Introducción
Imagina que trabajas en el departamento de marketing de un minorista digital. Tú y tu equipo están creando un programa de correo electrónico personalizado basado en los perfiles de los clientes. Ya crearon los perfiles y tienen los correos electrónicos de marketing listos. Ahora, deben crear un sistema que agrupe a los clientes en cada perfil según las preferencias de compra y el comportamiento de consumo, incluso si son nuevos. Supón que también quieren predecir sus hábitos de consumo para que puedan optimizar el momento de enviar los correos electrónicos con el fin de captar más clientes.
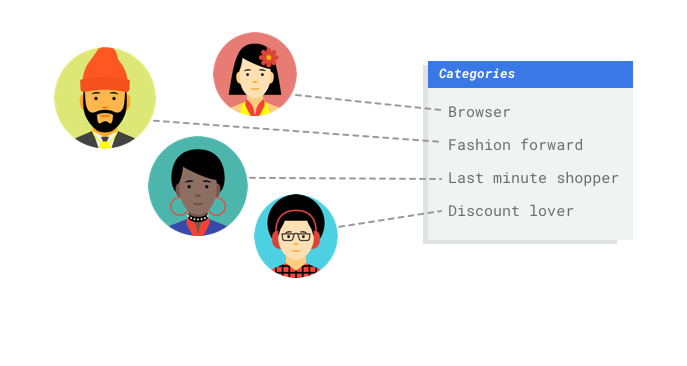
Debido a que eres un minorista digital, tienes datos sobre tus clientes y las compras que realizaron. Pero ¿qué sucede con los clientes nuevos? Los enfoques tradicionales pueden calcular estos valores con los clientes existentes con extensos historiales de compra, pero no funcionan muy bien con los clientes con pocos datos históricos. ¿Qué tal si pudieras crear un sistema para predecir estos valores y aumentar la velocidad con la que ofreces programas de marketing personalizados a los clientes?
Por suerte, el aprendizaje automático y AutoML Tables están bien preparados para resolver estos problemas. En esta guía, se explica cómo funciona AutoML Tables y los tipos de problemas que puede solucionar.
¿Cómo funciona AutoML Tables?
 AutoML Tables es un servicio de aprendizaje supervisado. Esto significa que puedes entrenar un modelo de aprendizaje automático con datos de ejemplo. AutoML Tables usa datos tabulares (estructurados) para entrenar un modelo de aprendizaje automático a fin de realizar predicciones sobre datos nuevos. Tu modelo aprenderá a predecir una columna de tu conjunto de datos llamada el objetivo. Algunas de las otras columnas de datos son entradas (llamadas atributos) de las que el modelo aprenderá patrones. Puedes usar los mismos atributos de entrada para crear varios tipos de modelos con solo cambiar el objetivo. A partir del ejemplo del correo electrónico de marketing, podrías crear dos modelos con los mismos atributos de entrada: un modelo podría predecir el perfil de un cliente (un objetivo categórico) y otro podría predecir su consumo mensual (un objetivo numérico).
AutoML Tables es un servicio de aprendizaje supervisado. Esto significa que puedes entrenar un modelo de aprendizaje automático con datos de ejemplo. AutoML Tables usa datos tabulares (estructurados) para entrenar un modelo de aprendizaje automático a fin de realizar predicciones sobre datos nuevos. Tu modelo aprenderá a predecir una columna de tu conjunto de datos llamada el objetivo. Algunas de las otras columnas de datos son entradas (llamadas atributos) de las que el modelo aprenderá patrones. Puedes usar los mismos atributos de entrada para crear varios tipos de modelos con solo cambiar el objetivo. A partir del ejemplo del correo electrónico de marketing, podrías crear dos modelos con los mismos atributos de entrada: un modelo podría predecir el perfil de un cliente (un objetivo categórico) y otro podría predecir su consumo mensual (un objetivo numérico).
Flujo de trabajo de AutoML Tables
AutoML Tables usa un flujo de trabajo de aprendizaje automático estándar:
- Reúne tus datos: Determina los datos que necesitas para entrenar y probar tu modelo en función del resultado que quieres lograr.
- Prepara tus datos: Asegúrate de que los datos tengan el formato adecuado antes y después de importarlos.
- Entrena: Configura los parámetros y crea tu modelo.
- Evalúa: Revisa las métricas del modelo.
- Prueba: Pon a prueba tu modelo con los datos de prueba.
- Implementa y predice: Haz que tu modelo esté disponible para su uso.
Sin embargo, antes de comenzar a recopilar datos, debes pensar en el problema que está tratando de resolver, lo que definirá los requisitos de datos.
Considera tu caso práctico

Comienza con tu problema: ¿cuál es el resultado que quieres obtener? ¿Qué tipo de datos lleva la columna objetivo? ¿A qué cantidad de datos tienes acceso?
Según tus respuestas, AutoML Tables creará el modelo necesario para resolver tu caso práctico:
Los modelos de clasificación binaria predicen un resultado binario (una de dos clases). Úsalos para preguntas de sí o no, por ejemplo, a fin de predecir si un cliente pagaría una suscripción (o no). Si todo lo demás permanece constante, un problema de clasificación binaria requiere menos datos que otros tipos de modelos.
Los modelos de clasificación de varias clases predicen una clase de tres o más clases discretas. Úsalos para categorizar. Para el ejemplo de la venta minorista, deberías crear un modelo de clasificación de clases múltiples con el fin de segmentar a los clientes en diferentes perfiles.
Un modelo de regresión predice un valor continuo. Para el ejemplo de venta minorista, también deberías crear un modelo de regresión a fin de prever el consumo de los clientes durante el próximo mes.
AutoML Tables definirá de forma automática el problema y el modelo que se debe crear según el tipo de datos de la columna objetivo. Por lo tanto, si tu columna objetivo contiene datos numéricos, AutoML Tables creará un modelo de regresión. Si tu columna objetivo es de datos categóricos, AutoML Tables detectará la cantidad de clases y determinará si necesitas crear un modelo binario o de varias clases.
Una aclaración sobre la equidad
La equidad es una de las prácticas responsables de la IA de Google. Su objetivo es comprender y evitar un tratamiento injusto o prejuicioso de las personas en relación con sus ingresos, su origen étnico, orientación sexual, religión, género y otras características asociadas históricamente con la discriminación y la exclusión en el lugar y momento en el que se manifiesten en los sistemas algorítmicos o en la toma de decisiones basada en algoritmos. A medida que leas esta guía, verás notas sobre “Imparcialidad” que tratan sobre cómo crear un modelo de aprendizaje automático más justo. Más información
Recopila tus datos
 Después de establecer tu caso práctico, deberás recopilar datos para entrenar el modelo.
La obtención y la preparación de datos son pasos fundamentales para crear un modelo de aprendizaje automático. Los datos que tengas disponibles dictaminarán el tipo de problemas que puedes resolver.
¿Cuántos de datos tienes disponibles? ¿Tus datos son relevantes para las preguntas que intentas responder? Mientras recopilas tus datos, ten en cuenta las consideraciones claves que se mencionan a continuación.
Después de establecer tu caso práctico, deberás recopilar datos para entrenar el modelo.
La obtención y la preparación de datos son pasos fundamentales para crear un modelo de aprendizaje automático. Los datos que tengas disponibles dictaminarán el tipo de problemas que puedes resolver.
¿Cuántos de datos tienes disponibles? ¿Tus datos son relevantes para las preguntas que intentas responder? Mientras recopilas tus datos, ten en cuenta las consideraciones claves que se mencionan a continuación.
Selecciona las características relevantes
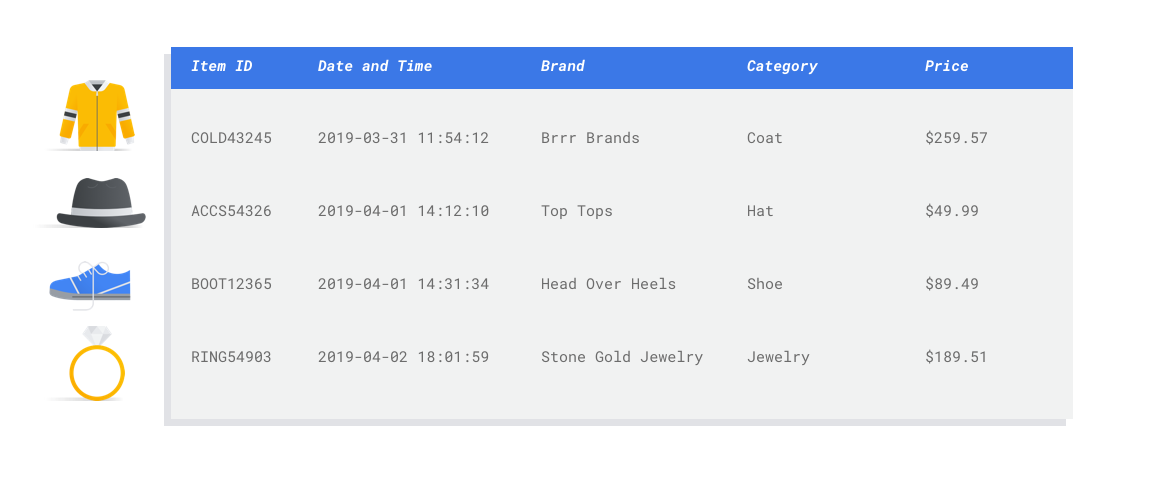
Una característica es un atributo de entrada que se usa para el entrenamiento del modelo. Las características son la forma en que tu modelo identifica patrones a fin de hacer predicciones, por lo que deben ser relevantes para problema. Por ejemplo, para crear un modelo que prediga si la transacción de una tarjeta de crédito es fraudulenta o no, deberás compilar un conjunto de datos que contenga detalles de la transacción, como el comprador, vendedor, importe, la fecha y hora y los artículos comprados. Otros atributos útiles pueden ser la información histórica sobre el comprador, el vendedor y la frecuencia con la que el artículo en cuestión ha sido objeto de fraude. ¿Qué otras características podrían ser relevantes?
Consideremos el caso práctico de la introducción sobre el correo electrónico de marketing para el vendedor minorista. Estas son algunas columnas de atributos que podrías necesitar:
- Lista de artículos comprados (que incluye marcas, categorías, precios, descuentos)
- Cantidad de artículos comprados (último día, semana, mes, año)
- Importe de dinero gastado (último día, semana, mes, año)
- Perfil demográfico conocido del comprador
Incluye suficientes datos
 En general, mientras más ejemplos de entrenamiento tengas, mejor será el resultado. La cantidad de datos de ejemplo necesarios también se ajusta a la complejidad del problema que intentas resolver. En comparación con un modelo de varias clases, para obtener un modelo de clasificación binaria preciso, no necesitarás tantos datos, porque es menos complicado predecir una clase entre dos que entre muchas.
En general, mientras más ejemplos de entrenamiento tengas, mejor será el resultado. La cantidad de datos de ejemplo necesarios también se ajusta a la complejidad del problema que intentas resolver. En comparación con un modelo de varias clases, para obtener un modelo de clasificación binaria preciso, no necesitarás tantos datos, porque es menos complicado predecir una clase entre dos que entre muchas.
No existe la fórmula perfecta, pero sí se recomiendan cantidades mínimas de filas de datos de ejemplo:
- Problema de clasificación: 50 veces la cantidad de atributos
- Problema de regresión: 200 veces la cantidad de atributos
Abarca la variedad
Tu conjunto de datos debería abarcar la diversidad de la dimensión del problema. Cuanto más diversos sean los ejemplos que ve un modelo durante el entrenamiento, con mayor facilidad podrá generalizar ejemplos nuevos o no tan comunes. Imagina si tu modelo de venta minorista se entrenara solo con datos de compras durante el invierno. ¿Podría predecir con éxito las preferencias sobre vestimenta o comportamientos de compra durante el verano?
Prepara los datos

Una vez que hayas identificado los datos disponibles, debes asegurarte de que estén listos para el entrenamiento. Si tus datos contienen sesgos, valores faltantes o erróneos, tu modelo los reflejará en el entrenamiento. Antes de comenzar a entrenar tu modelo, ten en cuenta lo siguiente. Más información
Evita la filtración de datos y desviaciones entre el entrenamiento y la entrega
La filtración de datos ocurre cuando usas atributos de entrada durante el entrenamiento que “filtran” información acerca del objetivo que intentas predecir y que no está disponible cuando el modelo se entrega. Esto se puede detectar cuando un atributo que tiene una alta correlación con la columna objetivo se incluye como uno de los atributos de entrada. Por ejemplo, si estás creando un modelo con el fin de predecir si un cliente se registrará para obtener una suscripción el próximo mes, y uno de los atributos de entrada es un pago a futuro de suscripción de ese cliente. Esto puede generar un gran rendimiento del modelo durante la prueba, pero no cuando se implementa en producción, ya que la información de pago a futuro de la suscripción no estará disponible al momento de la entrega.
Las desviaciones entre el entrenamiento y la entrega ocurren cuando los atributos de entrada usados durante el entrenamiento son diferentes de los que se proporcionan al modelo al momento de la entrega, lo que reduce la calidad de modelo en la producción. Por ejemplo, si creas un modelo para predecir las temperaturas por hora, pero entrenas con datos que solo contengan temperaturas semanales. Otro ejemplo: supongamos que quieres predecir la deserción escolar y siempre proporcionas las calificaciones de un alumno en los datos de entrenamiento, pero no lo haces al momento de la entrega.
Es importante que comprendas los datos de entrenamiento para evitar la filtración de datos y desviaciones entre el entrenamiento y la entrega:
- Antes de usar cualquier tipo de datos, asegúrate de saber qué significan y si debes usarlos como un atributo.
- Verifica la correlación en la pestaña de entrenamiento. Las altas correlaciones se deben marcar para revisarlas luego.
- Desviaciones entre el entrenamiento y la entrega: Asegúrate de proporcionar al modelo solo los atributos de entrada que, al momento de la entrega, no hubiesen cambiado de ninguna forma.
Borra los datos incompletos, incoherentes y faltantes
Es común que tengas valores faltantes o imprecisos en los datos de ejemplo. Tómate el tiempo para revisar y, cuando sea posible, mejorar la calidad de los datos antes de usarlos en el entrenamiento. Cuantos más valores faltantes haya, menos útil serán tus datos a la hora de entrenar un modelo de aprendizaje automático.
Busca valores faltantes entre tus datos. Corrígelos cuando sea posible o deja el valor en blanco si la columna es anulable. AutoML Tables puede trabajar con valores faltantes, pero es más probable que obtengas resultados óptimos si todos los valores están disponibles.
Realiza una limpieza de tus datos: corrige o borra los errores de datos o información irrelevante. Haz que tus datos sean coherentes: revisa la ortografía, las abreviaturas y el formato.
Analiza tus datos después de importarlos
AutoML Tables proporciona una descripción general de tu conjunto de datos después de importarlo. Revisa el conjunto de datos importado para asegurarte de que cada columna tenga el tipo de variable correcto. AutoML Tables detectará de forma automática el tipo de variable según los valores de las columnas, pero es conveniente revisar cada una. También debes revisar la nulidad de cada columna, que determina si una columna puede contener valores faltantes o NULL.
Entrena tu modelo
Después de importar tu conjunto de datos, el siguiente paso es entrenar un modelo. AutoML Tables generará un modelo de aprendizaje automático confiable con los valores predeterminados de entrenamiento, pero te recomendamos cambiar algunos de los parámetros según tu caso práctico.
Para el entrenamiento, intenta seleccionar tantas columnas de atributos como sea posible, pero revisa cada una con el fin de asegurarte de que sean adecuadas para el entrenamiento. Ten en cuenta las siguientes consideraciones para la selección de atributos:
- No selecciones columnas de atributos que generen información irrelevante, como columnas de identificador asignadas de forma aleatoria con un valor único para cada fila.
- Asegúrate de comprender cada columna de atributos y sus valores.
- Si creas varios modelos a partir de un conjunto de datos, quita las columnas objetivo que no forman parte del problema de predicción actual.
- Recuerda los principios de equidad: ¿Entrenaste tu modelo con un atributo que podría llevar a una toma de decisiones sesgada o injusta hacia los grupos marginados?
Cómo usa tu conjunto de datos AutoML Tables
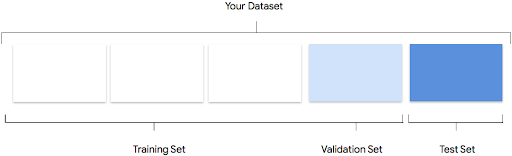
Tu conjunto de datos se dividirá en grupos de entrenamiento, validación y prueba. De forma predeterminada, AutoML Tables usa el 80% de los datos para entrenamiento, el 10% destinado a validación y el 10% a pruebas, pero puedes editar estos valores de forma manual si es necesario.
Conjunto de entrenamiento
 La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento: se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento: se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
Conjunto de validación
 El conjunto de validación, a veces denominado el conjunto “dev”, también se usa durante el proceso de entrenamiento. Después de que el marco de trabajo del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud. Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
El conjunto de validación, a veces denominado el conjunto “dev”, también se usa durante el proceso de entrenamiento. Después de que el marco de trabajo del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud. Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
Conjunto de prueba
 El conjunto de prueba nunca forma parte del proceso de entrenamiento. Una vez que el modelo completó su entrenamiento por completo, AutoML Tables usa el conjunto de prueba como un nuevo desafío para tu modelo. El rendimiento de tu modelo en el conjunto de prueba te dará una idea bastante aproximada de cómo tu modelo funcionará con datos reales.
El conjunto de prueba nunca forma parte del proceso de entrenamiento. Una vez que el modelo completó su entrenamiento por completo, AutoML Tables usa el conjunto de prueba como un nuevo desafío para tu modelo. El rendimiento de tu modelo en el conjunto de prueba te dará una idea bastante aproximada de cómo tu modelo funcionará con datos reales.
Evalúa tu modelo
 Después del entrenamiento del modelo, recibirás un resumen sobre el rendimiento. Las métricas de evaluación del modelo se basan en cómo se desempeñó ante una porción de tu conjunto de datos (el conjunto de datos de prueba). Hay algunas métricas y conceptos clave que debes tener en cuenta a fin de determinar si tu modelo está listo para usarse con datos reales.
Después del entrenamiento del modelo, recibirás un resumen sobre el rendimiento. Las métricas de evaluación del modelo se basan en cómo se desempeñó ante una porción de tu conjunto de datos (el conjunto de datos de prueba). Hay algunas métricas y conceptos clave que debes tener en cuenta a fin de determinar si tu modelo está listo para usarse con datos reales.
Métricas de clasificación
Umbral de puntuación
Considera un modelo de aprendizaje automático que prediga si el próximo año un cliente comprará una chaqueta o no. ¿Qué tan seguro debe estar el modelo antes de predecir que un cliente determinado comprará una chaqueta? En los modelos de clasificación, a cada predicción se le asigna una puntuación de confianza, una evaluación numérica acerca de la certeza del modelo de que la clase predicha sea correcta. El umbral de puntuación es el número que determina cuándo cierta puntuación se convierte en una decisión de sí o no, es decir, el valor con el que tu modelo dice: “sí, esta puntuación de confianza es lo bastante alta como para concluir que este cliente comprará un abrigo el próximo año”.
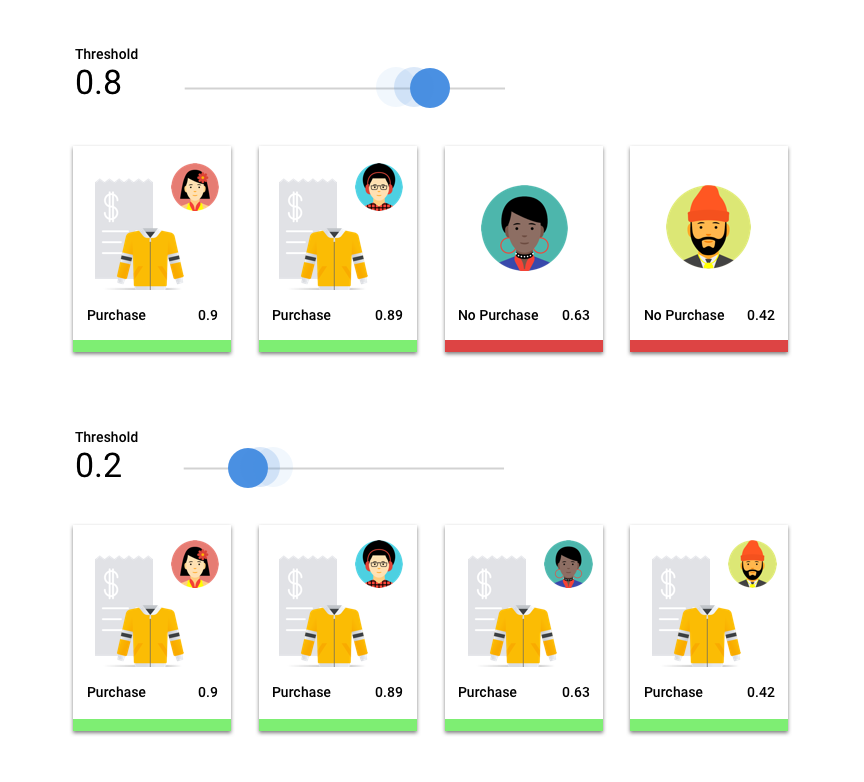
Si tu umbral de puntuación es bajo, tu modelo correrá el riesgo de realizar una clasificación errónea. Por ese motivo, el umbral de puntuación debe basarse en un caso práctico determinado.
Resultados de la predicción
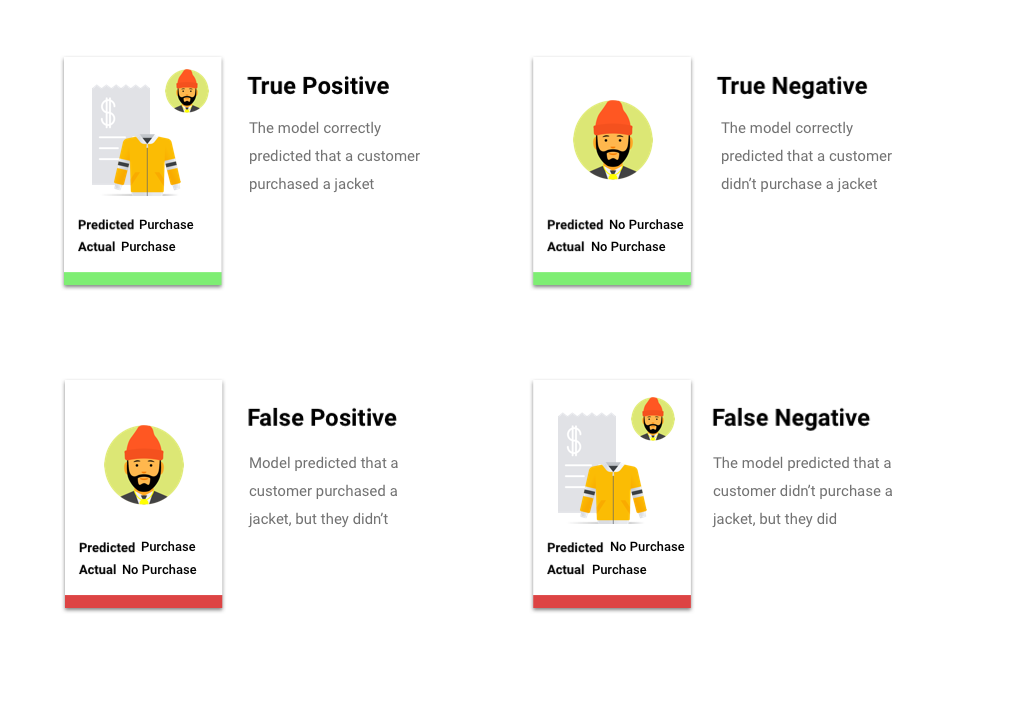
Después de aplicar el umbral de puntuación, las predicciones que realice tu modelo se clasificarán en una de cuatro categorías. Para comprender estas categorías, imagina otra vez un modelo de clasificación binaria de chaquetas. En este ejemplo, la clase positiva (lo que el modelo intenta predecir) es si cliente sí comprará una chaqueta el próximo año.
- Verdadero positivo: El modelo predice la clase positiva de forma correcta. El modelo predijo de forma correcta que un cliente compró una chaqueta.
- Falso positivo: El modelo predice la clase positiva de forma incorrecta. El modelo predijo que un cliente compró una chaqueta, pero este no lo hizo.
- Verdadero negativo: El modelo predice la clase negativa de forma correcta. El modelo predijo de forma correcta que un cliente no compró una chaqueta.
- Falso negativo: El modelo predice una clase negativa de forma incorrecta. El modelo predijo que un cliente no compró una chaqueta, pero sí lo hizo.
Precisión y recuperación
Las métricas de precisión y recuperación te ayudan a comprender qué tan bien tu modelo capta información y qué omite. Obtén más información sobre precisión y recuperación.
- La precisión es la fracción correcta de las predicciones positivas. De todas las predicciones de compra de un cliente, ¿qué fracción correspondieron a compras reales?
- La recuperación es la fracción de filas sw esta etiqueta que el modelo predijo de forma correcta. De todas las compras de clientes que se pudieron haber identificado, ¿qué fracción se predijo?
Según el caso práctico, es posible que debas optimizar la precisión o la recuperación.
Otras métricas de clasificación
AUC PR: El área bajo la curva de precisión y recuperación (PR). Esta medida puede variar de cero a uno, y cuanto más alto sea su valor, mejor será la calidad del modelo.
AUC ROC: El área bajo la curva de característica operativa del receptor (ROC). Esta puede variar de cero a uno y cuanto más alto sea su valor, mejor será la calidad del modelo.
Exactitud: La fracción de predicciones de clasificación correctas que produjo el modelo.
Pérdida logística: La entropía cruzada entre las predicciones del modelo y los valores objetivo. Esta medida puede variar de cero a infinito, y cuanto más bajo sea su valor, mejor será la calidad del modelo.
Puntuación F1: La media armónica de precisión y recuperación. F1 es una métrica útil si lo que buscas es un equilibrio entre la precisión y la recuperación, y tienes una distribución de clases despareja.
Métricas de regresión
Una vez creado tu modelo, AutoML Tables te proporcionará una variedad de métricas de regresión estándar para que las revises. No existe la respuesta perfecta sobre cómo evaluar tu modelo. Las métricas de evaluación se deben considerar en contexto con el tipo de problema y lo que quieras lograr con él. A continuación, te presentamos una descripción general de algunas métricas que tendrás disponibles.
Error absoluto medio (MAE)
MAE es la diferencia absoluta promedio entre los valores objetivo y valores predichos. Determina la magnitud promedio de los errores (la diferencia entre un valor objetivo y uno predicho) en un conjunto de predicciones. Además, como usa valores absolutos, MAE no tiene en cuenta la dirección de la relación, ni tampoco indica cuándo el rendimiento está por debajo o por encima del esperado. Cuando se evalúa MAE, cuanto más bajo el valor, mayor será la calidad del modelo (0 representa un predictor perfecto).
Raíz cuadrada del error cuadrático medio (RMSE)
RMSE es la raíz cuadrada de la diferencia cuadrática promedio entre los valores objetivo y valores predichos. RMSE es más sensible a los valores atípicos que MAE, por lo que si te preocupan los grandes errores, RMSE puede ser una métrica más útil para evaluar. Al igual que MAE, cuanto más bajo el valor, mayor será la calidad del modelo (0 representa un predictor perfecto).
Raíz cuadrada del error logarítmico cuadrático medio (RMSLE)
RMSLE es RMSE en escala logarítmica. RMSLE es más sensible a los errores relativos que a los absolutos y tiene más en cuenta a los rendimientos por debajo que por encima de lo esperado.
Prueba tu modelo
La evaluación de las métricas de tu modelo es, en esencia, la forma de determinar si el modelo está listo para implementarse, pero también puedes probarlo con datos nuevos. Intenta subir datos nuevos para ver si las predicciones del modelo coinciden con tus expectativas. Según las métricas de evaluación o las pruebas con datos nuevos, es posible que debas seguir mejorando el rendimiento de tu modelo. Obtén más información sobre la solución de problemas de tu modelo.
Implementa tu modelo y haz predicciones
 Cuando estés satisfecho con el rendimiento de tu modelo, es hora de usarlo. Quizás eso signifique usarlo en escala de producción o tal vez sea una solicitud de predicción de un solo uso. Según tu caso práctico, puedes usar tu modelo de diferentes maneras.
Cuando estés satisfecho con el rendimiento de tu modelo, es hora de usarlo. Quizás eso signifique usarlo en escala de producción o tal vez sea una solicitud de predicción de un solo uso. Según tu caso práctico, puedes usar tu modelo de diferentes maneras.
Predicción por lotes
La predicción por lotes es útil para realizar muchas solicitudes de predicción a la vez. La predicción por lotes es asíncrona, lo que significa que el modelo esperará hasta procesar todas las solicitudes de predicción antes de mostrar un archivo CSV o una tabla de BigQuery con valores de predicción.
Predicción en línea
Implementa tu modelo a fin de que esté disponible para las solicitudes de predicción mediante una API de REST. La predicción en línea es síncrona (en tiempo real), lo que significa que mostrará una predicción con rapidez, pero solo acepta una solicitud de predicción por cada llamada a la API. La predicción en línea es útil si tu modelo es parte de una aplicación y si algunas partes de tu sistema dependen de una rápida respuesta de predicción.
Para evitar consumos no deseados, recuerda anular la implementación de tu modelo cuando no esté en uso.