte der Minderheitsklasse. Bei Klassifizierungsmodellen mit mehreren Klassen sind die zusammengefassten Messwerte die Micro-Averaging-Messwerte.
Bei Klassifizierungsmesswerten können Sie auf einzelne Zielwerte klicken, um die Messwerte für diesen Wert aufzurufen.
REST
Mit der modelEvaluations.list-Methode erhalten Sie Bewertungsmesswerte für Ihr Modell mithilfe der Cloud AutoML API.
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. -
model-id: Die ID des Modells, das Sie bewerten möchten. Beispiel:
TBL543.
HTTP-Methode und URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
Senden Sie die Anfrage mithilfe einer der folgenden Optionen:
curl
Führen Sie folgenden Befehl aus:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
Führen Sie folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Node.js
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Python
Die Clientbibliothek für AutoML Tables enthält zusätzliche Python-Methoden, die die Verwendung der AutoML Tables API vereinfachen. Diese Methoden verweisen auf Datasets und Modelle anhand des Namens und nicht der ID. Dataset- und Modellnamen dürfen nur einmal vorkommen. Weitere Informationen finden Sie in der Kundenreferenz.
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Bewertungsergebnisse mit der API verstehen
Wenn Sie die Cloud AutoML API zum Abrufen von Messwerten für die Modellbewertung verwenden, wird eine große Menge an Informationen zurückgegeben. Wenn Sie wissen, wie die Messwerte strukturiert sind, können Sie die Ergebnisse interpretieren und verwenden, um Ihr Modell zu bewerten.
Klassifizierungsergebnisse
Bei einem Klassifizierungsmodell enthalten die Ergebnisse mehrere ModelEvaluation-Objekte, von denen jedes mehrere ConfidenceMetricsEntry-Objekte enthält. Kenntnisse über die Strukturierung der Ergebnisse helfen Ihnen, die richtigen Objekte für die Bewertung Ihres Modells auswählen.
Für jeden unterschiedlichen Wert der Zielspalte in den Trainingsdaten werden zwei ModelEvaluation-Objekte zurückgegeben. Darüber hinaus gibt es zwei zusammengefasste ModelEvaluation-Objekte und ein leeres ModelEvaluation-Objekt, das ignoriert werden kann.
Die beiden ModelEvaluation-Objekte, die für einen bestimmten Labelwert zurückgegeben werden, zeigen den Labelwert im Feld displayName an. Sie verwenden jeweils unterschiedliche Positionsschwellenwerte: eins und MAX_INT (die höchstmögliche Anzahl). Der Positionsschwellenwert bestimmt, wie viele Ergebnisse für eine Vorhersage berücksichtigt werden.
Bei einem Klassifizierungsproblem ist es oft am sinnvollsten, einen Positionsschwellenwert von 1 zu verwenden, da für jede Eingabe nur ein Label ausgewählt ist. Bei Problemen mit mehreren Labels kann mehr als ein Label pro Eingabe ausgewählt werden. Die Evaluationsmesswerte, die für den Positionsschwellenwert von MAX_INT zurückgegeben werden, können also nützlicher sein. Sie sollten anhand des spezifischen Anwendungsfalls Ihres Modells entscheiden, welche Messwerte verwendet werden sollen.
Die beiden zusammengefassten ModelEvaluation-Objekte enthalten das Feld displayName nur im Rahmen der Wahrheitsmatrix. Außerdem ist der Wert für das Feld evaluatedExampleCount die Gesamtanzahl der Zeilen in den Trainingsdaten.
Für Klassifizierungsmodelle mit mehreren Klassen stellen die zusammengefasssten Objekte die Micro-Averaging-Messwerte anhand aller Messwerte pro Label bereit.
Bei binären Klassifizierungsmodellen werden die Messwerte für die Minderheitsklasse als zusammengefasste Messwerte verwendet. Verwenden Sie das ModelEvaluation-Objekt mit einem Positionsschwellenwert von 1 für die zusammengefassten Messwerte.
Jedes ModelEvaluation-Objekt enthält abhängig von den Trainingsdaten bis zu 100 ConfidenceMetricsEntry-Objekte. Jedes ConfidenceMetricsEntry-Objekt stellt einen anderen Wert für den Konfidenzschwellenwert bereit, der auch als Punktzahlschwellenwert bezeichnet wird.
Zusammengefasste ModelEvaluation-Objekte sehen ähnlich aus wie im folgenden Beispiel. Beachten Sie, dass die Anzeigereihenfolge der Felder abweichen kann.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
Label-spezifische ModelEvaluation-Objekte sehen ähnlich aus wie im folgenden Beispiel. Beachten Sie, dass die Anzeigereihenfolge der Felder abweichen kann.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
Regressionsergebnisse
Die Ausgabe für ein Regressionsmodell sollte in etwa so aussehen:
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
Modellprobleme beheben
Die Messwerte für die Modellbewertung sollten gut, aber nicht perfekt sein. Sowohl eine schlechte Modellleistung als auch eine perfekte Modellleistung sind Anzeichen dafür, dass beim Training ein Problem aufgetreten ist.
Schlechte Leistung
Wenn das Modell nicht die gewünschte Leistung erbringt, können Sie Folgendes versuchen:
Überprüfen Sie das Schema.
Achten Sie darauf, dass alle Spalten den richtigen Typ haben. Außerdem sollten alle nicht vorhersagbaren Spalten, wie etwa ID-Spalten, ausgeschlossen sein.
Überprüfen Sie die Daten.
Wenn in Spalten, die keine Nullwerte zulassen, Werte fehlen, wird die jeweilige Zeile ignoriert. Achten Sie darauf, dass die Daten nicht zu viele Fehler enthalten.
Exportieren und untersuchen Sie das Test-Dataset.
Überprüfen Sie die Daten und ermitteln Sie, wann das Modell falsche Vorhersagen macht. Möglicherweise benötigen Sie für ein bestimmtes Ergebnis mehr Trainingsdaten oder die Trainingsdaten führen zu Datenlecks.
Erhöhen Sie die Menge der Trainingsdaten.
Bei einer zu geringen Menge von Trainingsdaten leidet die Modellqualität. Achten Sie darauf, dass die Trainingsdaten möglichst unverzerrt sind.
Verlängern Sie die Trainingszeit.
Wenn die Trainingszeit kurz war, erhalten Sie möglicherweise ein hochwertigeres Modell, wenn Sie den Zeitraum für das Training verlängern.
Perfekte Leistung
Wenn das Modell nahezu perfekte Bewertungsmesswerte liefert, stimmt möglicherweise etwas mit den Trainingsdaten nicht. Achten Sie unter anderem auf Folgendes:
Datenleck
Datenlecks treten auf, wenn die Trainingsdaten ein Merkmal enthalten, das während des Trainings nicht bekannt ist und auf dem Ergebnis basiert. Nehmen wir beispielsweise an, Sie trainieren ein Modell, mit dem ermittelt werden soll, ob ein erstmaliger Nutzer etwas kaufen würde. Wenn Sie einen Wert für Vielkäufer einbeziehen, hat das Modell sehr hohe Bewertungsmesswerte, funktioniert aber schlecht mit echten Daten, da der Wert für Vielkäufer nicht einbezogen werden kann.
Prüfen Sie das Diagramm Merkmalwichtigkeit auf dem Tab Evaluate (Bewerten) auf Datenlecks. Achten Sie darauf, dass die Spalten mit hoher Wichtigkeit wirklich aussagekräftig sind und nicht zu Datenlecks führen.
Zeitspalte
Wenn die Zeit der Daten von Bedeutung ist, sollten Sie unbedingt eine Zeitspalte einfügen oder die Daten manuell zeitlich aufteilen. Andernfalls erhalten Sie möglicherweise verzerrte Bewertungsmesswerte. Weitere Informationen
Test-Dataset in BigQuery herunterladen
Sie können das Test-Dataset einschließlich der Zielspalte zusammen mit dem Ergebnis des Modells für jede Zeile herunterladen. Die vom Modell falsch verwendeten Zeilen können Hinweise zur Verbesserung des Modells geben.
Öffnen Sie AutoML Tables in der Google Cloud Console.
Wählen Sie im linken Navigationsbereich Models (Modelle) aus und klicken Sie auf Ihr Modell.
Öffnen Sie den Tab Evaluate (Bewerten) und klicken Sie auf Export predictions on test dataset to BigQuery (Vorhersagen für ein Test-Dataset nach BigQuery exportieren).
Klicken Sie nach Abschluss des Exports auf View your evaluation results in BigQuery (Bewertungsergebnisse in BigQuery aufrufen), um die Daten anzusehen.