Migration d'Amazon Redshift vers BigQuery : présentation
Ce document fournit des conseils sur la migration d'Amazon Redshift vers BigQuery, en se concentrant sur les sujets suivants :
- Stratégies de migration
- Bonnes pratiques pour l'optimisation des requêtes et la modélisation des données
- Conseils de dépannage
- Conseils pour l'adoption par l'utilisateur
Les objectifs de ce document sont les suivants :
- Donner des conseils généraux aux entreprises qui migrent d'Amazon Redshift vers BigQuery, y compris vous aider à repenser vos pipelines de données existants afin de tirer le meilleur parti de BigQuery.
- Vous aider à comparer les architectures de BigQuery et d'Amazon Redshift afin de déterminer comment implémenter les fonctionnalités et les capacités existantes pendant la migration. Notre but est de vous présenter les nouvelles fonctionnalités auxquelles votre entreprise peut accéder grâce à BigQuery, et non de mettre en regard une à une les fonctionnalités de BigQuery avec celles de Redshift.
Ce document est destiné aux architectes d'entreprise, aux administrateurs de bases de données, aux développeurs d'applications et aux spécialistes de la sécurité informatique. Nous partons du principe que vous connaissez bien Amazon Redshift.
Vous pouvez également utiliser la traduction SQL par lot pour migrer vos scripts SQL de façon groupée, ou la traduction SQL interactive pour traduire des requêtes ad hoc. Amazon Redshift SQL est entièrement compatible avec les deux services de traduction SQL.
Tâches préalables à la migration
Pour garantir la réussite de la migration de l'entrepôt de données, commencez par planifier votre stratégie de migration dès le début de votre projet. Cette approche vous permet d'évaluer les fonctionnalités Google Cloud qui répondent à vos besoins.
Planification des capacités
BigQuery utilise des emplacements pour mesurer le débit des analyses. Un emplacement BigQuery est l'unité propriétaire de Google de la capacité de calcul nécessaire à l'exécution de requêtes SQL. BigQuery calcule en continu le nombre d'emplacements requis par les requêtes au fur et à mesure de leur exécution, mais il alloue ces emplacements à des requêtes en fonction d'un programmeur équitable.
Vous pouvez choisir entre les modèles tarifaires suivants lorsque vous planifiez la capacité des emplacements BigQuery :
- Tarifs à la demande : si vous optez pour la tarification à la demande, BigQuery facture le nombre d'octets traités (taille des données). Vous ne payez donc que pour les requêtes que vous exécutez. Pour plus d'informations sur la manière dont BigQuery détermine la taille des données, consultez la page Calcul de la taille des données. Étant donné que les emplacements déterminent la capacité de calcul sous-jacente, vous pouvez payer l'utilisation de BigQuery en fonction du nombre d'emplacements dont vous avez besoin (au lieu du nombre d'octets traités). Par défaut, tous les projets Google Cloud sont limités à 2 000 emplacements maximum. BigQuery peut passer en utilisation intensive au-delà de cette limite pour accélérer vos requêtes, mais l'utilisation intensive n'est pas garantie.
- Tarifs basés sur la capacité Avec la tarification basée sur la capacité, vous achetez des réservations d'emplacements BigQuery (au moins 100) au lieu de payer le nombre d'octets traités par les requêtes que vous exécutez. Nous recommandons les tarifs basés sur la capacité pour les charges de travail des entrepôts de données d'entreprise, qui présentent généralement de nombreuses requêtes simultanées de création de rapports et d'extraction, de chargement et de transformation (ELT, Extract-Load-Transform), dont la consommation est prévisible.
Pour vous aider à estimer les emplacements, nous vous recommandons de configurer la surveillance BigQuery à l'aide de Cloud Monitoring et d'analyser vos journaux d'audit à l'aide de BigQuery. Vous pouvez utiliser Looker Studio (voici un exemple Open Source de tableau de bord Looker Studio) ou Looker pour visualiser les données de journal d'audit de BigQuery, en particulier pour l'utilisation des emplacements entre les requêtes et les projets. Vous pouvez également utiliser les données de tables système de BigQuery pour surveiller l'utilisation des emplacements entre les tâches et les réservations (voir un exemple Open Source de tableau de bord Looker Studio). Surveiller et analyser régulièrement l'utilisation des emplacements vous aide à estimer le nombre total d'emplacements dont votre organisation a besoin à mesure que vous développez sur Google Cloud.
Par exemple, supposons que vous réservez initialement 4 000 emplacements BigQuery pour exécuter simultanément 100 requêtes de complexité moyenne. Si vous remarquez des temps d'attente élevés dans les plans d'exécution de vos requêtes et que vos tableaux de bord indiquent une utilisation des emplacements élevée, cela peut indiquer que vous avez besoin d'emplacements BigQuery supplémentaires pour prendre en charge vos charges de travail. Si vous souhaitez acheter des emplacements vous-même via des engagements annuels ou sur trois ans, vous pouvez commencer à utiliser les réservations BigQuery à l'aide de la console Google Cloud ou de l'outil de ligne de commande bq. Pour en savoir plus sur la gestion des charges de travail, l'exécution de requêtes et l'architecture BigQuery, consultez la page Migration vers Google Cloud : vue détaillée.
Security in Google Cloud
Les sections suivantes décrivent les contrôles de sécurité courants d'Amazon Redshift et expliquent comment vous pouvez vous assurer que votre entrepôt de données reste protégé dans un environnement Google Cloud.
Gestion de l'authentification et des accès
La configuration des contrôles d'accès dans Amazon Redshift implique l'écriture de stratégies d'autorisation d'Amazon Redshift et leur association à des identités IAM (Identity and Access Management). Les autorisations de l'API Amazon Redshift fournissent un accès au niveau du cluster, mais n'offrent pas des niveaux d'accès plus précis que le cluster. Si vous souhaitez obtenir un accès plus précis à des ressources telles que des tables ou des vues, vous pouvez utiliser des comptes utilisateur dans la base de données Amazon Redshift.
BigQuery utilise IAM pour gérer l'accès aux ressources de manière plus précise. Les types de ressources disponibles dans BigQuery sont des organisations, des projets, des ensembles de données, des tables, des colonnes et des vues. Dans la hiérarchie des stratégies IAM, les ensembles de données sont les ressources enfants des projets. Une table hérite des autorisations de l'ensemble de données qui la contient.
Pour accorder l'accès à une ressource, attribuez un ou plusieurs rôles IAM à un utilisateur, un groupe ou un compte de service. Les rôles associés aux organisations et aux projets affectent la capacité à exécuter des tâches ou à gérer le projet, tandis que les rôles associés aux ensembles de données ont une incidence sur l'accès aux données ou leur modification au sein d'un projet.
IAM fournit les types de rôles suivants :
- Les rôles prédéfinis conçus pour des cas d'utilisation courants et des modèles de contrôle des accès.
- Les rôles personnalisés qui fournissent un accès précis en fonction d'une liste d'autorisations spécifiée par l'utilisateur.
Dans IAM, BigQuery fournit un contrôle des accès au niveau de la table. Les autorisations au niveau de la table déterminent les utilisateurs, les groupes et les comptes de service autorisés à accéder à une table ou à une vue. Vous pouvez autoriser un utilisateur à accéder à des tables ou des vues spécifiques, sans lui accorder l'accès à l'ensemble de données entier. Pour un accès plus précis, vous pouvez également implémenter un ou plusieurs des mécanismes de sécurité suivants :
- Le contrôle des accès au niveau des colonnes, qui permet un accès précis aux colonnes sensibles à l'aide de tags avec stratégie, ou à une classification des données basée sur le type.
- Le masquage des données dynamiques au niveau des colonnes, qui vous permet de masquer de manière sélective les données des colonnes pour des groupes d'utilisateurs, tout en autorisant l'accès à la colonne.
- La sécurité au niveau des lignes vous permet de filtrer les données et d'accéder à des lignes spécifiques d'une table, en fonction des conditions éligibles de l'utilisateur.
Chiffrement complet de disque
En plus de la gestion de l'authentification et des accès, le chiffrement des données ajoute une couche de défense supplémentaire pour protéger les données. Dans le cas d'une exposition de données, les données chiffrées ne sont pas lisibles.
Sur Amazon Redshift, le chiffrement des données au repos et des données en transit n'est pas activé par défaut. Le chiffrement des données au repos doit être explicitement activé lors du lancement d'un cluster ou en modifiant un cluster existant de sorte qu'il utilise le chiffrement du service de gestion des clés AWS. Le chiffrement des données en transit doit également être explicitement activé.
Par défaut, BigQuery chiffre toutes les données au repos et en transit, indépendamment de la source ou de toute autre condition, et ce chiffrement ne peut pas être désactivé. BigQuery accepte également les clés de chiffrement gérées par le client (CMEK, Customer-Managed Encryption Key) si vous souhaitez contrôler et gérer les clés de chiffrement de clé dans Cloud Key Management Service.
Pour en savoir plus sur le chiffrement dans Google Cloud, consultez les livres blancs sur le chiffrement des données au repos et le chiffrement des données en transit.
Pour les données en transit sur Google Cloud, les données sont chiffrées et authentifiées lorsqu'elles sont se déplacent en dehors des limites physiques contrôlées par ou pour le compte de Google. À l'intérieur de ces limites, les données en transit sont généralement authentifiées, mais pas nécessairement chiffrées.
Protection contre la perte de données
Les exigences de conformité peuvent limiter les données pouvant être stockées sur Google Cloud. Vous pouvez utiliser la protection des données sensibles pour analyser vos tables BigQuery afin de détecter des données sensibles et de les classifier comme telles. Si des données sensibles sont détectées, les transformations d'anonymisation de la protection des données sensibles peuvent masquer, supprimer ou dissimuler ces données.
Migration vers Google Cloud : principes de base
Reportez-vous à cette page pour en savoir plus sur l'utilisation d'outils et de pipelines pour faciliter la migration.
Outils de migration
Le service de transfert de données BigQuery fournit un outil automatisé pour migrer directement le schéma et les données d'Amazon Redshift vers BigQuery. Le tableau suivant répertorie les outils supplémentaires pour faciliter la migration d'Amazon Redshift vers BigQuery :
| Outil | Objectif |
|---|---|
| Service de transfert de données BigQuery | Effectuez un transfert par lot automatisé de vos données Amazon Redshift vers BigQuery à l'aide de ce service entièrement géré. |
| Service de transfert de stockage | Importez rapidement des données Amazon S3 dans Cloud Storage et configurez un calendrier récurrent de transfert de données à l'aide de ce service entièrement géré. |
gsutil |
Copiez des fichiers Amazon S3 dans Cloud Storage à l'aide de cet outil de ligne de commande. |
| Outil de ligne de commande bq | Interagissez avec BigQuery à l'aide de cet outil de ligne de commande. Les interactions courantes incluent la création de schémas de table BigQuery, le chargement de données Cloud Storage dans des tables, et l'exécution de requêtes. |
| Bibliothèques clientes Cloud Storage | Copiez des fichiers Amazon S3 dans Cloud Storage à l'aide de votre outil personnalisé, basé sur la bibliothèque cliente Cloud Storage. |
| Bibliothèques clientes BigQuery | Interagissez avec BigQuery à l'aide de votre outil personnalisé, intégré à la bibliothèque cliente BigQuery. |
| Programmeur de requêtes BigQuery | Planifiez des requêtes SQL récurrentes à l'aide de cette fonctionnalité BigQuery intégrée. |
| Cloud Composer | Orchestrez les transformations et les tâches de chargement BigQuery à l'aide de cet environnement Apache Airflow entièrement géré. |
| Apache Sqoop | Envoyez des tâches Hadoop à l'aide de Sqoop et du pilote JDBC d'Amazon Redshift pour extraire des données d'Amazon Redshift dans HDFS ou Cloud Storage. Sqoop s'exécute dans un environnement Dataproc. |
Pour en savoir plus sur l'utilisation du service de transfert de données BigQuery, consultez la page Migrer le schéma et les données depuis Amazon Redshift.
Migration à l'aide de pipelines
Votre migration de données d'Amazon Redshift vers BigQuery peut suivre différents chemins en fonction des outils de migration disponibles. Bien que la liste présentée dans cette page ne soit pas exhaustive, elle fournit un aperçu des différents modèles de pipeline de données disponibles lors du déplacement de vos données.
Pour plus d'informations générales sur la migration de données vers BigQuery à l'aide de pipelines, consultez la page Migrer des pipelines de données.
Extraction et chargement (EL)
Vous pouvez automatiser entièrement un pipeline EL à l'aide du service de transfert de données BigQuery, qui peut copier automatiquement les schémas et les données de vos tables depuis votre cluster Amazon Redshift vers BigQuery. Si vous souhaitez mieux contrôler les étapes du pipeline de données, vous pouvez le créer à l'aide des options décrites dans les sections suivantes.
Utiliser les extraits de fichiers Amazon Redshift
- Exportez les données Amazon Redshift vers Amazon S3.
Pour copier des données d'Amazon S3 vers Cloud Storage, utilisez l'une des options suivantes :
- Service de transfert de stockage (recommandé)
gsutil. Voici un exemple.- Bibliothèques clientes Cloud Storage
Chargez des données Cloud Storage dans BigQuery à l'aide de l'une des options suivantes :
Utiliser une connexion JDBC Amazon Redshift
Utilisez l'un des produits Google Cloud suivants pour exporter des données Amazon Redshift à l'aide du pilote JDBC Amazon Redshift :
-
- Modèle fourni par Google : JDBC vers BigQuery
-
Se connecter à Amazon Redshift via JDBC à l'aide d'Apache Spark
Utiliser Sqoop et le pilote JDBC Amazon Redshift pour extraire des données d'Amazon Redshift vers Cloud Storage
Extraction, transformation et chargement (ETL)
Si vous souhaitez transformer certaines données avant de les charger dans BigQuery, suivez les mêmes recommandations de pipeline que celles décrites dans la section Extraction et chargement (EL), en ajoutant une étape pour transformer vos données avant de les charger dans BigQuery.
Utiliser les extraits de fichiers Amazon Redshift
Pour copier des données d'Amazon S3 vers Cloud Storage, utilisez l'une des options suivantes :
- Service de transfert de stockage (recommandé)
gsutil. Voici un exemple.- Bibliothèques clientes Cloud Storage
Transformez, puis chargez vos données dans BigQuery en utilisant l'une des options suivantes :
-
- Lire à partir de Cloud Storage
- Écrire dans BigQuery
- Modèle fourni par Google : Texte Cloud Storage vers BigQuery
Utiliser une connexion JDBC Amazon Redshift
Utilisez l'un des produits décrits dans la section Extraction et chargement (EL) en ajoutant une étape supplémentaire pour transformer vos données avant de les charger dans BigQuery. Modifiez le pipeline afin d'introduire une ou plusieurs étapes pour transformer vos données avant d'écrire dans BigQuery.
-
- Clonez le code du modèle JDBC vers BigQuery, puis modifiez-le pour ajouter des transformations Apache Beam.
-
- Transformez vos données à l'aide de l'un des plug-ins CDAP.
Extraction, chargement et transformation (ELT)
Vous pouvez transformer vos données à l'aide de BigQuery, en utilisant l'une des options EL (Extract and Load) pour charger vos données dans une table de préproduction. Vous transformez ensuite les données de cette table de préproduction à l'aide de requêtes SQL qui écrivent leur sortie dans votre table de production finale.
Capture de données modifiées (CDC)
La capture de données modifiées (Change Data Capture) est l'un des modèles de conception logicielle permettant de suivre les modifications de données. Elle est souvent utilisée dans l'entreposage de données, car l'entrepôt sert à classer et à suivre les données et leurs modifications provenant de divers systèmes sources au fil du temps.
Outils partenaires pour la migration de données
L'espace d'extraction, de transformation et de chargement (ETL) comporte plusieurs fournisseurs. Consultez le site Web des partenaires BigQuery pour obtenir la liste des partenaires clés et les solutions qu'ils fournissent.
Migration vers Google Cloud : vue complète
Cette section vous explique comment l'architecture, le schéma et le dialecte SQL de votre entrepôt de données affectent votre migration.
Comparaison des architectures
BigQuery et Amazon Redshift sont tous deux basés sur une architecture de traitement massivement parallèle (MPP). Les requêtes sont réparties sur plusieurs serveurs pour accélérer leur exécution. En ce qui concerne l'architecture du système, Amazon Redshift et BigQuery diffèrent principalement dans la manière dont les données sont stockées et comment les requêtes sont exécutées. Dans BigQuery, il est fait abstraction du matériel et des configurations sous-jacents ; le stockage et le calcul permettent à votre entrepôt de données de croître sans aucune intervention de votre part.
Calcul, mémoire et stockage
Dans Amazon Redshift, le processeur, la mémoire et le stockage sur disque sont liés via des nœuds de calcul, comme illustré dans ce schéma de la documentation Amazon Redshift. Les performances du cluster et la capacité de stockage sont déterminées par le type et la quantité de nœuds de calcul, qui doivent tous deux être configurés. Pour modifier les ressources de calcul ou de stockage, vous devez redimensionner votre cluster via un processus (s'étalant sur quelques heures, allant jusqu'à deux jours, voire plus longtemps), qui va créer un tout nouveau cluster et y copier les données. Amazon Redshift propose également des nœuds RA3 avec stockage géré qui permettent de séparer le calcul et le stockage. Le nœud le plus volumineux de la catégorie RA3 limite à 64 To l'espace de stockage géré pour chaque nœud.
Au départ, BigQuery ne relie pas le calcul, la mémoire et le stockage, mais traite chacun d'entre eux séparément.
Le calcul BigQuery est défini par des emplacements, une unité de capacité de calcul nécessaire pour exécuter des requêtes. Google gère l'ensemble de l'infrastructure encapsulée dans un emplacement, en éliminant toutes les tâches, sauf le choix de la quantité d'emplacements appropriée pour vos charges de travail BigQuery. Reportez-vous à la planification des capacités pour déterminer le nombre d'emplacements que vous allez acheter pour votre entrepôt de données. La mémoire BigQuery est fournie par un service distribué à distance, connecté aux emplacements de calcul par le réseau de pétaoctets de Google, le tout géré par Google.
BigQuery et Amazon Redshift s'appuient tous deux sur le stockage en colonnes. Cependant, BigQuery fait appel à des variantes et aux avancées du stockage en colonnes. Lors de l'encodage des colonnes, plusieurs statistiques concernant les données sont conservées et utilisées ultérieurement lors de l'exécution de la requête pour compiler des plans optimaux et choisir l'algorithme d'exécution le plus efficace. BigQuery stocke vos données dans le système de fichiers distribué de Google, où elles sont automatiquement compressées, chiffrées, répliquées et distribuées. Tout cela n'affecte pas la puissance de calcul disponible pour vos requêtes. La séparation du stockage et du calcul vous permet de faire évoluer facilement des dizaines de pétaoctets de stockage, sans avoir à payer de ressources de calcul supplémentaires coûteuses. Il existe également d'autres avantages à séparer le calcul et le stockage.
Scaling à la hausse ou à la baisse
Lorsque le stockage ou le calcul deviennent limités, les clusters Amazon Redshift doivent être redimensionnés en modifiant la quantité ou les types de nœuds dans le cluster.
Lorsque vous redimensionnez un cluster Amazon Redshift, vous avez le choix entre deux approches :
- Redimensionnement classique : Amazon Redshift crée un cluster dans lequel les données sont copiées. Ce processus peut prendre quelques heures, voire plus, pour les grandes quantités de données.
- Redimensionnement Elastic : si vous ne modifiez que le nombre de nœuds, les requêtes sont temporairement mises en pause et les connexions sont maintenues dans la mesure du possible. Pendant l'opération de redimensionnement, le cluster est en lecture seule. Le redimensionnement Elastic prend généralement de 10 à 15 minutes, mais peut ne pas être disponible pour toutes les configurations.
Comme BigQuery est une plate-forme PaaS (Platform as a Service), vous n'avez à vous soucier que du nombre d'emplacements BigQuery que vous souhaitez réserver pour votre organisation. Vous réservez des emplacements BigQuery dans des réservations, puis vous attribuez des projets à ces réservations. Pour savoir comment configurer ces réservations, consultez la section Planification des capacités.
Exécution de la requête
Le moteur d'exécution de BigQuery est semblable à celui d'Amazon Redshift, en ce sens qu'il orchestre votre requête en plusieurs étapes (un plan de requête), exécutent les étapes (simultanément si possible) puis réassemble les résultats. Amazon Redshift génère un plan de requête statique, contrairement à BigQuery qui optimise de manière dynamique les plans de requête à mesure que la vôtre s'exécute. BigQuery brasse les données à l'aide de son service de mémoire distante, tandis qu'Amazon Redshift brasse les données à l'aide de la mémoire du nœud de calcul local. Pour en savoir plus sur le stockage de données intermédiaires de BigQuery à différentes étapes de votre plan de requête, consultez la page Exécution de requêtes en mémoire dans Google BigQuery.
Gérer la charge de travail dans BigQuery
BigQuery propose les contrôles suivants pour la gestion des charges de travail :
- Requêtes interactives, qui sont exécutées dès que possible (paramètre par défaut)
- Requêtes par lots, qui sont mises en file d'attente en votre nom, puis démarrent dès que des ressources inactives sont disponibles dans le pool de ressources partagées BigQuery
Réservations d'emplacement via la tarification basée sur la capacité. Au lieu de payer les requêtes à la demande, vous pouvez créer et gérer de manière dynamique des buckets d'emplacements, également connus sous l'appellation réservations, etattribuer à ces réservations des projets, dossiers ou organisations. Pour réduire le plus possible les coûts, vous pouvez souscrire des engagements d'emplacements BigQuery (au minimum 100) sous la forme d'engagements modulables, mensuels ou annuels. Par défaut, les requêtes exécutées dans une réservation utilisent automatiquement les emplacements inactifs des autres réservations.
Comme le montre le schéma suivant, nous supposons que vous avez souscrit une capacité d'engagement totale de 1 000 emplacements à partager entre trois types de charges de travail : DS (science des données), ELT et BI (informatique décisionnelle). Pour gérer ces charges de travail, vous pouvez créer les réservations suivantes :
- Vous pouvez créer la réservation DS avec 500 emplacements et attribuer tous les projets science de données Google Cloud à cette réservation.
- Vous pouvez créer la réservation ELT avec 300 emplacements et attribuer les projets que vous utilisez pour les charges de travail ELT à cette réservation.
- Vous pouvez créer la réservation BI avec 200 emplacements et attribuer les projets associés à vos outils de BI à cette réservation.
Cette configuration est illustrée par le graphique ci-dessous :
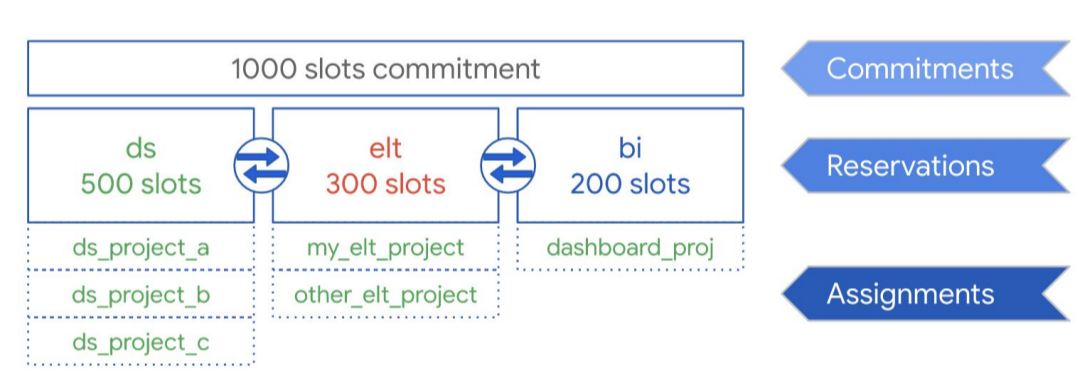
Au lieu de distribuer les réservations aux charges de travail de votre organisation, par exemple pour la production et les tests, vous pouvez choisir d'attribuer des réservations à des équipes ou à des services spécifiques, selon votre cas d'utilisation.
Pour en savoir plus, consultez la section Gérer la charge de travail à l'aide des réservations.
Gérer la charge de travail dans Amazon Redshift
Amazon Redshift propose deux types de gestion de la charge de travail :
- Automatique : si vous optez pour la gestion automatique de la charge de travail, Amazon Redshift gère la simultanéité des requêtes et l'allocation de mémoire. Jusqu'à huit files d'attente sont créées avec les identifiants de classe de service 100–107. La gestion automatique de la charge de travail détermine la quantité de ressources dont les requêtes ont besoin et ajuste la simultanéité en fonction de la charge de travail. Pour plus d'informations, consultez la section Priorité des requêtes.
- Manuel : en revanche, la gestion manuelle de la charge de travail nécessite de spécifier des valeurs pour la simultanéité des requêtes et l'allocation de mémoire. La valeur par défaut pour la gestion manuelle de la charge de travail représente la simultanéité de cinq requêtes, et la mémoire est répartie équitablement entre les cinq.
Lorsque le scaling de simultanéité est activé, Amazon Redshift ajoute automatiquement de la capacité de cluster supplémentaire lorsque vous en avez besoin pour traiter une augmentation du nombre de requêtes de lecture simultanées. Le scaling de simultanéité implique certaines considérations régionales liées aux requêtes. Pour en savoir plus, consultez la section Conditions du scaling de simultanéité.
Configurations d'ensembles de données et de tables
BigQuery propose plusieurs méthodes pour configurer vos données et vos tables, telles que le partitionnement, le clustering et la localité des données. Ces configurations peuvent vous aider à maintenir des tables volumineuses et à réduire la charge globale de données et le temps de réponse de vos requêtes, renforçant ainsi l'efficacité opérationnelle de vos charges de travail de données.
Partitionnement
Une table partitionnée est une table divisée en segments, appelés partitions, qui permettent de gérer et d'interroger facilement les données. Les utilisateurs divisent généralement de grandes tables en de nombreuses partitions plus petites, chaque partition contenant les données d'une journée. La gestion des partitions est un déterminant clé des performances et du coût de BigQuery lors de l'interrogation d'une plage de dates spécifique, car elle permet à BigQuery d'analyser moins de données par requête.
Il existe deux types de tables partitionnées dans BigQuery :
- Tables partitionnées par temps d'ingestion : les tables sont partitionnées en fonction du temps d'ingestion des données.
- Tables partitionnées par colonne : les tables sont partitionnées en fonction d'une colonne
TIMESTAMPouDATE. - Tables partitionnées par plage d'entiers : les tables sont partitionnées en fonction d'une colonne de nombres entiers.
Une table partitionnée par date et par colonne évite d'avoir à maintenir la détection de la partition indépendamment du filtrage des données existantes sur la colonne liée. Les données écrites dans une table partitionnée par date et par colonne sont automatiquement envoyées à la partition appropriée en fonction de la valeur des données. De même, les requêtes qui expriment des filtres sur la colonne de partitionnement peuvent réduire l'ensemble des données analysées, ce qui peut améliorer les performances et réduire le coût des requêtes à la demande.
Le partitionnement basé sur une colonne BigQuery est semblable au partitionnement basé sur une colonne d'Amazon Redshift, avec une motivation légèrement différente. Amazon Redshift utilise la distribution de clés basée sur les colonnes pour tenter de conserver les données associées stockées dans le même nœud de calcul, ce qui minimise le brassage des données lors des jointures et des agrégations. En séparant le stockage du calcul, BigQuery exploite le partitionnement basé sur les colonnes pour réduire la quantité de données lues par les emplacements sur le disque.
Une fois que les nœuds de calcul de lecture ont lu leurs données à partir du disque, BigQuery peut déterminer automatiquement une segmentation optimale des données et les repartitionner rapidement à l'aide du service de brassage de données en mémoire de BigQuery.
Pour plus d'informations, consultez la page Présentation des tables partitionnées.
Clustering et clés de tri
Amazon Redshift permet de spécifier des colonnes de table en tant que clés de tri composées ou entrelacées. Dans BigQuery, vous pouvez spécifier des clés de tri composées en procédant au clustering de votre table. Les tables en cluster BigQuery améliorent les performances des requêtes, car les données d'une table sont automatiquement triées en fonction du contenu de quatre colonnes spécifiées dans son schéma. Ces colonnes sont utilisées pour rapprocher les données associées. L'ordre des colonnes de clustering que vous spécifiez est important, car il détermine l'ordre de tri des données.
Le clustering peut améliorer les performances de certains types de requêtes, telles que les requêtes utilisant des clauses de filtre et celles agrégeant des données. Lorsque des données sont écrites dans une table en cluster par une tâche de requête ou de chargement, BigQuery trie les données à l'aide des valeurs des colonnes de clustering. Ces valeurs permettent d'organiser les données en plusieurs blocs dans le stockage BigQuery. Lorsque vous soumettez une requête contenant une clause qui filtre les données en fonction des colonnes de clustering, BigQuery utilise les blocs triés pour éviter l'analyse de données inutiles.
De même, lorsque vous soumettez une requête qui agrège des données sur la base des valeurs des colonnes de clustering, les performances sont améliorées, car les blocs triés rapprochent les lignes avec des valeurs similaires.
Utilisez le clustering dans les cas suivants :
- Les clés de tri composées sont configurées dans vos tables Amazon Redshift.
- Le filtrage ou l'agrégation est configuré sur des colonnes particulières de vos requêtes.
Lorsque vous utilisez le clustering et le partitionnement conjointement, vos données peuvent être partitionnées en fonction d'une colonne de date, d'horodatage ou d'entiers, puis mises en cluster sur un ensemble de colonnes différent (jusqu'à quatre colonnes en cluster au total). Dans ce cas, les données de chaque partition sont mises en cluster en fonction des valeurs des colonnes de clustering.
Dans Amazon Redshift, orsque vous spécifiez des clés de tri dans les tables, en fonction de la charge du système, Amazon Redshift initie automatiquement le tri à l'aide de la capacité de calcul de votre propre cluster. Vous devrez peut-être même exécuter manuellement la commande VACUUM si vous souhaitez trier complètement vos données de table dès que possible, par exemple après le chargement d'un grand volume de données. BigQuery gère automatiquement ce tri et n'utilise pas les emplacements BigQuery alloués, ce qui n'affecte pas les performances de vos requêtes.
Pour en savoir plus sur l'utilisation des tables en cluster, consultez la page Présentation des tables en cluster.
Clés de distribution
Amazon Redshift exploite les clés de distribution pour optimiser l'emplacement des blocs de données afin d'exécuter ses requêtes. BigQuery n'utilise pas de clés de distribution, car il détermine et ajoute automatiquement des étapes dans un plan de requête (pendant l'exécution de la requête) pour améliorer la distribution des données entre les nœuds de calcul de la requête.
Sources externes
Si vous utilisez Amazon Redshift Spectrum pour interroger des données sur Amazon S3, vous pouvez également utiliser la fonctionnalité de source de données externe de BigQuery pour interroger des données directement à partir de fichiers sur Cloud Storage.
En plus d'interroger des données dans Cloud Storage, BigQuery propose des fonctions de requête fédérées pour l'interrogation directe des produits suivants :
- Cloud SQL (MySQL ou PostgreSQL entièrement géré)
- Bigtable (NoSQL entièrement géré)
- Google Drive (CSV, JSON, Avro, Sheets)
Localisation des données
Vous pouvez créer vos ensembles de données BigQuery dans des emplacements régionaux et multirégionaux, tandis qu'Amazon Redshift ne propose que des emplacements régionaux. BigQuery détermine l'emplacement d'exécution de vos tâches de chargement, de requête ou d'exportation en fonction des ensembles de données référencés dans la requête. Reportez-vous aux considérations relatives aux emplacements BigQuery pour obtenir des conseils sur l'utilisation des ensembles de données régionaux et multirégionaux.
Mappage des types de données dans BigQuery
Les types de données Amazon Redshift diffèrent des types de données BigQuery. Pour plus d'informations sur les types de données BigQuery, reportez-vous à la documentation officielle.
BigQuery est également compatible avec les types de données suivants, qui n'ont pas d'analogie directe avec Amazon Redshift :
Comparaison SQL
GoogleSQL est conforme à la norme SQL 2011 et inclut des extensions permettant d'interroger des données imbriquées et répétées. Amazon Redshift SQL est basé sur PostgreSQL mais présente plusieurs différences qui sont détaillées dans la documentation Amazon Redshift. Pour obtenir une comparaison détaillée de la syntaxe et des fonctions SQL entre Amazon Redshift et GoogleSQL, consultez le guide de traduction SQL d'Amazon Redshift.
Vous pouvez utiliser le traducteur SQL par lot pour convertir des scripts et d'autres codes SQL de votre plate-forme actuelle vers BigQuery.
Post-migration
Puisque vous avez migré des scripts qui n'ont pas été conçus avec BigQuery, vous pouvez choisir d'implémenter des techniques pour optimiser les performances des requêtes dans BigQuery. Pour en savoir plus, consultez la section Présentation de l'optimisation des performances des requêtes.
Étapes suivantes
- Suivez les instructions détaillées pour migrer le schéma et les données depuis Amazon Redshift.
- Suivez les instructions détaillées pour migrer d'Amazon Redshift vers BigQuery avec un VPC.