Cette page décrit comment utiliser les métriques d'évaluation pour votre modèle une fois celui-ci entraîné, ainsi que certaines recommandations de base permettant d'améliorer ses performances.
Présentation
Après avoir entraîné un modèle, AutoML Tables utilise l'ensemble de données de test pour évaluer la qualité et la précision du nouveau modèle. Il fournit également un ensemble agrégé de métriques d'évaluation indiquant le niveau de performance du modèle sur l'ensemble de données de test.
L'utilisation des métriques d'évaluation pour déterminer la qualité du modèle dépend des besoins de votre entreprise et du problème que votre modèle est entraîné à résoudre. Par exemple, le coût des faux positifs peut être supérieur à celui des faux négatifs, et inversement. Pour les modèles de régression, le différentiel entre la prédiction et la réponse correcte est-il important ou pas ? Ce genre de questions a une incidence sur la manière dont vous allez analyser les métriques d’évaluation de votre modèle.
Si vous avez inclus une colonne de pondération dans vos données d'entraînement, les métriques d'évaluation n'en seront pas affectées. Les pondérations ne sont prises en compte que pendant la phase d'entraînement.
Métriques d'évaluation pour les modèles de classification
Les modèles de classification fournissent les métriques suivantes :
AUC PR : aire sous la courbe de précision/rappel (PR). Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
AUC ROC : aire sous la courbe ROC (Receiver Operating Characteristic). Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
Justesse : fraction des prédictions de classification produites par le modèle qui étaient correctes.
Perte logistique : entropie croisée entre les prédictions du modèle et les valeurs cibles. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité.
Score F1 : moyenne harmonique de précision et du rappel. F1 est une métrique utile si vous souhaitez équilibrer précision et rappel, et que les classes sont réparties de façon inégale.
Précision : fraction des prédictions positives produites par le modèle qui étaient correctes. (Les prédictions positives correspondent à la combinaison des faux positifs et des vrais positifs.)
Rappel : fraction des lignes comportant cette étiquette que le modèle a correctement prédites. Également appelé "taux de vrais positifs".
Taux de faux positifs : fraction de lignes prédites par le modèle comme étiquette cible, mais qui ne le sont pas (faux positifs).
Ces métriques s'affichent pour chaque valeur distincte de la colonne cible. Pour les modèles de classification à classes multiples, ces métriques sont des micro-moyennes et s'affichent sous forme de métriques récapitulatives. Pour les modèles de classification binaire, les métriques de la classe minoritaire sont utilisées comme métriques récapitulatives. Les valeurs de micro-moyenne représentent la valeur attendue de chaque métrique sur un échantillon aléatoire de votre ensemble de données.
Outre les métriques ci-dessus, AutoML Tables propose deux autres méthodes pour comprendre votre modèle de classification : la matrice de confusion et un graphique d'importance des caractéristiques.
Matrice de confusion: la matrice de confusion vous aide à comprendre l'origine des classifications erronées (quelles classes ont été confondues avec une autre). Chaque ligne représente la vérité terrain pour une étiquette spécifique, et chaque colonne affiche les étiquettes prédites par le modèle.
Les matrices de confusion ne sont fournies que pour les modèles de classification dont la colonne cible contient 10 valeurs ou moins.

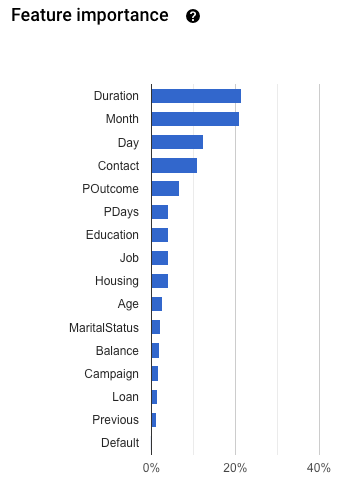
Importance des caractéristiques : AutoML Tables vous indique l'impact de chaque caractéristique sur ce modèle. Elle est indiquée dans le graphique Importance des caractéristiques. Les valeurs sont fournies sous la forme d'un pourcentage pour chaque caractéristique : plus le pourcentage est élevé, plus il est probable que cette caractéristique ait affecté l'entraînement du modèle.
Consultez ces informations pour vous assurer que toutes les caractéristiques les plus importantes sont significatives pour vos données et votre problématique métier. En savoir plus sur l'explicabilité.
Calcul de la micro-moyenne de la précision
La micro-moyenne de la précision est calculée en additionnant le nombre de vrais positifs (TP) pour chaque valeur potentielle de la colonne cible, puis en divisant le nombre obtenu par le nombre de vrais positifs (TP) et de vrais négatifs (TN).
\[ precision_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
Où :
- \(TP_1 + \ ldots + TP_n \) est la somme des vrais positifs pour chacune des n classes.
- \(FP_1 + \ ldots + FP_n \) est la somme des faux positifs pour chacune des n classes
Seuil de score
Le seuil de score est un nombre compris entre 0 et 1. Il permet de spécifier le niveau de confiance minimal selon lequel une valeur de prédiction donnée doit être considérée comme vraie. Par exemple, si vous avez une classe dont il est peu probable qu'elle représente la valeur réelle, il est conseillé d'en abaisser le seuil. En effet, avec un seuil de 0,5 ou plus, cette classe ne fera quasiment jamais l'objet de prédictions.
Un seuil plus élevé diminue les faux positifs mais augmente le nombre de faux négatifs. Un seuil plus bas diminue les faux négatifs mais augmente le nombre de faux positifs.
Autrement dit, le seuil de score affecte la précision et le rappel. Un seuil plus élevé augmente la précision (car le modèle n'effectue jamais de prédiction à moins d'être quasiment sûr), mais le rappel (le pourcentage d'exemples positifs prédits correctement par le modèle) diminue.
Métriques d'évaluation pour les modèles de régression
Les modèles de régression fournissent les métriques suivantes :
EAM : l'erreur absolue moyenne (EAM) représente l'écart absolu moyen entre les valeurs cibles et les valeurs prédites. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité.
RMSE : la racine carrée de l'erreur quadratique moyenne est couramment utilisée pour mesurer les écarts entre les valeurs prédites par un modèle ou un Estimator et les valeurs observées. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité.
RMSLE : la racine carrée de l'erreur logarithmique quadratique moyenne est semblable à la RMSE, à ceci près qu'elle utilise le logarithme naturel des valeurs prédictives et réelles plus 1. La RMSLE pénalise davantage la sous-prédiction que la sur-prédiction. Cette métrique est également utile si vous ne souhaitez pas pénaliser plus fortement les différences dans les grandes valeurs de prédiction par rapport aux valeurs plus petites. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité. La métrique d'évaluation RMSLE ne s'affiche que si toutes les valeurs et étiquettes de prédiction sont non négatives.
r^2: r-carré (r^2) correspond au carré du coefficient de corrélation de Pearson entre les étiquettes et les valeurs prédites. Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
EAMP : l'erreur absolue moyenne en pourcentage (EAMP) représente l'écart absolu moyen en pourcentage entre les étiquettes et les valeurs prédites. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité.
L'EAMP ne s'affiche pas si la colonne cible contient des valeurs nulles. Dans ce cas, l'EAMP n'est pas définie.
Importance des caractéristiques : AutoML Tables vous indique l'impact de chaque caractéristique sur ce modèle. Elle est indiquée dans le graphique Importance des caractéristiques. Les valeurs sont fournies sous la forme d'un pourcentage pour chaque caractéristique : plus le pourcentage est élevé, plus il est probable que cette caractéristique ait affecté l'entraînement du modèle.
Consultez ces informations pour vous assurer que toutes les caractéristiques les plus importantes sont significatives pour vos données et votre problématique métier. En savoir plus sur l'explicabilité.
Obtenir les métriques d'évaluation pour votre modèle
Pour évaluer les performances de votre modèle sur l'ensemble de données de test, vous inspectez les métriques d'évaluation qui lui sont associées.
Console
Pour afficher les métriques d'évaluation de votre modèle à l'aide de la console Google Cloud, procédez comme suit:
Accédez à la page "AutoML Tables" dans la console Google Cloud.
Ouvrez l'onglet Modèles dans le volet de navigation de gauche, puis sélectionnez le modèle dont vous souhaitez afficher les métriques d'évaluation.
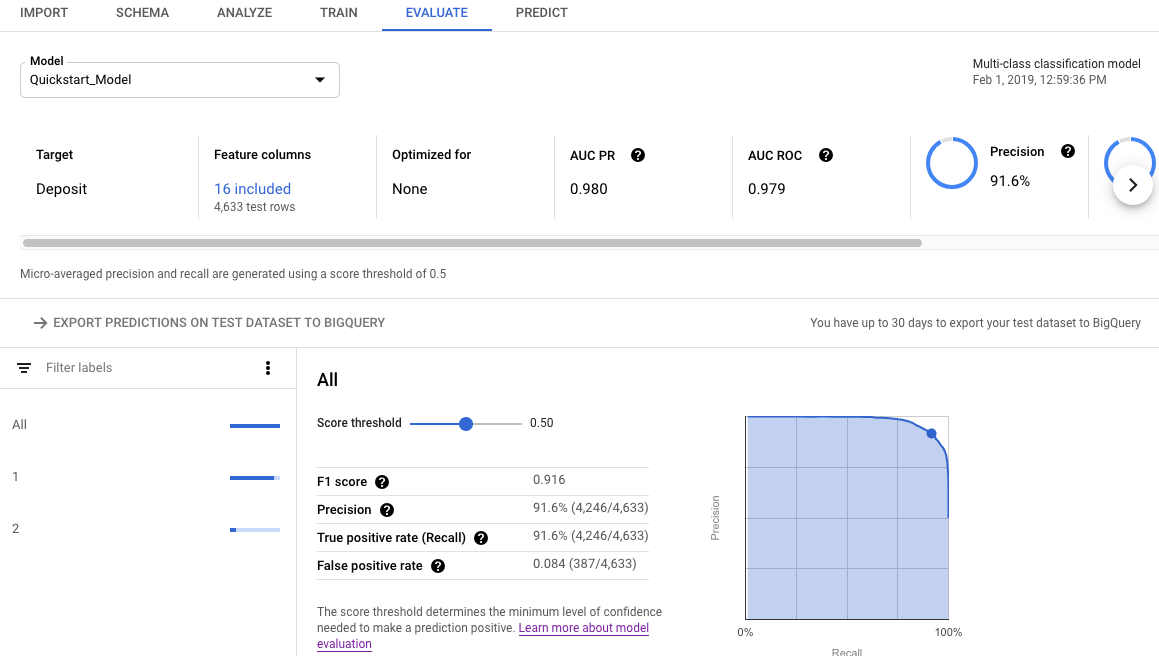
Ouvrez l'onglet Evaluate (Évaluation).
Les métriques d'évaluation récapitulatives sont affichées en haut de l'écran. Pour les modèles de classification binaire, les métriques récapitulatives représentent la classe minoritaire. Pour les modèles de classification à classes multiples, les métriques récapitulatives représentent les micro-moyennes.
Pour afficher les métriques de classification d'une valeur spécifique, cliquez sur la valeur cible correspondante.
REST
Pour obtenir les métriques d'évaluation de votre modèle à l'aide de l'API Cloud AutoML, vous devez utiliser la méthode modelEvaluations.list.
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
-
endpoint:
automl.googleapis.compour la zone internationale eteu-automl.googleapis.compour la région UE. - project-id : ID de votre projet Google Cloud.
- location : emplacement de la ressource :
us-central1pour l'emplacement mondial oueupour l'Union européenne. -
model-id : ID du modèle que vous souhaitez évaluer. Par exemple,
TBL543.
Méthode HTTP et URL :
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
exécutez la commande suivante :
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Node.js
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Python
La bibliothèque cliente AutoML Tables comprend des méthodes Python supplémentaires qui simplifient l'utilisation de l'API AutoML Tables. Ces méthodes référencent les ensembles de données et les modèles par nom et non par identifiant. L'ensemble de données et les noms de modèles doivent être uniques. Pour plus d'informations, consultez la documentation de référence du client.
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Comprendre les résultats des évaluations à l'aide de l'API
Lorsque vous utilisez l'API Cloud AutoML pour obtenir des métriques d'évaluation de modèle, une grande quantité d'informations est renvoyée. Comprendre la structure des résultats des métriques peut vous aider à interpréter ces résultats et à les utiliser pour évaluer votre modèle.
Résultats de la classification
Pour un modèle de classification, les résultats incluent plusieurs objets ModelEvaluation, chacun d'entre eux contenant différents objets ConfidenceMetricsEntry. La compréhension de la structure des résultats vous aide à choisir les objets adéquats à utiliser lors de l'évaluation de votre modèle.
Deux objets ModelEvaluation s'affichent pour chaque valeur distincte de la colonne cible présente dans les données d'entraînement. En outre, il existe deux objets ModelEvaluation récapitulatifs, et un objet ModelEvaluation vide qui peut être ignoré.
Les deux objets ModelEvaluation associés à une valeur d'étiquette spécifique affichent la valeur de celle-ci dans le champ displayName. Chacun utilise des valeurs de seuil de position différentes : un et MAX_INT (nombre le plus élevé possible). Le seuil de position détermine le nombre de résultats pris en compte pour une prédiction.
Pour un problème de classification, l'utilisation d'un seuil de position de un est souvent la
plus logique, car un seul libellé est choisi pour chaque entrée. Pour
des problèmes multi-libellés, plusieurs libellés peuvent être sélectionnés par entrée. Les
métriques d'évaluation renvoyées pour le seuil de position MAX_INT peuvent donc être plus
utiles. Vous devez déterminer les métriques à utiliser en fonction du cas d'utilisation spécifique
de votre modèle.
Les deux objets récapitulatifs ModelEvaluation n'incluent pas le champ displayName, sauf dans le cadre de la matrice de confusion. En outre, la valeur du champ evaluatedExampleCount correspond au nombre total de lignes dans les données d'entraînement.
Pour les modèles de classification à classes multiples, les objets récapitulatifs fournissent des métriques de micro-moyennes basées sur toutes les métriques par étiquette.
Pour les modèles de classification binaire, les métriques de la classe minoritaire sont utilisées en tant que métriques récapitulatives. Utilisez l'objet ModelEvaluation avec un seuil de position de un pour vos métriques récapitulatives.
Chaque objet ModelEvaluation contient jusqu'à 100 objets ConfidenceMetricsEntry, en fonction des données d'entraînement. Chaque objet ConfidenceMetricsEntry fournit une valeur de seuil de confiance différente (également appelé seuil de score).
Les objets ModelEvaluation récapitulatifs se présentent comme l'exemple ci-dessous. Notez que l'ordre d'affichage des champs peut varier.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
Les objets ModelEvaluation spécifiques à une étiquette se présentent comme ci-dessous. Notez que l'ordre d'affichage des champs peut varier.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
Résultats de la régression
Pour un modèle de régression, vous devriez obtenir un résultat semblable à l'exemple ci-dessous :
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
Résoudre les problèmes liés au modèle
Les métriques d'évaluation des modèles doivent être bonnes, mais pas parfaites. Des performances de modèle médiocres comme des performances de modèle parfaites indiquent un problème lié au processus d'entraînement.
Performances médiocres
Si votre modèle ne fonctionne pas aussi bien que vous le souhaitez, voici quelques mesures que vous pouvez appliquer :
Vérifiez votre schéma.
Vérifiez que le type de chaque colonne est correct et que vous avez exclu de l'entraînement les colonnes non prédictives, telles que les colonnes d'ID.
Examinez vos données.
Des valeurs manquantes dans les colonnes ne pouvant être vides font que cette ligne est ignorée. Assurez-vous que vos données ne comportent pas trop d'erreurs.
Exportez l'ensemble de données de test et examinez-le.
L'inspection des données et l'analyse des prédictions incorrectes du modèle permettent de déterminer que vos données d'entraînement pour un résultat particulier sont insuffisantes et qu'il vous en faut davantage, ou que des fuites de données se sont produites.
Augmentez la quantité de données d'entraînement.
Si vous ne disposez pas de données d'entraînement en quantité suffisante, la qualité du modèle en souffrira. Assurez-vous que vos données d’entraînement comportent le moins de biais possible.
Augmentez le temps d'entraînement.
Si le temps d'entraînement a été relativement bref, prolongez la durée d'entraînement pour obtenir un modèle de meilleure qualité.
Performances parfaites
Si votre modèle a renvoyé des métriques d'évaluation quasi-parfaites, il se peut que les données d'entraînement présentent un problème. Voici quelques points à vérifier :
Fuites cibles
Une fuite cible se produit lorsqu'une caractéristique incluse dans les données d'entraînement ne peut pas être connue au moment de l'entraînement, lequel est basé sur le résultat. Par exemple, si vous avez inclus une valeur "Acheteur fréquent" pour un modèle entraîné afin de déterminer si un nouvel utilisateur effectuera un achat, ce modèle produira des métriques d’évaluation très élevées mais des résultats médiocres sur des données réelles, car cette valeur pourrait ne pas être présente.
Pour vérifier les fuites cibles, examinez le graphique Importance des caractéristiques dans l'onglet Évaluation pour votre modèle. Assurez-vous que les colonnes d'importance élevée sont réellement prédictives et ne causent pas de fuites de données concernant la cible.
Colonne Heure
Si l'heure de vos données est un facteur important, assurez-vous d'avoir utilisé une colonne Heure ou une répartition manuelle basée sur l'heure. Ne pas le faire peut fausser vos métriques d'évaluation. En savoir plus
Télécharger votre ensemble de données de test dans BigQuery
Vous pouvez télécharger votre ensemble de données de test, y compris la colonne cible, ainsi que les résultats du modèle pour chaque ligne. L'inspection des lignes sur lesquelles le modèle s'est trompé peut fournir des indices sur la façon d'améliorer le modèle.
Ouvrez AutoML Tables dans la console Google Cloud.
Cliquez sur Modèles dans le volet de navigation de gauche, puis sur votre modèle.
Ouvrez l'onglet Evaluation et cliquez sur Exporter les prédictions sur l'ensemble de données test vers BigQuery.
Une fois l'exportation terminée, cliquez sur Afficher les résultats de votre évaluation dans BigQuery pour consulter les données.
Étapes suivantes
- Déployez votre modèle pour obtenir des prédictions en ligne.
- Obtenez des prédictions par lot à partir de votre modèle.