Este artigo é a terceira parte de uma série que discute a recuperação de desastres (DR) no Google Cloud. Nesta parte, discutimos cenários de backup e recuperação de dados.
A série contém estas partes:
- Guia de planejamento de recuperação de desastres
- Elementos básicos da recuperação de desastres
- Cenários de recuperação de desastres para dados (este artigo)
- Cenários de recuperação de desastres para aplicativos
- Como arquitetar a recuperação de desastres para cargas de trabalho com restrição de localidade
- Casos de uso da recuperação de desastres: aplicativos de análise de dados com restrição de localidade
- Como arquitetar a recuperação de desastres para interrupções de infraestrutura em nuvem
Introdução
Os planos de recuperação de desastres precisam especificar como você pode evitar a perda de dados durante um desastre. O termo dados aqui abrange dois cenários. Fazer backup e, em seguida, recuperar o banco de dados, dados de registro e outros tipos de dados se encaixa em um dos seguintes cenários:
- Backups de dados: o backup de dados consiste na cópia de uma pequena quantidade de dados de um local para outro. Os backups são feitos como parte de um plano de recuperação para reaver dados corrompidos, permitindo que seja feita a restauração para um ponto anterior à corrupção de dados diretamente no ambiente de produção, ou para restaurar dados no ambiente de DR, caso o ambiente de produção esteja inativo. Normalmente, os backups de dados têm um RTO pequeno ou médio, e um RPO pequeno.
- Backups de banco de dados: os backups de banco de dados são um pouco mais complexos, porque geralmente envolvem a recuperação para um momento determinado. Portanto, além de pensar em como fazer o backup e restaurar os backups do banco de dados para garantir que o sistema de recuperação espelhe a configuração de produção (mesma versão, configuração de disco espelhada), também é necessário pensar em como fazer o backup dos registros de transações. Durante a recuperação, depois de restaurar a funcionalidade do banco de dados, é necessário aplicar o backup mais recente e depois os registros de transações recuperados que foram armazenados após o último backup. Adotar uma abordagem de priorização da alta disponibilidade para minimizar o tempo de recuperação de uma situação que poderia causar indisponibilidade do servidor de banco de dados permite que você consiga valores menores de RTO e RPO por causa de fatores adversos inerentes aos sistemas de banco de dados, como a necessidade de fazer a correspondência das versões entre sistemas de produção e recuperação.
No restante deste artigo, são discutidos exemplos de como projetar alguns cenários para dados e bancos de dados que podem ajudar você a atingir suas metas de RTO e RPO.
Ambiente de produção no local
Nesse cenário, o ambiente de produção é local e o plano de recuperação de desastres envolve usar o Google Cloud como local de recuperação.
Backup e recuperação de dados
É possível usar várias estratégias para implementar um processo de backup regular dos dados do local para o Google Cloud. Nesta seção, analisamos duas das soluções mais comuns.
Solução 1: fazer backup no Cloud Storage usando uma tarefa programada
Elementos básicos de DR:
- Cloud Storage
Uma opção para fazer backup de dados é criar uma tarefa programada que execute um script ou aplicativo para transferir os dados para o Cloud Storage. É possível automatizar um processo de backup para o Cloud Storage usando a ferramenta de linha de comando gsutil ou uma das bibliotecas de cliente do Cloud Storage.
Por exemplo, o comando gsutil a seguir copia todos os arquivos de um diretório de origem para um bucket especificado.
gsutil -m cp -r [SOURCE_DIRECTORY] gs://[BUCKET_NAME]
As etapas a seguir descrevem como implementar um processo de backup e recuperação usando a ferramenta gsutil.
- Instale
gsutilna máquina local que você usa para fazer upload dos arquivos de dados. - Crie um bucket como o destino do backup de dados.
- Gere uma chave para uma conta de serviço dedicada no formato JSON. Esse arquivo é usado para transmitir credenciais para
gsutilcomo parte de um script automatizado. Copie a chave da conta de serviço para a máquina local em que é executado o script usado para fazer o upload dos seus backups.
Crie uma política do IAM para restringir quem tem acesso ao bucket e aos objetos dele. Inclua a conta de serviço criada especificamente para essa finalidade e uma conta de operador local. Para detalhes sobre as permissões de acesso ao Cloud Storage, consulte Permissões do IAM para comandos
gsutil.Veja se é possível fazer upload e o download dos arquivos no bucket de destino.
Siga as orientações em Escrever scripts de tarefas de transferência de dados para configurar um script programado.
Configure um processo de recuperação que use
gsutilpara recuperar seus dados no ambiente de recuperação de desastres no Google Cloud.
Também é possível usar o comando gsutil rsync para realizar sincronizações incrementais em tempo real entre seus dados e um bucket do Cloud Storage.
Por exemplo, o comando gsutil rsync a seguir torna o conteúdo em um
bucket do Cloud Storage igual ao conteúdo no diretório de origem ao
copiar todos os arquivos ou objetos ausentes ou aqueles com dados que foram alterados. Se o
volume de dados que mudou entre sessões sucessivas de backup for pequeno em relação ao
volume inteiro dos dados de origem, o uso de gsutil rsync pode ser mais
eficiente do que usar gsutil cp. Isso, por sua vez, possibilita uma programação de backup
mais frequente e permite que você consiga um valor de RPO mais baixo.
gsutil -m rsync -r [SOURCE_DIRECTORY] gs://[BUCKET_NAME]
Para saber mais, consulte Transferir a partir de colocation ou armazenamento local, que apresenta maneiras de otimizar o processo de transferência.
Solução 2: fazer backup no Cloud Storage usando o Serviço de transferência de dados locais
Elementos básicos de DR:
- Cloud Storage
- Serviço de transferência para dados locais
A transferência de grandes quantidades de dados em uma rede geralmente requer planejamento cuidadoso e estratégias robustas de execução. Essa é uma tarefa não trivial para desenvolver scripts personalizados que são escalonáveis, confiáveis e de fácil manutenção. Scripts personalizados geralmente podem levar a valores de RPO reduzidos e até mesmo maior risco de perda de dados.
Uma maneira de implementar a transferência de dados em grande escala é usar o Serviço de transferência de dados locais. Esse serviço é escalonável, confiável e gerenciado que permite transferir grandes quantidades de dados do seu data center para um bucket do Cloud Storage sem investir em equipes de engenharia ou comprar soluções de transferência.
Solução 3: fazer backup no Cloud Storage usando uma solução de gateway de parceiro
Elementos básicos de DR:
- Cloud Interconnect
- Armazenamento em níveis do Cloud Storage
Os aplicativos locais geralmente são integrados a soluções de terceiros que podem ser usadas como parte da sua estratégia de backup e recuperação de dados. Normalmente, as soluções usam um padrão de armazenamento hierárquico, em que os backups mais recentes ficam em um armazenamento mais rápido e, lentamente, você migra os backups mais antigos para um armazenamento mais barato, que também é mais lento. Ao usar o Google Cloud como destino, você tem várias opções de classe de armazenamento disponíveis para usar como o equivalente do nível mais lento.
Uma maneira de implementar esse padrão é usar um gateway de parceiro entre o armazenamento local e o Google Cloud para facilitar essa transferência de dados para o Cloud Storage. O diagrama a seguir ilustra essa disposição com uma solução de um parceiro que gerencia a transferência do dispositivo NAS local ou da SAN.

Em caso de falha, os dados que estão sendo copiados como backup precisarão ser recuperados no seu ambiente de DR. O ambiente de DR é usado para exibir o tráfego de produção até que seja possível revertê-lo para o ambiente de produção. O modo como isso será feito dependerá do seu aplicativo, da solução do parceiro e da arquitetura dela. É possível encontrar alguns cenários completos na documentação sobre aplicações da DR.
Para mais orientações sobre como transferir dados do local para o Google Cloud, consulte Como transferir conjuntos de Big Data para o Google Cloud.
Para mais informações sobre soluções de parceiros, consulte a página Parceiros no site do Google Cloud.
Backup e recuperação de banco de dados
É possível usar várias estratégias para implementar um processo de recuperação de um sistema de banco de dados no local para o Google Cloud. Nesta seção, analisamos duas das soluções mais comuns.
O detalhamento dos diversos mecanismos internos de backup e recuperação incluídos em bancos de dados de terceiros não faz parte do escopo deste artigo. Esta seção traz orientações gerais, implementadas nas soluções aqui discutidas.
Solução 1: backup e recuperação usando um servidor de recuperação no Google Cloud
- Crie um backup do banco de dados usando os mecanismos de backup integrados do sistema de gerenciamento de banco de dados.
- Conecte sua rede local e sua rede do Google Cloud.
- Crie um bucket do Cloud Storage como o destino do backup de dados.
- Copie os arquivos de backup para o Cloud Storage usando
gsutilou uma solução de gateway de parceiro (consulte as etapas discutidas anteriormente na seção de backup e recuperação de dados). Para detalhes, consulte Como transferir conjuntos de Big Data para o Google Cloud. - Copie os registros de transação para seu local de recuperação no Google Cloud. Ter um backup dos registros de transações ajuda a manter os valores de RPO baixos.
Depois de configurar essa topologia de backup, você precisa garantir que pode se recuperar para o sistema que está no Google Cloud. Essa etapa normalmente envolve não apenas restaurar o arquivo de backup para o banco de dados de destino, mas também reproduzir os registros de transação para chegar ao menor valor de RTO. Veja a seguir uma sequência típica de recuperação:
- Crie uma imagem personalizada do seu servidor de banco de dados no Google Cloud. A imagem do servidor de banco de dados deve ter a mesma configuração que seu servidor de banco de dados local.
- Implemente um processo para copiar os arquivos de backup e os arquivos de registros de transações locais para o Cloud Storage. Veja um exemplo de implementação na solução 1.
- Inicie uma instância de tamanho mínimo a partir da imagem personalizada e anexe todos os discos permanentes necessários.
- Defina a sinalização de exclusão automática como "falso" para os discos permanentes.
- Aplique o arquivo de backup mais recente que foi copiado anteriormente no Cloud Storage, seguindo as instruções do seu sistema de banco de dados para recuperação de arquivos de backup.
- Aplique o conjunto mais recente de arquivos de registros de transações que foram copiados para o Cloud Storage.
- Substitua a instância mínima por uma instância maior, capaz de aceitar o tráfego de produção.
- Alterne os clientes para apontar para o banco de dados recuperado no Google Cloud.
Quando seu ambiente de produção está em execução e é compatível com cargas de trabalho de produção, é preciso reverter as etapas seguidas para fazer o failover para o ambiente de recuperação do Google Cloud. Veja a seguir uma sequência típica para retornar ao ambiente de produção:
- Selecione um backup do banco de dados em execução no Google Cloud.
- Copie o arquivo de backup para seu ambiente de produção.
- Aplique o arquivo de backup ao sistema de banco de dados de produção.
- Impeça que os clientes se conectem ao sistema de banco de dados no Google Cloud. Uma das formas de fazer isso é, por exemplo, interrompendo o serviço do sistema de banco de dados. A partir desse momento, o aplicativo ficará indisponível até que seja concluída a restauração do ambiente de produção.
- Copie todos os arquivos de registros de transações para o ambiente de produção e aplique-os.
- Redirecione as conexões do cliente para o ambiente de produção.
Solução 2: replicação para um servidor de espera no Google Cloud
Uma maneira de conseguir valores de RTO e RPO bem baixos é replicar os dados (e não apenas fazer backup) e, em alguns casos, mudar o estado do banco de dados em tempo real para o de um servidor de banco de dados com espera ativa.
- Conecte sua rede local e sua rede do Google Cloud.
- Crie uma imagem personalizada do seu servidor de banco de dados no Google Cloud. A imagem do servidor de banco de dados deve ter a mesma configuração que seu servidor de banco de dados local.
- Inicie uma instância a partir da imagem personalizada e anexe todos os discos permanentes necessários.
- Defina a sinalização de exclusão automática como "falso" para os discos permanentes.
- Configure a replicação entre o servidor de banco de dados local e o servidor de banco de dados de destino no Google Cloud seguindo as instruções específicas do software de banco de dados.
- Os clientes são configurados durante a operação normal para apontar para o servidor de banco de dados local.
Depois de configurar essa topologia de replicação, alterne os clientes para apontar para o servidor de espera em execução na sua rede do Google Cloud.
Quando o ambiente de produção estiver de volta e pronto para oferecer suporte a cargas de trabalho de produção, você precisará sincronizar novamente o servidor de banco de dados de produção com o servidor de banco de dados do Google Cloud e depois alternar os clientes para apontar de volta para o ambiente de produção.
O ambiente de produção é o Google Cloud
Nesse cenário, os ambientes de produção e de recuperação de desastres são executados no Google Cloud.
Backup e recuperação de dados
Um padrão comum para backups de dados é usar um padrão de armazenamento em níveis. Quando sua carga de trabalho de produção está no Google Cloud, o sistema de armazenamento em camadas é similar ao diagrama a seguir. Você migra os dados para um nível com custos de armazenamento mais baixos porque é menos provável que você precise acessar os dados do backup.
Elementos básicos de DR:
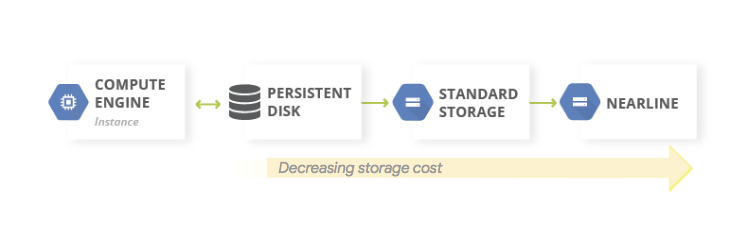
Como as classes de armazenamento Nearline, Coldline e Archive são destinadas ao armazenamento de dados pouco acessados, há custos extras associados à recuperação de dados ou metadados armazenados nessas classes, como: assim como pelas durações de armazenamento mínimas que são cobradas.
Backup e recuperação de banco de dados
Quando você usa um banco de dados autogerenciado, por exemplo, se o MySQL, PostgreSQL ou SQL Server estiverem instalados em uma instância do Compute Engine, as mesmas preocupações operacionais se aplicam ao gerenciamento de bancos de dados de produção locais. Por outro lado, você não precisa mais gerenciar a infraestrutura subjacente.
É possível definir configurações de alta disponibilidade com os elementos básicos de DR apropriados para manter o RTO baixo. Também é possível criar a configuração do banco de dados de modo a facilitar a recuperação para um estado o mais próximo possível daquele anterior ao desastre, o que ajuda a manter os valores de RPO baixos. O Google Cloud oferece uma ampla variedade de opções para esse cenário.
Nesta seção, mostramos duas abordagens comuns para projetar sua arquitetura de recuperação de banco de dados autogerenciados no Google Cloud.
Como recuperar um servidor de banco de dados sem sincronizar o estado
Um padrão comum é ativar a recuperação de um servidor de banco de dados que não requer que o estado do sistema seja sincronizado com um servidor em espera ativa.
Elementos básicos de DR:
- Compute Engine
- Grupos de instâncias gerenciadas
- Cloud Load Balancing (balanceamento de carga interno)
O diagrama a seguir ilustra um exemplo de arquitetura que atende a esse cenário. Ao implementar essa arquitetura, você terá um plano de DR que reage automaticamente a uma falha sem exigir recuperação manual.

As etapas a seguir descrevem como configurar esse cenário:
- Crie uma rede VPC
Siga as seguintes etapas para criar uma imagem personalizada configurada com o servidor de banco de dados:
- Configure o servidor para que os arquivos de banco de dados e os arquivos de registros sejam gravados em um disco permanente padrão anexado.
- Crie um instantâneo por meio do disco permanente anexado.
- Configure um script de inicialização para criar um disco permanente por meio do instantâneo e montá-lo.
- Crie uma imagem personalizada do disco de inicialização.
Crie um modelo de instância que use a imagem.
Usando o modelo de instância, configure um grupo gerenciado de instâncias com tamanho de destino 1.
Configure a verificação de integridade usando as métricas do Cloud Monitoring.
Configure o balanceamento de carga interno usando o grupo gerenciado de instâncias.
Configure uma tarefa programada para criar instantâneos regulares do disco permanente.
Caso seja necessário substituir uma instância de banco de dados, essa configuração fará automaticamente o seguinte:
- Introduzir outro servidor de banco de dados com a versão correta na mesma zona
- Anexar um disco permanente com os arquivos de registros de transações e backup mais recentes à instância do servidor de banco de dados recém-criada.
- Minimizar a necessidade de reconfigurar clientes que se comunicam com o servidor de banco de dados em resposta a um evento.
- Garantir que os controles de segurança do Google Cloud (políticas do IAM, configurações de firewall) aplicáveis ao servidor de banco de dados de produção sejam válidos para o servidor de banco de dados recuperado.
Como a instância substituta é criada a partir de um modelo de instância, os controles que se aplicam à original também se aplicam à instância substituta.
Esse cenário aproveita alguns dos recursos de alta disponibilidade disponíveis no Google Cloud. Você não precisa iniciar nenhuma etapa de failover, porque elas ocorrem automaticamente em caso de desastre. O balanceador de carga interno garante que, mesmo quando uma instância substituta é necessária, o mesmo endereço IP seja usado para o servidor de banco de dados. O modelo de instância e a imagem personalizada asseguram que a instância de substituição seja configurada de forma idêntica à instância que está substituindo. Com os instantâneos regulares dos discos permanentes, você garante que, quando os discos forem recriados a partir dos instantâneos e anexados à instância de substituição, essa instância esteja usando dados recuperados de acordo com um valor de RPO determinado pela frequência dos instantâneos. Nessa arquitetura, os arquivos de registros de transações mais recentes que foram gravados no disco permanente também são restaurados automaticamente.
O grupo gerenciado de instâncias fornece alta disponibilidade avançada. Ele fornece mecanismos para reagir a falhas no nível do aplicativo ou da instância, e você não precisa intervir manualmente caso algum desses cenários ocorra. Definir o tamanho de destino como 1 garante que você tenha apenas uma instância ativa que seja executada no grupo gerenciado de instâncias e veicule tráfego.
Os discos permanentes padrão são por zona e, portanto, se houver uma falha nela, serão necessários instantâneos para recriar discos. Além disso, os instantâneos também estão disponíveis entre regiões, o que permite restaurar um disco em uma região diferente com a mesma facilidade que você o restaura na mesma região.
Uma variação dessa configuração é usar discos permanentes regionais em vez de discos permanentes padrão. Nesse caso, não é preciso restaurar o snapshot como parte da etapa de recuperação.
Escolha uma dessas variações de acordo com seu orçamento e os valores de RTO e RPO.
Para mais informações sobre configurações de banco de dados projetadas para cenários de alta disponibilidade e recuperação de desastres no Google Cloud, consulte:
- Usar o Google Cloud Storage para recuperação de desastres do Cassandra, que descreve como implementar um processo de backup e recuperação para um ambiente do Cassandra em execução no Compute Engine. O artigo descreve o processo para implementar um backup no disco local de instantâneos do banco de dados e backups incrementais e, depois, copiá-los para o Cloud Storage.
- Como implantar o MongoDB no Google Compute Engine, que descreve uma arquitetura de alta disponibilidade em que os conjuntos de réplicas no MongoDb são implantados em uma segunda região.
Recuperar após corrupção parcial em bancos de dados muito grandes
Se você estiver usando um banco de dados capaz de armazenar petabytes de dados, pode haver uma interrupção que afete alguns dados, mas não todos. Nesse caso, convém minimizar a quantidade de dados a serem restaurados. Você não precisa recuperar o banco de dados inteiro apenas para restaurar alguns dados.
Há várias estratégias que você pode adotar:
- Armazenar os dados de períodos específicos em tabelas diferentes. Com esse método, você só precisa restaurar um subconjunto de dados para uma nova tabela, e não o conjunto todo.
Armazenar os dados originais no Cloud Storage. Isso permite criar uma nova tabela e carregar novamente os dados não corrompidos. A partir daqui, direcione seus aplicativos para uma nova tabela.
Além disso, caso seu RTO permita, é possível impedir o acesso à tabela que contém os dados corrompidos. Para isso, deixe os aplicativos off-line até que os dados não corrompidos sejam restaurados em uma nova tabela.
Serviços de banco de dados gerenciados no Google Cloud
Nesta seção, discutimos alguns métodos que podem ser usados para implementar mecanismos de backup e recuperação apropriados para os serviços de banco de dados gerenciados no Google Cloud.
Os bancos de dados gerenciados são escalonáveis e, portanto, os mecanismos mais comuns de backup e restauração usados com os RDMBSs tradicionais geralmente não estão disponíveis. Assim como no caso dos bancos de dados autogerenciados, se você estiver usando um banco de dados capaz de armazenar petabytes de dados, será necessário minimizar a quantidade de dados que você precisa restaurar em um cenário de recuperação de desastres. Há várias estratégias para cada banco de dados gerenciado para ajudá-lo a atingir esse objetivo.
O Bigtable fornece replicação do Bigtable. Um banco de dados replicado do Bigtable pode oferecer maior disponibilidade do que um único cluster, além de capacidade de leitura extra e maior durabilidade e resiliência em caso de falhas por zona ou região.
Os backups do Bigtable são um serviço totalmente gerenciado. Com eles, você salva uma cópia do esquema e dos dados de uma tabela para restaurar em outra posteriormente.
Também é possível exportar tabelas do Bigtable como uma série de arquivos sequenciais do Hadoop. Depois disso, esses arquivos podem ser armazenados no Cloud Storage ou usados para importar os dados de volta para outra instância do Bigtable. É possível replicar o conjunto de dados do Bigtable entre as zonas de uma r região do Google Cloud de maneira assíncrona.
BigQuery: se você quiser arquivar dados, use o armazenamento de longo prazo do BigQuery. Se uma tabela não for editada por 90 dias consecutivos, o preço do armazenamento para essa tabela cairá automaticamente em 50%. Não há degradação de desempenho, durabilidade, disponibilidade ou outra funcionalidade quando uma tabela é considerada como de armazenamento de longo prazo. No entanto, se a tabela for editada, ela será revertida para o preço de armazenamento regular e o contador de 90 dias será iniciado novamente.
O BigQuery é replicado em duas zonas de uma única região, mas isso não ajuda com a corrupção nas tabelas. Portanto, você precisa ter um plano de recuperação para esse cenário. Por exemplo, é possível:
- Se a corrupção for detectada dentro de sete dias, consulte a tabela em busca de um estado anterior à corrupção dos dados. Para recuperá-los, use os decoradores de instantâneo.
- Exportar os dados do BigQuery e criar uma nova tabela que contenha os dados exportados, excluindo os dados corrompidos.
- Armazenar os dados de períodos específicos em tabelas diferentes. Com esse método, você só precisará restaurar um subconjunto de dados para uma nova tabela, e não o conjunto todo.
- Faça cópias do conjunto de dados em períodos específicos. É possível usar essas cópias se um evento de corrupção de dados tiver ocorrido além do que uma consulta pontual pode capturar (por exemplo, mais de sete dias atrás). Também é possível copiar um conjunto de dados de uma região para outra para garantir a disponibilidade de dados em caso de falhas na região.
- Armazenar os dados originais no Cloud Storage. Isso permite criar uma nova tabela e carregar novamente os dados não corrompidos. A partir daqui, direcione seus aplicativos para uma nova tabela.
Firestore. O serviço de exportação e importação gerenciado permite importar e exportar entidades do Firestore usando um bucket do Cloud Storage. Isso, por sua vez, permite implementar um processo que você pode usar para recuperar-se de uma exclusão acidental de dados.
Cloud SQL: se você usa o Cloud SQL, o banco de dados MySQL totalmente gerenciado do Google Cloud, ative backups automáticos e geração de registros binários para suas instâncias do Cloud SQL. Assim, será possível realizar facilmente uma recuperação pontual, que restaura o banco de dados a partir de um backup e o recupera em uma nova instância do Cloud SQL. Para mais detalhes, consulte backups e recuperação do Cloud SQL.
Também é possível configurar o Cloud SQL em uma configuração de alta disponibilidade e réplicas entre regiões para maximizar o tempo no caso de falha zonal ou regional.
Spanner: use modelos do Cloud Dataflow para exportar totalmente o banco de dados para um conjunto de arquivos Avro (em inglês) em um bucket do Cloud Storage e use outro modelo para importar novamente os arquivos exportados para um novo banco de dados do Spanner.
Para backups mais controlados, o conector do Dataflow permite gravar código para ler e gravar dados no Spanner em um pipeline do Dataflow. Por exemplo, é possível usar o conector para copiar dados do Spanner e usar o Cloud Storage como destino de backup. A velocidade com que os dados podem ser lidos no Spanner (ou gravados nele) depende do número de nós configurados. Esse fator afeta diretamente os valores de RTO.
O recurso de carimbo de data/hora de confirmação do Spanner pode ser útil para backups incrementais, permitindo selecionar apenas as linhas que foram adicionadas ou modificadas desde o último backup completo.
Para backups gerenciados, o Backup e restauração do Spanner permite criar backups consistentes que podem ser retidos por até um ano. O valor de RTO é menor em comparação com export porque a operação de restauração monta diretamente o backup sem copiar os dados.
Para valores pequenos de RTO, configure uma instância do Spanner em espera configurada com o número mínimo de nós necessários para atender aos requisitos de capacidade de armazenamento e leitura.
O point-in-time-recovery (PITR) do Spanner permite recuperar dados de um momento específico no passado. Por exemplo, se um operador gravar dados inadvertidamente ou um lançamento de aplicativo corrompa o banco de dados, com o PITR é possível recuperar os dados de um ponto no passado, até um máximo de sete dias.
Cloud Composer: Use o Cloud Composer (uma versão gerenciada do Apache Airflow) para programar backups regulares de vários bancos de dados do Google Cloud. Crie um grafo acíclico dirigido (DAG, na sigla em inglês) a ser executado de acordo com uma programação (por exemplo, diária) para copiar dados de outro projeto, conjunto de dados ou tabela, dependendo da solução usada, ou exportar os dados para o Cloud Storage.
É possível exportar ou copiar dados usando os vários operadores do Cloud Platform.
Por exemplo, é possível criar um DAG para fazer o seguinte:
- Exportar uma tabela do BigQuery para o Cloud Storage usando o BigQueryToCloudStorageOperator.
- Exportar o Firestore no modo Datastore para o Cloud Storage usando o DatastoreExportOperator.
- Exportar tabelas MySQL para o Cloud Storage usando o MySqlToGoogleCloudStorageOperator.
- Exportar as tabelas do Postgres para o Cloud Storage usando o PostgresToGoogleCloudStorageOperator.
O ambiente de produção usa outra nuvem
Neste cenário, seu ambiente de produção usa outro provedor de nuvem e seu plano de recuperação de desastres usa o Google Cloud como local de recuperação.
Backup e recuperação de dados
A transferência de dados entre armazenamentos de objetos é um caso de uso comum em cenários de DR. O Serviço de transferência do Cloud Storage é compatível com o Amazon S3. Esse componente é a opção recomendada para transferir objetos do Amazon S3 para o Cloud Storage.
É possível configurar um job de transferência para programar a sincronização periódica da origem de dados com o coletor usando filtros avançados com base nas datas de criação dos arquivos, nos filtros de nome de arquivo e nas horas do dia em que você prefere importar dados. Para chegar ao RPO desejado, considere os seguintes fatores:
Taxa de mudança. A quantidade de dados que está sendo gerada ou atualizada por um determinado período. Quanto maior a taxa de alteração, mais recursos serão necessários para transferir as alterações para o destino em cada período de transferência incremental.
Desempenho da transferência. O tempo necessário para transferir arquivos. Para transferências de arquivos grandes, isso geralmente é determinado pela largura de banda disponível entre a origem e o destino. No entanto, se um job de transferência consistir em um grande número de arquivos pequenos, o QPS poderá se tornar um fator limitante. Se esse for o caso, programe vários jobs simultâneos para dimensionar o desempenho, desde que haja largura de banda suficiente disponível. Recomendamos que você meça o desempenho da transferência usando um subconjunto representativo de seus dados reais.
Frequência. O intervalo entre jobs de backup. A atualização de dados no destino é tão recente quanto a última vez que um job de transferência foi programado. Portanto, é importante que os intervalos entre jobs de transferência sucessivos não sejam maiores do que o objetivo de RPO. Por exemplo, se o objetivo de RPO for de 1 dia, o job de transferência precisará ser programado pelo menos uma vez por dia.
Monitoramento e alertas. O serviço de transferência do Cloud Storage fornece notificações do Pub/Sub em vários eventos. É recomendável se inscrever nessas notificações para lidar com falhas inesperadas ou alterações nos tempos de conclusão do job.
Outra opção para mover dados da AWS para o Google Cloud é usar o boto, que é uma ferramenta Python compatível com o Amazon S3 e o Cloud Storage. Ele pode ser instalado como um plug-in da ferramenta de linha de comando gsutil.
Backup e recuperação de banco de dados
Está fora do escopo deste artigo discutir detalhadamente os diversos mecanismos internos de backup e recuperação incluídos em bancos de dados de terceiros ou as técnicas de backup e recuperação usadas em outros provedores de nuvem. Se você estiver operando bancos de dados não gerenciados nos serviços de computação, use os recursos de alta disponibilidade que seu provedor de nuvem de produção disponibiliza. É possível estendê-las para incorporar uma implantação de alta disponibilidade ao Google Cloud ou usar o Cloud Storage como o destino final para o armazenamento de acesso raro dos arquivos de backup do banco de dados.
A seguir
- Leia sobre a Geografia e regiões do Google Cloud.
Leia outros artigos nesta série de DR:
- Guia de planejamento de recuperação de desastres
- Elementos básicos da recuperação de desastres
- Cenários de recuperação de desastres para aplicativos
- Como arquitetar a recuperação de desastres para cargas de trabalho com restrição de localidade
- Casos de uso da recuperação de desastres: aplicativos de análise de dados com restrição de localidade
- Como arquitetar a recuperação de desastres para interrupções de infraestrutura em nuvem
Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.