本教程介绍如何运行自动 Dataflow 流水线,以对为个人身份信息数据集创建 DLP 去标识化转换模板教程中使用的示例数据集进行去标识化。该示例数据集包含大规模的个人身份信息 (PII)。
本文档是以下系列文章中的一篇:
- 使用 Cloud DLP 对大规模数据集中的个人身份信息进行去标识化和重标识处理
- 为个人身份信息数据集创建 Cloud DLP 去标识化转换模板
- 运行自动 Dataflow 流水线以对个人身份信息数据集进行去标识化(本文)
本教程假定您熟悉 Shell 脚本和 Dataflow 流水线。
参考架构
本教程演示了数据去标识化流水线,如下图所示。

数据去标识化流式处理流水线使用 Dataflow 对文本内容中的敏感数据进行去标识化。您可以将该流水线重复用于多个转换和用例。
目标
- 触发和监控用于对示例数据集进行去标识化的 Dataflow 流水线。
- 了解流水线采用的代码。
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
您可使用价格计算器根据您的预计使用情况来估算费用。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
- 完成本系列教程的第 2 部分。
查看流水线参数
本教程使用通过 Apache Beam Java SDK 开发的 Dataflow 流水线。为了不断大规模地解决常见的数据相关任务,Dataflow 提供了一个框架,称为 Google 提供的模板。如果您使用这些模板,则无需编写或维护任何流水线代码。在本教程中,您需要使用以下参数触发自动的 data masking/tokenization using Cloud DLP from Cloud Storage to BigQuery 流水线。
| 流水线参数 | 值 | 备注 |
|---|---|---|
numWorkers
|
5 | 默认设置 |
maxNumWorkers
|
10 | |
machineType
|
n1-standard-4
|
|
pollingInterval
|
30 秒 | |
windowInterval
|
30 秒 | |
inputFilePattern
|
gs://${DATA_STORAGE_BUCKET}/CCRecords_*.csv
|
在本教程的第 2 部分中创建。 |
deidentifyTemplateName
|
${DEID_TEMPLATE_NAME}
|
|
inspectTemplateName
|
${INSPECT_TEMPLATE_NAME}
|
|
datasetName
|
deid_dataset
|
|
batchSize
|
500
|
对于批次大小为 500、总数为 10 万的记录,有 200 个并行 API 调用。默认情况下,批次大小设置为 100。
|
dlpProjectName
|
${PROJECT_ID}
|
本教程使用您的默认 Google Cloud 项目。 |
jobId
|
my-deid-job
|
Dataflow 的作业 ID |
运行流水线
在 Cloud Shell 中,设置应用默认凭据。
gcloud auth activate-service-account \ ${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --key-file=service-account-key.json --project=${PROJECT_ID} export GOOGLE_APPLICATION_CREDENTIALS=service-account-key.json运行流水线:
export JOB_ID=my-deid-job gcloud dataflow jobs run ${JOB_ID} \ --gcs-location gs://dataflow-templates/latest/Stream_DLP_GCS_Text_to_BigQuery \ --region ${REGION} \ --parameters \ "inputFilePattern=gs://${DATA_STORAGE_BUCKET}/CCRecords_1564602825.csv,dlpProjectId=${PROJECT_ID},deidentifyTemplateName=${DEID_TEMPLATE_NAME},inspectTemplateName=${INSPECT_TEMPLATE_NAME},datasetName=deid_dataset,batchSize=500"要监控流水线,请在 Google Cloud Console 中前往 Dataflow 页面。
点击作业 ID (
my-deid-job),您会看到作业图: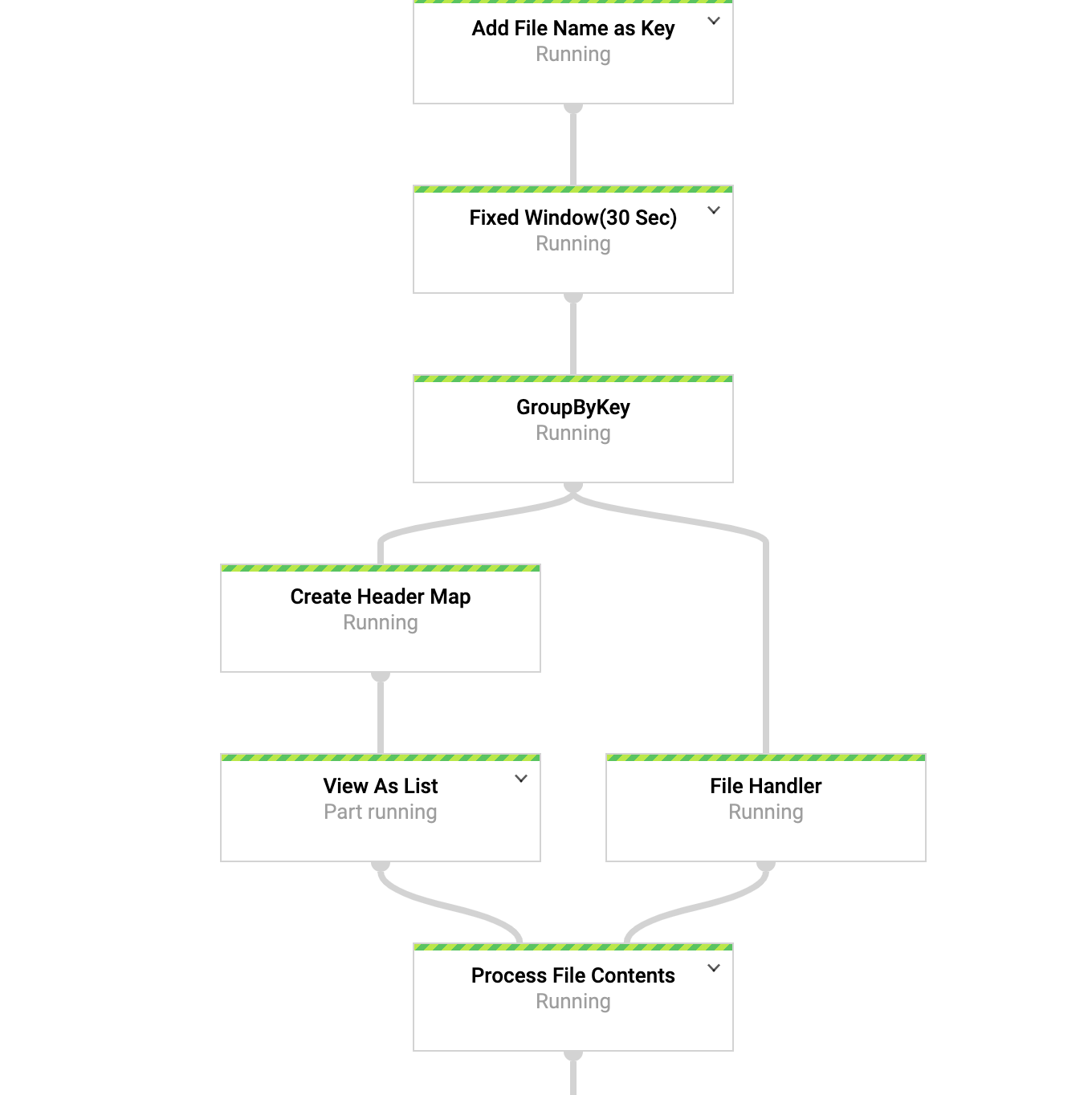
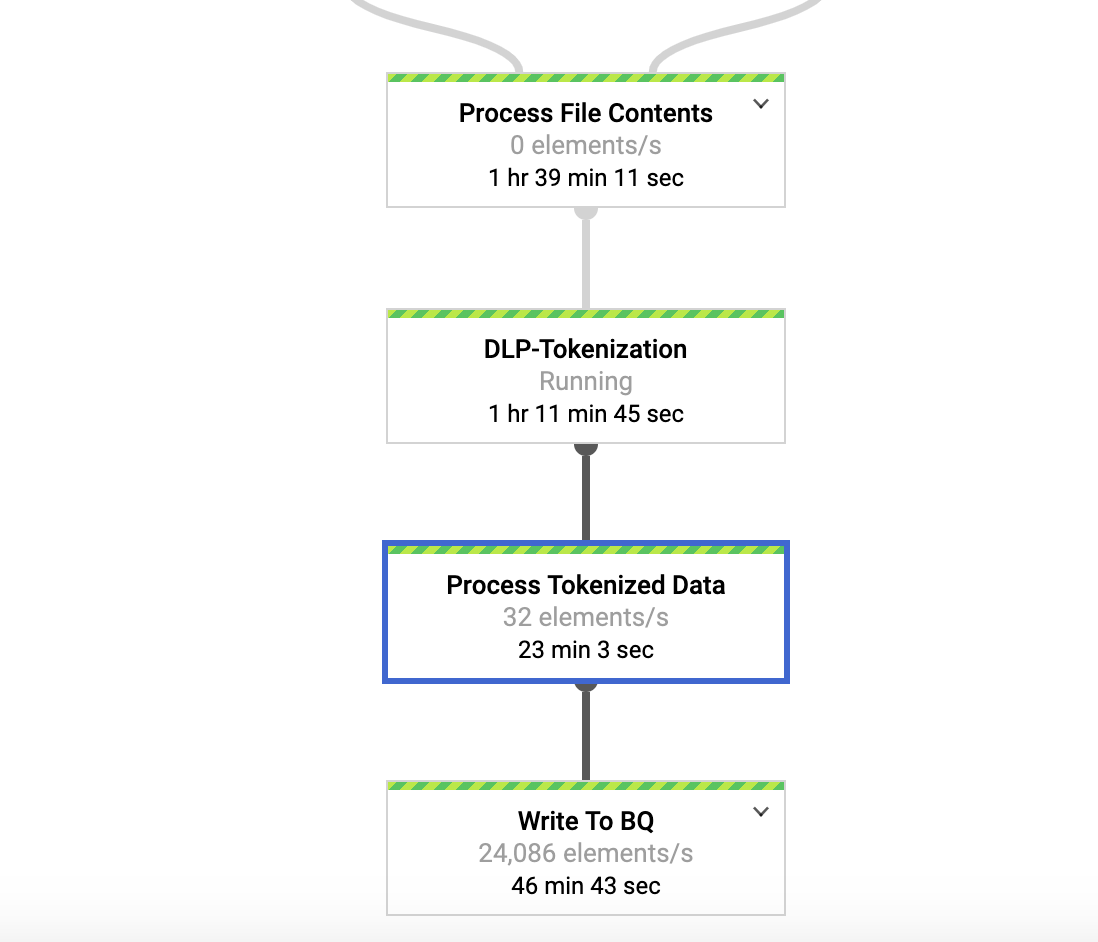
要验证流水线处理的数据量,请点击处理经过标记化的数据 (Process Tokenized Data)。
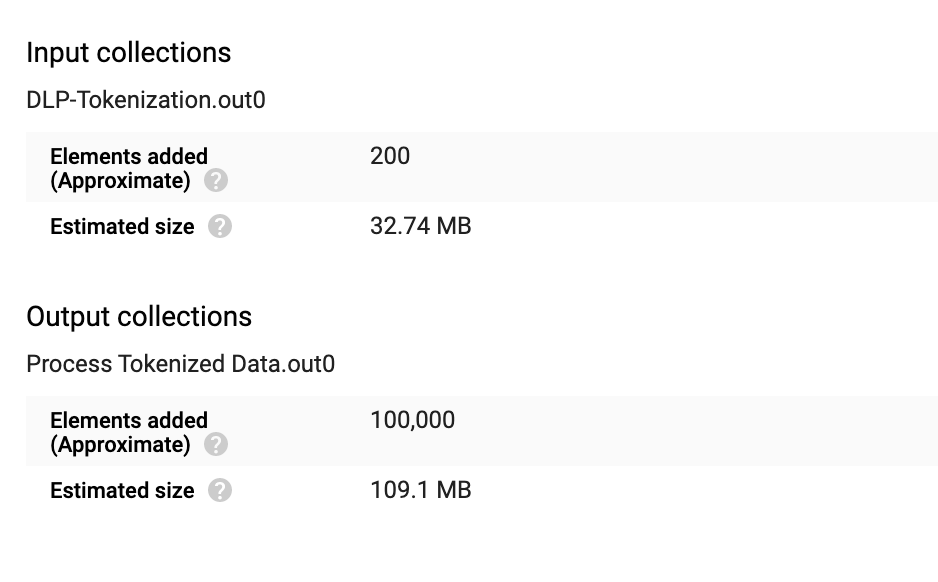
为 DLP-Tokenization 转换添加的元素数量为 200,为 Process Tokenized Data 转换添加的元素数量为 100000。
要验证在 BigQuery 表中插入的记录总数,请点击
Write To BQ。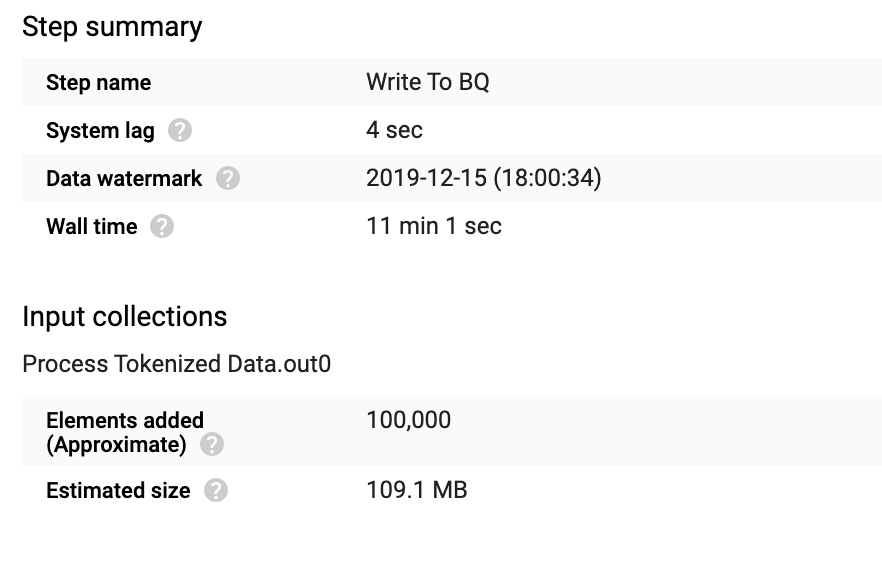
为 Process Tokenized Data 转换添加的元素数量为 100000。
处理流水线中的异常
DLP API 的默认上限为每分钟 600 次 API 调用。 流水线根据您指定的批次大小并行处理请求。
流水线配置为最多具有十个 n1-standard-4 工作器。
如果您需要比 Google 提供的模板的默认配置更快地处理大型数据集,可以自定义流水线以更新工作器数量和机器类型。如果增加工作器数量,则可能需要增加 vCPU、正在使用的 IP 地址以及 Cloud 项目的 SSD 的数量的默认配额。
查看流水线代码
完整的流水线代码位于 GitHub 代码库中。
此流水线使用内置的 Beam File IO 转换,每 30 秒轮询一次为该流水线的自动化版本配置的新文件。在停止或终止该流水线之前,该流水线会不断查找新文件。
可读文件可以包含相同的标头。流水线使用称为侧边输入的设计模式,而不是为每个元素都创建标头。只能为窗口创建一次标头,标头作为输入传递到其他转换。
Cloud DLP 的载荷大小上限为:每个 API 请求 512 KB 和每分钟 600 次并行 API 调用。为了管理此限制,流水线使用用户定义的批次大小作为参数。例如,示例数据集有 50 万行。批次大小为 1000 表示,假设每个请求不超过载荷大小上限,并行进行 500 次 DLP API 调用。批次大小越小,API 调用次数就越多。此批次大小可能会导致
quota resource exception。如果您需要提高配额限制,请参阅增加配额。流水线使用内置的 BigQuery IO 转换连接器写入 BigQuery。此连接器使用动态目标功能自动创建 BigQuery 表和架构。为了实现低延迟,流水线还使用了 BigQuery 流式插入。
您已成功完成本教程。您已触发使用 Cloud DLP 模板的自动去标识化流水线来处理大型数据集。
清理
若要避免产生费用,最简单的方法是删除您为本教程创建的 Cloud 项目。或者,您也可以删除各个资源。
删除项目
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
后续步骤
- 为个人身份信息数据集创建 Cloud DLP 去标识化转换模板。
- 使用 Cloud DLP 对大规模数据集中的个人身份信息进行去标识化和重标识处理。
- 查看 GitHub 上使用 Dataflow 和 Cloud DLP 迁移 BigQuery 中的敏感数据代码库中的示例代码。
- 了解其他模式识别解决方案。
- 探索有关 Google Cloud 的参考架构、图表、教程和最佳做法。查看我们的云架构中心。