Tutorial de migração do Teradata para o BigQuery
Neste documento, descrevemos como migrar do Teradata para o BigQuery usando dados de exemplo. Ele fornece uma prova de conceito que orienta você no processo de transferência de esquema e dados de um armazenamento de dados Teradata para o BigQuery.
Objetivos
- Gerar dados sintéticos e fazer o upload para o Teradata.
- Migrar o esquema e os dados para o BigQuery usando o BQDT (serviço de transferência de dados do BigQuery, na sigla em inglês).
- Verificar se as consultas retornam os mesmos resultados no Teradata e no BigQuery.
Custos
Neste guia de início rápido, usamos o seguinte componente faturável do Google Cloud:
- BigQuery: este tutorial armazena aproximadamente 1 GB de dados no BigQuery e processa menos de 2 GB ao executar as consultas uma vez. Como parte do Nível gratuito do Google Cloud, o BigQuery oferece alguns recursos gratuitos até um limite específico. Esses limites de uso gratuito estão disponíveis durante e após o período de avaliação gratuita. Se você ultrapassar esses limites de uso e não estiver mais no período de avaliação gratuita, será cobrado de acordo com os preços na página de preços do BigQuery.
Use a calculadora de preços para gerar uma estimativa de custo com base no uso previsto.
Prerequisites
- Verifique se você tem permissões de gravação e execução em uma máquina com acesso à Internet para fazer o download e executar a ferramenta de geração de dados.
- Certifique-se de que você consegue se conectar a um banco de dados do Teradata.
Verifique se a máquina tem as ferramentas do cliente BTEQ e FastLoad (links em inglês) do Teradata instaladas. As ferramentas do cliente podem ser encontradas no site do Teradata (em inglês). Se precisar de ajuda para instalar essas ferramentas, peça ao administrador do sistema detalhes sobre como instalar, configurar e executá-las. Como alternativa, ou além do BTEQ, é possível fazer as etapas a seguir:
- Instale uma ferramenta com uma interface gráfica, como o DBeaver (em inglês).
- Instale o Driver SQL do Teradata para Python para interações de script com o banco de dados do Teradata.
Verifique se a máquina tem conectividade de rede com o Google Cloud para que o agente do serviço de transferência de dados do BigQuery se comunique com o BigQuery e transfira o esquema e os dados.
Introdução
Neste guia de início rápido, orientamos você ao longo de uma prova de conceito de migração. Durante o início rápido, você gerará dados sintéticos que serão carregados no Teradata. Em seguida, você usará o serviço de transferência de dados do BigQuery para mover o esquema e os dados para o BigQuery. Por fim, você executará consultas nos dois lados para comparar os resultados. O estado final é que o esquema e os dados do Teradata serão mapeados um a um no BigQuery.
Este guia de início rápido é destinado a administradores, desenvolvedores e profissionais de armazenamento de dados em geral interessados em uma experiência prática com a migração de esquema e dados usando o serviço de transferência de dados do BigQuery.
Como gerar os dados
O Transaction Processing Performance Council (TPC) (em inglês) é uma organização sem fins lucrativos que publica especificações para comparativos de mercado. Essas especificações se tornaram os padrões de fato do setor para a execução de comparativos de mercado relacionados a dados.
A especificação TPC-H (em inglês) é uma referência com foco no suporte à decisão. Neste guia de início rápido, você usa partes dessa especificação para criar as tabelas e gerar dados sintéticos no formato de um modelo de armazenamento de dados da vida real. Ainda que a especificação tenha sido criada para comparativos de mercado, neste guia de início rápido, esse modelo é usado como parte da prova de conceito de migração, não para tarefas de comparativo de mercado.
- No computador em que você se conectará ao Teradata, use um navegador da Web para fazer o download da versão mais recente disponível das ferramentas TPC-H no site da TPC (em inglês).
- Abra um terminal de comando e acesse o diretório em que você fez o download das ferramentas.
Extraia o arquivo ZIP salvo. Substitua file-name pelo nome do arquivo salvo:
unzip file-name.zip
Será extraído um diretório com um nome que inclui o número da versão das ferramentas. Esse diretório inclui o código-fonte do TPC referente à ferramenta de geração de dados DBGEN e à própria especificação TPC-H.
Acesse o subdiretório
dbgen. Use o nome do diretório pai correspondente à sua versão, como no exemplo a seguir:cd 2.18.0_rc2/dbgenCrie um makefile usando o modelo fornecido:
cp makefile.suite makefileEdite o makefile com um editor de texto. Por exemplo, use "vi" para editar o arquivo:
vi makefileNo makefile, altere os valores das variáveis a seguir:
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHDependendo do ambiente, os valores do compilador C (
CC) ouMACHINEpodem ser diferentes. Se necessário, pergunte ao administrador do sistema.Salve as alterações e feche o arquivo.
Processe o makefile:
makeGere os dados TPC-H usando a ferramenta
dbgen:dbgen -vA geração de dados leva alguns minutos. A sinalização
-v(detalhada) faz com que o comando relate o progresso. Quando a geração de dados for concluída, haverá oito arquivos ASCII com a extensão.tblna pasta atual. Eles contêm dados sintéticos delimitados por pipeline para serem carregados em cada uma das tabelas TPC-H.
Como fazer o upload de dados de amostra para o Teradata
Nesta seção, mostramos como fazer o upload de dados gerados para o banco de dados do Teradata.
Criar o banco de dados TPC-H
O cliente Teradata, chamado Basic Teradata Query (BTEQ) (em inglês), é usado para se comunicar com um ou mais servidores de banco de dados do Teradata e para executar consultas SQL nesses sistemas. Nesta seção, você usa o BTEQ para criar um novo banco de dados para as tabelas TPC-H.
Abra o cliente Teradata BTEQ:
bteqFaça login no Teradata. Substitua teradata-ip e teradata-user pelos valores correspondentes ao seu ambiente.
.LOGON teradata-ip/teradata-user
Crie um banco de dados chamado
tpchcom 2 GB de espaço alocado:CREATE DATABASE tpch AS PERM=2e+09;Saia do BTEQ:
.QUIT
Carregar os dados gerados
Nesta seção, mostramos como criar um script FastLoad para criar e carregar as tabelas de amostra. As definições da tabela são descritas na seção 1.4 da especificação TPC-H (em inglês). A seção 1.2 tem um diagrama com o relacionamento entre entidades de todo o esquema do banco de dados.
O procedimento a seguir mostra como criar a tabela lineitem, que é a maior e mais complexa das tabelas TPC-H. Quando você terminar a tabela lineitem, repita este procedimento para as tabelas restantes.
Use um editor de texto para criar um novo arquivo chamado
fastload_lineitem.fl.vi fastload_lineitem.flCopie o script a seguir no arquivo, que se conecta ao banco de dados do Teradata e cria uma tabela chamada
lineitem.No comando
logon, substitua teradata-ip, teradata-user e teradata-pwd pelos detalhes da sua conexão.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);Primeiro, o script verifica se a tabela
lineiteme as tabelas de erro temporárias não existem, para depois criar a tabelalineitem.No mesmo arquivo, adicione o código a seguir, que carrega os dados na tabela recém-criada. Preencha todos os campos da tabela (...all-fields...) nos três blocos (
define,insertevalues). Usevarcharcomo tipo de dados de carregamento.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), ...all-fields... file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, ...all-fields... ) values ( :in_ORDERKEY, :in_PARTKEY, ...all-fields... ); end loading; logoff;
O script FastLoad carrega os dados de um arquivo no mesmo diretório que você gerou na seção anterior, chamado
lineitem.tbl.Salve as alterações e feche o arquivo.
Execute o script FastLoad:
fastload < fastload_lineitem.flRepita esse procedimento para o restante das tabelas TPC-H listadas na seção 1.4 da especificação TPC-H. Certifique-se de ajustar as etapas para cada tabela.
Como migrar o esquema e os dados para o BigQuery
As instruções sobre como migrar o esquema e os dados para o BigQuery estão em um tutorial separado: Migrar dados do Teradata. Nesta seção, incluímos detalhes sobre como proceder em determinadas etapas desse tutorial. Quando você concluir as etapas do outro tutorial, retorne a este documento e avance para a próxima seção, Como verificar resultados de consulta.
Criar o conjunto de dados do BigQuery
Durante as etapas iniciais de configuração do Google Cloud, você precisa criar um conjunto de dados no BigQuery para manter as tabelas após a migração. Nomeie o conjunto de dados tpch. As consultas no final deste guia de início rápido consideram esse nome e não precisam ser modificadas.
# Use the bq utility to create the dataset
bq mk --location=US tpch
Criar uma conta de serviço
Também como parte das etapas de configuração do Google Cloud, você precisa criar uma conta de serviço do gerenciamento de identidade e acesso (IAM). Essa conta de serviço é usada para gravar os dados no BigQuery e armazenar os dados temporários no Cloud Storage.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
Conceda permissões à conta de serviço para que ela possa administrar os conjuntos de dados do BigQuery e a área temporária no Cloud Storage:
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
Criar o bucket temporário no Cloud Storage
Uma tarefa adicional na configuração do Google Cloud é criar um bucket do Cloud Storage. Esse bucket é usado pelo serviço de transferência de dados do BigQuery como uma área temporária para que os arquivos de dados sejam inseridos no BigQuery.
# Use gsutil to create the bucket
gsutil mb -c regional -l us-central1 gs://${PROJECT}-tpch
Especificar os padrões de nome da tabela
Durante a configuração de uma nova transferência no serviço de transferência de dados do BigQuery, é solicitado que você especifique uma expressão que indique quais tabelas incluir na transferência. Neste guia de início rápido, inclua todas as tabelas do banco de dados tpch.
O formato da expressão é database.table e o nome da tabela pode ser substituído por um caractere curinga. Como os caracteres curingas em Java começam com dois pontos, a expressão para transferir todas as tabelas do banco de dados tpch é:
tpch..*
Observe que há dois pontos.
Como verificar resultados de consulta
Até aqui, você criou dados de amostra, carregou os dados no Teradata e os migrou para o BigQuery usando o serviço de transferência de dados do BigQuery, conforme explicado no tutorial separado. Nesta seção, mostraremos como executar duas das consultas padrão da TPC-H para verificar se os resultados são os mesmos no Teradata e no BigQuery.
Executar a consulta do relatório de resumo de preços
A primeira consulta é a consulta do relatório de resumo de preços (seção 2.4.1 da especificação TPC-H). Esta consulta relata o número de itens que foram faturados, enviados e devolvidos em uma determinada data.
A listagem a seguir mostra a consulta completa:
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Execute a consulta no Teradata:
- Execute o BTEQ e conecte-se ao Teradata. Para detalhes, consulte Criar o banco de dados TPC-H, anteriormente neste documento.
Altere o tamanho do resultado para 500 caracteres:
.set width 500Copie a consulta e cole-a no prompt do BTEQ.
O resultado será semelhante a este:
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
Execute a mesma consulta no BigQuery:
Acesse o console do BigQuery:
Copie a consulta no editor de consultas.
Verifique se o nome do conjunto de dados na linha
FROMestá correto.Clique em Executar.
O resultado é o mesmo que o resultado do Teradata.
Outra opção é escolher intervalos de tempo maiores na consulta para garantir que todas as linhas da tabela sejam verificadas.
Executar a consulta de volume do fornecedor local
A segunda consulta de exemplo é o relatório de consulta de volume do fornecedor local (seção 2.4.5 da especificação TPC-H). Para cada país de uma região, essa consulta retorna a receita produzida por cada item de linha em que o cliente e o fornecedor estavam naquele país. Esses resultados são úteis para, por exemplo, planejar onde colocar centros de distribuição.
A listagem a seguir mostra a consulta completa:
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
Execute a consulta no Teradata BTEQ e no console do BigQuery, conforme descrito na seção anterior.
Este é o resultado retornado pelo Teradata:
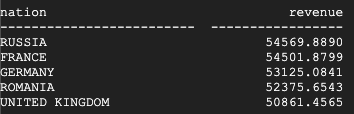
Este é o resultado retornado pelo BigQuery:
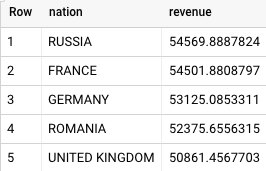
O Teradata e o BigQuery retornam os mesmos resultados.
Executar a consulta de medida de lucro do tipo de produto
O teste final para verificar a migração é a consulta de medida de lucro do tipo de produto, o último exemplo de consulta (seção 2.4.9 na especificação TPC-H). Essa consulta encontra o lucro de todas as peças encomendadas para cada país e a cada ano. Ela filtra os resultados por meio de uma substring nos nomes das peças e por um fornecedor específico.
A listagem a seguir mostra a consulta completa:
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
Execute a consulta no Teradata BTEQ e no console do BigQuery, conforme descrito na seção anterior.
Este é o resultado retornado pelo Teradata:
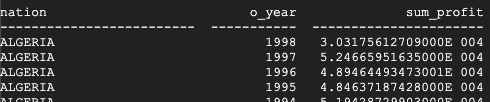
Este é o resultado retornado pelo BigQuery:
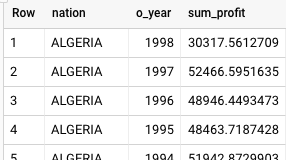
O Teradata e o BigQuery retornam os mesmos resultados, ainda que o Teradata use a notação científica para a soma.
Outras consultas
Também é possível executar as demais consultas TPC-H definidas na seção 2.4 da especificação TPC-H.
Também é possível gerar as consultas seguindo o padrão TPC-H usando a ferramenta QGEN, que está no mesmo diretório que a ferramenta DBGEN. O QGEN é criado usando o mesmo makefile que o DBGEN. Portanto, quando você executa o makefile para compilar o dbgen, também produz o executável qgen.
Para mais informações sobre as ferramentas e as opções de linha de comando, consulte o arquivo README de cada ferramenta.
Limpeza
Para evitar cobranças na sua conta do Google Cloud Platform pelos recursos usados neste tutorial, remova-os.
Exclua o projeto
A maneira mais simples de não ser cobrado é excluir o projeto criado neste tutorial.
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
- Receba instruções passo a passo para migrar o Teradata para o BigQuery.