Neste tutorial, descrevemos como migrar do Amazon DynamoDB para o Spanner. Ele é destinado principalmente aos proprietários de apps que querem migrar de um sistema NoSQL para o Spanner, um sistema de banco de dados SQL totalmente relacional, tolerante a falhas e altamente escalonável que oferece suporte a transações. Se você tiver uso consistente de tabelas do Amazon DynamoDB, em termos de tipos e layout, o mapeamento para o Spanner será simples. Se as tabelas do Amazon DynamoDB contiverem tipos e valores de dados arbitrários, talvez seja mais simples migrar para outros serviços NoSQL, como Datastore ou Firestore.
Neste tutorial, pressupomos que você tenha familiaridade com esquemas de banco de dados, tipos de dados, os fundamentos do NoSQL e sistemas de bancos de dados relacionais. O tutorial depende da execução de tarefas predefinidas para realizar uma migração de amostra. Após o tutorial, é possível modificar o código e as etapas fornecidas para corresponder ao seu ambiente.
O seguinte diagrama arquitetural descreve os componentes usados no tutorial para migrar dados:

Objetivos
- Migrar dados do Amazon DynamoDB para o Spanner.
- Criar um banco de dados do Spanner e uma tabela de migração.
- Mapear um esquema NoSQL em um esquema relacional.
- Criar e exportar um conjunto de dados de amostra que use o Amazon DynamoDB.
- Transferir dados entre o Amazon S3 e o Cloud Storage.
- Usar o Dataflow para carregar dados no Spanner.
Custos
Neste tutorial, usamos o seguinte componente faturável do Google Cloud:
As cobranças do Spanner são baseadas na quantidade de capacidade de computação na instância e na quantidade de dados armazenados durante o ciclo de faturamento mensal. Durante o tutorial, você usa uma configuração mínima desses recursos, que são limpos no final. Para cenários reais, estime seus requisitos de capacidade e armazenamento e, em seguida, use a documentação das instâncias do Spanner para determinar a quantidade de capacidade de computação necessária.
Além dos recursos do Google Cloud, este tutorial usa os seguintes recursos do Amazon Web Services (AWS):
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
Esses serviços são necessários apenas durante o processo de migração. No final do tutorial, siga as instruções para limpar todos os recursos e evitar cobranças desnecessárias. Use a calculadora de preços da AWS para estimar esses custos.
Para gerar uma estimativa de custo baseada na projeção de uso, use a calculadora de preços.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Spanner, Pub/Sub, Compute Engine, and Dataflow.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Spanner, Pub/Sub, Compute Engine, and Dataflow.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Preparar o ambiente
Neste tutorial, você executa comandos no Cloud Shell. O Cloud Shell fornece acesso à linha de comando no Google Cloud e inclui a CLI do Google Cloud e outras ferramentas necessárias para o desenvolvimento do Google Cloud. O Cloud Shell pode demorar vários minutos para ser inicializado.
-
No Console do Google Cloud, ative o Cloud Shell.
Na parte inferior do Console do Google Cloud, uma sessão do Cloud Shell é iniciada e exibe um prompt de linha de comando. O Cloud Shell é um ambiente shell com a CLI do Google Cloud já instalada e com valores já definidos para o projeto atual. A inicialização da sessão pode levar alguns segundos.
- Defina a zona padrão do Compute Engine. Por exemplo,
us-central1-b<pre class="devsite-click-to-copy"> gcloud config set compute/zone us-central1-b </pre></li> - Clone o repositório do GitHub que contém o código de amostra.
<pre class="devsite-click-to-copy"> git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git </pre></li> - Acesse o diretório clonado.
<pre class="devsite-click-to-copy"> cd dynamodb-spanner-migration </pre></li> - Crie um ambiente virtual em Python.
<pre class="devsite-click-to-copy"> pip3 install virtualenv virtualenv env </pre></li> - Ative o ambiente virtual.
<pre class="devsite-click-to-copy"> source env/bin/activate </pre></li> - Instale os módulos necessários do Python.
<pre class="devsite-click-to-copy"> pip3 install -r requirements.txt </pre></li>
Configure o acesso da AWS
Neste tutorial, você cria e exclui tabelas do Amazon DynamoDB, buckets do Amazon S3 e outros recursos. Para acessar esses recursos, primeiro você precisa criar as permissões exigidas pelo AWS Identity and Access Management (IAM). Use uma conta de teste ou sandbox da AWS para evitar afetar os recursos de produção na mesma conta.
Criar uma função do AWS IAM para o AWS Lambda
Nesta seção, você cria uma função do AWS IAM que o AWS Lambda usa em uma etapa posterior do tutorial.
- No console da AWS, acesse a seção IAM, clique em Papéis e selecione Criar papel.
- Em Trusted entity type, verifique se a opção AWS service está selecionada.
- Em Caso de uso, selecione Lambda e clique em Avançar.
- Na caixa de filtro Políticas de permissão, digite
AWSLambdaDynamoDBExecutionRolee pressioneReturnpara pesquisar. - Marque a caixa de seleção AWSLambdaDynamoDBExecutionRole e clique em Next.
- Na caixa Nome do papel, digite
dynamodb-spanner-lambda-rolee clique em Criar papel.
Criar um usuário do AWS IAM
Siga estas etapas para criar um usuário do AWS IAM com acesso programático aos recursos da AWS, que são usados em todo o tutorial.
- Ainda na seção IAM do console da AWS, clique em Usuários e selecione Adicionar usuários.
- Na caixa Nome de usuário, digite
dynamodb-spanner-migration. Em Tipo de acesso, marque a caixa de seleção à esquerda de Chave de acesso: acesso programático.
Clique em Next: Permissions.
Clique em Anexar políticas atuais diretamente e use a caixa Pesquisar para filtrar. Marque a caixa de seleção ao lado de cada uma das três políticas a seguir:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
Clique em Próximo: tags e Próximo: revisão e em Criar usuário.
Clique em Show para ver as credenciais. O ID da chave de acesso e a chave de acesso secreta são exibidos para o usuário recém-criado. Deixe essa janela aberta por enquanto porque as credenciais são necessárias na seção a seguir. Armazene com segurança essas credenciais porque com elas é possível fazer alterações em sua conta e afetar seu ambiente. No final deste tutorial, exclua o usuário do IAM.
Configurar a interface da linha de comando da AWS
No Cloud Shell, configure a interface da linha de comando (CLI, na sigla em inglês) da AWS.
aws configure
A seguinte resposta é exibida:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- Digite
ACCESS KEY IDeSECRET ACCESS KEYda conta do IAM da AWS que você criou. - No campo Nome da região padrão, insira
us-west-2. Deixe outros campos com os valores padrão.
- Digite
Feche a janela do console do AWS IAM.
Entenda o modelo de dados
A seção a seguir descreve as semelhanças e as diferenças entre tipos de dados, chaves e índices do Amazon DynamoDB e do Spanner.
Tipos de dados
O Spanner usa tipos de dados do GoogleSQL. A tabela a seguir descreve como os tipos de dados (em inglês) do Amazon DynamoDB se relacionam com os tipos de dados do Cloud Spanner.
| Amazon DynamoDB | Spanner |
|---|---|
| Número | Dependendo da precisão ou uso pretendido, pode ser mapeado como INT64, FLOAT64, TIMESTAMP ou DATE. |
| String | String |
| Booleano | BOOL |
| Nulo | Nenhum tipo explícito. Colunas podem conter valores nulos. |
| Binário | Bytes |
| Conjuntos | Matriz |
| Mapa e lista | Struct se a estrutura for consistente e puder ser descrita usando a sintaxe da tabela DDL. |
Chave primária
Uma chave primária do Amazon DynamoDB estabelece exclusividade e pode ser uma chave de hash ou uma combinação de uma chave de hash, além de uma chave de intervalo. Neste tutorial, iniciamos demonstrando a migração de uma tabela do Amazon DynamoDB em que a chave primária é uma chave de hash. Essa chave de hash se torna a chave principal da sua tabela do Spanner. Posteriormente, na seção sobre tabelas intercaladas, você modela uma situação em que uma tabela do Amazon DynamoDB usa uma chave primária composta de uma chave de hash e uma chave de intervalo.
Índices secundários
Tanto o Amazon DynamoDB quanto o Spanner são compatíveis com a criação de um índice em um atributo de chave não primária. Anote todos os índices secundários na tabela do Amazon DynamoDB para criá-los na tabela do Spanner, que é abordada em uma seção posterior deste tutorial.
Tabela de amostra
Para facilitar este tutorial, migre a seguinte tabela de amostra do Amazon DynamoDB para o Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| Nome da tabela |
Migration
|
Migration
|
| Chave primária |
"Username" : String
|
"Username" : STRING(1024)
|
| Tipo de chave | Hash | n/a |
| Outros campos |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Preparar a tabela do Amazon DynamoDB
Na seção a seguir, você cria uma tabela de origem do Amazon DynamoDB e a preenche com dados.
No Cloud Shell, crie uma tabela do Amazon DynamoDB que use os atributos da tabela de amostra.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75Verifique se o status da tabela é
ACTIVE.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'Preencha a tabela com dados de amostra.
python3 make-fake-data.py --table Migration --items 25000
Criar um banco de dados do Spanner
Você cria uma instância do Spanner com a menor capacidade de computação possível: 100 unidades de processamento. Essa capacidade de computação é suficiente para o escopo deste tutorial. Para uma implantação de produção, consulte a documentação de instâncias do Spanner para determinar a capacidade de computação apropriada para atender aos requisitos de desempenho de seu banco de dados.
Neste exemplo, você cria um esquema de tabela ao mesmo tempo que o banco de dados. Também é possível (e comum) realizar atualizações de esquema depois de criar o banco de dados.
Crie uma instância do Spanner na mesma região em que você define a zona padrão do Compute Engine. Por exemplo,
us-central1gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Crie um banco de dados na instância do Spanner com a tabela de exemplo.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"
Preparar a migração
Nas próximas seções, mostramos como exportar a tabela de origem do Amazon DynamoDB e configurar a replicação do Pub/Sub para capturar as alterações no banco de dados que ocorrerem durante a exportação.
Alterações de stream no Pub/Sub
Use uma função do AWS Lambda para transmitir alterações de banco de dados no Pub/Sub.
No Cloud Shell, ative os fluxos do Amazon DynamoDB na sua tabela de origem.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGESConfigure um tópico do Pub/Sub para receber as alterações.
gcloud pubsub topics create spanner-migration
A seguinte saída é exibida:
Created topic [projects/your-project/topics/spanner-migration].
Crie uma conta de serviço do IAM para enviar atualizações da tabela ao tópico do Pub/Sub.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"A seguinte saída é exibida:
Created service account [spanner-migration].
Crie uma vinculação de política do IAM para que a conta de serviço tenha permissão para publicar no Pub/Sub. Substitua
GOOGLE_CLOUD_PROJECTpelo nome do projeto do Google Cloud.gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comA seguinte resposta é exibida:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
Crie credenciais para a conta de serviço.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comA seguinte resposta é exibida:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
Prepare e empacote a função do AWS Lambda para enviar as alterações da tabela do Amazon DynamoDB ao tópico do Pub/Sub.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub
cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd -
zip -g pubsub-lambda.zip ddbpubsub.pyCrie uma variável para capturar o Nome de Recurso da Amazon (ARN na sigla em inglês) da função de execução do Lambda que você criou anteriormente.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)Use o pacote
pubsub-lambda.zippara criar a função do AWS Lambda.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"A seguinte resposta é exibida:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128,
... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Crie uma variável para capturar o ARN do fluxo do Amazon DynamoDB para sua tabela.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Anexe a função Lambda à tabela do Amazon DynamoDB.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONPara otimizar a capacidade de resposta durante o teste, adicione
--batch-size 1ao final do comando anterior, que aciona a função sempre que você cria, atualiza ou exclui um item.Você verá um resultado semelhante a este:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...
Exportar a tabela do Amazon DynamoDB para o Amazon S3
No Cloud Shell, crie uma variável para um nome de um bucket que você vai usar em várias das seções a seguir.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportCrie um bucket do Amazon S3 para receber a exportação do DynamoDB.
aws s3 mb s3://${BUCKET}No AWS Management Console, acesse DynamoDB e clique em Tabelas.
Clique na tabela
Migration.Na guia Exportações e stream, clique em Exportar para S3.
Ative
point-in-time-recovery(PITR), se solicitado.Clique em Procurar S3 para escolher o bucket do S3 que você criou anteriormente.
Clique em Exportar.
Clique no ícone Atualizar para atualizar o status do job de exportação. A exportação do job leva vários minutos.
Quando o processo terminar, observe o bucket de saída.
aws s3 ls --recursive s3://${BUCKET}Essa etapa pode levar cerca de cinco minutos. Após a conclusão, você verá uma saída como a seguinte:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
Faça a migração
Agora que a entrega de Pub/Sub está em vigor, é possível avançar quaisquer alterações de tabela que ocorreram após a exportação.
Copiar a tabela exportada para o Cloud Storage
No Cloud Shell, crie um bucket do Cloud Storage para receber os arquivos exportados do Amazon S3.
gsutil mb gs://${BUCKET}Sincronize os arquivos do Amazon S3 com o Cloud Storage. Para a maioria das operações de cópia, o comando
rsyncé efetivo. Se os arquivos de exportação forem grandes (vários GB ou mais), use o serviço de transferência do Cloud Storage para gerenciar a transferência em segundo plano.gsutil rsync -d -r s3://${BUCKET} gs://${BUCKET}
Importar os dados em lote
Para gravar os dados dos arquivos exportados na tabela do Spanner, execute um job do Dataflow com código de amostra do Apache Beam.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Para acompanhar o progresso do job de importação, acesse o Dataflow no console do Google Cloud.
Enquanto o job está em execução, é possível assistir ao gráfico de execução para examinar os registros. Clique no job que mostra o Status Em execução.
Clique em cada etapa para ver quantos elementos foram processados. A importação é concluída quando todas as etapas forem bem-sucedidas. O mesmo número de elementos criados em sua tabela do Amazon DynamoDB é processado em cada etapa.
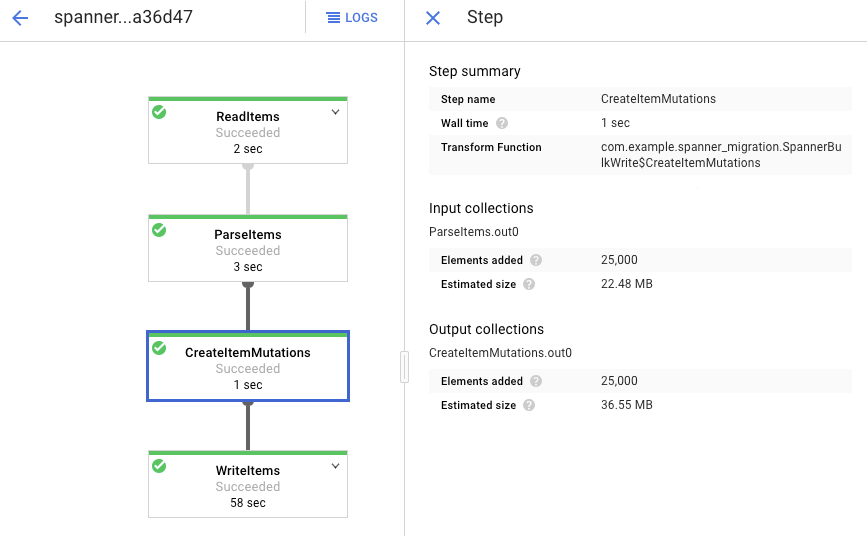
Verifique se o número de registros na tabela de Spanner de destino corresponde ao número de itens na tabela do Amazon DynamoDB.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"A seguinte saída é exibida:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
Crie uma amostra de entradas aleatórias em cada tabela para garantir que os dados sejam consistentes.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"A seguinte resposta é exibida:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
Consulte a tabela do Amazon DynamoDB com o mesmo
Usernameretornado da consulta do Spanner na etapa anterior. Por exemplo,aallen2538. O valor é específico para os dados de amostra no seu banco de dados.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'Os valores dos outros campos precisam corresponder aos valores da saída do Spanner. A seguinte resposta é exibida:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }
Replicar novas alterações
Quando o job de importação em lote estiver concluído, você configura um job de streaming para gravar atualizações contínuas da tabela de origem no Spanner. Você assina os eventos do Pub/Sub e os escreve no Spanner
A função Lambda que você criou está configurada para capturar alterações na tabela de origem do Amazon DynamoDB e publicá-las no Pub/Sub.
Crie uma assinatura para o tópico do Pub/Sub para o qual o AWS Lambda envia eventos.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migrationA seguinte resposta é exibida:
Created subscription [projects/your-project/subscriptions/spanner-migration].
Para transmitir as alterações que chegam ao Pub/Sub para gravar na tabela do Spanner, execute o job do Dataflow no Cloud Shell.
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"Semelhante à etapa de carregamento em lote, para acompanhar o progresso do job, no console do Google Cloud, acesse o Dataflow.
Clique no job que tem o Status Em execução.
O gráfico de processamento mostra uma resposta semelhante à anterior, mas cada item processado é contado na janela de status. O tempo de atraso do sistema é uma estimativa aproximada de quanto atraso esperar antes que as alterações apareçam na tabela do Spanner.
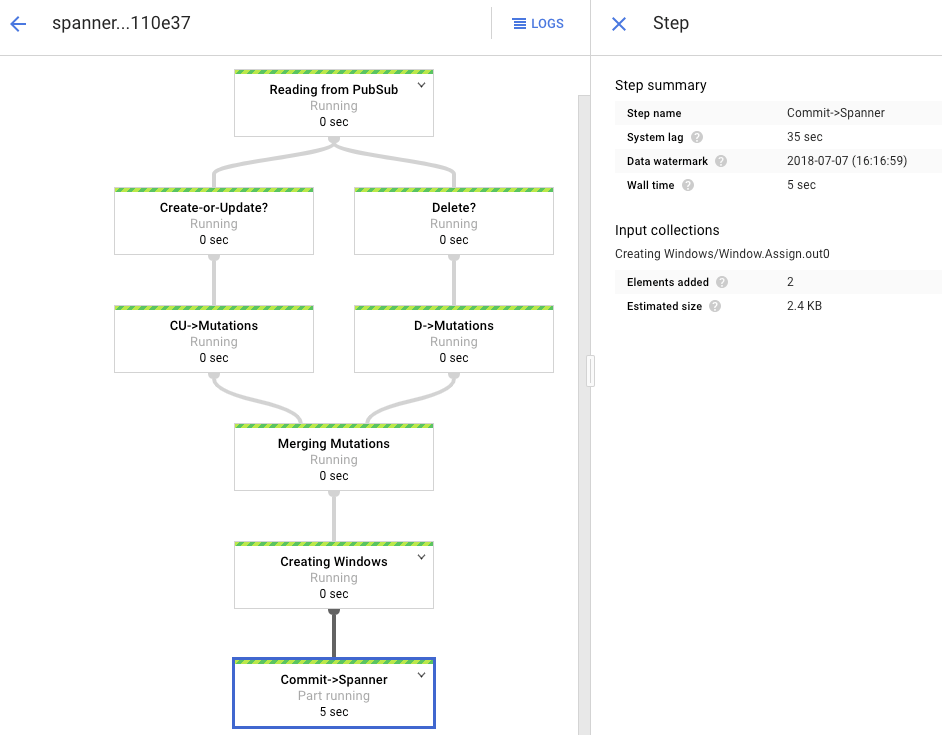
O job do Dataflow que você executou na fase de carregamento em lote era um conjunto finito de entrada, também conhecido como um conjunto de dados limitado. Esse job do Dataflow usa o Pub/Sub como uma fonte de streaming e é considerado ilimitado. Para ver mais informações sobre esses dois tipos de fontes, consulte a seção sobre PCollections no guia de programação do Apache Beam. O job do Dataflow nesta etapa foi criado para permanecer ativo e, portanto, não é encerrado quando concluído. O job de streaming do Dataflow permanece no status Em execução, em vez do status Concluído.
Verificar a replicação
Você faz algumas alterações na tabela de origem para verificar se as alterações são replicadas para a tabela do Spanner.
Consulte uma linha inexistente no Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"A operação não retornará nenhum resultado.
Crie um registro no Amazon DynamoDB com a mesma chave usada na consulta do Spanner. Se o comando for executado com sucesso, não haverá resposta.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'Execute a mesma consulta novamente para verificar se a linha está agora no Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"A resposta mostra a linha inserida:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
Altere alguns atributos no item original e atualize a tabela do Amazon DynamoDB.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEWVocê verá um resultado semelhante a este:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }Verifique se as alterações são propagadas para a tabela do Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"A resposta aparece da seguinte maneira:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Exclua o item de teste da tabela de origem do Amazon DynamoDB.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'Verifique se a linha correspondente foi excluída da tabela do Spanner. Quando a mudança é propagada, o comando a seguir não retorna nenhuma linha:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"
Usar tabelas intercaladas
O Spanner é compatível com o conceito de tabelas intercaladas. Esse é um modelo de concepção em que um item de nível superior tem vários itens aninhados relacionados a esse item de nível superior, como um cliente e os pedidos, ou um jogador e as pontuações no jogo. Se sua tabela de origem do Amazon DynamoDB usa uma chave primária composta de uma chave de hash e uma chave de intervalo, é possível modelar um esquema de tabela intercalada, conforme mostrado no diagrama a seguir. Essa estrutura permite consultar com eficiência a tabela intercalada ao unir campos na tabela pai.

Aplicar índices secundários
É uma prática recomendada aplicar índices secundários às tabelas do Spanner depois de carregar os dados. Agora que a replicação está funcionando, você configura um índice secundário para acelerar as consultas. Assim como as tabelas do Spanner, os índices secundários do Spanner são totalmente consistentes. Eles não têm consistência eventual, o que é comum em muitos bancos de dados NoSQL. Esse recurso pode ajudar a simplificar a concepção do aplicativo.
Execute uma consulta que não use índices. Você está procurando as N ocorrências principais, considerando um determinado valor de coluna. Essa é uma consulta comum no Amazon DynamoDB para eficiência do banco de dados.
Acesse o Spanner.
Clique em Spanner Studio.
No campo Consulta, insira a consulta a seguir e clique em Executar consulta.
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
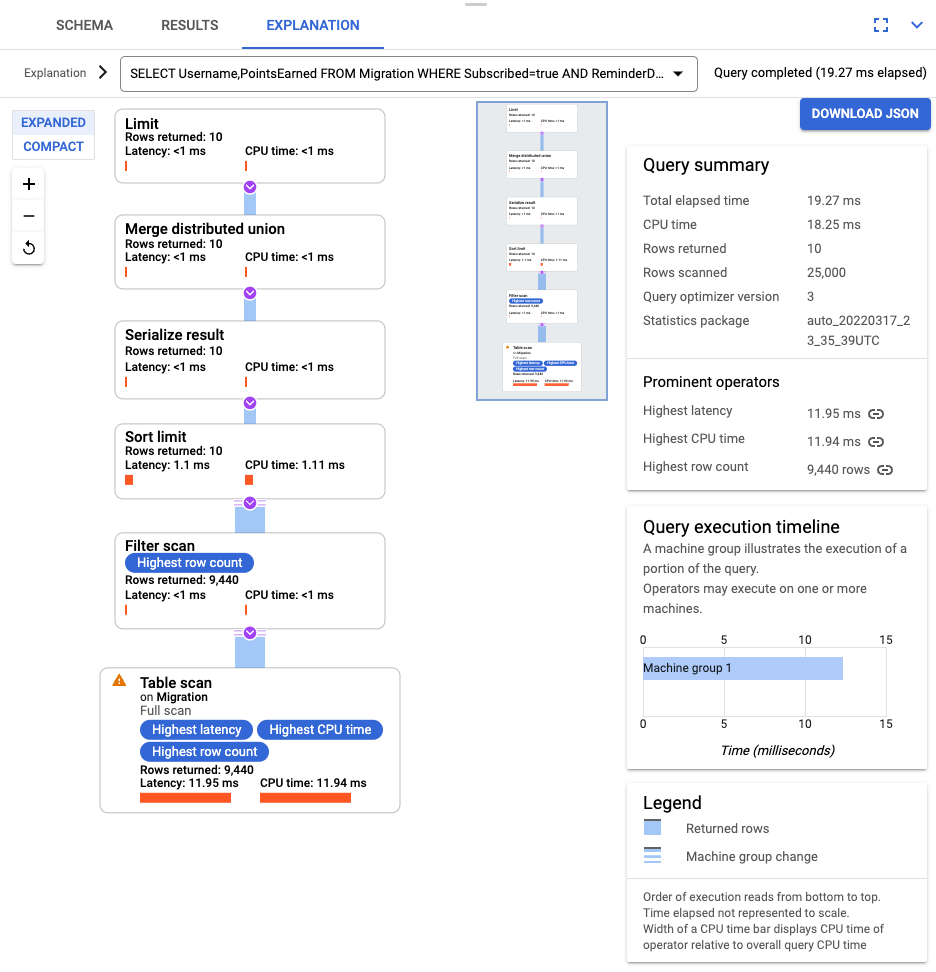
Depois que a consulta for executada, clique em Explicação e anote as linhas verificadas em relação às linhas retornadas. Sem um índice, o Spanner verifica a tabela inteira para retornar um pequeno subconjunto de dados que corresponde à consulta.
Se isso representar uma consulta comum, crie um índice composto nas colunas Subscribed e ReminderDate. No console do Spanner, selecione Indexesndices no painel de navegação à esquerda e clique em Criar índice.
Na caixa de texto, insira a definição do índice.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
Para começar a construir o banco de dados em segundo plano, clique em Criar.
Depois que o índice for criado, execute a consulta novamente e adicione o índice.
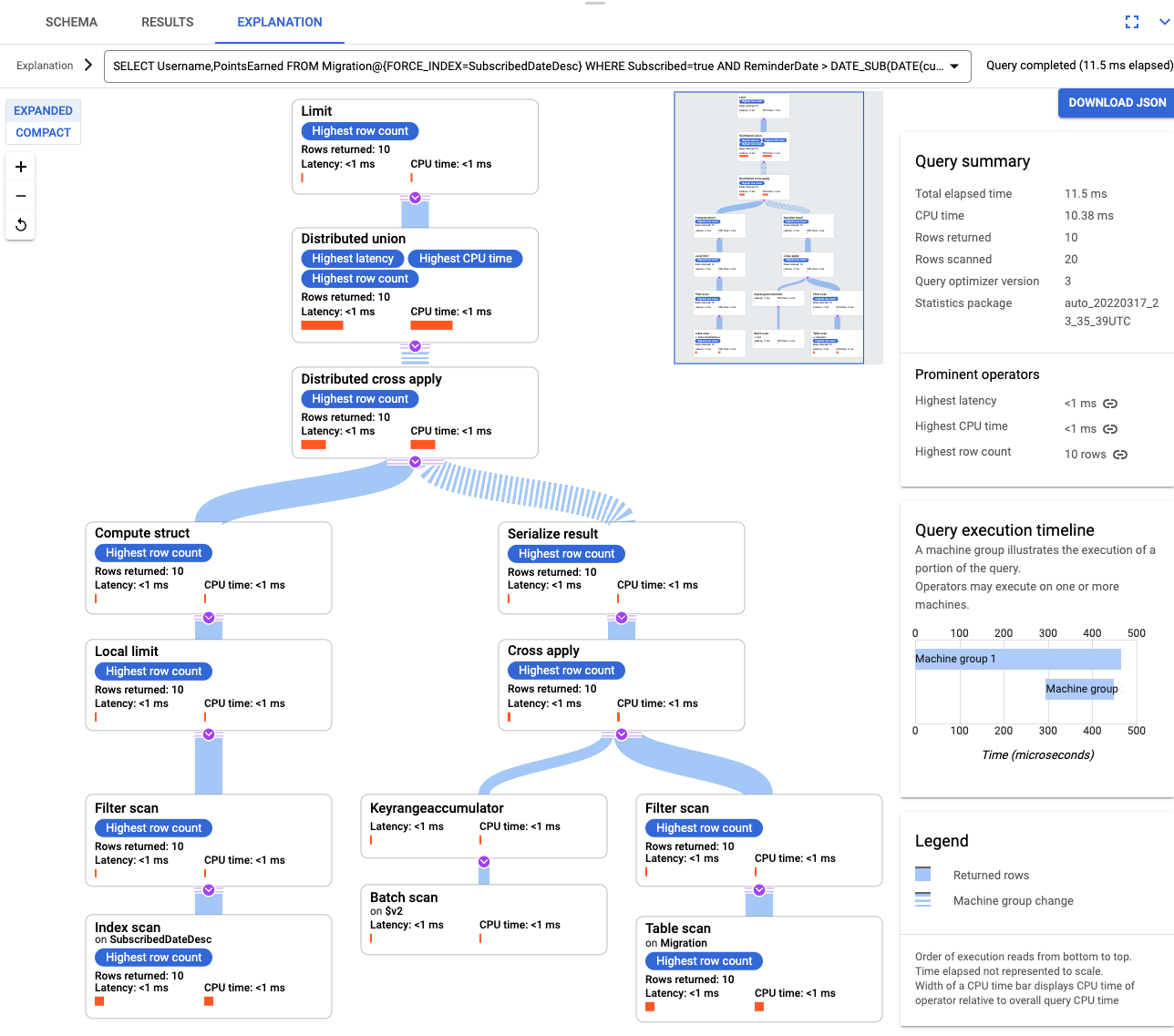
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10Examine a explicação da consulta novamente. Observe que o número de linhas verificadas diminuiu. As linhas retornadas em cada etapa correspondem ao número retornado pela consulta.
Índices intercalados
É possível configurar índices intercalados no Spanner. Os índices secundários discutidos na seção anterior estão na raiz da hierarquia do banco de dados e usam índices da mesma maneira que um banco de dados convencional. Um índice intercalado está dentro do contexto de sua linha intercalada. Consulte opções de índice para ver mais detalhes sobre onde aplicar índices intercalados.
Ajuste de acordo com seu modelo de dados
Para adaptar a parte de migração deste tutorial à sua própria situação, modifique os arquivos de origem do Apache Beam. É importante não alterar o esquema de origem durante a janela de migração real, caso contrário, você pode perder dados.
Para analisar o JSON recebido e criar mutações, use o GSON. Ajuste a definição JSON para corresponder aos seus dados.
Ajuste o mapeamento JSON correspondente.
Nas etapas anteriores, você modificou o código-fonte do Apache Beam para importação em massa. Modifique o código-fonte da parte de streaming do pipeline de maneira semelhante. Por fim, ajuste os scripts de criação de tabelas, esquemas e índices do banco de dados de destino do Spanner.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Exclua o projeto
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
Excluir recursos da AWS
Se sua conta da AWS for usada fora deste tutorial, tenha cuidado ao excluir os seguintes recursos:
- Exclua a tabela do DynamoDB chamada Migração.
- Exclua o bucket do Amazon S3 e a função Lambda que você criou durante as etapas de migração.
- Por fim, exclua o usuário do AWS IAM criado durante este tutorial.
A seguir
- Leia sobre como otimizar seu esquema do Spanner.
- Saiba como usar o Dataflow para situações mais complexas.