上次更新日期:2020 年 9 月
版本说明
本文档是系列文章中的一篇,该系列讨论了如何将架构和数据从 Teradata 迁移到 Google Cloud 上的 BigQuery。本部分是快速入门(也称概念验证教程),将逐步说明如何将各种非标准 Teradata SQL 语句转换为可在 BigQuery 中使用的标准 SQL。
本系列讨论了转换 Teradata 的具体细节,包括以下几个部分:
- 架构和数据传输快速入门
- 查询转换概览
- 查询转换快速入门(本文档)
- SQL 转换参考
如需简要了解如何从本地数据仓库转移到 Google Cloud 上的 BigQuery,请参阅相关系列内容,开篇是将数据仓库迁移到 BigQuery:简介和概览
目标
- 将查询从 Teradata SQL 转换为标准 SQL。
- 从适用于简单案例的手动方法开始,然后使用模板进行自动化处理。
- 了解更多需要进行查询重构的复杂转换。
费用
本快速入门使用 Google Cloud 的以下收费组件:
- BigQuery:本教程在一次执行多个查询时,会将大约 1 GB 的数据存储在 BigQuery 中,且处理的数据量不到 2 GB。作为 Google Cloud 免费层级的一部分,BigQuery 提供一些有特定限额的免费资源。这些免费资源的用量限额在免费试用期间及试用结束后均有效。如果超过这些用量限额且免费试用期已结束,您将需要根据 BigQuery 价格页面上的价格支付费用。
您可使用价格计算器根据您的预计用量来估算费用。
准备工作
- 首先运行架构和数据转移快速入门中的相关命令,在 Teradata 数据库和 BigQuery 中创建本快速入门所需的架构和数据。该快速入门与本快速入门使用的是同一项目。
- 请确保您的计算机安装了 Teradata BTEQ,并且可以连接到 Teradata 数据库。如果您需要安装 BTEQ 工具,可以从 Teradata 网站上获取。
如需详细了解如何安装、配置和运行 BTEQ,请咨询您的系统管理员。您也可以执行以下操作,作为 BTEQ 的补充或替代方式:
- 安装具有图形界面的工具,如 DBeaver。
- 安装由 Teradata 提供的 Python 模块,编写与 Teradata 数据库之间的互动脚本。
- 如果您的计算机尚未安装 Jinja2,请将其安装在 Python 环境中。 Jinja2 是 Python 的模板引擎。我们建议您使用 virtualenvwrapper 等环境管理器隔离 Python 环境。
- 确保您有权访问 BigQuery 控制台。
简介
本快速入门指导您将一些示例查询从 Teradata SQL 转换为可在 BigQuery 中使用的标准 SQL。首先介绍简单的搜索和替换方法,然后介绍如何使用脚本进行自动重构。最后,本文介绍了更多复杂的转换方法,需要领域主题专家的参与才能确保转换后的查询保留原本的语义。
本快速入门主要面向意在获得将查询从 Teradata SQL 转换为标准 ISO:2011 SQL 实际经验的数据仓库管理员、开发者和数据从业者。
替换运算符和函数
由于 Teradata SQL 符合 ANSI/ISO SQL,因此许多查询可以在改动很小的情况下轻松迁移。不过,Teradata 还支持非标准 SQL 扩展程序。对于在 Teradata 中使用非标准运算符和函数的简单情况,您通常可以使用查找和替换流程来转换查询。
例如,首先在 Teradata 中使用查询来查找 1994 年购物金额超过 1 万美元的客户数量。
在安装了 BTEQ 的计算机上,打开 Teradata BTEQ 客户端:
bteq登录 Teradata。将 teradata-ip 和 teradata-user 替换为与您的环境相对应的值。
.LOGON teradata-ip/teradata-user
在 BTEQ 提示符处,运行以下 Teradata SQL 查询:
SELECT COUNT(DISTINCT(O_CUSTKEY)) AS num_customers FROM tpch.orders WHERE O_TOTALPRICE GT 10000 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994;结果类似于以下内容:
num_customers ------------- 86101
现在,在 BigQuery 中运行同一查询:
转到 BigQuery 控制台:
将该查询复制到查询编辑器中。
运算符
GT(大于)不是标准 SQL,因此查询编辑器会显示语法错误消息: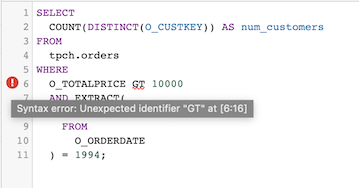
将
GT替换为>运算符。点击运行。
所得数值结果与 Teradata 的结果相同。
使用脚本搜索和替换 SQL 元素
您刚刚进行的改动非常小,而且很容易手动完成。但是,当您需要处理大型 SQL 脚本或大量 SQL 脚本时,手动搜索和替换会变得非常麻烦且容易出错。 因此,最好自动完成此任务,这是您在本部分中要执行的操作。
在控制台中,转到 Cloud Shell:
使用文本编辑器创建名为
num-customers.sql的新文件。例如,使用 vi 创建该文件:vi num-customers.sql将上个部分中的 SQL 脚本复制到该文件中。
保存并关闭文件。
将
GT替换为>运算符:sed -i 's/GT/>/' num-customers.sql验证文件中是否已将
GT替换为>:cat num-customers.sql
您可以将刚刚用过的 sed 脚本批量应用于一组文件。它可以处理每个文件中的多个替换项。
在 Cloud Shell 中,使用文本编辑器打开名为
num-customers.sql的文件:vi num-customers.sql将该文件的内容替换为以下脚本:
SELECT COUNT(DISTINCT(O_CUSTKEY)) AS num_customers FROM tpch.orders WHERE O_TOTALPRICE GT 10000 AND O_ORDERPRIORITY EQ '1-URGENT' AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994;这个脚本几乎与前一个脚本相同,但添加了一行,使查询内容仅包含紧急订单。SQL 脚本现在有两个非标准 SQL 运算符:
GT和EQ。保存并关闭文件。
复制 99 份该文件:
for i in {1..99}; do cp num-customers.sql "num-customers$i.sql"; done命令完成后,您将得到 100 份脚本文件。
通过一次操作将所有文件中的
GT替换为>:sed -i 's/GT/>/g;s/EQ/=/g' *.sql使用脚本更改所有 100 个文件比逐个手动更改这些文件的效率要高得多。
列出包含
GT运算符的文件:grep GT *.sql此命令不返回任何结果,因为所有出现的
GT运算符均已被替换为>运算符。选择任意文件并验证非标准运算符是否已被替换为与其对应的标准运算符:
cat num-customers33.sql
以下情况非常适合采用这种搜索和替换方法:
- 某些日期函数,例如:
- 将
DATE + k替换为DATE_ADD - 将
TD_DAY_OF_MONTH替换为EXTRACT - 将
MONTHS_BETWEEN替换为DATE_DIFF
- 将
- 某些字符串函数,例如:
- 将
CHARACTER_LENGTH替换为CHAR_LENGTH - 将
INDEX替换为STRPOS - 将
LEFT替换为SUBSTR
- 将
- 某些数学函数,例如:
- 将
NULLIFZERO替换为NULLIF - 将
RANDOM替换为RAND - 将
ZEROIFNULL替换为IFNULL
- 将
- 缩写,例如将
SEL替换为SELECT。
如需查看更全面的常见转换列表,请参阅 Teradata 到 BigQuery 的 SQL 转换参考文档。
使用脚本重构 SQL 语句和脚本
到目前为止,您仅完成了 Teradata SQL 和标准 SQL 之间一对一映射的运算符和函数的自动替换。但是,对于非标准函数,转换 SQL 元素的复杂性会增加。转换脚本不仅需要替换关键字,还需要添加或移动其他元素,如参数、括号或其他函数调用。
在本部分中,您将在 Teradata 中执行查询,以查找每个月底一组客户订购金额的最高值。
在安装了 BTEQ 的计算机上,切换到或打开 BTEQ 命令提示符。如果您关闭了 BTEQ,请运行以下命令:
bteq在 BTEQ 提示符处,运行以下 Teradata SQL 查询:
SELECT O_CUSTKEY, SUM(O_TOTALPRICE) as total, TD_MONTH_END(O_ORDERDATE) as month_end FROM tpch.orders WHERE O_CUSTKEY < 5 GROUP BY O_CUSTKEY, month_end ORDER BY total DESC;该查询使用非标准
TD_MONTH_ENDTeradata 函数来获取紧接在订单日期之后的月末日期。例如,如果订单日期为 1996-05-16,则TD_MONTH_END将返回 1996-05-31。它需要获取一个日期参数,即订单日期。结果按月末日期和客户键进行分组,以获得指定月份和指定客户的总值。结果类似于以下内容:
O_CUSTKEY total month_end ----------- ----------------- --------- 4 379593.37 96/06/30 4 323004.15 96/08/31 2 312692.22 97/02/28 4 311722.87 92/04/30
如需在 BigQuery 中运行返回相同结果的查询,您需要将非标准 TD_MONTH_END 函数替换为与其等效的标准 SQL。然而,此函数没有一对一的映射关系。因此,您需要创建一个使用 Jinja2 模板的函数以执行此任务。
在 Cloud Shell 中,创建名为
month-end.jinja2的新文件:vi month-end.jinja2将以下 SQL 代码段复制到该文件中:
DATE_SUB( DATE_TRUNC( DATE_ADD( {{ date }}, INTERVAL 1 MONTH ), MONTH ), INTERVAL 1 DAY )此文件是一个 Jinja2 模板。它在标准 SQL 中与
TD_MONTH_END函数等效。此文件含有一个名为{{ date }}的占位符,它将被替换为日期参数,本例中为O_ORDERDATE。保存并关闭文件。
创建名为
translate-query.py的新文件:translate-query.py将以下 Python 脚本复制到该文件中:
"""Translates a sample using a template.""" import re from jinja2 import Environment from jinja2 import PackageLoader env = Environment(loader=PackageLoader('translate-query', '.')) regex = re.compile(r'(.*)TD_MONTH_END\(([A-Z_]+)\)(.*)') with open('month-end.td.sql', 'r') as td_sql: with open('month-end.sql', 'w') as std_sql: for line in td_sql: match = regex.search(line) if match: argument = match.group(2) template = env.get_template('month-end.jinja2') std_sql.write(match.group(1) + template.render(date=argument) \ + match.group(3) + '\n') else: std_sql.write(line)此 Python 脚本会打开您之前创建的文件 (
month-end.td.sql),从中读取 Teradata SQL 作为输入,并将已转换的标准 SQL 脚本写入month-end.sql文件。请注意以下细节:
- 该脚本将正则表达式
(.*)TD_MONTH_END\(([A-Z_]+)\)(.*)与从输入文件中读取的每一行进行匹配。该表达式用于查找TD_MONTH_END并捕获以下三个分组:- 此函数前面的所有字符
(.*),归为group(1)。 - 发送至
TD_MONTH_END函数的参数([A-Z_]+),归为group(2)。 - 此函数后面的所有字符
(.*),归为group(3)。
- 此函数前面的所有字符
- 如果匹配,该脚本会检索您在上一步中创建的 Jinja2 模板
month-end.jinja2。然后,它会按此顺序将以下内容写入输出文件:- 由
group(1)表示的字符。 date占位符已替换为在 Teradata SQL 中找到的原始参数O_ORDERDATE的模版。- 由
group(3)表示的字符。
- 由
- 该脚本将正则表达式
保存并关闭文件。
运行 Python 脚本:
python translate-query.py这将创建一个名为
month-end.sql的文件。显示此新文件的内容:
cat month-end.sql此命令显示由脚本转换为标准 SQL 的查询:
SELECT O_CUSTKEY, SUM(O_TOTALPRICE) as total, DATE_SUB( DATE_TRUNC( DATE_ADD( O_ORDERDATE, INTERVAL 1 MONTH ), MONTH ), INTERVAL 1 DAY ) as month_end FROM tpch.orders WHERE O_CUSTKEY < 5 GROUP BY O_CUSTKEY, month_end ORDER BY total DESC;TD_MONTH_END函数不会再出现。它已被模板和模板中适当位置的日期参数O_ORDERDATE替换。
Python 脚本已经使用了来自外部 Jinja2 文件的模板。同样的方法可以应用于正则表达式,也就是说,您可以从文件或键值对存储区加载表达式。这样,脚本可以实现通用化,以处理任意表达式及其对应的转换模板。
最后,在 BigQuery 中运行生成的脚本,验证其结果与从 Teradata 中获得的结果一致:
转到 BigQuery 控制台:
将您之前用过的查询复制到查询编辑器中。
点击运行。
所得结果与 Teradata 的结果相同。
增加查询转换工作量
在迁移期间,您需要一群经验丰富的人员使用工具(例如您先前看到的示例脚本)来应用一组转换。这些脚本将在迁移过程中发生变化。因此,我们强烈建议您将脚本置于源代码控制之下。您需要仔细测试运行这些脚本的结果。
我们建议您联系我们的销售团队,他们可以帮助您联系我们的专业服务组织以及我们的合作伙伴,以便在迁移过程中为您提供帮助。
重构查询
在上一部分中,您使用脚本搜索 Teradata SQL 中的运算符,并将其替换为标准 SQL 中的等效运算符。您还借助模板对查询进行了有限的自动重构。
如需转换某些 Teradata SQL 功能,您需要对 SQL 查询进行更深入的重构。本部分将介绍两个示例:转换 QUALIFY 子句和转换跨列引用。
本部分中的示例是手动重构的。实际上,某些更为复杂的重构可能更适合自动化。然而,由于分析每种不同的情况非常复杂,对这些重构实现自动化可能会导致收益降低。此外,自动化脚本可能会错过能够保留查询语义的更优解决方案。
QUALIFY 子句
Teradata 的 QUALIFY 子句是 SELECT 语句中的条件子句,用于过滤先前计算的有序分析函数的结果。有序分析函数对一系列行进行处理,并为每行生成一个结果。Teradata 客户通常使用此功能快速进行排名并返回结果,而无需其他子查询。
为便于说明,您可以使用 QUALIFY 子句选择 1994 年每位客户的最高价值订单。
在安装了 BTEQ 的计算机上,切换到或打开 BTEQ 命令提示符。如果您关闭了 BTEQ,请运行以下命令:
bteq将以下 Teradata SQL 查询复制到 BTEQ 提示符:
SELECT O_CUSTKEY, O_TOTALPRICE FROM tpch.orders QUALIFY ROW_NUMBER() OVER ( PARTITION BY O_CUSTKEY ORDER BY O_TOTALPRICE DESC ) = 1 WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1994 AND (O_CUSTKEY MOD 10000) = 0;请注意有关此查询的以下事项:
- 该查询将行分为多个分区。每个分区对应一个客户键 (
PARTITION BY O_CUSTKEY)。 QUALIFY子句仅从每个分区中过滤出第一行 (ROW_NUMBER()=1)。- 由于每个分区中的行按总订单价格降序排列 (
ORDER BY O_TOTALPRICE DESC),因此第一行对应于具有最高订单价值的行。 SELECT语句提取客户键和总订单价格(O_CUSTKEY、O_TOTALPRICE),并使用WHERE子句进一步将结果过滤为 1994 年内。- 为便于显示,取模运算符 (
MOD) 只提取一部分行。这种采样方法优于SAMPLE子句,由于SAMPLE是随机的,因此无法与 BigQuery 比较结果。
- 该查询将行分为多个分区。每个分区对应一个客户键 (
运行查询。
结果类似于以下内容:
O_CUSTKEY O_TOTALPRICE ----------- ----------------- 10000 182742.02 20000 56470.00 40000 211502.51 50000 81584.54 70000 53131.09 80000 15902.64 100000 306639.29 130000 183113.29 140000 250958.13第二列是 1994 年内第一列中采样客户键的订单最高总价值。
如需在 BigQuery 中运行同一查询,您需要转换 SQL 脚本,使其符合 ANSI/ISO SQL。
转到 BigQuery 控制台:
将以下已转换的查询复制到查询编辑器:
SELECT O_CUSTKEY, O_TOTALPRICE FROM ( SELECT O_CUSTKEY, O_TOTALPRICE, ROW_NUMBER() OVER ( PARTITION BY O_CUSTKEY ORDER BY O_TOTALPRICE DESC ) as row_num FROM tpch.orders WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1994 AND MOD(O_CUSTKEY, 10000) = 0 ) WHERE row_num = 1这一新查询包含一些更改,这些更改均无法通过简单的搜索和替换来完成。请注意以下事项:
QUALIFY子句已移除,分析函数ROW_NUMBER()作为一列移入SELECT语句,并被赋予别名 (as row_num)。- 如果封装查询不存在,则会创建该封装查询,并向其添加具有分析值过滤条件 (
row_num = 1) 的WHERE条件语句。 - Teradata
MOD运算符也是非标准运算符,因此会被替换为MOD()函数。
点击运行。
所得列式结果与 Teradata 的结果相同。
跨列引用
Teradata 支持在同一查询中定义的列之间进行交叉引用。在本部分中,您所使用的查询为嵌套的 SELECT 语句指定别名,然后在 CASE 表达式中引用该别名。
为便于说明,您可以运行一个查询来确定某位客户在指定年份是否活跃。如果客户在该年份至少下过一个订单,则该客户处于活跃状态。
在安装了 BTEQ 的计算机上,切换到或打开 BTEQ 命令提示符。如果您关闭了 BTEQ,请运行以下命令:
bteq将以下 Teradata SQL 查询复制到 BTEQ 提示符:
SELECT ( SELECT COUNT(O_CUSTKEY) FROM tpch.orders WHERE O_CUSTKEY = 2 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994 ) AS num_orders, CASE WHEN num_orders = 0 THEN 'INACTIVE' ELSE 'ACTIVE' END AS status;请注意有关此查询的以下事项:
- 有一个嵌套查询用于计算客户键
2在 1994 年出现的次数。此查询的结果将在第一列中返回,并被赋予别名num_orders。 - 在第二列中,如果找到的订单数不为零,则
CASE表达式输出ACTIVE;否则输出INACTIVE。CASE表达式在内部使用同一查询的第一列的别名 (num_orders)。
- 有一个嵌套查询用于计算客户键
运行查询。
结果类似于以下内容:
num_orders status ----------- -------- 3 ACTIVE
如需在 BigQuery 中运行同一查询,您需要消除同一查询中各列之间的引用。
转到 BigQuery 控制台:
将以下已转换的查询复制到查询编辑器:
SELECT customer.num_orders, CASE WHEN customer.num_orders = 0 THEN 'INACTIVE' ELSE 'ACTIVE' END AS status FROM ( SELECT COUNT(O_CUSTKEY) AS num_orders FROM tpch.orders WHERE O_CUSTKEY = 2 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994 ) customer;请注意对原始查询的以下更改:
- 嵌套查询被移到封装查询的
FROM子句中。 它被赋予别名customer,但此别名没有定义输出列,因为它位于FROM子句而不是SELECT子句中。 SELECT子句有两列:- 第一列输出嵌套查询 (
customer) 中定义的订单数量 (num_orders)。 - 第二列包含引用嵌套查询中定义的订单数量的
CASE语句。
- 第一列输出嵌套查询 (
- 嵌套查询被移到封装查询的
点击运行。
所得列式结果与 Teradata 的结果相同。
清除数据
为避免系统因本教程中使用的资源而向您的 Google Cloud 帐号收取费用,您应该将资源移除。
删除项目
停止计费的最简单方法是删除您为本教程创建的项目。
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
后续步骤
- 参阅 Teradata 到 BigQuery 的 SQL 转换参考,详细了解 Teradata SQL 与 BigQuery 中使用的标准 SQL 之间的区别和映射关系。
- 继续阅读本系列文章的后续篇:数据治理
- 查看 Google 的专业服务组织提供的产品与服务,以及我们庞大的合作伙伴生态系统,我们的合作伙伴公司可以为您的迁移提供支持。
- 探索有关 Google Cloud 的参考架构、图表、教程和最佳做法。查看我们的 Cloud Architecture Center。