はじめに
たとえば、あなたはデジタル小売店のマーケティング部門で働いているとします。あなたとチームメイトは、顧客のペルソナに基づいてカスタマイズされたメール プログラムを作成しています。すでにペルソナを作成し、マーケティング メールは送信できる状態にあります。次に作る必要があるのは、顧客の新旧を問わず、顧客を小売店の好みや消費行動に基づいて各ペルソナに振り分けるシステムです。また、顧客の消費習慣を予測してメールを送信するタイミングを最適化し、エンゲージメントを最大化できるようにすることも必要です。
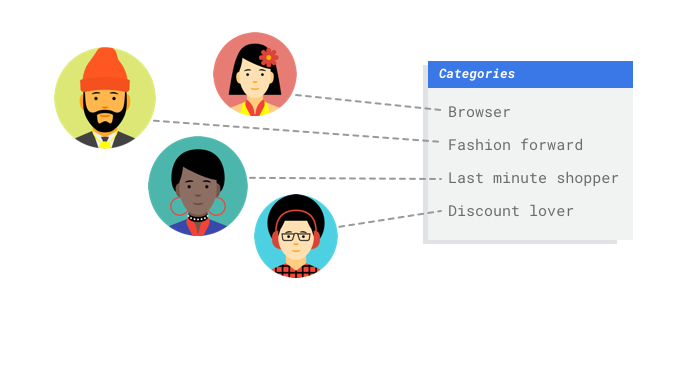
デジタル小売店であれば、顧客とその購入情報に関するデータは持っています。しかし、新しい顧客についてはどうでしょうか。従来の方法では、購入履歴が長い既存顧客であればこうした値を計算できますが、履歴データが少ない顧客の場合はうまくいきません。これらの値を予測するシステムを作ることができ、個人の好みに合ったマーケティング プログラムを迅速に顧客に提供できるとしたらどうでしょうか。
こうした問題の解決にうってつけなのが機械学習と AutoML Tables です。このガイドでは、AutoML Tables の仕組みと、AutoML Tables で解決できる問題のタイプについて説明します。
AutoML Tables の仕組み
 AutoML Tables とは、教師付きの学習サービスです。これは、ユーザーがサンプルデータを使用して機械学習モデルをトレーニングすることを意味します。AutoML Tables は表形式(構造化)データを使用して、機械学習モデルが新しいデータについて予測を行うようトレーニングします。データセット内の列の 1 つはターゲットと呼ばれ、モデルはそれを学習して予測します。他のデータ列の一部は入力(特徴と呼ばれる)であり、モデルはそこからパターンを学習します。同じ入力特徴を使用すれば、ターゲットを変更するだけで、複数の種類のモデルを構築できます。このメール マーケティングの例では、同じ入力特徴で 2 つのモデルを構築できることを意味します。1 つのモデルは顧客のペルソナ(カテゴリ型のターゲット)を予測でき、もう 1 つは顧客の毎月の支出(数値型のターゲット)を予測できます。
AutoML Tables とは、教師付きの学習サービスです。これは、ユーザーがサンプルデータを使用して機械学習モデルをトレーニングすることを意味します。AutoML Tables は表形式(構造化)データを使用して、機械学習モデルが新しいデータについて予測を行うようトレーニングします。データセット内の列の 1 つはターゲットと呼ばれ、モデルはそれを学習して予測します。他のデータ列の一部は入力(特徴と呼ばれる)であり、モデルはそこからパターンを学習します。同じ入力特徴を使用すれば、ターゲットを変更するだけで、複数の種類のモデルを構築できます。このメール マーケティングの例では、同じ入力特徴で 2 つのモデルを構築できることを意味します。1 つのモデルは顧客のペルソナ(カテゴリ型のターゲット)を予測でき、もう 1 つは顧客の毎月の支出(数値型のターゲット)を予測できます。
AutoML Tables のワークフロー
AutoML Tables は、標準の機械学習ワークフローを使用します。
- データの収集: 達成したい結果に向けて、モデルのトレーニング用データとテスト用データを選定します。
- データの準備: データが正しい形式であることを、データ インポートの前後に確認します。
- トレーニング: パラメータを設定してモデルを構築します。
- 評価: モデルの指標を確認します。
- テスト: モデルをテストデータで試します。
- デプロイと予測: モデルを利用できるようにします。
ただし、実際にデータを収集する前に、解決しようとしている問題について検討し、データの要件を把握しておく必要があります。
ユースケースの検討

まずは問題に目を向けて、達成する必要のある結果を考えてください。ターゲット列はどのような種類のデータですか。アクセスできるデータはどのくらいありますか。
AutoML Tables はこれらの答えに応じて、ユーザーのユースケースを解決するために必要なモデルを作成します。
バイナリ分類モデルは、2 択の結果(2 つのクラスのうちのいずれか)を予測します。これは、顧客がサブスクリプションを購入するかしないかの予測など、「はい」または「いいえ」の質問に使用します。他の条件がすべて同じである場合、バイナリ分類の問題は他のモデルタイプより必要とするデータが少なくなります。
マルチクラス分類モデルは、1 つのクラスを 3 つ以上の離散クラスから予測します。これは、ものごとを分類するために使用します。上記の小売店の例では、顧客をさまざまなペルソナに分割するためのマルチクラス分類モデルを構築できます。
回帰モデルは連続値を予測します。上記の小売店の例では、今後 1 か月の顧客の消費を予測するための回帰モデルを構築することもできます。
AutoML Tables は、ターゲット列のデータ型に基づいて、問題と構築すべきモデルを自動的に定義します。そのため、ターゲット列に数値データが含まれている場合、AutoML Tables は回帰モデルを構築します。ターゲット列がカテゴリデータの場合、AutoML Tables はクラスの数を検知して、バイナリモデルを構築すべきかマルチクラス モデルを構築すべきかを判定します。
公平性に関する注記
公平性は、Google の責任ある AI への取り組みの 1 つとなっています。公平性の目的とは、過去に差別や過小評価の対象になった人種、収入、性的志向、宗教、性別などの特性を理解し、そのような特性がアルゴリズム システムやアルゴリズムによる意思決定に現れる場合に、不公平で偏見的な扱いを防止することです。このガイドには、より公平な機械学習モデルの作成方法について詳しく説明する、「公平性の認識」という注記を記載しています。詳細
データの収集
 ユースケースを確立したら、モデルをトレーニングするためのデータを収集する必要があります。データの調達と準備は、機械学習モデルを構築するうえで重要なステップです。使用できるデータによって、解決できる問題のタイプがわかります。使用できるデータはどれくらいありますか?それらのデータは、答えようとしている質問に関連していますか?データを収集する際は、以下の重要事項を心に留めておいてください。
ユースケースを確立したら、モデルをトレーニングするためのデータを収集する必要があります。データの調達と準備は、機械学習モデルを構築するうえで重要なステップです。使用できるデータによって、解決できる問題のタイプがわかります。使用できるデータはどれくらいありますか?それらのデータは、答えようとしている質問に関連していますか?データを収集する際は、以下の重要事項を心に留めておいてください。
関連する特徴を選択する
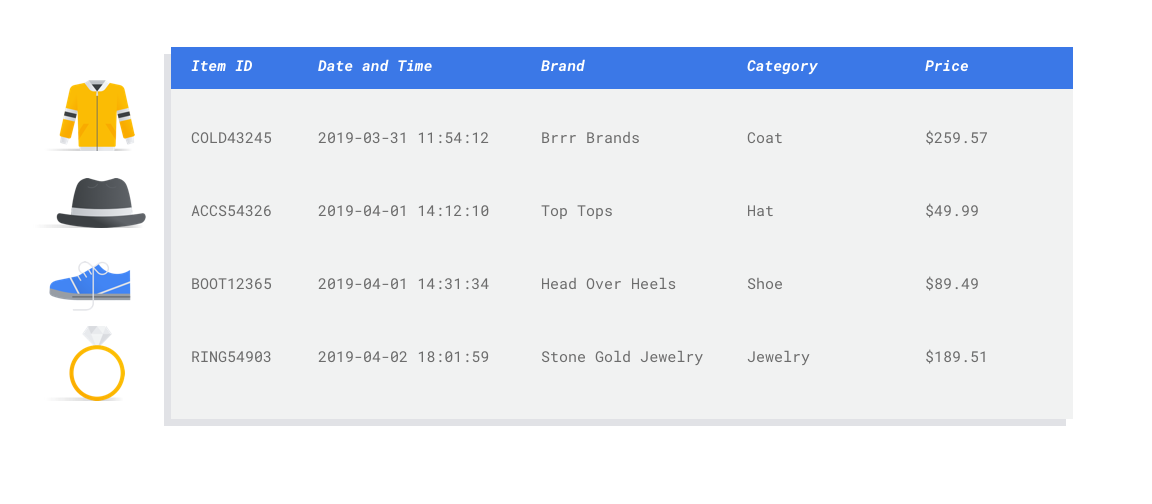
特徴は、モデルのトレーニングに使用される入力属性です。特徴とは、モデルがパターンを特定して予測を行う方法であるため、問題に関連している必要があります。たとえば、クレジット カード取引が不正であるかどうかを予測するモデルを構築するには、購入者、販売者、金額、日時、購入した商品などの取引詳細を含むデータセットを構築する必要があります。その他に役立つ特徴として、購入者と販売者に関する過去の情報、購入された商品がどのくらいの頻度で不正行為に関わっていたかなどが挙げられます。他にはどのような特徴が関連している可能性があるでしょうか。
冒頭の小売店のメール マーケティングのユースケースを考えてみましょう。必要となる特徴の列の例を以下に示します。
- 購入された商品のリスト(ブランド、カテゴリ、価格、割引など)
- 購入された商品の数(最終日、週、月、年)
- 消費された金額(最終日、週、月、年)
- 既知の買い物客層
十分なデータを含める
 一般的に、トレーニングの例が多ければ多いほど、成果は上がります。必要なサンプルデータの量は、解決しようとしている問題の複雑さにも比例します。正確なバイナリ分類モデルを取得するために必要なデータは、マルチクラス モデルと比較するとそれほど多くはありません。1 つのクラスを 2 つのクラスから予測するのは、多数から予測するほど複雑でないからです。
一般的に、トレーニングの例が多ければ多いほど、成果は上がります。必要なサンプルデータの量は、解決しようとしている問題の複雑さにも比例します。正確なバイナリ分類モデルを取得するために必要なデータは、マルチクラス モデルと比較するとそれほど多くはありません。1 つのクラスを 2 つのクラスから予測するのは、多数から予測するほど複雑でないからです。
完璧な数式はありませんが、推奨されるサンプルデータの最低行数は次のとおりです。
- 分類問題: 特徴数 × 50
- 回帰問題: 特徴数 × 200
バリエーションを考慮する
データセットには、問題空間に多様性を持たせてください。モデルのトレーニングで使用するサンプルが多様であればあるほど、目新しいサンプルや一般的ではないサンプルにも対応できる汎用化されたモデルが実現されます。小売店のモデルが、冬季の購入データだけを使ってトレーニングされた場合を想像してみましょう。夏服の嗜好や購入行動をうまく予測することができるでしょうか。
データの準備

利用可能なデータが見つかったら、トレーニングの準備ができていることを確認する必要があります。データに偏りがある場合、または欠損値やエラー値が含まれている場合、モデルはトレーニングでそれらを反映します。モデルのトレーニングを始める前に、次のことを考慮してください。詳細
データの漏出とトレーニング / サービング スキューを防ぐ
データの漏出とは、トレーニング時に入力特徴を使用した際に、予測しようとしているターゲットに関する情報、つまり実際にモデルを使用する際には把握できない情報を「漏出」させることです。これは、ターゲット列との相関性が高い特徴が入力特徴の 1 つとして含まれているときに検出できます。たとえば、顧客が来月にかけてサブスクリプションに申し込むかどうかを予測するモデルを構築しているとします。そして入力特徴の 1 つが、その顧客からの将来のサブスクリプションの支払いであったとします。この場合、テスト時のモデル パフォーマンスは強力になるかもしれませんが、本番環境でデプロイされたときはそうなりません。なぜなら将来のサブスクリプションの支払い情報はサービス提供時に存在しないからです。
トレーニング / サービング スキューとは、トレーニング時に使用される入力特徴が、サービス提供時にモデルに提供される特徴と異なるため、本番環境でモデル品質低下が生じる状態を指します。たとえば、毎時の気温を予測するモデルを構築する際に、一週間ごとの気温のみが含まれるデータを使ってトレーニングした場合です。別の例としては、学生の落第を予測する際に、トレーニング データには学生の成績が常に提供されているが、サービス提供時にはこの情報が提供されない場合です。
トレーニング データを把握することは、データの漏出やトレーニング / サービング スキューを防ぐために重要です。
- データを使用する前に、そのデータが何を意味するか、そのデータを特徴として使用するべきかどうかを必ず把握しておいてください。
- 相関関係を [トレーニング] タブで確認します。相関関係が高い場合は、フラグを付けて見直せるようにしてください。
- トレーニング / サービング スキュー: サービス提供時にまったく同じ形式で使用できる入力特徴だけをモデルに提供するようにしてください。
欠落データ、不完全データ、矛盾するデータをクリーンアップする
サンプルデータの値が欠落していたり正確でないことがよくあります。トレーニングに使用する前に時間をとって見直し、可能であればデータ品質を向上させてください。欠落している値が多いほど、データが機械学習モデルのトレーニングに役立つ度合いが減ってしまいます。
データに欠損値がないか確認し、可能であれば修正するか、列が null 可能に設定されている場合は、値を空白にします。AutoML Tables は欠損値を処理できますが、すべての値を使用できる場合は最適な結果が得られる可能性が高くなります。
データのエラーやノイズを修正または削除して、データをクリーニングします。一貫性のあるデータにするために、スペル、略語、形式を確認します。
データをインポート後に分析する
AutoML Tables には、データセットをインポートした後に概要が表示されます。インポートしたデータセットをレビューして、各列の変数型が正しいことを確認してください。AutoML Tables は列の値に基づいて変数型を自動的に検出しますが、それぞれ確認することをおすすめします。さらに、null 値許容も確認する必要があります。これによって、列で値の欠落が許容されるか、null 値が必要かが決まります。
モデルのトレーニング
データセットをインポートしたら、次のステップはモデルをトレーニングすることです。AutoML Tables は、トレーニング用のデフォルト値を使用して信頼性の高い機械学習モデルを作成しますが、ユースケースに基づいて一部のパラメータを調整することをおすすめします。
できるだけ多くの特徴列をトレーニングで選択するようにしてください。ただし、それぞれをレビューして、トレーニングに適していることを確認してください。特徴の選択に関しては、以下の事項に留意してください。
- 各行に一意の値を持つランダムに割り当てられた ID 列のように、ノイズを発生させる特徴列を選択しないでください。
- 各特徴列とその値を把握しておいてください。
- 複数のモデルを 1 つのデータセットから作成する場合は、現在の予測問題の一部ではないターゲット列を削除してください。
- 公平性の原則を思い出してください。モデルのトレーニングで使用している特徴は、主流ではないグループにとって偏った、あるいは不公平な意思決定となるでしょうか。
AutoML Tables がデータセットを使用する方法
データセットは、トレーニング セット、検証セット、テストセットに分割されます。デフォルトでは、AutoML Tables はデータの 80% をトレーニングに、10% を検証に、10% をテストに使用しますが、これらの値は必要に応じて手動で編集できます。
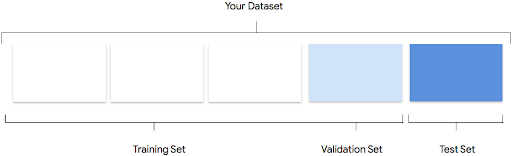
トレーニング セット
 データの大部分をトレーニング セットに含めるようにします。これはトレーニング中にモデルが「見る」データであり、モデルのパラメータ、つまりニューラル ネットワークのノード間の接続の重みを学習するために使用されます。
データの大部分をトレーニング セットに含めるようにします。これはトレーニング中にモデルが「見る」データであり、モデルのパラメータ、つまりニューラル ネットワークのノード間の接続の重みを学習するために使用されます。
検証セット
 検証セットは「dev」セットとも呼ばれ、やはりトレーニング プロセス中に使用されます。モデルの学習フレームワークは、トレーニング プロセスの各イテレーションでトレーニング データを取り込んだ後、検証セットに対するモデルのパフォーマンスに基づき、そのハイパーパラメータ(モデルの構造を指定する変数)を調整します。トレーニング セットを使用してハイパーパラメータを調整しようとすると、モデルがトレーニング データに過度に適合してしまい、正確に一致しないサンプルを一般化するのが困難になる可能性が高いです。多少違ったデータセットを使ってモデル構造を細かく調整することで、モデルがより適切に一般化されます。
検証セットは「dev」セットとも呼ばれ、やはりトレーニング プロセス中に使用されます。モデルの学習フレームワークは、トレーニング プロセスの各イテレーションでトレーニング データを取り込んだ後、検証セットに対するモデルのパフォーマンスに基づき、そのハイパーパラメータ(モデルの構造を指定する変数)を調整します。トレーニング セットを使用してハイパーパラメータを調整しようとすると、モデルがトレーニング データに過度に適合してしまい、正確に一致しないサンプルを一般化するのが困難になる可能性が高いです。多少違ったデータセットを使ってモデル構造を細かく調整することで、モデルがより適切に一般化されます。
テストセット
 テストセットはトレーニング プロセスにはまったく使用されません。モデルのトレーニングが完了したら、AutoML Tables はモデル向けのまったく新しい課題としてテストセットを使用します。テストセットに対するモデルのパフォーマンスを知ることで、モデルが実世界のデータに対してどのように機能するかをおおよそ理解できます。
テストセットはトレーニング プロセスにはまったく使用されません。モデルのトレーニングが完了したら、AutoML Tables はモデル向けのまったく新しい課題としてテストセットを使用します。テストセットに対するモデルのパフォーマンスを知ることで、モデルが実世界のデータに対してどのように機能するかをおおよそ理解できます。
モデルの評価
 モデルのトレーニングが完了すると、モデルのパフォーマンスの要約を受け取ります。概要が表示されます。モデルの評価指標は、データセット(テスト データセット)のスライスに対するモデルのパフォーマンスに基づきます。モデルが実際のデータで使用できる状態になっているかどうかを判断する際には、検討すべき主な指標とコンセプトがあります。
モデルのトレーニングが完了すると、モデルのパフォーマンスの要約を受け取ります。概要が表示されます。モデルの評価指標は、データセット(テスト データセット)のスライスに対するモデルのパフォーマンスに基づきます。モデルが実際のデータで使用できる状態になっているかどうかを判断する際には、検討すべき主な指標とコンセプトがあります。
分類指標
スコアの基準値
顧客が来年にジャケットを購入するかどうかを予測する機械学習モデルを考えてみましょう。特定の顧客がジャケットを購入することを予測する前に、このモデルにはどの程度の確実性が必要でしょうか。分類モデルでは、各予測に信頼スコア(予測クラスが正しいというモデルの確実性の数値的評価)が割り当てられます。スコアしきい値は、特定のスコアがはい / いいえの決定に変換されるときを決定する数値です。つまり、モデルが「はい、この信頼度スコアは、この顧客が来年中にコートを購入すると結論づけるのに十分な高さです」と知らせる値です。
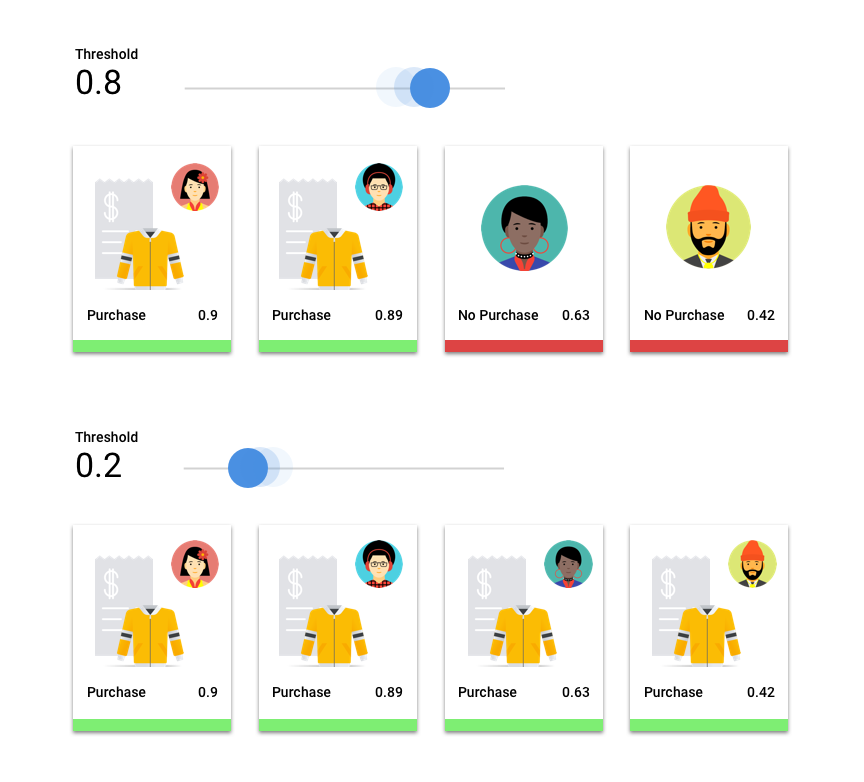
スコアしきい値が低いと、モデルが誤った分類を行うリスクがあります。このため、スコアしきい値は特定のユースケースに基づいて設定しなければなりません。
予測結果
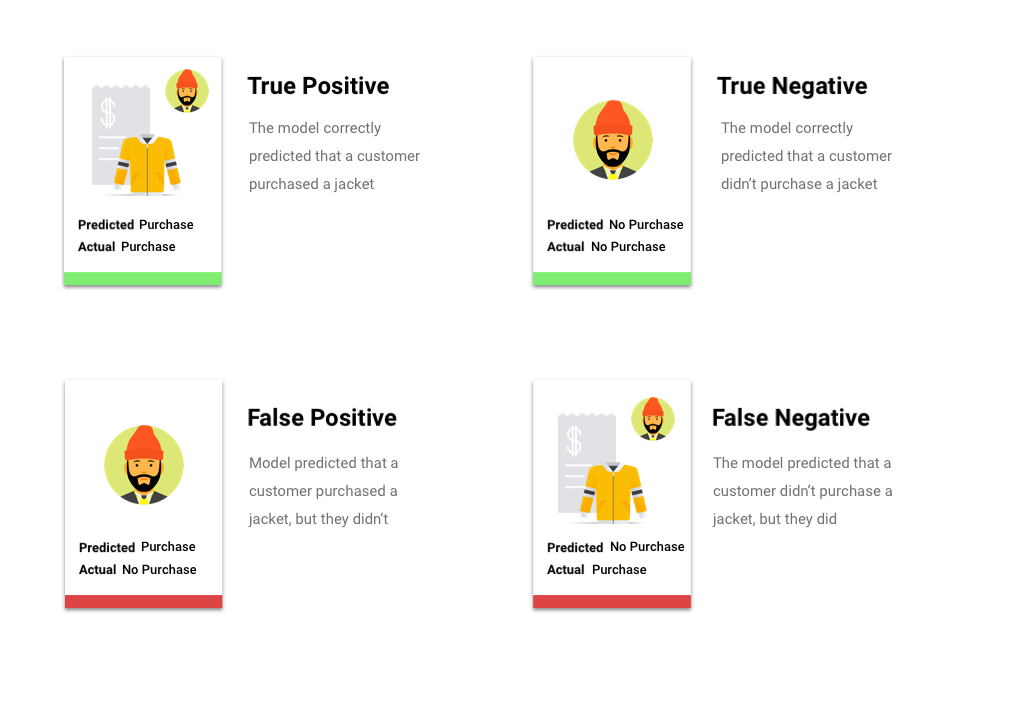
スコアしきい値を適用した後のモデルによる予測は、4 つのカテゴリのうちの 1 つに分類されます。これらのカテゴリを理解するために、もう一度ジャケットのバイナリ分類モデルを考えてみましょう。この例では、陽性のクラス(モデルが予測しようとしていること)は、顧客がジャケットを来年に購入するということです。
- 真陽性: モデルは陽性のクラスを正しく予測している。モデルは顧客がジャケットを購入することを正しく予測しました。
- 偽陽性: モデルは陽性のクラスを誤って予測している。モデルは顧客がジャケットを購入すると予測しましたが、顧客は購入しませんでした。
- 真陰性: モデルは陰性のクラスを正しく予測している。モデルは顧客がジャケットを購入しないことを正しく予測しました。
- 偽陰性: モデルは陰性のクラスを誤って予測している。モデルは顧客がジャケットを購入しないと予測しましたが、顧客は購入しました。
適合率と再現率
適合率と再現率は、モデルがどの程度適切に情報を取得しているか、そしてどれだけの情報を除外しているかを把握するのに役立ちます。適合率と再現率の詳細。
- 適合率は、肯定の予測のうち、正しかった予測の割合です。つまり、顧客が購入するであろうと予測されたうち、実際に購入した割合です。
- 再現率は、モデルによって正しく予測された、このラベルが付けられた行の割合です。つまり、識別できるはずの顧客の購入のうち、実際に識別された割合を示します。
ユースケースに応じて、適合率または再現率の最適化が必要になる場合があります。
その他の分類指標
AUC PR: 適合率 / 再現率(PR)曲線の下の面積。この値は範囲が 0~1 で、値が高いほど高品質のモデルであることを示します。
AUC ROC: 受信者操作特性(ROC)曲線の下の面積。この範囲は 0~1 で、値が高いほど高品質のモデルであることを示します。
精度: 正しいモデルによって生成された分類予測の割合。
ログ損失: モデル予測とターゲット値の間のクロス エントロピー。この範囲はゼロから無限大までで、値が低いほど高品質のモデルであることを示します。
F1 スコア: 適合率と再現率の調和平均。適合率と再現率のバランスを求めていて、クラス分布が不均一な場合、F1 は有用な指標となります。
回帰指標
モデルが構築されると、AutoML Tables から提供されるさまざまな標準的回帰指標を使ってモデルを評価できます。モデルを評価する方法について完全な答えはありません。評価指標を、問題の種類やモデルを使って達成したいことと関連させて考慮する必要があります。利用できる指標の概要を以下に示します。
平均絶対誤差(MAE)
MAE は、目標値と予測値の平均絶対差です。一連の予測における誤差(目標値と予測値の差)の平均の大きさを測定します。絶対値を使用するため、MAE は関係の方向性を考慮せず、過少パフォーマンスや過剰パフォーマンスを示すこともありません。MAE を評価するとき、値が小さいほど品質の高いモデルを示します(0 は完全な予測因子を表します)。
二乗平均平方根誤差(RMSE)
RMSE は、目標値と予測値の平均二乗差の平方根です。RMSE は MAE よりも外れ値の影響を受けやすいため、大きな誤差が心配な場合は RMSE のほうがより便利な評価指標といえます。MAE と同様に、値が小さいほど品質の高いモデルを示します(0 は完全な予測因子を表します)。
二乗平均対数平方誤差(RMSLE)
RMSLE は対数目盛りの RMSE です。RMSLE は絶対的誤差よりも相対的誤差に対して敏感であり、過剰パフォーマンスよりも過小パフォーマンスを重視します。
モデルのテスト
モデル指標の評価とは主として、モデルをデプロイする準備ができているかどうかを判断する方法ですが、新しいデータでテストすることもできます。新しいデータをアップロードしてみて、モデルの予測が自分の予想と一致するかどうかを確かめてください。評価指標や新しいデータによるテストに基づいて、モデルのパフォーマンスを引き続き向上させる必要があることがあります。モデルのトラブルシューティングの詳細
モデルをデプロイして予測する
 モデルのパフォーマンスが満足のいくものになったら、モデルを使い始めます。本番環境で使用することになる可能性もありますし、一回限りの予測リクエストかもしれません。ユースケースに応じて、モデルをさまざまな方法で使用できます。
モデルのパフォーマンスが満足のいくものになったら、モデルを使い始めます。本番環境で使用することになる可能性もありますし、一回限りの予測リクエストかもしれません。ユースケースに応じて、モデルをさまざまな方法で使用できます。
バッチ予測
バッチ予測は、多数の予測リクエストを一度で行うのに便利です。バッチ予測は非同期です。つまり、モデルはすべての予測リクエストを処理するのを待ってから、予測値を含む CSV ファイルまたは BigQuery テーブルを返します。
オンライン予測
モデルをデプロイして、REST API を使用して予測リクエストで使用できるようにします。オンライン予測は同期的(リアルタイム)です。つまり、予測はすぐに返されますが、API 呼び出しごとに 1 つの予測リクエストしか受け付けません。オンライン予測は、モデルがアプリケーションの一部であり、システムの一部が素早い予測ターンアラウンドに依存している場合に便利です。
不必要な料金が発生しないようにするため、モデルを使用していないときはモデルをデプロイ解除することを忘れないでください。