En esta página se describe cómo usar las métricas de evaluación de tu modelo después de su entrenamiento, y se ofrecen algunas sugerencias básicas para que mejores el rendimiento del modelo.
Introducción
Después de entrenar un modelo, AutoML Tables usa el conjunto de datos de prueba para evaluar la calidad y precisión del nuevo modelo, y proporciona un conjunto agregado de métricas de evaluación que indica el rendimiento del modelo en el conjunto de datos de prueba.
El uso de las métricas de evaluación a fin de determinar la calidad de tu modelo depende de la necesidad de tu empresa y del problema que tu modelo está entrenado para resolver. Por ejemplo, podría haber un costo más alto para los falsos positivos que para los falsos negativos, o viceversa. En el caso de los modelos de regresión, ¿es importante o no el delta entre la predicción y la respuesta correcta? Este tipo de preguntas afecta la forma en la que vas a analizar las métricas de evaluación de tu modelo.
Si incluiste una columna de ponderación en tus datos de entrenamiento, no va a afectar las métricas de evaluación. Los pesos se consideran solo durante la fase de entrenamiento.
Métricas de evaluación para modelos de clasificación
Los modelos de clasificación proporcionan las siguientes métricas:
AUC PR: El área bajo la curva de precisión y recuperación (PR). Esta medida puede variar de cero a uno, y cuanto más alto sea su valor, mejor será la calidad del modelo.
AUC ROC: El área bajo la curva de característica operativa del receptor (ROC). Esta puede variar de cero a uno y cuanto más alto sea su valor, mejor será la calidad del modelo.
Exactitud: La fracción de predicciones de clasificación correctas que produjo el modelo.
Pérdida logística: La entropía cruzada entre las predicciones del modelo y los valores objetivo. Esta medida puede variar de cero a infinito, y cuanto más bajo sea su valor, mejor será la calidad del modelo.
Puntuación F1: La media armónica de precisión y recuperación. F1 es una métrica útil si lo que buscas es un equilibrio entre la precisión y la recuperación, y tienes una distribución de clases despareja.
Precisión: La fracción de predicciones positivas de clasificación correctas que produjo el modelo. (Las predicciones positivas son los falsos positivos y los verdaderos positivos combinados).
Recuperación: La fracción de filas con esta etiqueta que el modelo predijo de forma correcta. También se denomina “tasa de verdaderos positivos”.
Tasa de falsos positivos: La fracción de filas que, según la predicción del modelo, corresponden a la etiqueta objetivo, pero en realidad no pertenecen a esta (falso positivo).
Estas métricas se muestran para cada valor distinto de la columna objetivo. Para los modelos de clasificación de clases múltiples, estas métricas se micropromedian y se muestran como métricas de resumen. En el caso de los modelos de clasificación binaria, las métricas de la clase minoritaria se usan como métricas de resumen. Las métricas que se micropromedian son el valor esperado de cada métrica en una muestra aleatoria de tu conjunto de datos.
Además de las métricas anteriores, AutoML Tables ofrece otras dos formas de comprender tu modelo de clasificación: la matriz de confusión y un gráfico de importancia de los atributos.
Matriz de confusión: La matriz de confusión te ayuda a comprender dónde se producen los errores de clasificación (qué clases se “confunden” con otras). Cada fila representa la verdad fundamental de una etiqueta específica, y en cada columna se muestran las etiquetas que predijo el modelo.
Las matrices de confusión solo se proporcionan para los modelos de clasificación con 10 valores o menos para la columna objetivo.

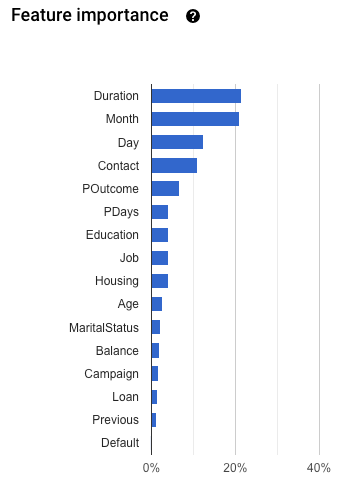
Importancia de las características: AutoML Tables te indica en que medida afecta cada atributo a este modelo. Se muestra en el gráfico Importancia de las características. Los valores se proporcionan como un porcentaje para cada característica: cuanto más alto sea el porcentaje, más fuerte será el entrenamiento del modelo.
Debes revisar esta información a fin de asegurarte de que todas las funciones más importantes tengan sentido para tus datos y tu problema empresarial. Obtén más información sobre la justificación.
Cómo se calcula la precisión micropromediada
La precisión micropromediada se calcula cuando se suman los números de verdaderos positivos (VP) de cada valor potencial de la columna objetivo y se dividen por la cantidad de verdaderos positivos (VP) y verdaderos negativos (VN) de cada valor potencial.
\[ precision_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n}\]
donde
- \(TP_1 + \ ldots + TP_n \) es la suma de los verdaderos positivos para cada una de las clases n.
- \(FP_1 + \ ldots + FP_n \) es la suma de los falsos positivos para cada una de las clases n.
Umbral de puntuación
El umbral de puntuación es un número que puede variar de 0 a 1. Proporciona una forma de especificar el nivel de confianza mínimo en el que un valor de predicción determinado debe considerarse como verdadero. Por ejemplo, si tienes una clase que es poco probable que sea el valor real, entonces deberías bajar el umbral para esa clase. Si se usa un umbral de .5 o superior, la clase se predecirá muy pocas veces (o nunca).
Con un umbral más alto, disminuyen los falsos positivos, a costa de más falsos negativos. Con un umbral más bajo, disminuyen los falsos negativos a costa de más falsos positivos.
Dicho de otra manera, el umbral de puntuación afecta la precisión y la recuperación. Un umbral más alto genera un aumento en la precisión (porque el modelo nunca hace una predicción, a menos que tenga total seguridad), pero la recuperación (el porcentaje de ejemplos positivos que el modelo obtiene) disminuye.
Métricas de evaluación para modelos de regresión
Los modelos de regresión proporcionan las siguientes métricas:
MAE: El error absoluto promedio (MAE) es la diferencia absoluta promedio entre los valores objetivo y los valores previstos. Esta métrica puede variar de cero a infinito, y cuanto más bajo sea el valor, mejor será la calidad del modelo.
RMSE: La métrica de la raíz cuadrada del error cuadrático medio mide las diferencias entre los valores previstos por un modelo o estimador y los valores observados. Esta métrica puede variar de cero a infinito, y cuanto más bajo sea el valor, mejor será la calidad del modelo.
RMSLE: La métrica del error logarítmico de la raíz cuadrada de la media es similar a RMSE, excepto que usa el logaritmo natural de los valores previstos y reales más 1. RMSLE penaliza con mayor peso la subpredicción que la sobrepredicción. También puede ser una buena métrica cuando no se desean penalizar con mayor peso las diferencias para los valores de predicciones grandes que para los valores de predicciones pequeños. Esta métrica puede variar de cero a infinito, y cuanto más bajo sea el valor, mejor será la calidad del modelo. La métrica de evaluación RMSLE se muestra solo si todos los valores previstos y las etiquetas no son negativos.
r al cuadrado (r^2) es el cuadrado del coeficiente de correlación de Pearson entre las etiquetas y los valores previstos. Esta métrica puede variar entre cero y uno, cuanto más alto sea el valor, mejor será la calidad del modelo.
MAPE: El error porcentual absoluto promedio (MAPE) es el promedio de la diferencia porcentual absoluta entre los valores previstos y las etiquetas. Esta métrica puede variar entre cero y un valor infinito; cuanto más bajo sea el valor, mejor será la calidad del modelo.
MAPE no se muestra si la columna objetivo contiene valores 0. En este caso, MAPE no está definido.
Importancia de las características: AutoML Tables te indica en que medida afecta cada atributo a este modelo. Se muestra en el gráfico Importancia de las características. Los valores se proporcionan como un porcentaje para cada característica: cuanto más alto sea el porcentaje, más fuerte será el entrenamiento del modelo.
Debes revisar esta información a fin de asegurarte de que todas las funciones más importantes tengan sentido para tus datos y tu problema empresarial. Obtén más información sobre la justificación.
Obtén las métricas de evaluación de tu modelo
Para evaluar el rendimiento de tu modelo en el conjunto de datos de prueba, inspecciona las métricas de evaluación de tu modelo.
Console
Para ver las métricas de evaluación de tu modelo con la consola de Google Cloud, sigue estos pasos:
Ve a la página AutoML Tables en la consola de Google Cloud.
Selecciona la pestaña Modelos en el panel de navegación izquierdo y selecciona el modelo del que deseas obtener las métricas de evaluación.
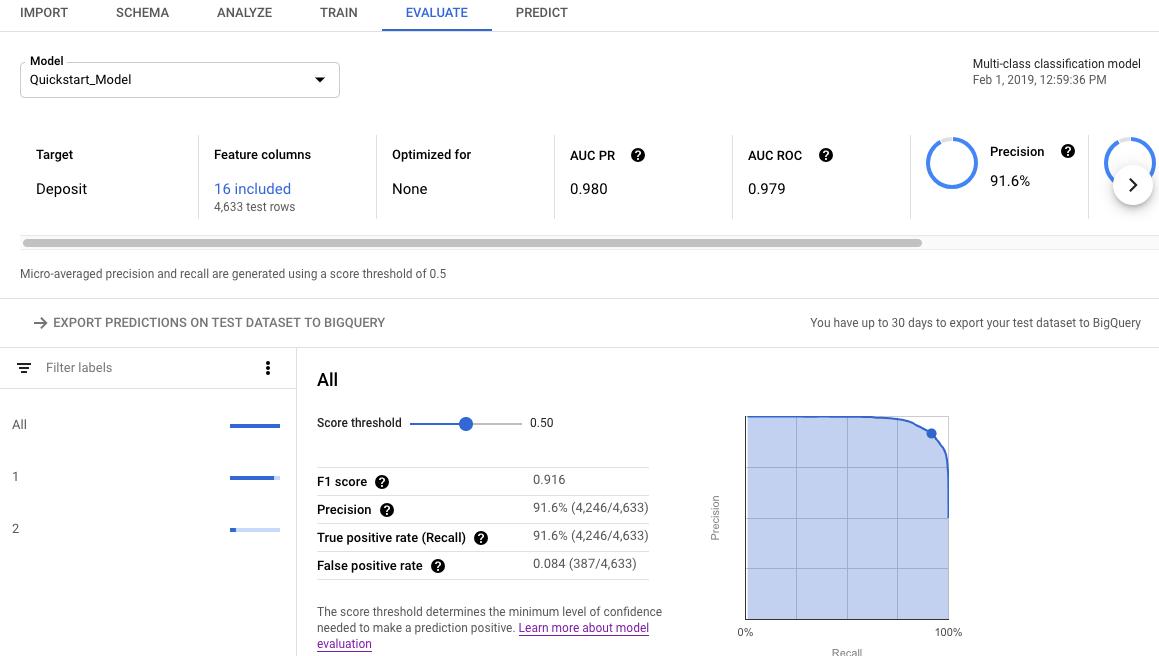
Abre la pestaña Evaluar (Evaluate).
Las métricas de evaluación de resumen se muestran en la parte superior de la pantalla. Para los modelos de clasificación binaria, las métricas de resumen son las métricas de la clase minoritaria. Para los modelos de clasificación de clases múltiples, las métricas de resumen son las métricas micropromediadas.
Para las métricas de clasificación, puedes hacer clic en los valores objetivos individuales y ver las métricas de ese valor.
REST
Para obtener las métricas de evaluación de tu modelo con la API de Cloud AutoML, usa el método modelEvaluations.list.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea -
model-id: el ID del modelo que deseas evaluar. Por ejemplo,
TBL543
HTTP method and URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
Para enviar tu solicitud, elige una de estas opciones:
curl
Ejecuta el siguiente comando:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
Ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Node.js
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Python
La biblioteca cliente de AutoML Tables incluye métodos adicionales de Python que simplifican el uso de la API de AutoML Tables. Estos métodos hacen referencia a conjuntos de datos y modelos por nombre en lugar de ID. El conjunto de datos y los nombres de los modelos deben ser únicos. Para obtener más información, consulta la página de referencia del cliente.
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Comprender los resultados de la evaluación mediante la API
Cuando usas la API de Cloud AutoML para obtener métricas de evaluación del modelo, se muestra una gran cantidad de información. Comprender cómo se estructuran los resultados de las métricas puede ayudarte a interpretar los resultados y usarlos para evaluar tu modelo.
Resultados de la clasificación
Para un modelo de clasificación, los resultados incluyen varios objetos ModelEvaluation, y cada uno contiene varios objetos ConfidenceMetricsEntry. Comprender cómo están estructurados los resultados te ayuda a elegir los objetos correctos que se van a usar para evaluar tu modelo.
Se muestran dos objetos ModelEvaluation para cada valor distinto de la columna objetivo presente en los datos de entrenamiento. Además, hay dos objetos de resumen ModelEvaluation y un objeto ModelEvaluation vacío que pueden ignorarse.
Los dos objetos ModelEvaluation que se muestran para un valor de etiqueta específico muestran el valor de la etiqueta en el campo displayName. Cada uno de ellos usa valores de umbral de posición diferentes: uno y MAX_INT (el número más alto posible). El umbral de posición determina cuántos resultados se consideran para una predicción.
En el caso de un problema de clasificación, el uso de un límite de posición de uno a menudo tiene más sentido, ya que solo hay una etiqueta elegida para cada entrada. En el caso de los problemas de varias etiquetas, se puede elegir más de una etiqueta por entrada, por lo que las métricas de evaluación que se muestran para el límite de posición MAX_INT pueden ser más útiles. Debes determinar qué métricas usar en función del caso práctico específico de tu modelo.
Los dos objetos de resumen ModelEvaluation no incluyen el campo displayName, excepto como parte de la matriz de confusión. Además, su valor para el campo evaluatedExampleCount es la cantidad total de filas en los datos de entrenamiento.
Para los modelos de clasificación de clases múltiples, los objetos de resumen proporcionan las métricas micropromediadas en función de todas las métricas por etiqueta.
En el caso de los modelos de clasificación binaria, las métricas de la clase minoritaria se usan como métricas de resumen. Usa el objeto ModelEvaluation con un umbral de posición de uno para tus métricas de resumen.
Cada objeto ModelEvaluation contiene hasta 100 objetos ConfidenceMetricsEntry, según los datos de entrenamiento. Cada objeto ConfidenceMetricsEntry proporciona un valor diferente para el umbral de confianza (también conocido como umbral de puntuación).
Los objetos de resumen ModelEvaluation tienen un aspecto similar al del siguiente ejemplo. Ten en cuenta que el orden de visualización del campo puede variar.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
Los objetos específicos de la etiqueta ModelEvaluation tienen un aspecto similar al del siguiente ejemplo. Ten en cuenta que el orden de visualización del campo puede variar.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
Resultados de la regresión
Para un modelo de regresión, deberías ver un resultado similar al siguiente ejemplo:
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
Soluciona los problemas del modelo
Las métricas de evaluación del modelo deben ser buenas, pero no perfectas. El rendimiento bajo del modelo y el rendimiento perfecto del modelo son indicios de que algo salió mal en el proceso de entrenamiento.
Rendimiento bajo
Si el rendimiento de tu modelo no es tan bueno como te gustaría, puedes probar lo siguiente:
Revisa tu esquema.
Asegúrate de que todas las columnas tengan el tipo correcto y de que excluiste del entrenamiento las columnas que no eran predictivas, como las columnas de ID.
Revisa tus datos.
Los valores faltantes en las columnas que no admiten nulos provocan que se ignore esa fila. Asegúrate de que tus datos no tengan demasiados errores.
Exporta el conjunto de datos de prueba y examínalo.
Si inspeccionas los datos y analizas cuándo el modelo realiza predicciones incorrectas, puedes determinar que necesitas más datos de entrenamiento para un resultado específico o que tus datos de entrenamiento incorporaron filtraciones.
Aumenta la cantidad de datos de entrenamiento.
Si no tienes suficientes datos de entrenamiento, la calidad del modelo se verá afectada. Asegúrate de que tus datos de entrenamiento sean lo más imparciales posible.
Aumenta el tiempo de entrenamiento.
Si tuviste un tiempo de entrenamiento corto, es posible que obtengas un modelo de mejor calidad si permites que se entrene por un período más largo.
Rendimiento perfecto
Si tu modelo mostró métricas de evaluación casi perfectas, es posible que algo esté mal con tus datos de entrenamiento. A continuación, se especifica qué deberías tener en cuenta:
Filtración de objetivos
La filtración de objetivos ocurre cuando se incluye un atributo en los datos de entrenamiento que no se puede conocer durante el entrenamiento y se basa en el resultado. Por ejemplo, si incluiste un número de comprador frecuente en un modelo entrenado para decidir si un usuario nuevo realizaría una compra, ese modelo tendría métricas de evaluación muy altas, pero tendría un rendimiento bajo en datos reales, ya que el número de comprador frecuente no se incluirá.
Para comprobar si hay filtraciones de objetivos, revisa el gráfico Importancia de los atributos en la pestaña Evaluar de tu modelo. Asegúrate de que las columnas de gran importancia sean en verdad predictivas y no filtren información sobre el objetivo.
Columna de tiempo
Si la hora de tus datos es importante, asegúrate de usar una columna de tiempo o una división manual en función del tiempo. Si no lo haces, puedes sesgar tus métricas de evaluación. Obtener más información.
Descarga tu conjunto de datos de prueba a BigQuery
Puedes descargar tu conjunto de datos de prueba, que incluye la columna objetivo, junto con el resultado del modelo para cada fila. Inspeccionar las filas en las que el modelo se equivocó puede proporcionar pistas sobre cómo mejorar el modelo.
Abre AutoML Tables en la consola de Google Cloud.
Selecciona Modelos en el panel de navegación izquierdo y haz clic en tu modelo.
Abre la pestaña Evaluar y haz clic en Exportar predicciones en el conjunto de datos de prueba a BigQuery.
Cuando se terminen de exportar los datos, haz clic en Ver los resultados de la evaluación en BigQuery para verlos.
¿Qué sigue?
- Implementa tu modelo para obtener predicciones en línea.
- Obtén predicciones por lotes de tu modelo.