En este documento, se describe cómo medir el rendimiento del sistema de inferencia de TensorFlow que creaste en Implementa un sistema de inferencia de TensorFlow escalable. Además, se muestra cómo aplicar el ajuste de parámetros para mejorar la capacidad de procesamiento del sistema.
La implementación se basa en la arquitectura de referencia que se describe en Sistema de inferencia de TensorFlow escalable.
Esta serie está dirigida a desarrolladores familiarizados con Google Kubernetes Engine y con los marcos de trabajo de aprendizaje automático (AA), incluidos TensorFlow y TensorRT.
Este documento no está diseñado para proporcionar los datos de rendimiento de un sistema en particular. En cambio, ofrece orientación general sobre el proceso de medición del rendimiento. Las métricas de rendimiento que ves, como las de Solicitudes totales por segundo (RPS) y Tiempos de respuesta (ms), variarán según el modelo entrenado, el software y versiones de hardware que uses.
Arquitectura
Para obtener una descripción general de la arquitectura del sistema de inferencia de TensorFlow, consulta Sistema de inferencia de TensorFlow escalable.
Objetivos
- Definir el objetivo de rendimiento y las métricas
- Medir el rendimiento de referencia
- Realizar la optimización del gráfico
- Medir la conversión de FP16
- Medir la cuantización INT8
- Ajustar la cantidad de instancias
Costos
Para obtener detalles sobre los costos asociados con la implementación, consulta Costos.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
Asegúrate de que ya completaste los pasos en Implementa un sistema de inferencia de TensorFlow escalable.
En este documento, usarás las siguientes herramientas:
- Una terminal SSH de la instancia de trabajo que preparaste en Crea un entorno de trabajo
- El panel de Grafana que preparaste en Implementa servidores de supervisión con Prometheus y Grafana
- La consola de Locust que preparaste en Implementa una herramienta de prueba de carga
Configura el directorio
En la consola de Google Cloud, ve a Compute Engine > Instancias de VM.
Verás la instancia de
working-vmque creaste.Para abrir la consola de la terminal de la instancia, haz clic en SSH.
En la terminal SSH, establece el directorio actual como el subdirectorio
client:cd $HOME/gke-tensorflow-inference-system-tutorial/clientEn este documento, ejecutarás todos los comandos desde ese directorio.
Define el objetivo de rendimiento
Cuando mides el rendimiento de los sistemas de inferencia, debes definir el objetivo de rendimiento y las métricas de rendimiento apropiadas según el caso de uso del sistema. A modo de demostración, en este documento, se usan los siguientes objetivos de rendimiento:
- Al menos el 95% de las solicitudes reciben respuestas en un plazo de 100 ms.
- La capacidad de procesamiento total, que se representa mediante solicitudes por segundo (RPS), mejora sin afectar el objetivo anterior.
Con estas suposiciones, deberás medir y mejorar la capacidad de procesamiento de los siguientes modelos ResNet-50 con diferentes optimizaciones. Cuando un cliente envía solicitudes de inferencia, especifica el modelo con uno de los nombres de modelo en esta tabla.
| Nombre del modelo | Optimización |
|---|---|
original |
Modelo original (sin optimización con TF-TRT) |
tftrt_fp32 |
Optimización de gráficos (tamaño del lote: 64, grupos de instancias: 1) |
tftrt_fp16 |
Conversión a FP16 y optimización de gráficos (tamaño de lote: 64, grupos de instancias: 1) |
tftrt_int8 |
Cuantización con INT8 y optimización de gráficos (tamaño de lote: 64, grupos de instancias: 1) |
tftrt_int8_bs16_count4 |
Cuantización con INT8 y optimización de gráficos (tamaño de lote: 16, grupos de instancias: 4) |
Medir el rendimiento de referencia
Comienzas con TF-TRT como modelo de referencia para medir el rendimiento del modelo original no optimizado. Debes comparar el rendimiento de otros modelos con el original para evaluar de forma cuantitativa la mejora en el rendimiento. Cuando implementaste Locust, ya se configuró para enviar solicitudes del modelo original.
Abre la consola de Locust que preparaste en Implementa una herramienta de prueba de carga.
Confirma que el número de clientes (denominado secundarios) sea 10.
Si es inferior a 10, los clientes siguen iniciándose. En ese caso, espera unos minutos hasta que sea 10.
Mide el rendimiento:
- En el campo Cantidad de usuarios que se simularán, ingresa
3000. - En el campo Velocidad de generación, ingresa
5. - Para aumentar la cantidad de usos simulados de 5 por segundo hasta que alcance los 3,000, haz clic en Comenzar a generar.
- En el campo Cantidad de usuarios que se simularán, ingresa
Haz clic en Gráficos.
Los gráficos muestran los resultados del rendimiento. Observa que, si bien el valor Solicitudes totales por segundo aumenta de forma lineal, el valor Tiempos de respuesta (ms) aumenta en consecuencia.
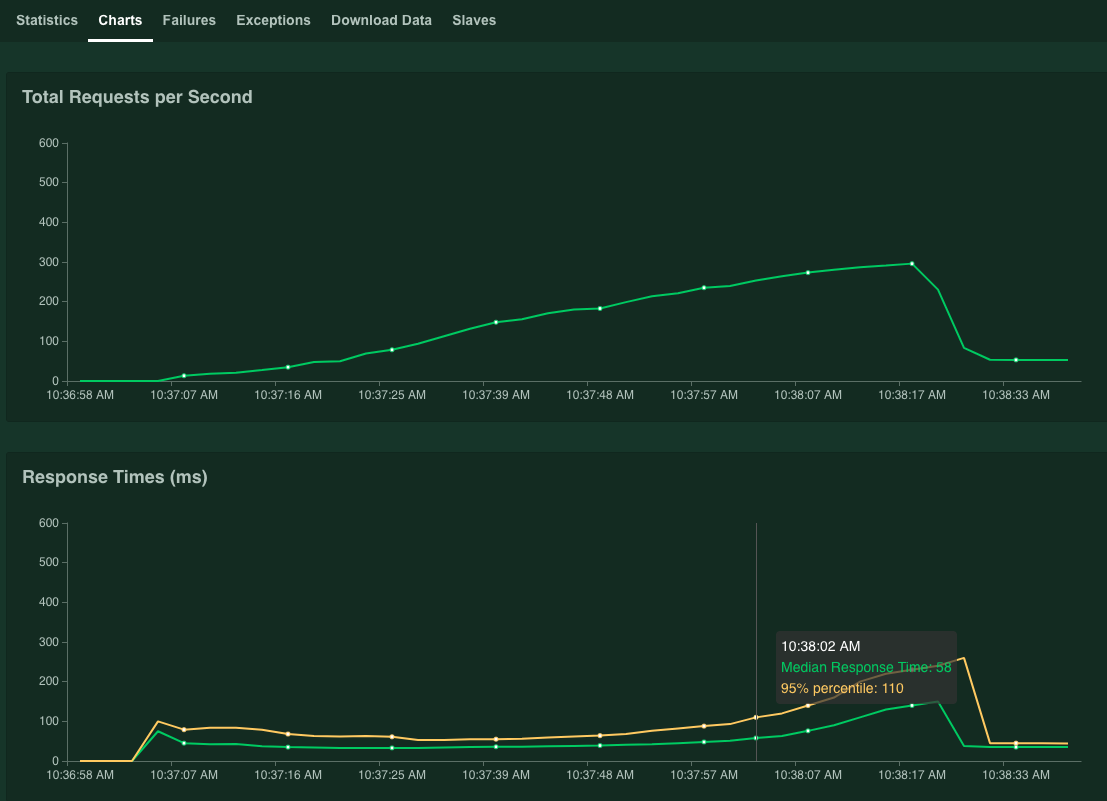
Cuando el valor del percentil 95 de los tiempos de respuesta supere los 100 ms, haz clic en Detener para parar la simulación.
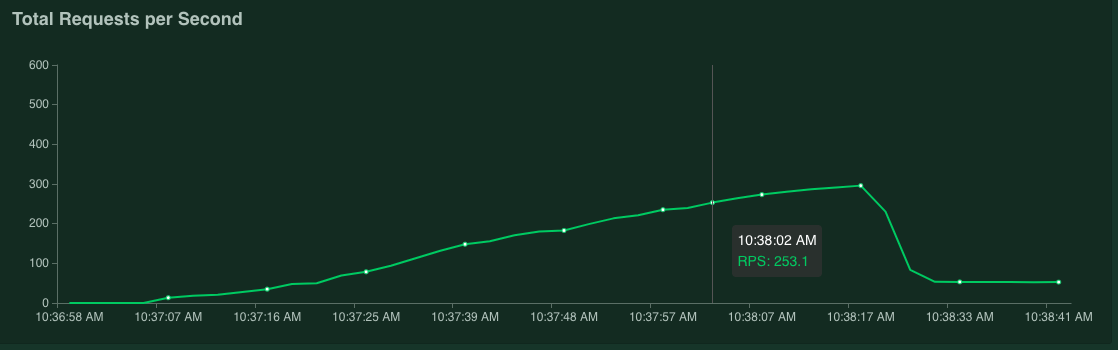
Si mueves el puntero del mouse sobre el gráfico, puedes verificar la cantidad de solicitudes por segundo que corresponden al momento en que el valor del percentil 95% de los tiempos de respuesta superó los 100 ms.
Por ejemplo, en la captura de pantalla siguiente, el número de solicitudes por segundo es 253.1.
Te recomendamos que repitas esta medición varias veces y tengas un promedio para representar la fluctuación.
En la terminal de SSH, reinicia Locust:
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustPara repetir la medición, repite este procedimiento.
Optimiza los gráficos
En esta sección, medirás el rendimiento del modelo tftrt_fp32, que está optimizado con TF-TRT para la optimización de gráficos. Esta es una optimización común que es compatible con la mayoría de las tarjetas de GPU de NVIDIA.
En la terminal de SSH, reinicia la herramienta de prueba de carga:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustEl recurso
configmapespecifica el modelo comotftrt_fp32.Reinicia el servidor de Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Espera unos minutos hasta que los procesos del servidor estén listos.
Verifica el estado del servidor:
kubectl get podsEl resultado es similar al siguiente, en el que la columna
READYmuestra el estado del servidor:NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sEl valor
1/1en la columnaREADYindica que el servidor está listo.Mide el rendimiento:
- En el campo Cantidad de usuarios que se simularán, ingresa
3000. - En el campo Velocidad de generación, ingresa
5. - Para aumentar la cantidad de usos simulados de 5 por segundo hasta que alcance los 3,000, haz clic en Comenzar a generar.
Los gráficos muestran la mejora del rendimiento de la optimización del gráfico TF-TRT.
Por ejemplo, tu gráfico puede mostrar que el número de solicitudes por segundo ahora es de 381 con un tiempo de respuesta medio de 59 ms.
- En el campo Cantidad de usuarios que se simularán, ingresa
Convertir a FP16
En esta sección, medirás el rendimiento del modelo tftrt_fp16 que está optimizado con TF-TRT para la optimización de gráficos y la conversión a FP16. Esta es una optimización disponible para NVIDIA T4.
En la terminal de SSH, reinicia la herramienta de prueba de carga:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustReinicia el servidor de Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Espera unos minutos hasta que los procesos del servidor estén listos.
Mide el rendimiento:
- En el campo Cantidad de usuarios que se simularán, ingresa
3000. - En el campo Velocidad de generación, ingresa
5. - Para aumentar la cantidad de usos simulados de 5 por segundo hasta que alcance los 3,000, haz clic en Comenzar a generar.
Los gráficos muestran la mejora en el rendimiento de la conversión de FP16, además de la optimización del gráfico de TF-TRT.
Por ejemplo, tu gráfico puede mostrar que el número de solicitudes por segundo es de 1,072.5 con un tiempo de respuesta medio de 63 ms.
- En el campo Cantidad de usuarios que se simularán, ingresa
Cuantiza con INT8
En esta sección, medirás el rendimiento del modelo tftrt_int8 que está optimizado con TF-TRT para la optimización de gráficos y la cuantización con INT8. Esta optimización está disponible para NVIDIA T4.
En la terminal de SSH, reinicia la herramienta de prueba de carga.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustReinicia el servidor de Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Espera unos minutos hasta que los procesos del servidor estén listos.
Mide el rendimiento:
- En el campo Cantidad de usuarios que se simularán, ingresa
3000. - En el campo Velocidad de generación, ingresa
5. - Para aumentar la cantidad de usos simulados de 5 por segundo hasta que alcance los 3,000, haz clic en Comenzar a generar.
Los gráficos muestran los resultados del rendimiento.
Por ejemplo, tu gráfico puede mostrar que el número de solicitudes por segundo es 1,085.4 con un tiempo de respuesta medio de 32 ms.
En este ejemplo, el resultado no es un aumento significativo en el rendimiento en comparación con la conversión a FP16. En teoría, la GPU NVIDIA T4 puede manejar modelos de cuantización con INT8 más rápido que los modelos de conversión a FP16. En este caso, puede haber un cuello de botella distinto del rendimiento de la GPU. Puedes confirmarlo con los datos de uso de GPU en el panel de Grafana. Por ejemplo, si el uso es inferior al 40%, significa que el modelo no puede usar el rendimiento de la GPU por completo.
Como se muestra en la siguiente sección, es posible facilitar este cuello de botella aumentando la cantidad de grupos de instancias. Por ejemplo, aumenta la cantidad de grupos de instancias de 1 a 4 y disminuye el tamaño del lote de 64 a 16. Este enfoque mantiene la cantidad total de solicitudes procesadas en una sola GPU en 64.
- En el campo Cantidad de usuarios que se simularán, ingresa
Ajustar la cantidad de instancias
En esta sección, medirás el rendimiento del modelo tftrt_int8_bs16_count4. Este modelo tiene la misma estructura que tftrt_int8, pero debes cambiar el tamaño del lote y la cantidad de grupos de instancias como se describe en Cuantizar con INT8.
En la terminal de SSH, reinicia Locust:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustEn este comando, debes usar el recurso
configmappara especificar el modelo comotftrt_int8_bs16_count4. También aumentas la cantidad de Pods de cliente de Locust para generar suficientes cargas de trabajo para medir la limitación de rendimiento del modelo.Reinicia el servidor de Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Espera unos minutos hasta que los procesos del servidor estén listos.
Mide el rendimiento:
- En el campo Cantidad de usuarios que se simularán, ingresa
3000. - En el campo Velocidad de generación, ingresa
15. Para este modelo, puede tomar mucho tiempo alcanzar el límite de rendimiento si la velocidad de generación se establece en5. - Para aumentar la cantidad de usos simulados de 5 por segundo hasta que alcance los 3,000, haz clic en Comenzar a generar.
Los gráficos muestran los resultados del rendimiento.
Por ejemplo, tu gráfico puede mostrar que el número de solicitudes por segundo es 2,236.6 con un tiempo de respuesta medio de 38 ms.
Cuando ajustas la cantidad de instancias, casi puedes duplicar las solicitudes por segundo. Observa que el uso de GPU aumentó en el panel de Grafana (por ejemplo, el uso puede alcanzar el 75%).
- En el campo Cantidad de usuarios que se simularán, ingresa
Rendimiento y varios nodos
Cuando escalas con varios nodos, mides el rendimiento de un mismo Pod. Debido a que los procesos de inferencia se ejecutan de forma independiente en Pods que no comparten nada, puedes suponer que la capacidad de procesamiento total escalará de manera lineal con la cantidad de Pods. Esta suposición se aplica siempre que no haya cuellos de botella, como el ancho de banda de la red entre clientes y servidores de inferencia.
Sin embargo, es importante comprender cómo se balancean las solicitudes de inferencia entre varios servidores de inferencia. Triton usa el protocolo de gRPC para establecer una conexión TCP entre un cliente y un servidor. Debido a que Triton vuelve a usar la conexión establecida para enviar varias solicitudes de inferencia, las solicitudes de un solo cliente siempre se envían al mismo servidor. A fin de distribuir solicitudes para varios servidores, debes usar varios clientes.
Limpia
Puedes borrar el proyecto para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en esta serie.
Borra el proyecto
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
¿Qué sigue?
- Aprende a minimizar la latencia de la entrega de predicciones en tiempo real en el aprendizaje automático.
- Más información sobre Google Kubernetes Engine (GKE).
- Obtén más información sobre Cloud Load Balancing.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.