Wenn Sie einige Container-Images direkt aus Registrys von Drittanbietern herunterladen, um sie in Google Cloud-Umgebungen wie Google Kubernetes Engine oder Cloud Run bereitzustellen, können Ratenbegrenzungen für das Abrufen von Images oder Ausfälle von Drittanbietern Ihre Builds und Bereitstellungen beeinträchtigen. Auf dieser Seite wird gezeigt, wie Sie diese Images ermitteln und zur konsolidierten, konsistenten Container-Image-Verwaltung nach Artifact Registry kopieren.
Artifact Registry überwacht keine Drittanbieter-Registrys auf Updates für Images, die Sie nach Artifact Registry kopieren. Wenn Sie eine neuere Version eines Images in Ihre Pipeline einbinden möchten, müssen Sie sie in Artifact Registry hochladen.
Migration
Die Migration Ihrer Container-Images umfasst die folgenden Schritte:
- Richten Sie Voraussetzungen ein.
- Identifizieren Sie die zu migrierenden Images.
- Suchen Sie in Dockerfile-Dateien und Bereitstellungsmanifesten nach Verweisen auf Registrys von Drittanbietern.
- Ermitteln Sie mithilfe von Cloud Logging und BigQuery die Abrufhäufigkeit von Images aus Drittanbieter-Registrys.
- Kopieren Sie ermittelte Images nach Artifact Registry.
- Prüfen Sie, ob die Berechtigungen für die Registry korrekt konfiguriert sind, insbesondere wenn sich Artifact Registry und Ihre Google Cloud-Bereitstellungsumgebung in unterschiedlichen Projekten befinden.
- Aktualisieren Sie manifests für Ihre Bereitstellungen.
- Stellen Sie Ihre Arbeitslasten neu bereit.
Hinweise
- Prüfen Sie Ihre Berechtigungen. Sie benötigen die IAM-Rolle Inhaber oder Bearbeiter in den Projekten, in denen Sie Images zu Artifact Registry migrieren.
-
- Wählen Sie das Google Cloud-Projekt aus, in dem Sie Artifact Registry verwenden möchten.
- Rufen Sie Cloud Shell in der Google Cloud Console auf.
Suchen Sie Ihre Projekt-ID und legen Sie sie in Cloud Shell fest. Ersetzen Sie
YOUR_PROJECT_IDdurch Ihre Projekt-ID.gcloud config set project YOUR_PROJECT_ID
Exportieren Sie die folgenden Umgebungsvariablen:
export PROJECT=$(gcloud config get-value project)Aktivieren Sie die BigQuery, Artifact Registry und Cloud Monitoring APIs mit dem folgenden Befehl:
gcloud services enable \ artifactregistry.googleapis.com \ stackdriver.googleapis.com \ logging.googleapis.com \ monitoring.googleapis.comWenn Sie Artifact Registry derzeit nicht verwenden, konfigurieren Sie ein Repository für Ihre Images:
- Repository erstellen
- Konfigurieren Sie die Authentifizierung für externe Clients, die Zugriff auf das Repository benötigen.
Prüfen Sie, ob Go Version 1.13 oder höher installiert ist.
Prüfen Sie die Version einer vorhandenen Go-Installation mit folgendem Befehl:
go versionWenn Sie Go installieren oder aktualisieren müssen, finden Sie Informationen dazu in der Dokumentation zur Go-Installation.
Kosten
In diesem Leitfaden werden die folgenden kostenpflichtigen Komponenten von Google Cloud verwendet:
Zu migrierende Images identifizieren
Suchen Sie in den Dateien, die Sie zum Erstellen und Bereitstellen Ihrer Container-Images verwenden, nach Verweise auf Registrys von Drittanbietern. Prüfen Sie dann, wie oft Sie die Images abrufen.
Verweise in Dockerfiles identifizieren
Führen Sie diesen Schritt an einem Speicherort aus, an dem Ihre Dockerfiles gespeichert sind. Dies kann dort sein, wo Ihr Code lokal geprüft wird, oder in Cloud Shell, wenn die Dateien in einer VM verfügbar sind.
Führen Sie im Verzeichnis mit Ihren Dockerfiles den folgenden Befehl aus:
grep -inr -H --include Dockerfile\* "FROM" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
Die Ausgabe sieht so aus:
./code/build/baseimage/Dockerfile:1:FROM debian:stretch
./code/build/ubuntubase/Dockerfile:1:FROM ubuntu:latest
./code/build/pythonbase/Dockerfile:1:FROM python:3.5-buster
Mit diesem Befehl werden alle Dockerfiles in Ihrem Verzeichnis durchsucht, um die Zeile "FROM" zu ermitteln. Passen Sie den Befehl entsprechend der Speicherung Ihrer Dockerfiles an.
Verweise in Manifesten ermitteln
Führen Sie diesen Schritt an einem Speicherort aus, an dem Ihre GKE- oder Cloud Run-Manifeste gespeichert sind. Dies kann dort sein, wo Ihr Code lokal geprüft wird, oder in Cloud Shell, wenn die Dateien in einer VM verfügbar sind.
Führen Sie den folgenden Befehl im Verzeichnis mit Ihren GKE- oder Cloud Run-Manifesten aus:
grep -inr -H --include \*.yaml "image:" . | grep -i -v -E 'docker.pkg.dev|gcr.io'Beispielausgabe:
./code/deploy/k8s/ubuntu16-04.yaml:63: image: busybox:1.31.1-uclibc ./code/deploy/k8s/master.yaml:26: image: kubernetes/redis:v1Dieser Befehl prüft alle YAML-Dateien in Ihrem Verzeichnis und identifiziert die Zeile image:. Passen sie ihn so an, dass er mit der Art des Speicherns der Manifeste funktioniert.
Um die derzeit auf einem Cluster ausgeführten Images aufzulisten, führen Sie folgenden Befehl aus:
kubectl get all --all-namespaces -o yaml | grep image: | grep -i -v -E 'docker.pkg.dev|gcr.io'Dieser Befehl gibt alle Objekte zurück, die im aktuell ausgewählten Kubernetes-Cluster ausgeführt werden, und ruft deren Image-Namen ab.
Beispielausgabe:
- image: nginx image: nginx:latest - image: nginx - image: nginx
Führen Sie diesen Befehl für alle GKE-Cluster in allen Google Cloud-Projekten aus für gesamte Abdeckung.
Abrufhäufigkeit von Drittanbieter-Registry ermitteln
Verwenden Sie in Projekten, die aus Registrys von Drittanbietern abrufen, Informationen zur Image-Abrufhäufigkeit, um festzustellen, ob Ihre Nutzung irgendwelche Ratenbegrenzungen durch die Drittanbieter-Registry fast erreicht oder überschreitet.
Logdaten erfassen
Erstellen Sie eine Logsenke, um Daten nach BigQuery zu exportieren. Eine Senke enthält ein Ziel und eine Abfrage, mit der die Logeinträge ausgewählt werden, die exportiert werden sollen. Sie können eine Senke durch Abfrage einzelner Projekte erstellen oder durch Verwendung eines Skripts, mit dem Daten projektübergreifend erfasst werden.
So erstellen Sie eine Senke für ein einzelnes Projekt:
Wählen Sie ein Google Cloud-Projekt aus.
Geben Sie auf dem Tab Query Builder die folgende Abfrage ein:
resource.type="k8s_pod" jsonPayload.reason="Pulling"Ändern Sie den Verlaufsfilter von Letzte Stunde in Letzte 7 Tage.
Klicken Sie auf Abfrage ausführen.
Nachdem Sie geprüft haben, ob die Ergebnisse korrekt angezeigt werden, klicken Sie auf Aktionen > Senke erstellen.
Wählen Sie in der Liste der Senken BigQuery-Dataset aus und klicken Sie auf Weiter.
Führen Sie im Bereich „Senke bearbeiten“ die folgenden Schritte aus:
- Geben Sie im Feld Name der Senke ()
image_pull_logsein. - Erstellen Sie im Feld Senkenziel ein neues Dataset oder wählen Sie ein Ziel-Dataset in einem anderen Projekt aus.
- Geben Sie im Feld Name der Senke ()
Klicken Sie auf Senke erstellen.
So erstellen Sie eine Senke für mehrere Projekte:
Führen Sie die folgenden Befehle in Cloud Shell aus:
PROJECTS="PROJECT-LIST" DESTINATION_PROJECT="DATASET-PROJECT" DATASET="DATASET-NAME" for source_project in $PROJECTS do gcloud logging --project="${source_project}" sinks create image_pull_logs bigquery.googleapis.com/projects/${DESTINATION_PROJECT}/datasets/${DATASET} --log-filter='resource.type="k8s_pod" jsonPayload.reason="Pulling"' doneWobei Folgendes gilt:
- PROJECT-LIST ist eine Liste von Google Cloud-Projekt-IDs, die durch Leerzeichen getrennt sind. Beispiel:
project1 project2 project3. - DATASET-PROJECT ist das Projekt, in dem Sie das Dataset speichern möchten.
- DATASET-NAME ist der Name des Datasets, z. B.
image_pull_logs.
- PROJECT-LIST ist eine Liste von Google Cloud-Projekt-IDs, die durch Leerzeichen getrennt sind. Beispiel:
Nachdem Sie eine Senke erstellt haben, dauert es eine gewisse Zeit, bis Daten an BigQuery-Tabellen übertragen werden. Dies hängt auch davon ab, wie häufig Images abgerufen werden.
Abfrage von Abrufhäufigkeit
Sobald Ihnen ein repräsentatives Stichprobe für das Abrufen von Images durch Ihre Builds zur Verfügung steht, führen Sie eine Abfrage für die Abrufhäufigkeit aus.
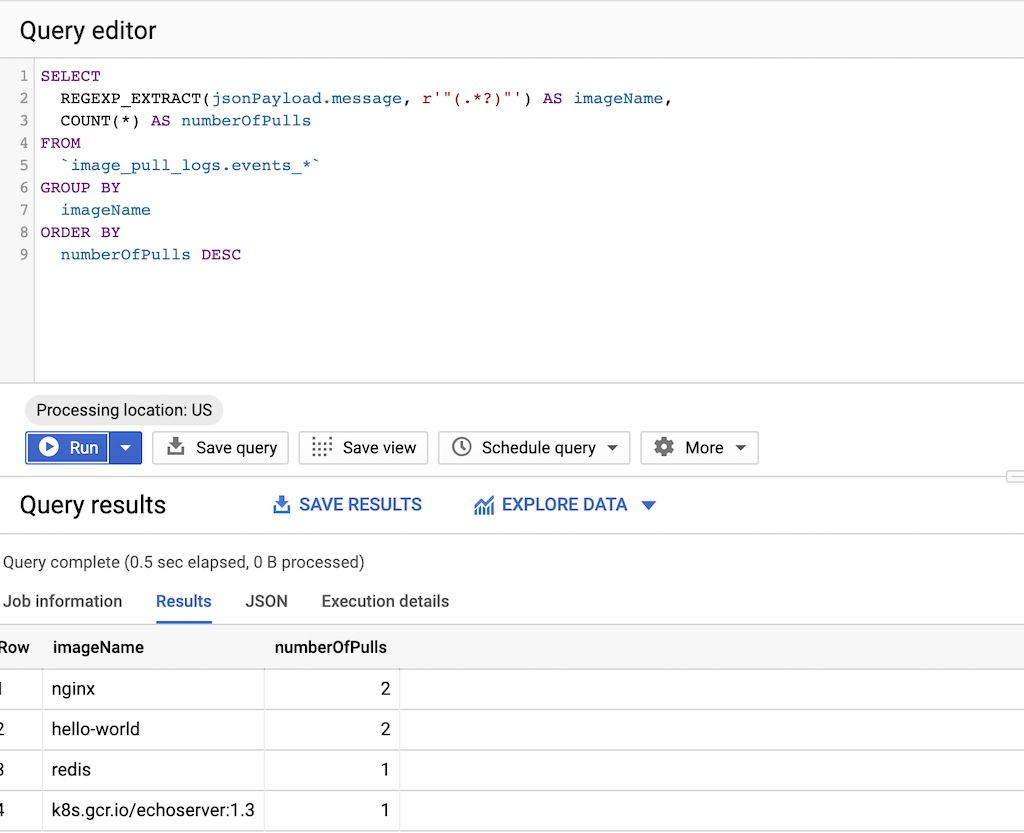
Führen Sie die folgende Abfrage aus:
SELECT REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName, COUNT(*) AS numberOfPulls FROM `DATASET-PROJECT.DATASET-NAME.events_*` GROUP BY imageName ORDER BY numberOfPulls DESCWobei Folgendes gilt:
- DATASET-PROJECT ist das Projekt, das Ihr Dataset enthält.
- DATASET-NAME ist der Name des Datasets.
Das folgende Beispiel zeigt die Ausgabe der Abfrage. In der Spalte imageName können Sie prüfen, wie häufig Images abgerufen werden, die nicht in Artifact Registry oder Container Registry gespeichert sind.
Images nach Artifact Registry kopieren
Nachdem Sie Images von Drittanbieter-Registrys ermittelt haben, können Sie diese nach Artifact Registry kopieren. Das gcrane-Tool bietet eine Unterstützung für den Kopiervorgang.
Erstellen Sie in Cloud Shell die Textdatei
images.txtmit den Namen der ermittelten Images. Beispiel:ubuntu:18.04 debian:buster hello-world:latest redis:buster jupyter/tensorflow-notebookLaden Sie gcrane herunter.
GO111MODULE=on go get github.com/google/go-containerregistry/cmd/gcraneErstellen Sie ein Skript mit dem Namen
copy_images.sh, um die Liste Ihrer Dateien zu kopieren.#!/bin/bash images=$(cat images.txt) if [ -z "${AR_PROJECT}" ] then echo ERROR: AR_PROJECT must be set before running this exit 1 fi for img in ${images} do gcrane cp ${img} LOCATION-docker.pkg.dev/${AR_PROJECT}/${img} doneErsetzen Sie dabei LOCATION durch die Region oder Mehrfachregion des Repositorys.
Machen Sie das Skript ausführbar:
chmod +x copy_images.shFühren Sie das Skript aus, um die Dateien zu kopieren:
AR_PROJECT=${PROJECT} ./copy_images.sh
Berechtigungen prüfen
Standardmäßig haben Google Cloud-CI/CD-Dienste Zugriff auf Artifact Registry im selben Google Cloud-Projekt.
- Mit Cloud Build können Images übertragen und abgerufen werden.
- Mit Laufzeitumgebungen wie GKE, Cloud Run, die flexible App Engine-Umgebung und Compute Engine können Images abgerufen werden.
Wenn Sie Images projektübergreifend übertragen oder abrufen müssen oder wenn Sie Tools von Drittanbietern in Ihrer Pipeline verwenden, die auf Artifact Registry zugreifen müssen, prüfen Sie vor dem Aktualisieren und nochmaligen Bereitstellen Ihrer Arbeitslasten, ob die Berechtigungen korrekt konfiguriert sind.
Weitere Informationen finden Sie in der Dokumentation zur Zugriffssteuerung.
Manifeste zum Verweis auf Artifact Registry aktualisieren
Aktualisieren Sie die Dockerfiles und Manifeste, damit sie nicht auf die Registry von Drittanbietern, sondern auf Artifact Registry verweisen.
Das folgende Beispiel zeigt ein Manifest, das auf die Registry eines Drittanbieters verweist:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Die aktualisierte Version dieses Manifests verweist auf ein Image in us-docker.pkg.dev:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: us-docker.pkg.dev/<AR_PROJECT>/nginx:1.14.2
ports:
- containerPort: 80
Für eine große Anzahl an Manifesten verwenden Sie sed oder ein anderes Tool, mit dem sich die Aktualisierung vieler Textdateien verarbeiten lässt.
Arbeitslasten noch einmal bereitstellen
Stellen Sie Arbeitslasten mit aktualisierten Manifesten noch einmal bereit.
Führen Sie die folgende Abfrage in der BigQuery-Konsole aus, um den Überblick über neue Imageabrufe zu behalten:
SELECT`
FORMAT_TIMESTAMP("%D %R", timestamp) as timeOfImagePull,
REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName,
COUNT(*) AS numberOfPulls
FROM
`image_pull_logs.events_*`
GROUP BY
timeOfImagePull,
imageName
ORDER BY
timeOfImagePull DESC,
numberOfPulls DESC
Das Abrufen neuer Images sollte immer aus Artifact Registry erfolgen und den String docker.pkg.dev enthalten.