En este documento, se analizan las técnicas empleadas con el fin de implementar y automatizar la integración continua (CI), la entrega continua (CD) y el entrenamiento continuo (CT) para sistemas de aprendizaje automático (AA).
La ciencia de datos y el AA se están convirtiendo en capacidades principales para resolver problemas complejos de la vida real, transformar industrias y ofrecer valor en todos los dominios. En la actualidad, los componentes para aplicar el AA eficaz están a tu alcance:
- Conjuntos de datos grandes
- Recursos de procesamiento a pedido asequibles
- Aceleradores especializados para el AA en varias plataformas en la nube
- Avances rápidos en campos de investigación de AA diferentes (como la visión artificial, la comprensión del lenguaje natural y los sistemas de Recomendaciones IA).
Por lo tanto, muchas empresas invierten en sus equipos de ciencia de datos y en sus capacidades de AA para desarrollar modelos predictivos que puedan ofrecer valor comercial a los usuarios.
Este documento está dirigido a científicos de datos y a ingenieros de AA que deseen aplicar los principios de DevOps a los sistemas de AA (MLOps). MLOps es una práctica y cultura de la ingeniería de AA, cuyo fin es unificar el desarrollo (Dev) y las operaciones (Ops) del sistema de AA. La práctica de MLOps implica abogar por la automatización y la supervisión en todos los pasos de la construcción del sistema de AA, incluida la integración, las pruebas, el lanzamiento, la implementación y la administración de la infraestructura.
Los científicos de datos pueden implementar y entrenar un modelo de AA con rendimiento predictivo en un conjunto de datos de exclusión sin conexión, con datos de entrenamiento relevantes para el caso de uso. Sin embargo, el verdadero desafío no consiste en compilar un modelo de AA, sino un sistema de AA integrado, y operarlo en la producción de forma continua. Con base en la historia extensa de los servicios de AA de producción en Google, descubrimos que puede haber muchas dificultades para operar sistemas basados en AA en la producción. Se resumen algunas de estas dificultades en Aprendizaje automático: la tarjeta de crédito de mayor interés de la deuda técnica.
Como se muestra en el siguiente diagrama, solo una fracción pequeña de un sistema de AA de la vida real está compuesta por el código de AA. Los elementos circundantes requeridos son vastos y complejos.
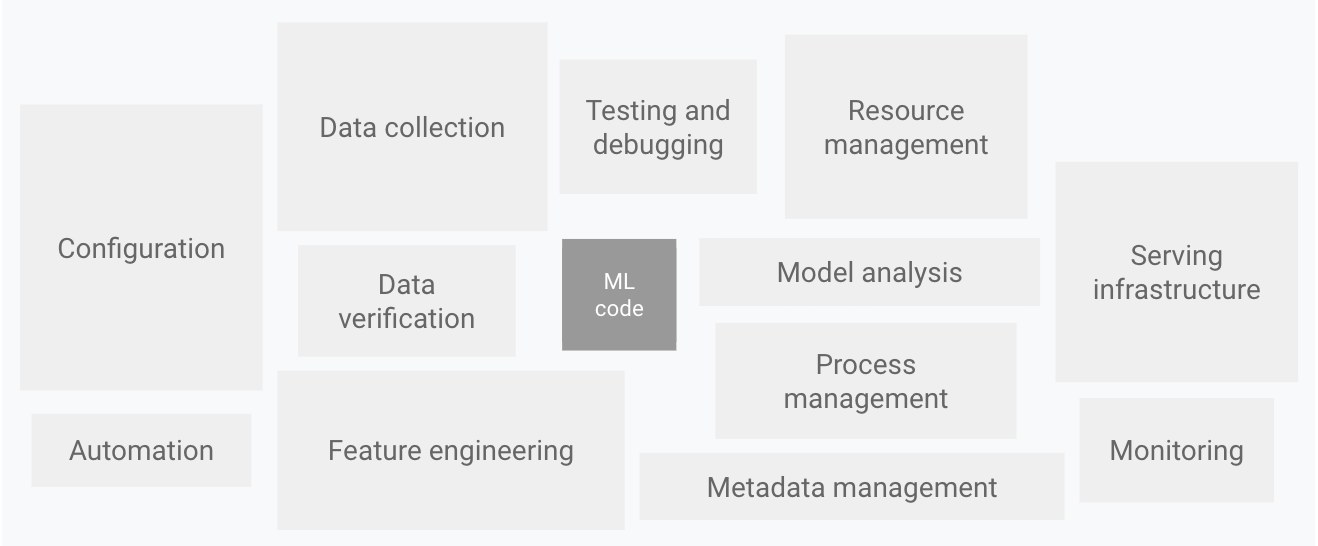
Figura 1. Elementos para los sistemas de AA. Adaptados de Deuda técnica oculta de los sistemas de aprendizaje automático.
En este diagrama, el resto del sistema está compuesto por la configuración, la automatización, la recopilación de datos, la verificación de datos, las pruebas y la depuración, la administración de recursos, el análisis de modelos, la administración de metadatos y procesos, la infraestructura de entregas y la supervisión.
Para desarrollar y operar sistemas complejos como estos, puedes aplicar los principios de DevOps en los sistemas de AA (MLOps). En este documento, se abordan los conceptos que se deben tener en cuenta cuando se configura un entorno de MLOps para tus prácticas de ciencia de datos, como la CI, la CD y el CT en el AA.
A continuación, se tratan los siguientes temas:
- DevOps frente a MLOps
- Pasos para desarrollar modelos de AA
- Niveles de madurez de MLOps
DevOps frente a MLOps
DevOps es una práctica popular en el desarrollo y la operación de sistemas de software a gran escala. Esta práctica proporciona beneficios, como la reducción de los ciclos de desarrollo, el aumento de la velocidad de implementación y la disponibilidad de actualizaciones confiables. Para aprovechar estos beneficios, debes ingresar dos conceptos en el desarrollo del sistema de software:
Un sistema de AA es un sistema de software, por lo que se aplican prácticas similares para garantizar que puedas compilar y operar sistemas de AA a gran escala de manera confiable.
Sin embargo, los sistemas de AA se diferencian de otros sistemas de software de las siguientes maneras:
Capacidades de equipo: en un proyecto de AA, el equipo suele incluir a los científicos de datos o investigadores de AA, que se enfocan en el análisis exploratorio de datos, el desarrollo de modelos y la experimentación. Es posible que estos miembros no sean ingenieros de software experimentados capaces de compilar servicios a nivel de la producción.
Desarrollo: el AA es experimental por naturaleza. Deberás probar funciones, algoritmos, técnicas de modelado y configuraciones de parámetros diferentes a fin de encontrar la mejor solución para el problema con la mayor rapidez posible. El desafío es realizar un seguimiento de lo que funcionó y de lo que fracasó, y mantener la reproducibilidad mientras se maximiza la reutilización del código.
Pruebas: realizar pruebas en un sistema de AA es más complejo que analizar otros sistemas de software. Además de las pruebas de integración y unidades típicas, deberás llevar a cabo la validación de datos, la evaluación de calidad de modelos entrenados y la validación de modelos.
Implementación: en los sistemas de AA, la implementación no es tan fácil como implementar un modelo de AA entrenado sin conexión como un servicio de predicción. Es posible que los sistemas de AA requieran que implementes una canalización de varios pasos para volver a entrenar el modelo y, luego, implementarlo de manera automática. Esta canalización agrega complejidad y requiere que automatices los pasos que se realizan de forma manual antes de que los científicos de datos lleven a cabo la implementación para entrenar y validar los modelos nuevos.
Producción: los modelos de AA pueden tener un rendimiento menor debido a una codificación subóptima y a perfiles de datos en constante evolución. En otras palabras, los modelos pueden decaer en formas más variadas con respecto a los sistemas de software convencionales, por lo que debes considerar esta degradación. Por lo tanto, debes realizar un seguimiento de las estadísticas de resumen de tus datos, así como supervisar el rendimiento en línea del modelo para enviar notificaciones o revertir la actualización cuando los valores se desvíen de tus expectativas.
El AA y otros sistemas de software son similares en la integración continua del control de la fuente, la prueba de unidades, la prueba de integración y la entrega continua del módulo de software o el paquete. Sin embargo, existen algunas diferencias notables en el AA:
- La CI ya no se trata solo de probar y validar el código y los componentes, sino también de probar y validar datos, esquemas de datos y modelos.
- La CD ya no se trata de un solo paquete de software o un servicio, sino de un sistema (una canalización de entrenamiento de AA) que debe implementar otro servicio (servicio de predicción del modelo) de manera automática.
- El CT es una propiedad nueva, exclusiva de los sistemas de AA, que se ocupa de volver a entrenar y entregar los modelos de forma automática.
En la siguiente sección, se analizan los pasos típicos para entrenar y evaluar un modelo de AA a fin de que funcione como un servicio de predicción.
Pasos de la ciencia de datos para el AA
En cualquier proyecto de AA, después de definir el caso de uso empresarial y establecer los criterios de éxito, el proceso de entrega de un modelo de AA a la producción implica los siguientes pasos. Puedes completar estos pasos de forma manual o mediante una canalización automática.
- Extracción de datos: selecciona y, luego, integra los datos relevantes de varias fuentes de datos para la tarea de AA.
- Análisis de datos: realiza un análisis de datos exploratorio (EDA) para identificar los datos disponibles a fin de compilar el modelo de AA. En este proceso, se incluye lo siguiente:
- La compresión de las características y el esquema de datos que espera el modelo
- La identificación de la preparación de datos y la ingeniería de atributos que se necesitan para el modelo
- Preparación de datos: se preparan los datos para la tarea de AA. Esta preparación incluye la limpieza de datos, en la que se dividen los datos en conjuntos de entrenamiento, validación y pruebas. También debes aplicar las transformaciones de datos y la ingeniería de atributos al modelo que resuelve la tarea de destino. El resultado de este paso comprende las divisiones de datos en el formato preparado.
- Entrenamiento de modelos: el científico de datos implementa algoritmos diferentes con los datos preparados para entrenar varios modelos de AA. Además, debes someter los algoritmos implementados al ajuste de hiperparámetros para obtener el modelo de AA de mejor rendimiento. El resultado de este paso es un modelo entrenado
- Evaluación de modelos: el modelo se analiza en un conjunto de pruebas de exclusión para evaluar la calidad del modelo. Este paso da como resultado un conjunto de métricas que se usan para evaluar la calidad del modelo.
- Validación de modelos: se confirma que el modelo es adecuado para la implementación si su rendimiento predictivo es mejor que un modelo de referencia determinado.
- Entrega de modelos: se implementa el modelo validado en un entorno de destino a fin de entregar predicciones. Esta implementación puede ser una de las que se describen a continuación:
- Microservicios con una API de REST para entregar predicciones en línea
- Un modelo incorporado a un borde o dispositivo móvil
- Parte de un sistema de predicción por lotes
- Supervisión del modelo: se supervisa el rendimiento predictivo del modelo para invocar, de manera potencial, una iteración nueva en el proceso de AA.
El nivel de automatización de estos pasos define la madurez del proceso de AA, lo cual refleja la velocidad de entrenamiento de modelos nuevos con datos nuevos o con implementaciones nuevas. En las siguientes secciones, se describen tres niveles de MLOps, desde el nivel más frecuente, que no implica automatización, hasta la automatización de canalizaciones de AA y de CI/CD.
Nivel 0 de MLOps: Proceso manual
Muchos equipos tienen investigadores de AA y científicos de datos que pueden compilar modelos de vanguardia, pero su proceso para compilar y, luego, implementar modelos de AA es manual en su totalidad. A esto se lo considera como el nivel de madurez básico o nivel 0. En el siguiente diagrama, se muestra el flujo de trabajo de este proceso.

Figura 2. Pasos manuales de AA para entregar el modelo como un servicio de predicción.
Características
En la siguiente lista, se destacan las características del proceso de nivel 0 de MLOps, como se muestra en la Figura 2:
Proceso manual, interactivo y controlado por secuencias de comandos: cada paso es manual, incluidos el análisis de datos, la preparación de datos, el entrenamiento de modelos y la validación. Se requiere la ejecución de cada paso y la transición de un paso a otro, ambas de forma manual. Un científico de datos suele controlar este proceso a través de un código experimental que escribe y ejecuta en notebooks, de forma interactiva, hasta que se produce un modelo viable.
Desconexión entre el AA y las operaciones: en el proceso, se separa a los científicos de datos que crean el modelo y a los ingenieros que entregan dicho modelo como un servicio de predicción. Los científicos de datos entregan un modelo entrenado como un artefacto al equipo de ingeniería, que deberá implementarlo en la infraestructura de la API. En esta transferencia, se puede incluir la colocación del modelo entrenado en una ubicación de almacenamiento, la verificación del objeto del modelo en un repositorio de código o la carga del modelo a un registro de modelos. Luego, los ingenieros que implementan el modelo deben habilitar las funciones requeridas disponibles en la producción para la entrega de latencia baja, lo que puede generar un sesgo entre el entrenamiento y la entrega.
Iteraciones de versiones poco frecuentes: en el proceso, se supone que el equipo de ciencia de datos administra algunos modelos que no cambian con frecuencia, ya sea mediante la modificación de la implementación del modelo o el reentrenamiento del modelo con datos nuevos. Se implementa una versión de modelo nuevo solo un par de veces al año.
Sin CI: debido a que se esperan pocos cambios en la implementación, se ignora la CI. Por lo general, probar el código es parte de la ejecución de los notebooks o las secuencias de comandos. Las secuencias de comandos y los notebooks que implementan los pasos del experimento están controlados por la fuente y producen artefactos, como modelos entrenados, métricas de evaluación y visualizaciones.
Sin CD: debido a que no hay implementaciones frecuentes de versiones de modelos, se ignora la CD.
La implementación se basa en el servicio de predicción: el proceso se centra solo en la implementación del modelo entrenado como un servicio de predicción (por ejemplo, un microservicio con una API de REST), en lugar de implementar todo el sistema de AA.
Falta de supervisión activa del rendimiento: en el proceso, no se realiza un seguimiento ni se registran las predicciones y acciones del modelo, que son necesarias para detectar la degradación del rendimiento y otros desvíos del comportamiento del modelo.
El equipo de ingeniería puede tener su propia configuración compleja para las pruebas, la implementación y la configuración de la API, incluidas las pruebas canary, de seguridad, y regresión y carga. Además, se suelen realizar pruebas A/B o experimentos en línea de la implementación de producción de una versión nueva de un modelo de AA antes de ascender el modelo para entregar el tráfico de solicitudes de predicción completo.
Desafíos
El nivel 0 de MLOps es frecuente en muchas empresas que comienzan a aplicar el AA en sus casos de uso. Este proceso manual, basado en datos científicos, puede ser útil cuando se modifican o entrenan los modelos con poca frecuencia. En la práctica, los modelos suelen fallar cuando se implementan en la vida real. Los modelos no se adaptan a los cambios en la dinámica del entorno ni a los cambios en los datos que describen el entorno. Para obtener más información, consulta Por qué los modelos de aprendizaje automático representan un fracaso total en la producción.
Para abordar estos desafíos y mantener la exactitud de tu modelo en la producción, sigue estos pasos:
Supervisa la calidad de tu modelo en la producción de forma activa: la supervisión te permitirá detectar la degradación del rendimiento y la inactividad del modelo. Actúa como una señal para una iteración de experimentación nueva y un reentrenamiento (manual) del modelo con datos nuevos.
Vuelve a entrenar con frecuencia tus modelos de producción: para capturar los patrones emergentes y en evolución, deberás volver entrenar el modelo con los datos más recientes. Por ejemplo, si tu app recomienda productos de moda mediante el uso de AA, estas recomendaciones deberán adaptarse a las últimas tendencias y productos.
Experimenta de manera continua con implementaciones nuevas a fin de producir el modelo: para aprovechar las últimas ideas y avances en tecnología, deberás probar implementaciones nuevas, como la ingeniería de atributos, la arquitectura de modelos y los hiperparámetros. Por ejemplo, si usas la visión artificial en la detección de rostro, los patrones de rostros son fijos; no obstante, las técnicas nuevas y mejoradas pueden mejorar la exactitud de la detección.
A fin de abordar los desafíos de este proceso manual, se recomiendan las prácticas de MLOps para la CI/CD y el CT. Mediante la implementación de una canalización de entrenamiento de AA, puedes habilitar el CT y configurar un sistema de CI/CD para probar, compilar y proporcionar implementaciones nuevas de la canalización de AA con rapidez. En las siguientes secciones, se analizan estas funciones con más detalle.
Nivel 1 de MLOps: Automatización de la canalización de AA
El objetivo del nivel 1 es realizar un entrenamiento continuo del modelo mediante la automatización de la canalización de AA, lo que te permite lograr una entrega continua del servicio de predicción del modelo. Para automatizar el proceso de uso de datos nuevos a fin de volver a entrenar los modelos en la producción, debes ingresar los datos automatizados y los pasos de validación de modelos en la canalización, y los activadores de canalización y la administración de metadatos.
La siguiente figura es una representación esquemática de una canalización de AA automatizada para el CT.

Figura 3. Automatización de la canalización de AA para el EI.
Características
En la siguiente lista, se destacan las características de la configuración del nivel 1 de MLOps, como se muestra en la Figura 3:
Experimento rápido: los pasos del experimento de AA están organizados. La transición entre los pasos es automática, lo que permite una iteración rápida de experimentos y una preparación más adecuada para mover toda la canalización a la producción.
El CT del modelo en la producción: se entrena el modelo en la producción de manera automática con datos recientes basados en activadores de canalización activos, que se analizan en la siguiente sección.
Simetría experimental-operacional: se usa la implementación de la canalización empleada en el entorno de desarrollo o experimentación en el entorno de producción y producción previa, que es un aspecto clave de la práctica de MLOps para unificar DevOps.
Código modularizado para componentes y canalizaciones: a fin de compilar las canalizaciones de AA, los componentes deben ser reutilizables, acoplables y, posiblemente, fáciles de compartir en dichas canalizaciones. Por lo tanto, aunque todavía se pueda usar el código EDA en notebooks, se debe modularizar el código fuente de los componentes. Además, lo ideal es que los componentes estén organizados en contenedores para llevar a cabo el siguiente proceso:
- Separar el entorno de ejecución del entorno de ejecución de código personalizado
- Hacer que el código sea reproducible entre los entornos de desarrollo y producción
- Aislar cada componente de la canalización (los componentes pueden tener su propia versión del entorno de ejecución, así como lenguajes y bibliotecas diferentes)
Entrega continua de modelos: una canalización de AA en la producción entrega de manera continua servicios de predicción a modelos nuevos que están entrenados con datos nuevos. El paso de implementación del modelo, que entrega el modelo entrenado y validado como un servicio de predicción para predicciones en línea, es automático.
Implementación de la canalización: en el nivel 0, implementa un modelo entrenado como un servicio de predicción en la producción. En el nivel 1, implementa una canalización de entrenamiento completa, que se ejecuta de forma automática y recurrente para entregar el modelo entrenado como el servicio de predicción.
Componentes adicionales
En esta sección, se analizan los componentes que debes agregar a la arquitectura para habilitar el entrenamiento continuo de AA.
Validación de datos y modelos
Cuando se implementa la canalización de AA en la producción, uno o más de los activadores analizados en la sección Activadores de canalización de AA ejecutan la canalización de forma automática. La canalización espera datos nuevos y activos para producir una versión nueva del modelo que esté entrenada con los datos nuevos (como se muestra en la Figura 3). Por lo tanto, se requieren pasos automatizados de validación de datos y validación de modelos en la canalización de producción para garantizar el siguiente comportamiento esperado:
Validación de datos: es obligatorio ejecutar este paso antes del entrenamiento de modelos para decidir si debes volver a entrenar el modelo o detener la ejecución de la canalización. Esta decisión se toma de manera automática si la canalización identifica lo que se describe a continuación.
- Sesgos de esquema de datos: a estos sesgos se los considera como anomalías en los datos de entrada, lo que significa que los pasos de la canalización descendente, incluidos el procesamiento de datos y el entrenamiento de modelos, reciben datos que no cumplen con el esquema esperado. En este caso, debes detener la canalización para que el equipo de ciencia de datos pueda investigar. El equipo puede presentar una solución o una actualización en la canalización para controlar estos cambios en el esquema. En los sesgos de esquema, se incluye la recepción de funciones inesperadas o con valores inesperados, o la falta de recepción de todas las funciones esperadas.
- Sesgos de valores de datos: estos sesgos son cambios significativos en las propiedades estadísticas de los datos, lo que significa que los patrones de datos están cambiando, y deberás activar un reentrenamiento del modelo para capturar esos cambios.
Validación de modelos: este paso se realiza después de entrenar el modelo de forma correcta según los datos nuevos. Evalúa y valida el modelo antes de que se lo ascienda a producción. Este paso de validación de modelos sin conexión consta de lo siguiente.
- Produce valores de métricas de evaluación mediante el modelo entrenado en un conjunto de datos de prueba para evaluar la calidad predictiva del modelo.
- Compara los valores de métricas de evaluación que generó tu modelo recién entrenado con el modelo actual; por ejemplo, modelo de producción, modelo de referencia, o bien, otros modelos de requisitos empresariales. Asegúrate de que el modelo nuevo produzca un mejor rendimiento que el modelo actual antes de ascenderlo a producción.
- Asegúrate de que el rendimiento del modelo sea coherente en varios segmentos de los datos. Por ejemplo, tu modelo de deserción de clientes recién entrenado podría generar una exactitud predictiva más adecuada en comparación con el modelo anterior, pero los valores de exactitud por región de clientes podrían variar de forma significativa.
- Asegúrate de evaluar tu modelo para la implementación, incluida la compatibilidad de la infraestructura y la coherencia con la API del servicio de predicción.
Además de la validación de modelos sin conexión, un modelo recién implementado se valida en línea, en una implementación de versiones canary o una prueba A/B, antes de entregar predicciones para el tráfico en línea.
Tienda de funciones
Una tienda de funciones es un componente adicional (opcional) para la automatización de la canalización de AA de nivel 1. Una tienda de funciones es un repositorio centralizado que te permite normalizar la definición, el almacenamiento y el acceso de las funciones para el entrenamiento y la entrega. Una tienda de funciones debe proporcionar una API para la entrega por lotes de capacidad de procesamiento alta y la entrega de latencia baja en tiempo real en relación con los valores de funciones y admitir cargas de trabajo de entrenamiento y entrega.
La tienda de funciones ayuda a los científicos de datos a realizar las siguientes tareas:
- Descubrir y reutilizar los conjuntos de atributos disponibles para sus entidades, en lugar de volver a crearlos o crear otros similares
- Mantener las funciones y sus metadatos relacionados para evitar tener funciones similares con definiciones diferentes
- Entregar los valores de las funciones actualizadas de la tienda de funciones
Evita el sesgo entre el entrenamiento y la entrega mediante el uso de la tienda de funciones como fuente de datos para la experimentación, el entrenamiento continuo y la entrega en línea. Este enfoque garantiza que las funciones usadas para el entrenamiento sean las mismas que se usan durante la entrega:
- Para la experimentación, los científicos de datos pueden obtener un extracto sin conexión de la tienda de funciones a fin de ejecutar sus experimentos.
- A fin de realizar el entrenamiento continuo, la canalización automática de entrenamiento de AA puede recuperar un lote de los valores de las funciones actualizadas del conjunto de datos que se usan para la tarea de entrenamiento.
- Para la predicción en línea, el servicio de predicción puede recuperar un lote de valores de las funciones relacionados con la entidad solicitada, como las funciones demográficas de clientes, las funciones de los productos y las funciones de agregación de sesiones actuales.
Administración de metadatos
Se registra la información sobre cada ejecución de la canalización de AA para ayudar con el linaje, la reproducibilidad y las comparaciones de los datos y artefactos. También te ayuda a depurar errores y anomalías. Cada vez que ejecutas la canalización, la tienda de metadatos de AA registra los siguientes metadatos:
- Las versiones de canalización y componentes que se ejecutaron
- La fecha de inicio y finalización; la hora, y la duración de la canalización para completar cada uno de los pasos
- El ejecutor de la canalización
- Los argumentos de parámetros que se pasaron a la canalización
- Los punteros de los artefactos producidos por cada paso de la canalización, como la ubicación de los datos preparados, las anomalías de validación, las estadísticas calculadas y el vocabulario extraído de los atributos categóricos. El seguimiento de estos resultados intermedios te ayuda a reanudar la canalización desde el paso más reciente si la canalización se detuvo debido a un paso erróneo, sin tener que volver a ejecutar los pasos que ya se completaron
- Un puntero al modelo entrenado anterior si necesitas revertir la versión actual a una anterior o producir métricas de evaluación para una versión del modelo anterior cuando la canalización recibe datos de prueba nuevos durante el paso de validación de modelos
- Las métricas de evaluación de modelos producidas durante el paso de evaluación del modelo para los conjuntos de entrenamiento y de prueba. Estas métricas te ayudan a comparar el rendimiento de un modelo recién entrenado con el rendimiento registrado del modelo anterior durante el paso de validación de modelos
Activadores de la canalización de AA
Puedes automatizar las canalizaciones de producción de AA para volver a entrenar los modelos con datos recientes, según tu caso de uso:
- A pedido: ejecución manual ad hoc de la canalización.
- De manera programada: los datos nuevos y etiquetados están disponibles de forma sistemática para el sistema de AA cada hora, día, semana o mes. La frecuencia del reentrenamiento también depende de la frecuencia con la que cambian los patrones de datos y del costo de volver a entrenar los modelos.
- Según la disponibilidad de datos de entrenamiento nuevos: los datos nuevos no están disponibles de manera sistemática para el sistema de AA, pero están disponibles en una base ad hoc cuando se recopilan datos nuevos y se vuelven accesibles en las bases de datos de origen.
- Según el deterioro del rendimiento del modelo: se vuelve a entrenar el modelo cuando hay una degradación notable del rendimiento.
- Según los cambios significativos en las distribuciones de datos (desvío de conceptos). Es difícil evaluar el rendimiento completo del modelo en línea, pero puedes observar cambios significativos en la distribución de datos de las funciones que se usan para realizar la predicción. Estos cambios sugieren que tu modelo está inactivo y que es necesario volver a entrenarlo con datos nuevos.
Desafíos
En los casos en que se supone que no se realizan implementaciones nuevas de la canalización con frecuencia y se administran solo algunas canalizaciones, se suele llevar a cabo una evaluación manual de la canalización y sus componentes. Además, debes implementar de forma manual implementaciones de canalización nuevas. También debes enviar el código fuente de la canalización evaluado al equipo de TI para que lo implemente en el entorno de destino. Esta configuración es adecuada cuando se implementan modelos nuevos basados en datos nuevos, en lugar de basarse en ideas de AA.
Sin embargo, debes probar ideas nuevas de AA y realizar implementaciones nuevas de los componentes de AA. Si administras muchas canalizaciones de AA en la producción, necesitarás una configuración de CI/CD para automatizar la compilación, la prueba y la implementación de canalizaciones de AA.
Nivel 2 de MLOps: Automatización de la canalización de CI/CD
Para obtener una actualización rápida y confiable de las canalizaciones en la producción, necesitarás un sistema de CI/CD sólido y automatizado. Este sistema automatizado de CI/CD permite que los científicos de datos exploren con rapidez ideas nuevas en torno a la ingeniería de atributos, la arquitectura de modelos y los hiperparámetros. Pueden aplicar estas ideas y compilar, evaluar y, luego, implementar de forma automática los componentes de la canalización nuevos en el entorno de destino.
En el siguiente diagrama, se muestra la implementación de la canalización de AA con CI/CD, que tiene las características de la configuración de canalizaciones automáticas de AA y las rutinas automáticas de CI/CD.

Figura 4. La IC/EC y la canalización automática de AA.
Esta configuración de MLOps incluye los siguientes componentes:
- Control de la fuente
- Servicios de compilación y prueba
- Servicios de implementación
- Registro de modelos
- Tienda de funciones
- Tienda de metadatos de AA
- Organizador de canalizaciones de AA
Características
En el siguiente diagrama, se muestran las etapas de la canalización de automatización de IC/EC de AA:

Figura 5. Etapas de la canalización de AA automatizada de IC/EC
La canalización consta de las siguientes etapas:
Desarrollo y experimentación: prueba de manera iterativa algoritmos de AA y modelos nuevos en los que se organizan los pasos del experimento. El resultado de esta etapa es el código fuente de los pasos de canalización de AA, que luego se envía a un repositorio de código fuente.
Integración continua de la canalización: compila el código fuente y ejecuta varias pruebas. Los resultados de esta etapa son componentes de canalización (paquetes, ejecutables y artefactos) que se implementarán en una etapa posterior.
Entrega continua de canalización: implementa los artefactos producidos durante la etapa de la CI en el entorno de destino. El resultado de esta etapa es una canalización implementada con la implementación nueva del modelo.
Activación automática: la canalización se ejecuta de forma automática en la producción según una programación o en respuesta a un activador. El resultado de esta etapa es un modelo entrenado que se envía al registro de modelos.
Entrega continua de modelos: entrega el modelo entrenado como un servicio de predicción para las predicciones. El resultado de esta etapa es un servicio de predicción del modelo implementado.
Supervisión: recopila estadísticas sobre el rendimiento del modelo en función de los datos activos. El resultado de esta etapa es un activador para ejecutar la canalización o un ciclo experimental nuevo.
El paso de análisis de datos sigue siendo un proceso manual para los científicos de datos antes de que la canalización comience una iteración nueva del experimento. El paso de análisis del modelo también es un proceso manual.
Integración continua
En esta configuración, la canalización y sus componentes se compilan, evalúan y empaquetan cuando se confirma un código nuevo o se envía al repositorio del código fuente. Además de compilar paquetes, imágenes de contenedores y ejecutables, el proceso de CI puede incluir las siguientes pruebas:
Realizar una prueba de unidades de la lógica de ingeniería de atributos
Realizar una prueba de unidades de los diferentes métodos implementados en tu modelo (por ejemplo, tienes una función que acepta una columna de datos categóricos y codificas la función como one-hot)
Evaluar si hay una convergencia de tu entrenamiento de modelos (es decir, la pérdida de tu modelo se reduce por iteraciones y sobreajustes a algunos registros de muestra)
Evaluar si tu entrenamiento de modelos no produce valores NaN debido a la división por cero o a la manipulación de valores pequeños o grandes
Evaluar que cada componente de la canalización produzca los artefactos esperados
Evaluar la integración entre componentes de canalización
Entrega continua
En este nivel, el sistema entrega de forma continua implementaciones de canalización nuevas en el entorno de destino que, a su vez, proporciona servicios de predicción del modelo recién entrenado. Para una entrega continua rápida y confiable de canalizaciones y modelos, debes considerar lo siguiente:
Verifica la compatibilidad del modelo con la infraestructura de destino antes de implementar el modelo. Por ejemplo, debes verificar que los paquetes que requiere el modelo estén instalados en el entorno de entrega y que los recursos de memoria, procesamiento y acelerador necesarios estén disponibles.
Llama a la API de servicio con los datos de entrada esperados para evaluar el servicio de predicción y asegúrate de obtener la respuesta que esperas. Por lo general, esta prueba captura problemas que pueden ocurrir cuando actualizas la versión del modelo y espera una entrada diferente.
Evalúa el rendimiento del servicio de predicción, que implica realizar una prueba de carga del servicio para capturar métricas, como las consultas por segundo (QPS) y la latencia del modelo.
Valida los datos para el reentrenamiento o la predicción por lotes.
Verifica que los modelos cumplan con los objetivos de rendimiento predictivo antes de implementarlos.
Realiza una implementación automatizada en un entorno de prueba, por ejemplo, una implementación que se activa durante el envío del código a la rama de desarrollo.
Realiza una implementación semiautomatizada en un entorno de preproducción, por ejemplo, una implementación que se activa después de fusionar el código con la rama principal una vez que los revisores aprueban los cambios.
Realiza una implementación manual en un entorno de producción después de varias ejecuciones satisfactorias de la canalización en el entorno de producción previa.
En resumen, la implementación de AA en un entorno de producción no solo implica implementar su modelo como una API para la predicción. En realidad, significa implementar una canalización de AA que pueda automatizar el reentrenamiento y la implementación de modelos nuevos. La configuración de un sistema de CI/CD te permite probar y establecer de forma automática implementaciones de canalización nuevas. Este sistema te permite lidiar con los cambios rápidos en tus datos y el entorno empresarial. No es necesario mover de inmediato todos los procesos de un nivel a otro. Puedes implementar estas prácticas de forma gradual para que puedas mejorar la automatización del desarrollo y la producción de tu sistema de AA.
¿Qué sigue?
- Obtén más información sobre la arquitectura para MLOps mediante TensorFlow Extended, Vertex AI Pipelines y Cloud Build.
- Obtén información sobre la Guía de profesionales para las operaciones de aprendizaje automático (MLOps).
- Si deseas obtener más información, consulta Configura una canalización de CI/CD para el flujo de trabajo de procesamiento de datos.
- Mira ML Ops Best Practices on Google Cloud (Cloud Next '19) (Prácticas recomendadas de MLOps en Google Cloud) en YouTube.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.