BigQuery로 Teradata 마이그레이션 튜토리얼
이 문서에서는 샘플 데이터를 사용하여 Teradata에서 BigQuery로 마이그레이션하는 방법을 설명합니다. Teradata 데이터 웨어하우스의 스키마와 데이터 모두 BigQuery로 전송하는 프로세스를 설명하는 개념 증명을 제공합니다.
목표
- 합성 데이터를 생성하여 Teradata에 업로드합니다.
- BigQuery Data Transfer Service(BQDT)를 사용하여 스키마와 데이터를 BigQuery로 마이그레이션합니다.
- 쿼리가 Teradata 및 BigQuery에서 동일한 결과를 반환하는지 확인합니다.
비용
이 빠른 시작에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
- BigQuery: 이 튜토리얼에서는 BigQuery에 데이터를 약 1GB 저장하고 쿼리를 한 번 실행할 때 데이터를 2GB 미만 처리합니다. Google Cloud 무료 등급 혜택 중 하나로 BigQuery의 일부 리소스를 특정 한도까지 무료로 사용할 수 있습니다. 무료 사용량은 무료 체험 기간 및 그 이후에도 사용할 수 있습니다. 그러나 이 사용량 한도를 소진하고 무료 체험 기간이 종료된 경우에는 BigQuery 가격 책정 페이지의 가격 정책에 따라 요금이 청구됩니다.
가격 계산기를 사용하여 예상 사용량을 기준으로 예상 비용을 산출할 수 있습니다.
기본 요건
- 데이터 생성 도구를 다운로드하고 실행할 수 있도록 인터넷에 액세스할 수 있는 머신에서 쓰기 및 실행 권한이 있는지 확인합니다.
- Teradata 데이터베이스에 연결할 수 있는지 확인합니다.
머신에 BTEQ 및 FastLoad 클라이언트 도구가 설치되어 있는지 확인합니다. Teradata 클라이언트 도구는 Teradata 웹사이트에서 다운로드할 수 있습니다. 이러한 도구를 설치하는 데 도움이 필요하면 시스템 관리자에게 도구 설치, 구성, 실행에 관한 자세한 내용을 문의하세요. BTEQ 외에 다른 대안으로 다음을 수행할 수도 있습니다.
- DBeaver와 같이 그래픽 인터페이스를 사용하는 도구를 설치합니다.
- Teradata 데이터베이스와 상호작용을 스크립트로 작성하기 위해 Python용 Teradata SQL 드라이버를 설치합니다.
BigQuery Data Transfer Service 에이전트가 BigQuery와 통신하고 스키마와 데이터를 전송할 수 있도록 머신이 Google Cloud와 네트워크에 연결되어 있는지 확인합니다.
소개
이 빠른 시작은 마이그레이션 개념 증명을 안내합니다. 빠른 시작에서는 합성 데이터를 생성하여 Teradata에 로드합니다. 그런 다음 BigQuery Data Transfer Service를 사용하여 스키마와 데이터를 BigQuery로 이전합니다. 마지막으로 양측에서 쿼리를 실행하여 결과를 비교합니다. 최종적으로는 Teradata의 스키마와 데이터가 BigQuery에서 일대일로 매핑되어야 합니다.
이 빠른 시작은 BigQuery Data Transfer Service를 사용하여 스키마 및 데이터 마이그레이션을 실습하는 데 관심이 있는 데이터 웨어하우스 관리자, 개발자, 데이터 운영자를 대상으로 합니다.
데이터 생성
TPC(Transaction Processing Performance Council)는 벤치마킹 사양을 게시하는 비영리 조직입니다. 이러한 사양은 데이터 관련 벤치마크를 실행하는 사실상의 업계 표준으로 자리 잡았습니다.
TPC-H 사양은 의사 결정 지원에 초점을 맞춘 벤치마크입니다. 이 빠른 시작에서는 이 사양 중 일부를 사용하여 테이블을 만들고, 실제 데이터 웨어하우스의 모델로 합성 데이터를 생성합니다. 사양이 벤치마킹용으로 만들어진 경우라도 이 빠른 시작에서는 이 모델을 벤치마킹 태스크가 아닌 마이그레이션 개념 증명의 일부로 사용합니다.
- Teradata에 연결할 컴퓨터에서 웹 브라우저를 사용하여 TPC 웹사이트에서 최신 버전의 TPC-H 도구를 다운로드합니다.
- 명령어 터미널을 열고 도구를 다운로드한 디렉터리로 이동합니다.
다운로드한 zip 파일의 압축을 풉니다. file-name을 다운로드한 파일의 이름으로 바꿉니다.
unzip file-name.zip
이름에 도구 버전 번호가 포함된 디렉터리가 추출됩니다. 이 디렉터리에는 DBGEN 데이터 생성 도구용 TPC 소스 코드와 TPC-H 사양 자체가 포함되어 있습니다.
dbgen하위 디렉터리로 이동합니다. 다음 예시와 같이 사용 중인 버전에 해당하는 상위 디렉터리 이름을 사용합니다.cd 2.18.0_rc2/dbgen제공된 템플릿을 사용하여 makefile을 만듭니다.
cp makefile.suite makefile텍스트 편집기에서 makefile을 수정합니다. 예를 들어 vi를 사용하여 파일을 수정합니다.
vi makefilemakefile에서 다음 변수 값을 변경합니다.
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCH환경에 따라 C 컴파일러(
CC) 또는MACHINE값이 달라질 수 있습니다. 필요한 경우 시스템 관리자에게 문의하세요.변경사항을 저장하고 파일을 닫습니다.
makefile을 처리합니다.
makedbgen도구를 사용하여 TPC-H 데이터를 생성합니다.dbgen -v데이터가 생성되는 데 몇 분 정도 걸릴 수 있습니다.
-v(verbose) 플래그를 사용하면 명령어가 진행 상황을 보고합니다. 데이터가 생성되면 현재 폴더에 확장자가.tbl인 ASCII 파일 8개가 포함된 것을 확인할 수 있습니다. 이러한 파일에는 각각의 TPC-H 테이블에 로드되는 파이프로 구분된 합성 데이터가 포함됩니다.
Teradata에 샘플 데이터 업로드
이 섹션에서는 생성된 데이터를 Teradata 데이터베이스에 업로드합니다.
TPC-H 데이터베이스 만들기
BTEQ(Basic Teradata Query)라는 Teradata 클라이언트는 1개 이상의 Teradata 데이터베이스 서버와 통신하고 해당 시스템에서 SQL 쿼리를 실행하는 데 사용됩니다. 이 섹션에서는 BTEQ를 사용하여 TPC-H 테이블에 사용할 새 데이터베이스를 만듭니다.
Teradata BTEQ 클라이언트를 엽니다.
bteqTeradata에 로그인합니다. teradata-ip 및 teradata-user를 환경에 해당하는 값으로 바꿉니다.
.LOGON teradata-ip/teradata-user
공간 2GB가 할당된
tpch라는 데이터베이스를 만듭니다.CREATE DATABASE tpch AS PERM=2e+09;BTEQ를 종료합니다.
.QUIT
생성된 데이터 로드
이 섹션에서는 FastLoad 스크립트를 만들어 샘플 테이블을 만들고 로드합니다. 테이블 정의는 TPC-H 사양의 섹션 1.4에 설명되어 있습니다. 섹션 1.2에는 전체 데이터베이스 스키마의 항목 관계 다이어그램이 있습니다.
다음 절차는 TPC-H 테이블 중에서 가장 크고 복잡한 lineitem 테이블을 만드는 방법입니다. lineitem 테이블이 생성되면 이 절차를 반복하여 나머지 테이블을 만듭니다.
텍스트 편집기를 사용하여
fastload_lineitem.fl이라는 새 파일을 만듭니다.vi fastload_lineitem.fl다음 스크립트를 파일에 복사합니다. 그러면 Teradata 데이터베이스에 연결되고
lineitem이라는 테이블이 생성됩니다.logon명령어에서 teradata-ip, teradata-user, teradata-pwd를 연결 세부정보로 바꿉니다.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);스크립트는 먼저
lineitem테이블과 임시 오류 테이블이 없는지 확인하고lineitem테이블을 만듭니다.같은 파일에서 다음 코드를 추가하여 데이터를 새로 생성된 테이블에 로드합니다. 블록 3개(
define,insert,values)에서 모든 테이블 필드(...all-fields...)를 채웁니다. 이때varchar를 로드 데이터 유형으로 사용합니다.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), ...all-fields... file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, ...all-fields... ) values ( :in_ORDERKEY, :in_PARTKEY, ...all-fields... ); end loading; logoff;
FastLoad 스크립트는 이전 섹션에서 생성한
lineitem.tbl이라는 동일한 디렉터리의 파일에서 데이터를 로드합니다.변경사항을 저장하고 파일을 닫습니다.
FastLoad 스크립트를 실행합니다.
fastload < fastload_lineitem.fl위의 절차를 반복하여 TPC-H 사양의 1.4 섹션에 표시된 나머지 TPC-H 테이블을 만듭니다. 각 테이블에 맞게 단계를 조정해야 합니다.
BigQuery로 스키마 및 데이터 마이그레이션
스키마와 데이터를 BigQuery로 마이그레이션하는 방법에 대한 안내는 별도의 튜토리얼인 Teradata에서 데이터 마이그레이션에 나와 있습니다. 이 섹션에는 이 튜토리얼의 특정 단계를 진행하는 방법에 대한 세부정보가 포함되어 있습니다. 다른 튜토리얼의 단계를 완료했으면 이 문서로 돌아와 다음 섹션인 쿼리 결과 확인을 계속 진행합니다.
BigQuery 데이터 세트 만들기
초기 Google Cloud 구성 단계에서는 테이블이 마이그레이션된 후 BigQuery에 테이블을 보관할 데이터 세트를 만들라는 메시지가 표시됩니다. 데이터 세트 이름을 tpch로 지정합니다. 이 빠른 시작의 끝부분에 있는 쿼리에서도 이 이름을 사용하게 되므로 이름을 수정할 필요는 없습니다.
# Use the bq utility to create the dataset
bq mk --location=US tpch
서비스 계정 만들기
또한 Google Cloud 구성 단계의 일부로 Identity and Access Management(IAM) 서비스 계정을 만들어야 합니다. 이 서비스 계정은 BigQuery에 데이터를 쓰고 Cloud Storage에 임시 데이터를 저장하는 데 사용됩니다.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
Cloud Storage에서 BigQuery 데이터 세트와 스테이징 영역을 관리할 수 있는 권한을 서비스 계정에 부여합니다.
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
스테이징 Cloud Storage 버킷 만들기
Google Cloud 구성의 추가 태스크 중 하나는 Cloud Storage 버킷을 만드는 것입니다. 이 버킷은 BigQuery Data Transfer Service에서 BigQuery에 수집할 데이터 파일의 스테이징 영역으로 사용됩니다.
# Use gsutil to create the bucket
gsutil mb -c regional -l us-central1 gs://${PROJECT}-tpch
테이블 이름 패턴 지정
BigQuery Data Transfer Service에서 새 전송을 구성하는 도중 전송에 포함할 테이블을 나타내는 표현식을 지정하라는 메시지가 표시됩니다. 이 빠른 시작에서는 tpch 데이터베이스의 모든 테이블을 포함합니다.
표현식 형식은 database.table이며 테이블 이름을 와일드 카드로 바꿀 수 있습니다. 자바에서 와일드 카드는 점 두 개로 시작하므로 tpch 데이터베이스의 모든 테이블을 전송하는 표현식은 다음과 같습니다.
tpch..*
위 예시에는 점 두 개가 있습니다.
쿼리 결과 확인
지금까지 샘플 데이터를 만들고, 이 데이터를 Teradata에 업로드한 다음 별도의 튜토리얼에 설명된 대로 BigQuery Data Transfer Service를 사용하여 BigQuery로 마이그레이션했습니다. 이 섹션에서는 2개의 TPC-H 표준 쿼리를 실행하여 Teradata와 BigQuery에서 같은 결과가 반환되는지 확인합니다.
가격 요약 보고서 쿼리 실행
첫 번째 쿼리는 가격 요약 보고서 쿼리(TPC-H 사양의 섹션 2.4.1)입니다. 이 쿼리는 지정된 날짜를 기준으로 청구, 배송, 반환된 항목의 수를 결과로 반환합니다.
전체 쿼리는 다음과 같습니다.
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Teradata에서 쿼리를 실행합니다.
- BTEQ를 실행하고 Teradata에 연결합니다. 자세한 내용은 이 문서의 앞 부분에서 설명한 TPC-H 데이터베이스 만들기를 참조하세요.
출력 표시 너비를 500자로 변경합니다.
.set width 500쿼리를 복사하여 BTEQ 프롬프트에 붙여 넣습니다.
결과는 다음과 유사합니다.
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
BigQuery에서 동일한 쿼리를 실행합니다.
BigQuery 콘솔로 이동합니다.
쿼리를 쿼리 편집기에 복사합니다.
FROM줄의 데이터 세트 이름이 올바른지 확인합니다.실행을 클릭합니다.
반환된 결과가 Teradata의 결과와 동일합니다.
원할 경우 테이블의 모든 행이 검색되도록 쿼리를 실행하는 시간 간격을 늘릴 수 있습니다.
로컬 공급업체 볼륨 쿼리 실행
두 번째 쿼리 예시는 로컬 공급업체 볼륨 쿼리 실행 보고서(TPC-H 사양의 섹션 2.4.5)입니다. 이 쿼리는 고객과 공급업체가 각 광고 항목을 통해 창출한 수익을 리전별 국가를 기준으로 반환합니다. 반환된 결과는 유통 센터의 운영 위치를 계획하는 데 유용합니다.
전체 쿼리는 다음과 같습니다.
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
이전 섹션의 설명대로 Teradata BTEQ와 BigQuery 콘솔에서 쿼리를 실행합니다.
다음은 Teradata에서 반환된 결과입니다.
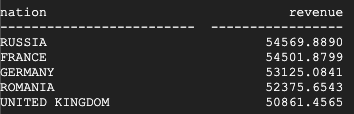
다음은 BigQuery에서 반환된 결과입니다.
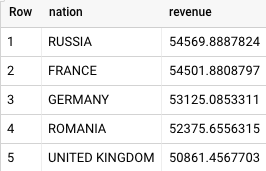
Teradata와 BigQuery 모두 같은 결과를 반환합니다.
상품 유형 수익률 쿼리 실행
마이그레이션을 확인하는 마지막 테스트는 상품 유형 수익률 쿼리의 마지막 쿼리 예시(TPC-H 사양의 섹션 2.4.9)입니다. 이 쿼리는 주문된 모든 부품의 수익을 국가와 연도별로 반환합니다. 또한 부품 이름의 하위 문자열과 특정 공급업체를 기준으로 결과를 필터링합니다.
전체 쿼리는 다음과 같습니다.
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
이전 섹션의 설명대로 Teradata BTEQ와 BigQuery 콘솔에서 쿼리를 실행합니다.
다음은 Teradata에서 반환된 결과입니다.
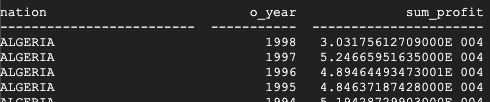
다음은 BigQuery에서 반환된 결과입니다.
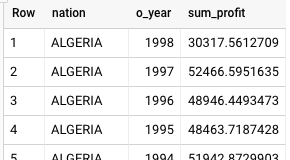
Teradata는 합계를 표시하는 데 과학적 표기법을 사용하지만 Teradata와 BigQuery 모두 같은 결과를 반환합니다.
추가 쿼리
원할 경우 TPC-H 사양의 섹션 2.4에 정의되어 있는 나머지 TPC-H 쿼리를 실행할 수 있습니다.
또한 DBGEN 도구와 같은 디렉터리에 있는 QGEN 도구를 사용하여 TPC-H 표준을 준수하는 쿼리를 생성할 수도 있습니다. QGEN은 DBGEN과 동일한 makefile을 통해 빌드되므로 dbgen을 컴파일하기 위해 make를 실행하면 qgen 실행 파일도 생성됩니다.
두 도구와 해당 명령줄 옵션에 대한 자세한 내용은 각 도구의 README 파일을 참조하세요.
삭제
이 튜토리얼에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 관련 리소스를 삭제해야 합니다.
프로젝트 삭제
요금이 청구되지 않도록 하는 가장 간단한 방법은 이 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
다음 단계
- Teradata를 BigQuery로 마이그레이션의 단계별 안내를 참조하세요.