Nesta página, você encontra uma visão geral do Monitoramento de modelos com a Vertex AI para modelos tabulares de AutoML e treinamento personalizado. Para ativar o monitoramento de modelos da Vertex AI, consulte Como usar o monitoramento de modelos.
Visão geral
Um modelo implantado em produção tem um desempenho melhor em dados de entrada de previsão semelhante aos dados de treinamento. Quando os dados de entrada se desviam dos dados usados para treinar o modelo, o desempenho do modelo pode se deteriorar, mesmo que o próprio modelo não tenha mudado.
Para ajudar a manter o desempenho de um modelo, o monitoramento de modelos monitora os dados de entrada de previsão do modelo em busca de desvio e desvio do atributo:
O desvio entre treinamento e disponibilização ocorre quando a distribuição de dados do recurso na produção é diferente da distribuição de dados do recurso usada para treinar o modelo. Se os dados de treinamento originais estiverem disponíveis, será possível ativar a detecção de distorção para monitorar seus modelos para o desvio de treinamento/disponibilização.
O desvio da previsão ocorre quando a distribuição de dados do recurso na produção muda significativamente ao longo do tempo. Se os dados de treinamento originais não estiverem disponíveis, será possível ativar a detecção de deslocamento para monitorar as entradas de produção para alterações ao longo do tempo.
É possível ativar a detecção de distorção e desvio.
O monitoramento de modelos é compatível com a detecção de desvios e desvios de atributos em atributos categóricos e numéricos.
Atributos categóricos são dados limitados por um número de valores possíveis, geralmente agrupados por propriedades qualitativas. Por exemplo, categorias como tipo de produto, país ou tipo de cliente.
Atributos numéricos são dados que podem ser qualquer valor numérico. Por exemplo, peso e altura.
Quando a distorção ou desvio do atributo de um modelo excede um limite de alerta definido por você, o monitoramento de modelos envia um alerta por e-mail. Também é possível ver as distribuições de cada recurso ao longo do tempo para avaliar se você precisa treinar novamente seu modelo.
Calcular a distorção entre treinamento e disponibilização e o desvio de previsão
Para detectar desvios de treinamento/disponibilização e desvio de previsão, o monitoramento de modelos usa o TensorFlow Data Validation (TFDV) para calcular as distribuições e pontuações de distância de acordo com para o seguinte processo:
Calcule a distribuição estatística do valor de referência:
Na detecção de distorção, o valor de referência é a distribuição estatística dos valores do atributo nos dados de treinamento.
Na detecção de desvio, o valor de referência é a distribuição estatística dos valores do atributo exibidos na produção no passado recente.
As distribuições de atributos categóricos e numéricos são calculadas da seguinte forma:
Para atributos categóricos, a distribuição calculada é o número ou a porcentagem de instâncias de cada valor possível do atributo.
Para atributos numéricos, o monitoramento de modelos divide o intervalo de valores de atributos possíveis em intervalos iguais e calcula o número ou a porcentagem de valores de atributos que se enquadram em cada intervalo.
O valor de referência é calculado quando você cria um job de monitoramento de modelos e só é recalculado se você atualizar o conjunto de dados de treinamento para o job.
Calcular a distribuição estatística dos valores mais recentes de atributo vistos na produção.
Compare a distribuição dos valores mais recentes de atributos na produção com a distribuição do valor de referência calculando uma pontuação de distância:
Para recursos categóricos, a pontuação de distância é calculada usando a distância de L-infinito.
Para atributos numéricos, a pontuação de distância é calculada usando a divergência de Jensen-Shannon.
Quando a pontuação de distância entre duas distribuições estatísticas excede o limite especificado, o monitoramento de modelos identifica a anomalia como distorção ou desvio.
O exemplo a seguir mostra a distorção ou desvio entre o valor de referência e as distribuições mais recentes de um atributo categórico:
Distribuição do valor de referência
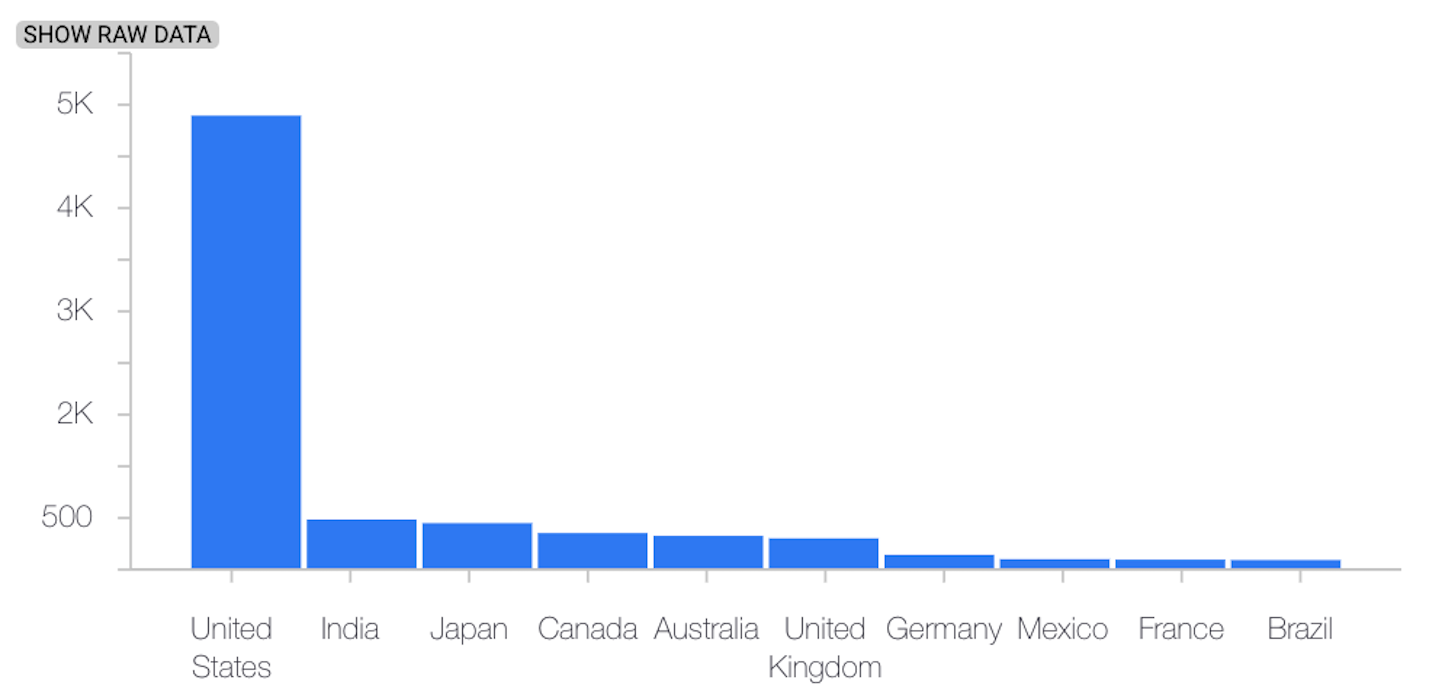
Distribuição mais recente
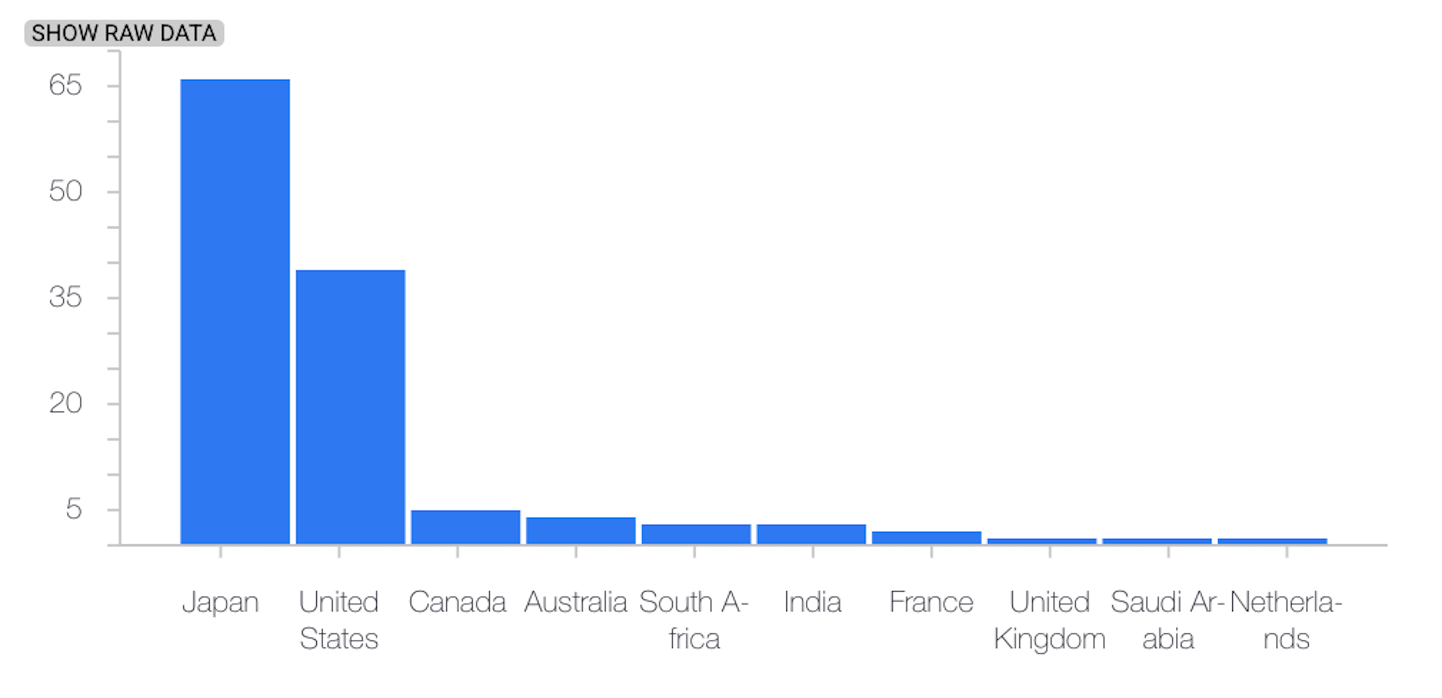
O exemplo a seguir mostra a distorção ou desvio entre o valor de referência e as distribuições mais recentes de um atributo numérico:
Distribuição do valor de referência
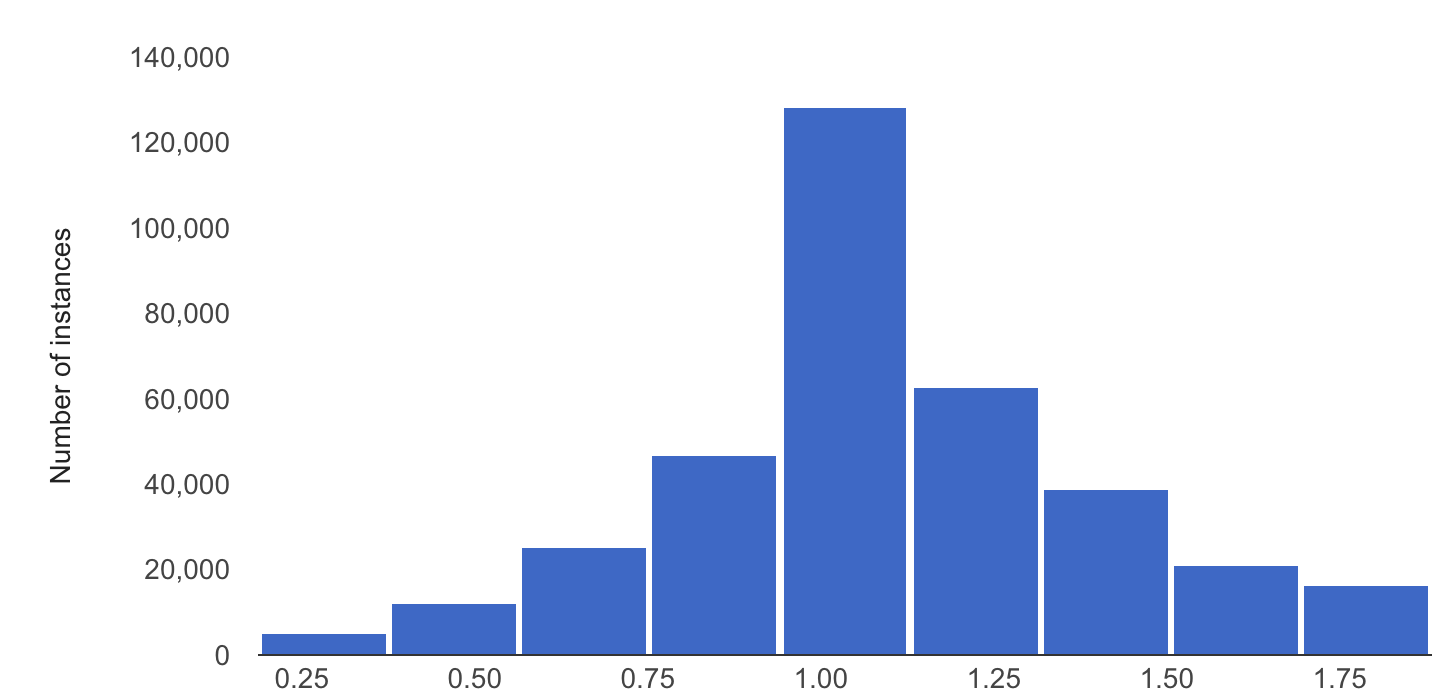
Distribuição mais recente
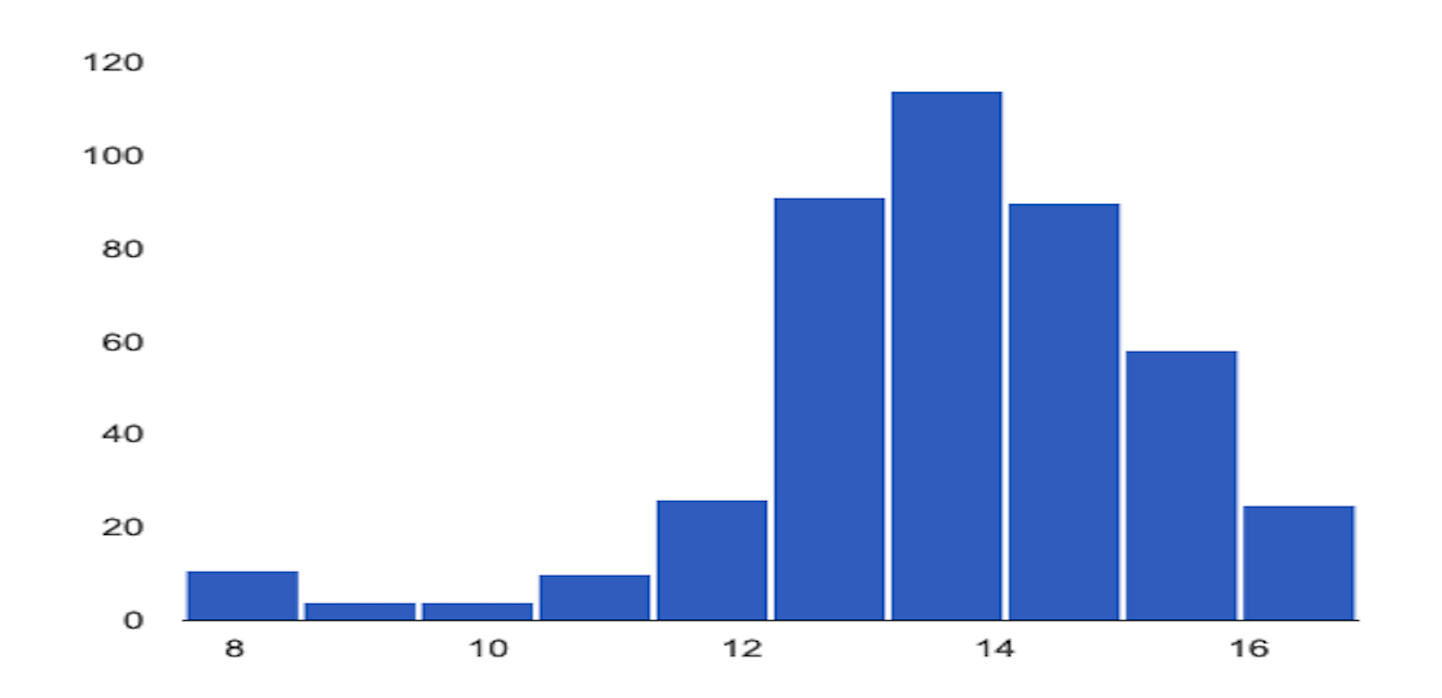
Considerações ao usar o monitoramento de modelos
Para manter a eficiência de custos, defina uma taxa de amostragem de solicitações de previsão para monitorar um subconjunto das entradas de produção em um modelo.
É possível definir uma frequência com que as entradas registradas recentemente de um modelo implantado são monitoradas em busca de distorção ou desvio. A frequência de monitoramento determina o período, ou o tamanho da janela de monitoramento, dos dados registrados que são analisados em cada execução do monitoramento.
É possível especificar limites de alerta para cada atributo que você quer monitorar. Um alerta é registrado quando a distância estatística entre a distribuição do recurso de entrada e o valor de referência correspondente excede o limite especificado. Por padrão, todos os atributos categóricos e numéricos são monitorados com valores limite de 0,3.
Um endpoint de previsão on-line pode hospedar vários modelos. Quando você ativa a detecção de desvios ou desvios em um endpoint, os seguintes parâmetros de configuração são compartilhados em todos os modelos hospedados nesse endpoint:
- Tipo de detecção
- Frequência de monitoramento
- Fração de solicitações de entrada monitoradas
Para os outros parâmetros de configuração, é possível definir valores diferentes para cada modelo.
A seguir
- Saiba como os esquemas funcionam com seu job de monitoramento tabular.
- Ative a detecção de desvios e deslocamentos para seus modelos.
- Teste o notebook de exemplo no Colab (em inglês) ou visualize-o no GitHub.
- Consulte a Referência de anomalias do TensorFlow Data Validation