In diesem Dokument werden Best Practices für die Implementierung von maschinellem Lernen (ML) in Google Cloud vorgestellt. Der Schwerpunkt liegt auf benutzerdefiniert trainierten Modellen, die auf Ihren Daten und Ihrem Code basieren. Wir bieten Ihnen Empfehlungen zum Entwickeln eines benutzerdefiniert trainierten Modells im gesamten ML-Workflow, einschließlich wichtiger Aktionen und Links für weitere Informationen.
Das folgende Diagramm bietet eine allgemeine Übersicht über die in diesem Dokument behandelten Phasen, darunter:
- ML-Entwicklung
- Datenverarbeitung
- Operationalisiertes Training
- Modellbereitstellung und -einsatz
- ML-Workflow-Orchestrierung
- Organisation von Artefakten
- Modellmonitoring
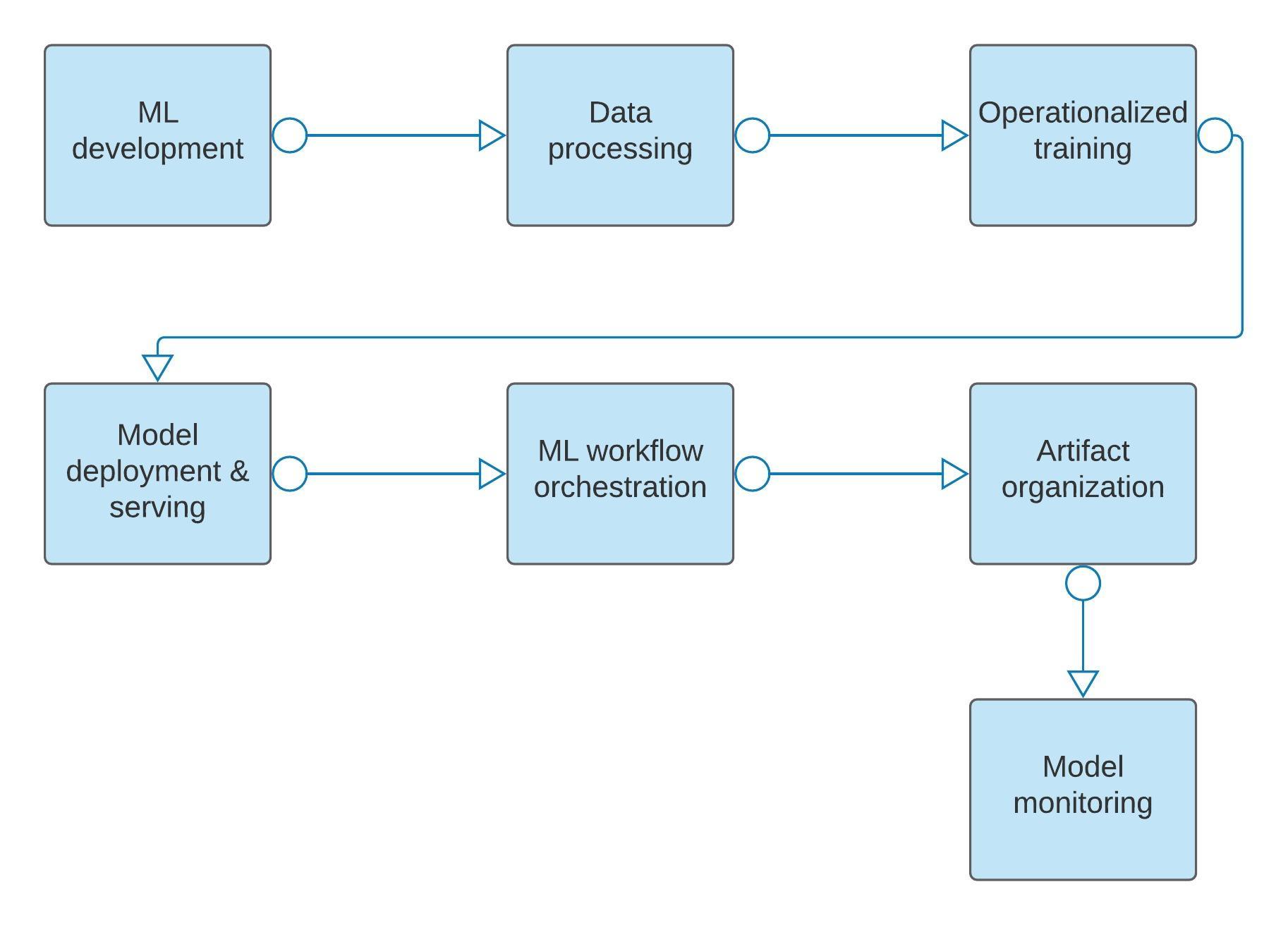
Das Dokument ist nicht als vollständige Liste von Empfehlungen zu betrachten. Es soll vielmehr Data Scientists und ML-Architekten dabei helfen, den Umfang der ML-bezogenen Aktivitäten in Google Cloud zu verstehen und entsprechend zu planen. Der Schwerpunkt dieses Dokuments liegt auf benutzerdefiniert trainierten Modellen. Alternativen zur ML-Entwicklung wie AutoML finden Sie unter Empfohlene Tools und Produkte verwenden.
Bevor Sie die Best Practices in diesem Dokument befolgen, lesen Sie den Artikel Einführung in Vertex AI.
In diesem Dokument wird Folgendes vorausgesetzt:
Sie verwenden hauptsächlich Google Cloud-Dienste. Hybrid- und lokale Ansätze werden in diesem Dokument nicht behandelt.
Sie möchten Trainingsdaten erfassen und in Google Cloud speichern.
Sie haben fortgeschrittene Kenntnisse in maschinellem Lernen, Big-Data-Tools und Datenvorverarbeitung und besitzen Grundkenntnisse in Cloud Storage, BigQuery und Google Cloud.
Wenn Sie noch nicht mit dem maschinellen Lernen vertraut sind, lesen Sie die Informationen im Crashkurs für maschinelles Lernen von Google.
Empfohlene Tools und Produkte verwenden
In der folgenden Tabelle sind für jede Phase des ML-Workflows empfohlene Tools und Produkte aufgeführt, wie in diesem Dokument beschrieben:
Google bietet AutoML, Vertex AI Forecasting und BigQuery ML als vordefinierte alternative Trainingsroutinen zu benutzerdefinierten, von Vertex AI trainierten Modelllösungen. Die folgende Tabelle enthält Empfehlungen zur Verwendung dieser Optionen für Vertex AI.
| ML-Umgebung | Beschreibung | Wählen Sie diese Umgebung aus, wenn folgende Voraussetzungen erfüllt sind: |
| BigQuery ML | BigQuery ML fasst Daten, Infrastruktur und vordefinierte Modelltypen in einem zentralen System zusammen. |
|
| AutoML (im Zusammenhang mit Vertex AI) | AutoML bietet Trainingsroutinen für häufige Probleme wie die Klassifizierung von Bildern und tabellarische Regression. Fast alle Aspekte des Trainings und der Bereitstellung eines Modells, wie die Auswahl einer Architektur, Hyperparameter-Abstimmung und Bereitstellung von Maschinen werden automatisch erledigt. |
|
| Benutzerdefiniert trainierte Vertex AI-Modelle | Mit Vertex können Sie eigene benutzerdefinierte Trainingsroutinen ausführen und Modelle beliebiger Art in einer serverlosen Architektur bereitstellen. Vertex AI bietet zusätzliche Dienste wie Hyperparameter-Abstimmung und Monitoring, um die Entwicklung eines Modells zu erleichtern. Weitere Informationen finden Sie unter Benutzerdefinierte Trainingsmethode auswählen. |
|
Einrichtung der Umgebung für maschinelles Lernen
Vertex AI Workbench-Notebooks für Experimente und Entwicklung verwenden.
Notebooks-Instanz pro Teammitglied erstellen.
ML-Ressourcen und -Artefakte basierend auf Ihrer Unternehmensrichtlinie speichern
Vertex AI SDK für Python verwenden
Vertex AI Workbench-Notebooks für Experimente und Entwicklung nutzen
Unabhängig von den Tools, die Sie bereits verwenden, empfehlen wir, Vertex AI Workbench-Notebooks für Tests und die Entwicklung zu verwenden. Dazu gehören das Schreiben von Code, das Starten von Jobs, das Ausführen von Abfragen und die Statusprüfung. Mit Notebook-Instanzen können Sie alle Daten und KI-Dienste (künstliche Intelligenz) von Google Cloud auf einfache und reproduzierbare Weise aufrufen.
Notebook-Instanzen bieten Ihnen außerdem direkt einen sicheren Satz von Software- und Zugriffsmustern. Es ist üblich, mit einem Notebook verknüpfte Google Cloud-Attribute wie Netzwerk und Cloud Identity and Access Management sowie Software (über einen Container) anzupassen. Weitere Informationen finden Sie unter Komponenten von Vertex AI und Einführung in nutzerverwaltete Notebooks.
Notebook-Instanz pro Teammitglied erstellen
Erstellen Sie eine vom Nutzer verwaltete Notebook-Instanz für jedes Mitglied Ihres Data-Science-Teams. Wenn ein Teammitglied an mehreren Projekten beteiligt ist, insbesondere Projekten mit unterschiedlichen Abhängigkeiten, empfehlen wir die Verwendung mehrerer Notebook-Instanzen, wobei jede Notebook-Instanz als virtueller Arbeitsbereich behandelt wird. Sie können Notebooks-Instanzen beenden, wenn sie nicht verwendet werden.
ML-Ressourcen und Artefakte entsprechend Ihrer Unternehmensrichtlinie speichern
Die einfachste Zugriffssteuerung besteht darin, sowohl Ihre Roh- als auch Ihre Vertex AI-Ressourcen und -Artefakte wie Datasets und Modelle im selben Google Cloud-Projekt zu speichern. Üblicherweise hat Ihr Unternehmen Richtlinien, die den Zugriff steuern. In Fällen, in denen Ihre Ressourcen und Artefakte projektübergreifend gespeichert werden, können Sie Ihre unternehmensinterne projektübergreifende Zugriffssteuerung mit Identity and Access Management (IAM) konfigurieren.
Vertex AI SDK für Python verwenden
Verwenden Sie Vertex AI SDK for Python, eine Python-Methode, mit der Sie Vertex AI für End-to-End-Workflows beim Erstellen von Modellen verwenden können. Diese funktionieren reibungslos mit Ihren bevorzugten ML-Frameworks wie PyTorch, TensorFlow, XGBoost und scikit-learn.
Alternativ können Sie die Google Cloud Console nutzen, die die Funktionalität von Vertex AI als Benutzeroberfläche über den Browser unterstützt.
ML-Entwicklung
Trainingsdaten vorbereiten
Strukturierte und semistrukturierte Daten in BigQuery speichern
Bild-, Video-, Audio- und unstrukturierte Daten in Cloud Storage speichern
Vertex Data Labeling für unstrukturierte Daten verwenden
Vertex AI Feature Store mit strukturierten Daten verwenden
Speichern von Daten im Blockspeicher vermeiden
Vertex AI TensorBoard und Vertex AI Experiments zur Analyse von Experimenten verwenden
Modell innerhalb einer Notebookinstanz für kleine Datasets trainieren
Vorhersagegenauigkeit des Modells durch Hyperparameter-Abstimmung maximieren
Modelle mit einer Notebook-Instanz verstehen
Mit Feature-Attributionen Informationen zu Modellvorhersagen erhalten
Die ML-Entwicklung dient zur Vorbereitung der Daten, für Tests und Bewertung des Modells. Beim Lösen eines ML-Problems müssen Sie in der Regel viele verschiedene Modelle erstellen und vergleichen, um herauszufinden, welches am besten funktioniert.
In der Regel trainieren Data Scientists Modelle mithilfe verschiedener Architekturen, Eingabedatensätze, Hyperparameter und Hardware. Data Scientists bewerten die resultierenden Modelle anhand von aggregierten Leistungsmesswerten wie Accuracy, Precision und Recall in Test-Datasets. Schließlich bewerten Data Scientists die Leistung der Modelle anhand bestimmter Teilmengen ihrer Daten, unterschiedlicher Modellversionen und verschiedener Modellarchitekturen.
Trainingsdaten vorbereiten
Die Daten, die zum Trainieren eines Modells verwendet werden, können aus einer beliebigen Anzahl von Systemen stammen, beispielsweise aus einem Onlinedienstsystem, aus Bildern von einem lokalen Gerät oder aus Dokumenten, die aus dem Web stammen.
Extrahieren Sie unabhängig vom Ursprung der Daten aus den Quellsystemen und konvertieren Sie sie in ein Format und einen Speicher (unabhängig von der Betriebsquelle), die für das ML-Training optimiert sind. Weitere Informationen zum Vorbereiten von Trainingsdaten für die Verwendung mit Vertex AI finden Sie unter Trainingsdaten für die Verwendung mit Vertex AI vorbereiten.
Strukturierte und semistrukturierte Daten in BigQuery speichern
Wenn Sie mit strukturierten oder halbstrukturierten Daten arbeiten, empfehlen wir, alle Daten in BigQuery zu speichern, wie in der BigQuery-Empfehlung für die Projektstruktur beschrieben. In den meisten Fällen können Sie Zwischendaten, die verarbeitet wurden, auch in BigQuery speichern. Für maximale Geschwindigkeit ist es besser, materialisierte Daten anstelle von Ansichten oder Unterabfragen für Trainingsdaten zu speichern.
Daten mit der BigQuery Storage API aus BigQuery lesen. Für das Artefakt-Tracking können Sie ein verwaltetes tabellarisches Dataset nutzen. In der folgenden Tabelle sind die Google Cloud-Tools aufgeführt, die die Verwendung der API vereinfachen:
| Wenn Sie Folgendes verwenden... | Verwenden Sie dieses Google Cloud-Tool |
| TensorFlow oder Keras | tf.data.dataset-Reader für BigQuery |
| TFX | BigQuery-Client |
| Dataflow | BigQuery-E/A-Connector |
| Ein anderes Framework (z. B. PyTorch, XGBoost oder scilearn-kit) | BigQuery Python-Clientbibliothek |
Bild-, Video-, Audio- und unstrukturierte Daten in Cloud Storage speichern
Speichern Sie diese Daten in großen Containerformaten in Cloud Storage. Dies gilt für fragmentierte TFRecord-Dateien, wenn Sie TensorFlow verwenden, oder für Avro-Dateien, wenn Sie ein anderes Framework verwenden.
Kombinieren Sie viele Bilder, Videos oder Audioclips zu großen Dateien, da dies den Lese- und Schreibdurchsatz in Cloud Storage verbessert. Die Datei sollte mindestens 100 MB groß sein und zwischen 100 und 10.000 Fragmentierungen enthalten.
Verwenden Sie Cloud Storage-Buckets und -Verzeichnisse, um die Shards zu gruppieren, um die Datenverwaltung zu aktivieren. Weitere Informationen finden Sie unter Was ist Cloud Storage?
Vertex Data Labeling für unstrukturierte Daten verwenden
Möglicherweise benötigen Sie Menschen, um Ihren Daten Labels hinzuzufügen, insbesondere wenn es um unstrukturierte Daten geht. Verwenden Sie Vertex AI Data Labeling für diese Arbeit. Sie können eigene Labelersteller verwenden und die Google Cloud-Software zur Verwaltung ihrer Arbeit verwenden oder die internen Labelersteller von Google für die Aufgabe verwenden. Weitere Informationen finden Sie unter Daten-Labeling anfordern.
Vertex AI Feature Store mit strukturierten Daten verwenden
Wenn Sie ein Modell mit strukturierten Daten trainieren, gehen Sie unabhängig davon, wo Sie das Modell trainieren, folgendermaßen vor:
Suchen Sie in Vertex AI Feature Store nach verfügbaren Features, die Ihre Anforderungen erfüllen.
Öffnen Sie Vertex AI Feature Store und suchen Sie nach einem verfügbaren Feature, das Ihrem Anwendungsfall entspricht oder das Signal abdeckt, das Sie an das Modell übergeben möchten.
Wenn Sie Features aus Vertex AI Feature Store verwenden möchten, rufen Sie diese Features für Ihre Trainingslabels mit der Batch-Bereitstellungsfunktion von Vertex AI Feature Store ab.
Erstellen Sie ein neues Feature. Wenn Vertex AI Feature Store nicht die benötigten Features hat, erstellen Sie ein neues Feature mit Daten aus Ihrem Data Lake.
Rufen Sie Rohdaten aus Ihrem Data Lake ab und schreiben Sie Ihre Skripts, um die notwendige Featureverarbeitung und -entwicklung durchzuführen.
Führen Sie die aus Vertex AI Feature Store abgerufenen Featurewerte und die aus dem Data Lake erstellten neuen Featurewerte zusammen. Durch das Zusammenführen dieser Featurewerte wird das Trainings-Dataset erzeugt.
Richten Sie einen regelmäßigen Job ein, um die aktualisierten Werte des neuen Features zu berechnen. Wenn Sie ein Feature als nützlich erachten und in die Produktion nehmen möchten, richten Sie einen regelmäßig geplanten Job mit der erforderlichen Häufigkeit ein, um die aktualisierten Werte dieses Features zu berechnen und in Vertex AI Feature Store aufzunehmen. Wenn Sie das neue Feature in Vertex AI Feature Store aufnehmen, können Sie die Features (für Anwendungsfälle der Onlinevorhersage) automatisch online bereitstellen. Außerdem können Sie das Feature für andere Mitglieder in der Organisation freigeben, damit diese es für ihre eigenen ML-Modelle nutzen können.
Weitere Informationen finden Sie unter Vertex AI Feature Store.
Speichern von Daten im Blockspeicher vermeiden
Vermeiden Sie die Speicherung von Daten in Blockspeicher, wie Netzwerkdateisysteme oder VM-Festplatten. Diese Tools sind schwieriger zu verwalten als Cloud Storage oder BigQuery und führen oft zu Herausforderungen bei der Optimierung der Leistung. Ebenso sollten Sie Daten nicht direkt aus Datenbanken wie Cloud SQL auslesen. Speichern Sie stattdessen Daten in BigQuery und Cloud Storage. Weitere Informationen finden Sie in der Cloud Storage-Dokumentation und in der Einführung in das Laden von Daten für BigQuery.
Vertex AI TensorBoard und Vertex AI Experiments für die Analyse von Experimenten verwenden
Verwenden Sie beim Entwickeln von Modellen Vertex AI TensorBoard, um bestimmte Tests zu visualisieren und zu vergleichen, z. B. anhand von Hyperparametern. Vertex AI TensorBoard ist ein sofort einsatzbereiter Vertex AI TensorBoard-Dienst mit einer kostengünstigen, sicheren Lösung, mit der Data Scientists und ML-Forscher einfach zusammenarbeiten können, da Tests nahtlos verfolgt, verglichen und freigegeben werden können. Vertex AI TensorBoard ermöglicht das Verfolgen von Testmesswerten wie Verlust und Accuracy im Zeitverlauf, die Visualisierung des Modelldiagramms, das Projizieren von Einbettungen in einen niedrigdimensionalen Raum und vieles mehr.
Verwenden Sie Vertex AI Experiments, um Vertex ML-Metadaten einzubinden und um Parameter, Messwerte sowie Dataset- und Modellartefakte zu protokollieren und zu verbinden.
Modell in einer Notebookinstanz für kleine Datasets trainieren
Das Trainieren eines Modells in der Notebooks-Instanz kann für kleine Datasets oder Teilmengen eines größeren Datasets ausreichen. Es kann nützlich sein, den Trainingsdienst für größere Datasets oder für verteiltes Training zu verwenden. Die Verwendung des Vertex AI-Trainingsdienstes wird auch für die Produktionsphase selbst mit kleinen Datasets empfohlen, wenn das Training nach einem Zeitplan oder als Reaktion auf den Eingang zusätzlicher Daten ausgeführt wird.
Vorhersagegenauigkeit Ihres Modells mit Hyperparameter-Abstimmung maximieren
Wenn Sie die Vorhersagegenauigkeit Ihres Modells maximieren möchten, verwenden Sie die Hyperparameter-Abstimmung. Dies ist die automatische Modelloptimierung von Vertex AI Training, die die Verarbeitungsinfrastruktur von Google Cloud und Vertex AI Vizier nutzt, um beim Trainieren Ihres Modells verschiedene Hyperparameter-Konfigurationen zu testen. Bei der Hyperparameter-Abstimmung ist es nicht mehr notwendig, Hyperparameter im Verlauf zahlreicher Trainingsläufe manuell anzupassen, um die optimalen Werte zu ermitteln.
Weitere Informationen zur Hyperparameter-Abstimmung finden Sie in der Übersicht zur Hyperparameter-Abstimmung und unter Hyperparameter-Abstimmung verwenden.
Modelle mit einer Notebookinstanz verstehen
Verwenden Sie eine Notebookinstanz, um Ihre Modelle zu bewerten und zu verstehen. Neben integrierten gängigen Bibliotheken wie scikit-learn umfassen Notebookinstanzen das What-if-Tool (WIT) und das Language Interpretability Tool (LIT). Mit WIT können Sie Ihre Modelle mithilfe von verschiedenen Techniken interaktiv auf Verzerrungen analysieren und mit LIT können Sie mithilfe von visuellen, interaktiven und erweiterbaren Tools das Verhalten der Natural Language Processing-Modelle verstehen.
Mit Feature-Attributionen Informationen zu Modellvorhersagen erhalten
Vertex Explainable AI ist ein wesentlicher Bestandteil des ML-Implementierungsprozesses und bietet Featureattributionen, um Informationen darüber zu erhalten, warum Modelle Vorhersagen generieren. Vertex Explainable AI gibt Aufschluss über die Bedeutung der einzelnen Features, die ein Modell als Eingabe für eine Vorhersage verwendet, und hilft Ihnen, das Modellverhalten besser zu verstehen und Vertrauen in Ihre Modelle zu schaffen.
Vertex Explainable AI unterstützt Modelle, die anhand von Tabellen- und Bilddaten benutzerdefiniert trainiert wurden.
Weitere Informationen zu Vertex Explainable AI finden Sie unter:
Datenverarbeitung
Mit BigQuery tabellarische Daten verarbeiten.
Dataflow zum Verarbeiten von Daten nutzen
Dataproc für serverlose Spark-Datenverarbeitung nutzen
Verwaltete Datasets mit Vertex ML Metadata nutzen
Der empfohlene Ansatz für die Verarbeitung Ihrer Daten hängt vom Framework und den verwendeten Datentypen ab. Dieser Abschnitt bietet eine allgemeine Empfehlung für häufige Szenarien.
Mit BigQuery strukturierte und semistrukturierte Daten verarbeiten
Verwenden Sie BigQuery zum Speichern unverarbeiteter strukturierter oder semistrukturierter Daten. Wenn Sie Ihr Modell mit BigQuery ML erstellen, verwenden Sie die in BigQuery integrierten Transformationen zur Vorverarbeitung der Daten. Wenn Sie AutoML verwenden, nutzen Sie die in AutoML integrierten Transformationen zur Vorverarbeitung der Daten. Wenn Sie ein benutzerdefiniertes Modell erstellen, ist die Verwendung der BigQuery-Transformationen die kostengünstigste Methode.
Dataflow zum Verarbeiten von Daten verwenden
Bei großen Datenmengen sollten Sie Dataflow mit dem Programmiermodell Apache Beam verwenden. Sie können mit Dataflow die unstrukturierten Daten in binäre Datenformate wie TFRecord umwandeln. Dadurch lässt sich die Leistung der Datenaufnahme während des Trainingsvorgangs verbessern.
Dataproc für serverlose Spark-Datenverarbeitung nutzen
Wenn Ihre Organisation Investitionen in eine Apache Spark-Codebasis und entsprechende Kompetenzen hat, können Sie alternativ Dataproc verwenden. Verwenden Sie einmalige Python-Skripts für kleinere Datasets, die in den Speicher passen.
Wenn Sie Transformationen durchführen müssen, die in Cloud SQL nicht ausdrucksfähig sind oder zum Streamen dienen, können Sie eine Kombination aus Dataflow und der pandas-Bibliothek verwenden.
Verwaltete Datasets mit ML-Metadaten nutzen
Nachdem die Daten für ML vorverarbeitet wurden, ziehen Sie die Verwendung eines verwalteten Datasets in Vertex AI in Betracht. Mit verwalteten Datasets können Sie eine klare Verbindung zwischen Ihren Daten und benutzerdefiniert trainierten Modellen herstellen. Außerdem erhalten Sie aussagekräftige Statistiken und eine automatische oder manuelle Aufteilung in Trainings-, Test- und Validierungs-Datasets.
Verwaltete Datasets sind nicht erforderlich und auf ihre Verwendung kann verzichtet werden, wenn Sie mehr Kontrolle über die Aufteilung Ihrer Daten in Ihrem Trainingscode benötigen oder eine Lineage zwischen Ihren Daten und dem Modell für Ihre Anwendung nicht kritisch ist.
Weitere Informationen finden Sie unter Datasets und Verwaltetes Dataset in einer benutzerdefiniert trainierten Anwendung verwenden.
Operationalisiertes Training
Code in einem verwalteten Dienst ausführen
Jobausführung mit Trainingspipelines operationalisieren
Mit Trainingsprüfpunkten den aktuellen Status von Tests speichern
Produktionsartefakte zur Bereitstellung in Cloud Storage vorbereiten
Neue Featurewerte regelmäßig berechnen
Bei operativem Training wird das Modelltraining wiederholbar, die Wiederholung von Wiederholungen wird überwacht und die Leistung verwaltet. Vertex AI Workbench-Notebooks sind zwar praktisch für die iterative Entwicklung in kleinen Datasets geeignet, wir empfehlen jedoch, den Code zu operationalisieren, damit er reproduzierbar ist und auf große Datasets skaliert werden kann. In diesem Abschnitt werden Tools und Best Practices für die Operationalisierung Ihrer Trainingsroutinen erläutert.
Code in einem verwalteten Dienst ausführen
Wir empfehlen, Code entweder in Vertex AI Training oder in Vertex AI Pipelines auszuführen.
Optional können Sie Ihren Code direkt in einem Deep Learning Virtual Machine-Container oder in Compute Engine ausführen. Dieser Ansatz wird jedoch nicht empfohlen, da die von Vertex AI verwalteten Dienste automatische und kostengünstigere Burst-Funktionen bieten.
Jobausführung mit Trainingspipelines operationalisieren
Erstellen Sie Trainingspipelines, um die Ausführung von Trainingsjobs in Vertex AI zu operationalisieren. Eine Trainingspipeline unterscheidet sich von einer allgemeinen ML-Pipeline und kapselt Trainingsjobs. Weitere Informationen zu Trainingspipelines finden Sie unter Trainingspipelines erstellen und REST-Ressource: projects.locations.trainingPipelines.
Mit Trainingsprüfpunkten den aktuellen Status von Tests speichern
Der ML-Workflow in diesem Dokument setzt voraus, dass Sie nicht interaktiv trainieren. Wenn Ihr Modell fehlschlägt und nicht Prüfpunktausführungen enthält, wird der Trainingsjob oder die Pipeline beendet und die Daten gehen verloren, weil das Modell nicht im Speicher ist. Um dieses Szenario zu vermeiden, sollten Sie immer Trainingsprüfpunkte verwenden, damit der Status nicht verloren geht.
Es wird empfohlen, Trainingsprüfpunkte in Cloud Storage zu speichern. Erstellen Sie für jeden Test oder Trainingslauf einen anderen Ordner.
Weitere Informationen zu Prüfpunkten finden Sie unter Trainingsprüfpunkte für TensorFlow Core, Allgemeine Prüfpunkte in PyTorch speichern und laden und Designmuster für maschinelles Lernen.
Modellartefakte zur Bereitstellung in Cloud Storage vorbereiten
Für benutzerdefinierte Modelle oder benutzerdefinierte Container speichern Sie Ihre Modellartefakte in einem Cloud Storage-Bucket, wobei die Region des Buckets dem von Ihnen für die Produktion verwendeten regionalen Endpunkt entspricht. Weitere Informationen finden Sie unter Bucket-Regionen.
Speichern Sie Ihren Cloud Storage-Bucket im selben Google Cloud-Projekt. Wenn sich Ihr Cloud Storage-Bucket in einem anderen Google Cloud-Projekt befindet, müssen Sie Vertex AI Zugriff gewähren, um Ihre Modellartefakte zu lesen.
Wenn Sie einen vordefinierten Vertex AI-Container verwenden, achten Sie darauf, dass die Modellartefakte Dateinamen haben, die exakt mit folgenden Beispielen übereinstimmen:
TensorFlow SavedModel:
saved_model.pbScikit-learn:
model.joblibodermodel.pklXGBoost:
model.bstPyTorch:
model.pth
Informationen zum Speichern Ihres Modells in Form eines oder mehrerer Modellartefakte finden Sie unter Modellartefakte zur Vorhersage exportieren.
Neue Featurewerte regelmäßig berechnen
Häufig verwendet ein Modell eine Teilmenge von Features aus Vertex AI Feature Store. Die Features in Vertex AI Feature Store sind für die Onlinebereitstellung einsatzbereit. Für neue Features, die von Data Scientists durch das Beschaffen von Daten aus dem Data Lake erstellt werden, sollten Sie die entsprechenden Datenverarbeitungs- und Feature Engineering-Jobs (oder idealerweise Dataflow) planen, um die neuen Featurewerte in den erforderlichen Abständen abhängig von den Anforderungen an die Aktualität der Features regelmäßig zu berechnen. Außerdem sollten sie in den Vertex AI Feature Store zur Online- oder Batchbereitstellung aufgenommen werden.
Modellbereitstellung und -einsatz
Anzahl und Typ der erforderlichen Maschinen angeben
Eingaben für das Modell planen
Automatische Skalierung aktivieren
Modellbereitstellung und -bereitstellung bezieht sich auf das Einfügen eines Modells in die Produktion. Die Ausgabe des Trainingsjobs ist eines oder mehrere der Modellartefakte, die in Cloud Storage gespeichert sind. Sie können sie in Vertex AI Model Registry hochladen, um die Datei für die Vorhersagebereitstellung zu verwenden. Es gibt zwei Arten der Vorhersagebereitstellung: Die Batchvorhersage wird zur regelmäßigen Punktzahlbewertung von Daten verwendet und die Onlinevorhersage wird für die Echtzeit-Bewertung von Daten für Liveanwendungen verwendet. Mit beiden Ansätzen können Sie Vorhersagen von trainierten Modellen erhalten. Dazu übergeben Sie Eingabedaten an ein in der Cloud gehostetes ML-Modell und erhalten Inferenzen für jede Dateninstanz. Weitere Informationen finden Sie unter Batchvorhersagen abrufen und Onlinevorhersagen aus benutzerdefinierten Modellen abrufen.
Verwenden Sie private Vertex AI-Endpunkte, um die Latenz für Peer-to-Peer-Anfragen zwischen Client und Modellserver zu verringern. Diese sind besonders nützlich, wenn sich Ihre Anwendung, die die Vorhersageanfragen stellt, und die beritstellende Binärdatei im selben lokalen Netzwerk befinden. Sie können den Aufwand für das Internetrouting vermeiden und eine Peer-to-Peer-Verbindung über Virtual Private Cloud herstellen.
Anzahl und Typen der erforderlichen Maschinen angeben
Wenn Sie das Modell für die Vorhersage bereitstellen möchten, wählen Sie die für Ihr Modell geeignete Hardware aus, z. B. verschiedene VM-Typen (Central Processing Unit, VM) oder GPU-Typen (Graphics Processing Unit). Weitere Informationen finden Sie unter Maschinentypen oder Skalierungsstufen angeben.
Eingaben an das Modell planen
Neben der Bereitstellung des Modells müssen Sie auch festlegen, wie Sie Eingaben an das Modell übergeben möchten. Wenn Sie die Batchvorhersage verwenden, können Sie Daten aus dem Data Lake oder der Vertex AI Feature Store Batch Serving API abrufen. Wenn Sie die Onlinevorhersage verwenden, können Sie Eingabeinstanzen an den Dienst senden und diese erhalten die Vorhersagen in der Antwort. Weitere Informationen finden Sie unter Details zum Antworttext.
Wenn Sie Ihr Modell für die Onlinevorhersage bereitstellen, benötigen Sie eine niedrige Latenz, um die Eingaben oder Funktionen bereitzustellen, die an den Endpunkt des Modells übergeben werden müssen. Dazu können Sie entweder einen der vielen Datenbankdienste in Google Cloud verwenden oder die Online Serving API von Vertex AI Feature Store verwenden. Die Clients, die den Endpunkt für die Onlinevorhersage aufrufen, können zuerst die Featurebereitstellungslösung aufrufen, um die Featureeingaben abzurufen, und dann den Vorhersageendpunkt mit diesen Eingaben aufrufen.
Mit der Streamingaufnahme können Sie Echtzeitwerte für Featurewerte aktualisieren. Diese Methode ist nützlich, wenn die neuesten verfügbaren Daten für die Onlinebereitstellung eine Priorität haben. Sie können beispielsweise Streaming-Ereignisdaten aufnehmen und innerhalb weniger Sekunden stellt Vertex AI Feature Store diese Daten für Online-Bereitstellungsszenarien zur Verfügung.
Mit benutzerdefinierten Vorhersageroutinen können Sie außerdem die Verarbeitung und das Format von Eingabe (Anfrage) und Ausgabe (Antwort) an und von Ihrem Modellserver anpassen.
Automatische Skalierung aktivieren
Wenn Sie den Onlinevorhersagedienst verwenden, sollten Sie in den meisten Fällen die automatische Skalierung durch Festlegen von Mindest- und Höchstwerten aktivieren. Weitere Informationen finden Sie unter Vorhersagen für ein benutzerdefiniertes trainiertes Modell abrufen. Zur Gewährleistung eines Service Level Agreements (SLA) für hohe Verfügbarkeit legen Sie die automatische Skalierung mit mindestens zwei Knoten fest.
Weitere Informationen zu Skalierungsoptionen finden Sie unter Vorhersagen für maschinelles Lernen skalieren.
ML-Workflow-Orchestrierung
Vertex-AI Pipelines zur Orchestrierung des ML-Workflows nutzen
Kubeflow Pipelines für eine flexible Pipelineerstellung verwenden.
Vertex AI bietet eine ML-Workflow-Orchestrierung zum Automatisieren des ML-Workflows mit Vertex AI Pipelines, einem vollständig verwalteten Dienst, mit dem Sie Ihre Modelle so oft wie nötig neu trainieren können. Wenn Sie Ihre Modelle neu trainieren, um Änderungen einzubinden und die Leistung im Zeitverlauf beizubehalten, berücksichtigen Sie bei der Auswahl der optimalen Häufigkeit das Ausmaß der Änderungen auf Ihre Daten.
ML-Orchestrierungsworkflows funktionieren am besten für Kunden, die ihr Modell bereits entworfen, erstellt und in die Produktion übertragen haben und nun herausfinden möchten, was im ML-Modell funktioniert und was nicht. Der für Tests verwendete Code ist wahrscheinlich für den Rest des ML-Workflows mit einigen Änderungen nützlich. Wenn Sie mit automatisierten ML-Workflows arbeiten möchten, müssen Sie mit Python vertraut sein, die grundlegende Infrastruktur wie Container verstehen und über Kenntnisse in ML und Data Science verfügen.
Vertex AI Pipelines zur Orchestrierung des ML-Workflows verwenden
Sie können jeden Datenprozess, jedes Training, jede Bewertung, jeden Test und jede Bereitstellung manuell starten. Wir empfehlen jedoch, Vertex AI Pipelines zur Orchestrierung des Ablaufs zu verwenden. Ausführliche Informationen finden Sie unter MLOps-Stufe 1: Automatisierung der ML-Pipeline.
Vertex AI Pipelines unterstützt die Ausführung von DAGs, die von KubeFlow, TensorFlow Extended (TFX) und Airflow generiert wurden.
Kubeflow Pipelines für eine flexible Pipelineerstellung verwenden
Für die meisten Nutzer, die verwaltete Pipelines erstellen möchten, wird das Kubeflow Pipelines SDK empfohlen. Kubeflow Pipelines ist flexibel, sodass Sie einfachen Code verwenden können, um Pipelines zu erstellen. Es stellt Google Cloud-Pipeline-Komponenten bereit, mit denen Sie Vertex-AI-Funktionen wie AutoML in Ihre Pipeline einbinden können. Weitere Informationen zu Kubeflow Pipelines finden Sie unter Kubeflow Pipelines und Vertex AI Pipelines.
Organisation von Artefakten
ML-Modellartefakte organisieren
Quellkontroll-Repository für Pipelinedefinitionen und Trainingscode verwenden.
Artefakte sind Ausgaben, die aus jedem Schritt im ML-Workflow entstehen. Es empfiehlt sich, sie standardisiert zu organisieren.
ML-Modellartefakte organisieren
Speichern Sie Ihre Artefakte an den folgenden Speicherorten:
| Storage-Speicherort | Artefakte |
| Versionsverwaltungs-Repository |
|
| Tests und ML-Metadaten |
|
| Vertex AI Model Registry |
|
| Artifact Registry |
|
| Vertex AI-Vorhersage |
|
Quellverwaltungs-Repository für Pipelinedefinitionen und Trainingscode verwenden
Mit der Quellsteuerung können Sie Ihre ML-Pipelines und die benutzerdefinierten Komponenten, die Sie für diese Pipelines erstellen, einer Versionskontrolle unterziehen. Verwenden Sie Artifact Registry, um Ihre Docker-Container-Images zu speichern, zu verwalten und zu sichern, ohne sie öffentlich sichtbar zu machen.
Modellmonitoring
Abweichungs- und Drifterkennung verwenden
Schwellenwerte für Benachrichtigungen anpassen
Feature-Attributionen zur Erkennung von Datenabweichungen verwenden
Sobald Sie Ihr Modell in der Produktion bereitgestellt haben, müssen Sie die Leistung überwachen, um zu prüfen, ob das Modell wie erwartet funktioniert. Vertex AI bietet zwei Möglichkeiten zur Überwachung von ML-Modellen:
Verzerrungserkennung: Bei diesem Ansatz wird nach dem Grad der Verzerrung zwischen den Modelltrainings- und den Produktionsdaten gesucht.
Abweichungserkennung: Bei dieser Art des Monitorings suchen Sie nach einer Abweichung in Ihren Produktionsdaten. Eine Abweichung tritt auf, wenn sich die statistischen Attribute der Eingaben und des Ziels, die das Modell vorherzusagen versucht, im Laufe der Zeit unvorhergesehen ändern. Dies kann zu Problemen führen, da die Vorhersagen mit der Zeit an Genauigkeit verlieren.
Die Modellüberwachung funktioniert für strukturierte Daten wie numerische und kategoriale Merkmale, nicht jedoch für unstrukturierte Daten wie Bilder. Weitere Informationen finden Sie unter Modelle für Funktionsabweichungen oder Drift überwachen.
Erkennung von Abweichungen und Drift
Verwenden Sie so oft wie möglich die Verzerrungserkennung, denn wenn sich die Produktionsdaten stark von den Trainingsdaten unterscheiden, bedeutet dies, dass Ihr Modell bei der Produktion nicht den Erwartungen entspricht. Richten Sie für die Verzerrungserkennung den Job zur Modellüberwachung ein. Verweisen Sie dazu auf die Trainingsdaten, mit denen Sie das Modell trainieren.
Wenn Sie keinen Zugriff auf die Trainingsdaten haben, aktivieren Sie die Abweichungserkennung, um zu wissen, wann sich die Eingaben im Laufe der Zeit ändern.
Verwenden Sie die Drifterkennung, um zu prüfen, ob Ihre Produktionsdaten im Laufe der Zeit abweichen. Aktivieren Sie für die Drifterkennung die Features, die Sie überwachen möchten, sowie die entsprechenden Schwellenwerte, die eine Benachrichtigung auslösen sollen.
Schwellenwerte für Benachrichtigungen anpassen
Passen Sie die Schwellenwerte an, die für Benachrichtigungen verwendet werden, damit Sie wissen, wenn es in Ihren Daten eine Verzerrung oder Drift gibt. Schwellenwerte für Benachrichtigungen werden durch den Anwendungsfall, das Domainwissen des Nutzers und die ersten Messwerte zur Modellüberwachung bestimmt. Informationen zum Erstellen von Dashboards oder zum Konfigurieren von Benachrichtigungen anhand der Messwerte mithilfe von Monitoring finden Sie unter Cloud Monitoring-Messwerte.
Feature-Attributionen zur Erkennung von Datenabweichungen verwenden
Sie können Feature-Attributionen in Vertex Explainable AI verwenden, um Datenabweichungen oder -verzerrungen als frühen Hinweis auf eine mögliche Verschlechterung der Modellleistung zu erkennen. Wenn Ihr Modell z. B. ursprünglich auf fünf Features angewiesen war, um Vorhersagen in Ihren Trainings- und Testdaten zu treffen, aber es bei der Übernahme in die Produktion ganz andere Features nutzte, würden Feature-Attributionen dabei helfen, eine Verschlechterung der Modellleistung zu erkennen.
Dies ist besonders für komplexe Featuretypen wie Einbettungen und Zeitachsen nützlich, die mit herkömmlichen Verzerrungs- und Abweichungsmethoden schwer zu vergleichen sind. Bei Vertex Explainable AI können Feature-Attributionen auf eine Verschlechterung der Modellleistung hinweisen.
Nächste Schritte
- Dokumentation zu Vertex AI
- Leitfaden zu MLOps: Ein ML-Framework für Continuous Delivery und Automatisierung von maschinellem Lernen
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center