本教程演示了如何使用 Cloud Functions 将新对象从 Cloud Storage 存储桶流式插入到 BigQuery。 Cloud Functions 是一个 Google Cloud 事件驱动的无服务器计算平台,此平台提供自动扩缩、高可用性和容错能力,无需使用服务器来预配、管理、更新或修补。通过 Cloud Functions 流式传输数据,可让您连接和扩展其他 Google Cloud 服务,而且只需在应用运行时付费。
本文适用于需要对添加到 Cloud Storage 的文件进行近于实时的分析的数据分析师、开发人员或运维人员。本文假设您熟悉 Linux、Cloud Storage 和 BigQuery。
架构
以下架构图说明了本教程的流式传输流水线的所有组件和整个流程。不过,此流水线预设您会将 JSON 文件上传到 Cloud Storage 中,如果要支持其他文件格式,还需要对代码进行少量更改。本文未介绍其他文件格式的提取。

在上图中,流水线包含以下步骤:
- 将 JSON 文件上传到
FILES_SOURCECloud Storage 存储桶。 - 此事件会触发
streamingCloud Functions 函数。 - 系统解析数据并将其插入到 BigQuery 中。
- 系统会将提取状态记录到 Firestore 和 Cloud Logging 中。
- 消息会发布到以下 Pub/Sub 主题之一:
streaming_success_topicstreaming_error_topic
- 根据结果,Cloud Functions 将 JSON 文件从
FILES_SOURCE存储桶移动到以下存储桶之一:FILES_ERRORFILES_SUCCESS
目标
- 创建 Cloud Storage 存储桶以存储 JSON 文件。
- 创建 BigQuery 数据集和表以将数据流式传输到其中。
- 配置 Cloud Functions 函数,使其在有文件添加到存储桶时触发。
- 设置 Pub/Sub 主题。
- 配置其他函数来处理函数输出。
- 测试您的流式传输流水线。
- 配置 Cloud Monitoring 以针对任何意外行为发出提醒。
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
- Cloud Storage
- Cloud Functions
- Firestore
- BigQuery
- Logging
- Monitoring
- Container Registry
- Cloud Build
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
- 在 Google Cloud 控制台中,转到 Monitoring。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
设置您的环境
在本教程中,您将使用 Cloud Shell 输入命令。Cloud Shell 让您能够使用 Google Cloud 控制台中的命令行,并包含在 Google Cloud 中进行开发所需的 Google Cloud CLI 和其他工具。Cloud Shell 显示为 Google Cloud 控制台底部的一个窗口。初始化可能需要几分钟,但窗口会立即显示。
如需使用 Cloud Shell 设置环境并克隆本教程中使用的 git 代码库,请执行以下操作:
在 Google Cloud Console 中,打开 Cloud Shell。
确保您正在使用刚刚创建的项目。将
[YOUR_PROJECT_ID]替换为您刚创建的 Google Cloud 项目。gcloud config set project [YOUR_PROJECT_ID]设置默认计算区域。在本教程中,计算区域为
us-east1。如果要部署到生产环境,请部署到您选择的地区。REGION=us-east1克隆包含本教程中使用的函数的代码库。
git clone https://github.com/GoogleCloudPlatform/solutions-gcs-bq-streaming-functions-python cd solutions-gcs-bq-streaming-functions-python
创建流式传输来源和目标接收器
如需将内容流式插入 BigQuery,您需要有一个 FILES_SOURCE Cloud Storage 存储桶和一个 BigQuery 中的目标表。
创建 Cloud Storage 存储桶
创建一个 Cloud Storage 存储桶,用作本教程中介绍的流式传输流水线的来源。此存储桶的主要目的是临时存储流式插入 BigQuery 的 JSON 文件。
创建您的
FILES_SOURCECloud Storage 存储分区,其中FILES_SOURCE设为具有唯一名称的环境变量。FILES_SOURCE=${DEVSHELL_PROJECT_ID}-files-source-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_SOURCE}
创建 BigQuery 表
本部分创建用作文件的内容目的地的 BigQuery 表。BigQuery 允许您在将数据加载到表中或创建新表时指定表架构。 在本部分中,您将创建表并同时指定其架构。
创建 BigQuery 数据集和表。
schema.json文件中定义的架构必须与来自FILES_SOURCE存储桶的文件的架构匹配。bq mk mydataset bq mk mydataset.mytable schema.json验证表是否已创建。
bq ls --format=pretty mydataset输出为:
+---------+-------+--------+-------------------+ | tableId | Type | Labels | Time Partitioning | +---------+-------+--------+-------------------+ | mytable | TABLE | | | +---------+-------+--------+-------------------+
将数据流式插入 BigQuery
现在您已创建源和目标接收器,您可以创建 Cloud Functions 函数以将数据从 Cloud Storage 流式插入到 BigQuery。
设置流式传输 Cloud Functions 函数
流式传输函数侦听添加到 FILES_SOURCE 存储桶的新文件,然后触发执行以下操作的过程:
- 解析并验证文件。
- 检查是否有重复。
- 将文件的内容插入 BigQuery。
- 在 Firestore 和 Logging 中记录提取状态。
- 将消息发布到 Pub/Sub 中的错误或成功主题。
如需部署函数,请执行以下操作:
创建一个 Cloud Storage 存储桶以在部署期间暂存函数,其中
FUNCTIONS_BUCKET设为具有唯一名称的环境变量。FUNCTIONS_BUCKET=${DEVSHELL_PROJECT_ID}-functions-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FUNCTIONS_BUCKET}部署
streaming函数。实现代码位于./functions/streaming文件夹中。该过程可能需要几分钟时间才能完成。gcloud functions deploy streaming --region=${REGION} \ --source=./functions/streaming --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-bucket=${FILES_SOURCE}此代码部署了一个用 Python 编写的 Cloud Functions 函数,该函数名为
streaming。只要将文件添加到FILES_SOURCE存储桶,就会触发该函数。验证该函数已经部署。
gcloud functions describe streaming --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"输出为:
┌────────────────┬────────┬────────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├────────────────┼────────┼────────────────────────────────┤ │ streaming │ ACTIVE │ google.storage.object.finalize │ └────────────────┴────────┴────────────────────────────────┘
预配名为
streaming_error_topic的 Pub/Sub 主题来处理错误路径。STREAMING_ERROR_TOPIC=streaming_error_topic gcloud pubsub topics create ${STREAMING_ERROR_TOPIC}预配名为
streaming_success_topic的 Pub/Sub 主题以处理成功路径。STREAMING_SUCCESS_TOPIC=streaming_success_topic gcloud pubsub topics create ${STREAMING_SUCCESS_TOPIC}
设置您的 Firestore 数据库
当数据流式插入到 BigQuery 时,务必要了解每次提取文件时发生的情况。例如,假设您有未正确导入的文件。在这种情况下,您需要找出问题的根本原因并加以解决,以免在流水线结束时生成损坏的数据和不准确的报告。上一部分中部署的 streaming 函数将文件提取状态存储在 Firestore 文档中,以便您可以查询最近的错误,排查任何存在的问题。
如需创建 Firestore 实例,请按照下列步骤操作:
在 Google Cloud Console 中,转到 Firestore。
在选择 Cloud Firestore 模式窗口中,点击选择原生模式。
在选择位置列表中,选择 nam5(美国),然后点击创建数据库。等待 Firestore 完成初始化。这通常需要几分钟时间。
处理流式传输错误
如需预配处理错误文件的路径,请部署另一个 Cloud Functions 函数,用于侦听发布到 streaming_error_topic 的消息。您的业务需求决定了您在生产环境中处理此类错误的方式。
在本教程中,有问题的文件将移动到另一个 Cloud Storage 存储桶,以方便排查。
创建 Cloud Storage 存储桶以存储有问题的文件。
FILES_ERROR设为具有唯一名称的环境变量,用于存储错误文件的存储桶。FILES_ERROR=${DEVSHELL_PROJECT_ID}-files-error-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_ERROR}部署
streaming_error函数来处理错误。这可能需要几分钟时间。gcloud functions deploy streaming_error --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_ERROR_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_ERROR}此命令与部署
streaming函数的命令类似。其主要区别在于,此命令中的函数由发布到主题的消息触发,它会接收两个环境变量:SOURCE_BUCKET变量(从该变量复制文件)和DESTINATION_BUCKET变量(文件被复制到该变量)。验证
streaming_error函数已经创建。gcloud functions describe streaming_error --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"输出为:
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
处理成功的流式传输
如需预配处理成功文件的路径,请部署第三个 Cloud Functions 函数,用于侦听发布到 streaming_success_topic 的消息。在本教程中,成功提取的文件归档在 Coldline Cloud Storage 存储桶中。
创建 Coldline Cloud Storage 存储桶。
FILES_SUCCESS设为具有唯一名称的环境变量,用于存储错误文件的存储桶。FILES_SUCCESS=${DEVSHELL_PROJECT_ID}-files-success-$(date +%s) gsutil mb -c coldline -l ${REGION} gs://${FILES_SUCCESS}部署
streaming_success函数以处理成功。这可能需要几分钟时间。gcloud functions deploy streaming_success --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_SUCCESS_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_SUCCESS}验证该函数已经部署。
gcloud functions describe streaming_success --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"输出为:
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
测试您的流式传输流水线
现在您已完成流式传输流水线的创建工作,可以测试不同的路径了。首先测试新文件的提取,然后测试重复文件的提取,最后测试有问题的文件的提取。
提取新文件
如需测试新文件的提取,请上传一个必须成功通过整个流水线的文件。为了确保一切正常,您需要检查所有存储部分:BigQuery、Firestore 和 Cloud Storage 存储桶。
将
data.json文件上传到FILES_SOURCE存储桶。gsutil cp test_files/data.json gs://${FILES_SOURCE}输出:
Operation completed over 1 objects/312.0 B.
在 BigQuery 中查询您的数据。
bq query 'select first_name, last_name, dob from mydataset.mytable'此命令会输出
data.json文件的内容:+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
在 Google Cloud Console 中,前往 Firestore 页面。
转到 / > streaming_files > data.json 文档,以验证是否存在 success: true 字段。
streaming函数将文件的状态存储在名为 streaming_files 的集合中,并将文件名用作文档 ID。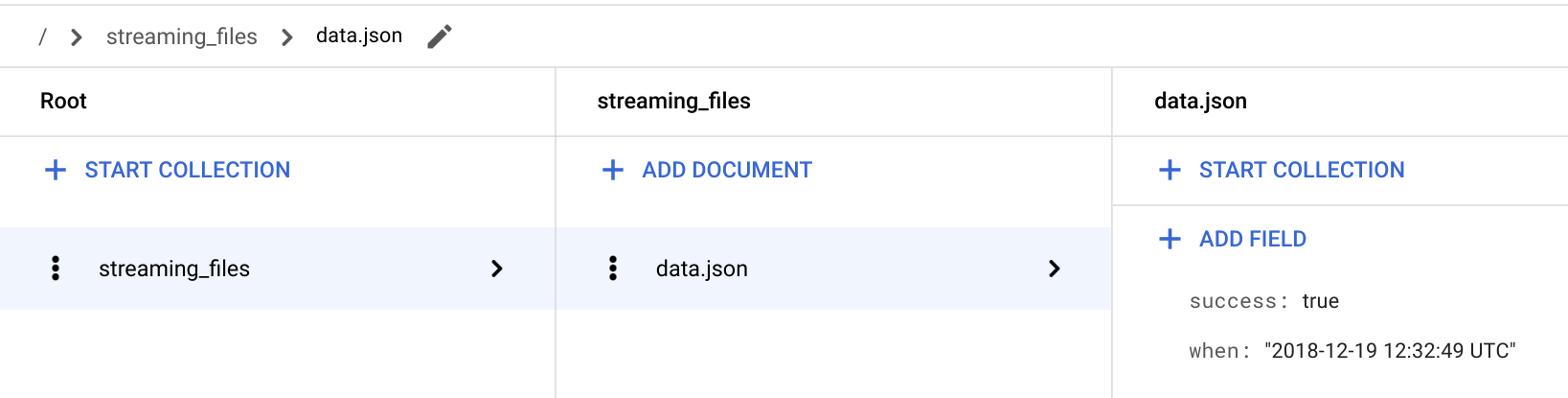
返回到 Cloud Shell。
验证
streaming_success函数是否已从FILES_SOURCE存储桶中移除已提取的文件。gsutil ls -l gs://${FILES_SOURCE}/data.json输出为
CommandException,因为文件不再存在于FILES_SOURCE存储桶中。验证所提取的文件现在是否位于
FILES_SUCCESS存储桶中。gsutil ls -l gs://${FILES_SUCCESS}/data.json输出为:
TOTAL: 1 objects, 312 bytes.
提取已处理的文件
文件名在 Firestore 中用作文档 ID。这使得 streaming 函数可以轻松查询给定文件是否已处理。如果先前已成功提取文件,系统会忽略添加该文件的任何新尝试,因为它会在 BigQuery 中生成重复的信息,导致报告不准确。
在本部分中,您将验证在将重复文件上传到 FILES_SOURCE 存储桶时流水线是否按预期工作。
将同一个
data.json文件再次上传到FILES_SOURCE存储桶。gsutil cp test_files/data.json gs://${FILES_SOURCE}输出为:
Operation completed over 1 objects/312.0 B.
查询 BigQuery 会返回与以前相同的结果。 这意味着流水线处理了该文件,但它没有将文件内容插入到 BigQuery 中,因为该文件之前已提取。
bq query 'select first_name, last_name, dob from mydataset.mytable'输出如下:
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
在 Google Cloud 控制台中,转到 Firestore 页面。
在 / > streaming_files > data.json 文档中,验证是否已添加新的
**duplication_attempts**字段。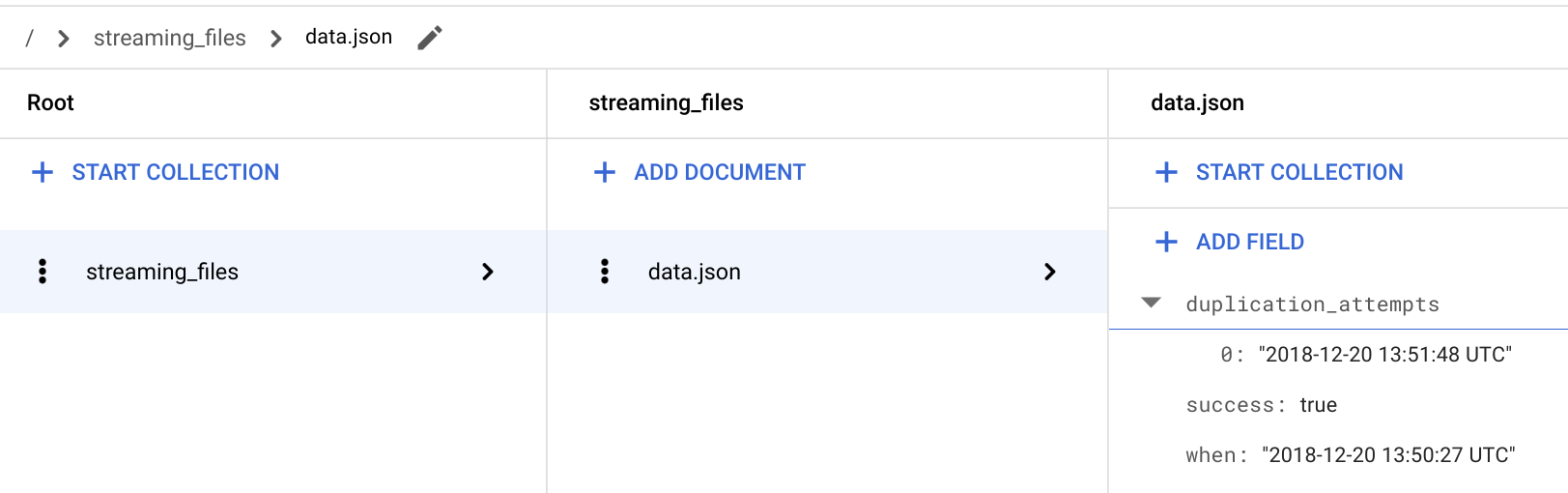
每次将文件添加到与之前成功处理的具有相同名称的
FILES_SOURCE存储桶时,系统都会忽略该文件的内容,并在 Cloud Firestore 中的**duplication_attempts**字段附加新的重复尝试。返回到 Cloud Shell。
验证重复文件是否仍在
FILES_SOURCE存储桶中。gsutil ls -l gs://${FILES_SOURCE}/data.json输出为:
TOTAL: 1 objects, 312 bytes.
在重复场景中,
streaming函数会在 Logging 中记录意外行为,忽略提取操作,并将文件留在FILES_SOURCE存储桶中以供以后分析。
提取存在错误的文件
现在您已确认流式传输流水线正在工作,并且未将重复内容提取到 BigQuery 中,下面可以检查错误路径。
将
data_error.json上传到FILES_SOURCE存储桶。gsutil cp test_files/data_error.json gs://${FILES_SOURCE}输出为:
Operation completed over 1 objects/311.0 B.
查询 BigQuery 会返回与以前相同的结果。 这意味着流水线处理了该文件,但它没有将文件内容插入到 BigQuery 中,因为该文件不符合预期的架构。
bq query 'select first_name, last_name, dob from mydataset.mytable'输出如下:
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
在 Google Cloud Console 中,前往 Firestore 页面。
在 / > streaming_files > data_error.json 文档中,验证已添加 success: false 字段。
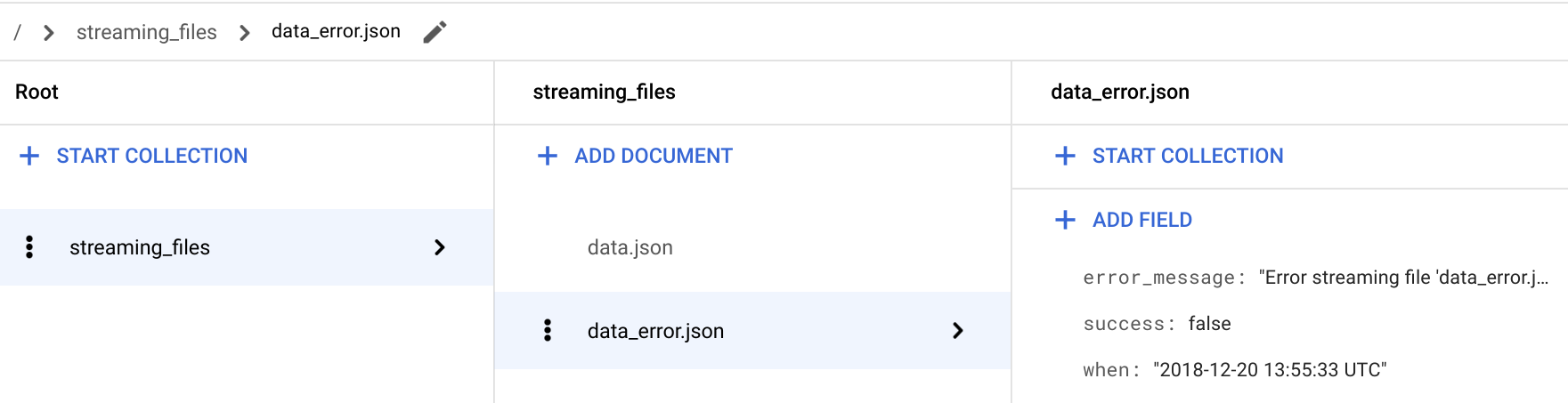
对于存在错误的文件,
streaming函数还会存储error_message字段,该字段为您提供有关文件未被提取的详细信息。返回到 Cloud Shell。
验证
streaming_error函数是否已从FILES_SOURCE存储桶中移除该文件。gsutil ls -l gs://${FILES_SOURCE}/data_error.json输出为
CommandException,因为文件不再存在于FILES_SOURCE存储桶中。验证文件现在按预期位于
FILES_ERROR存储桶中。gsutil ls -l gs://${FILES_ERROR}/data_error.json输出为:
TOTAL: 1 objects, 311 bytes.
找到并解决数据提取问题
通过在 Firestore 中对 streaming_files 集合运行查询,可以快速诊断和修复问题。在本部分中,您将使用适用于 Firestore 的标准 Python API 过滤所有错误文件。
如需在您的环境中查看查询结果,请执行以下操作:
在
firestore文件夹中创建虚拟环境。pip install virtualenv virtualenv firestore source firestore/bin/activate在虚拟环境中安装 Python Firestore 模块。
pip install google-cloud-firestore呈现现有的流水线问题。
python firestore/show_streaming_errors.pyshow_streaming_errors.py文件包含 Firestore 查询和其他样板,用于循环结果和格式化输出。运行上述命令后,输出类似于以下内容:+-----------------+-------------------------+----------------------------------------------------------------------------------+ | File Name | When | Error Message | +-----------------+-------------------------+----------------------------------------------------------------------------------+ | data_error.json | 2019-01-22 11:31:58 UTC | Error streaming file 'data_error.json'. Cause: Traceback (most recent call las.. | +-----------------+-------------------------+----------------------------------------------------------------------------------+
完成分析后,停用虚拟环境。
deactivate找到并解决有问题的文件后,再次使用相同的文件名将其上传到
FILES_SOURCE存储桶。此过程会让这些文件通过整个流式传输流水线,以将其内容插入 BigQuery。
有关意外行为的提醒
在生产环境中,务必要监控发生的意外情况并发出提醒。自定义指标是众多 Logging 功能中的一个。通过自定义指标,您可以创建提醒政策,以便在指标满足指定条件时通知您和您的团队。
在本部分中,您将 Monitoring 配置为在文件提取失败时发送电子邮件提醒。为了识别失败的提取,以下配置使用默认的 Python logging.error(..) 消息。
在 Google Cloud 控制台中,转到“基于日志的指标”页面。
点击创建指标。
在过滤列表中,选择转换为高级过滤器。
在高级过滤器中,粘贴以下配置。
resource.type="cloud_function" resource.labels.function_name="streaming" resource.labels.region="us-east1" "Error streaming file "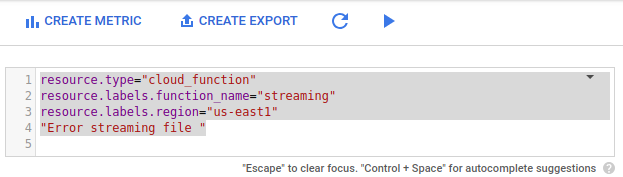
在指标编辑器中,填写以下字段,然后点击创建指标。
- 在名称字段中,输入
streaming-error。 - 在标签部分的名称字段中输入
payload_error。 - 在标签类型列表中,选择字符串。
- 在字段名称列表中,选择 textPayload。
- 在提取正则表达式字段中,输入
(Error streaming file '.*'.)。 在类型列表中,选择计数器。
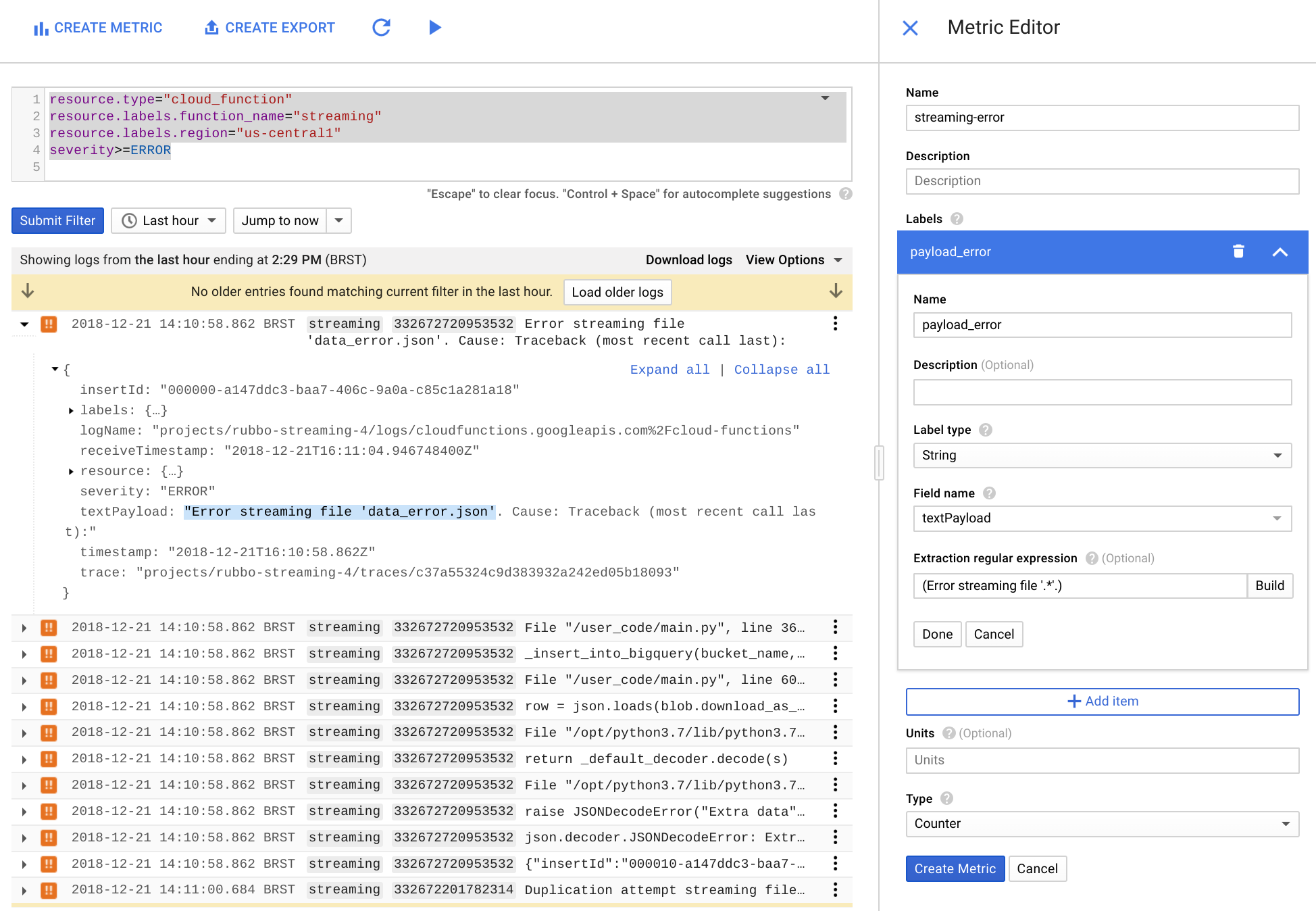
- 在名称字段中,输入
在 Google Cloud Console 中,转到 Monitoring 或使用以下按钮:
在 Monitoring 导航窗格中,选择 notifications 提醒,然后选择创建政策。
在为此政策命名字段中,输入
streaming-error-alert。点击添加条件:
- 在标题字段中,输入
streaming-error-condition。 - 在指标字段中,输入
logging/user/streaming-error。 - 在发生以下情况时触发条件列表中,选择任何违反时间序列的情况。
- 在条件列表中,选择超过。
- 在阈值字段中,输入
0。 - 在时限列表中,选择 1 分钟。
- 在标题字段中,输入
在通知渠道类型列表中,选择电子邮件,输入您的电子邮件地址,然后点击添加通知渠道。
(可选)点击文档并添加您希望包含在通知消息中的任何信息。
点击保存。
保存提醒政策后,Monitoring 会以每分钟一次的间隔监视 streaming 函数错误日志,并在出现流式传输错误时发送电子邮件提醒。
清除数据
为避免因本教程中使用的资源导致您的 Google Cloud 帐号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 查看事件和触发器,了解在 Google Cloud 中触发无服务器函数的其他方法。
- 访问提醒页面,了解如何改进本教程中定义的提醒政策。
- 访问 Firestore 文档,详细了解这种全球规模的 NoSQL 数据库。
- 访问 BigQuery 配额和限制页面,了解在生产环境中实现此解决方案时的流式插入限制。
- 访问 Cloud Functions 配额和限制页面,了解部署的函数能够处理的大小上限。
- 探索有关 Google Cloud 的参考架构、图表、教程和最佳做法。查看我们的 Cloud Architecture Center。