Este tutorial mostra como configurar o Elastic Stack em vários ambientes e como fazer uma migração de dados básica do Elastic Cloud no Kubernetes (ECK) para o Elastic Cloud no Google Cloud.
À medida que as organizações migram para o Google Cloud, as estratégias de migração se tornam importantes. Se a migração for de outro ambiente de nuvem ou de um ambiente local, será preciso garantir que os processos de negócios continuem com o mínimo de interrupções. A plataforma de dados que processa, armazena e exibe dados de análise geralmente pode fornecer insights críticos sobre como sua infraestrutura de negócios e de aplicativos está operando. Para muitas organizações, o Elastic Stack é um componente essencial que fornece esses insights.
Este tutorial é destinado a administradores de sistemas e arquitetos empresariais envolvidos na migração de sistemas e aplicativos para o Google Cloud. Com o tutorial, você tem experiência em instanciar o Elastic Stack em vários ambientes no Google Cloud.
Este tutorial foi desenvolvido e testado com a versão 1.0.1 do ECK.
Principais componentes
Este tutorial interage com as seguintes tecnologias:
- O Elastic Stack, que é uma plataforma que consiste nos seguintes componentes principais:
- Elasticsearch, que é um mecanismo distribuído de pesquisa e análise com base em JSON projetado para escalabilidade horizontal, confiabilidade máxima e gerenciamento simplificado.
- Kibana, que fornece uma forma aos seus dados e é a interface de usuário extensível para configurar e gerenciar todos os aspectos do Elastic Stack.
- Beats, que são remetentes leves, que enviam dados das máquinas edge para o Logstash e o Elasticsearch.
- Logstash, que é um pipeline de coleta de dados dinâmico com um ecossistema de plug-ins extensível e um forte sinergia do Elasticsearch.
- Elastic Cloud, que é um serviço hospedado e gerenciado pelo Elasticsearch e Kibana e pode ser executado no Google Cloud.
- ECK, que amplia os recursos básicos de orquestração do Kubernetes para dar suporte à configuração e ao gerenciamento do Elasticsearch, Kibana e do APM Server no Kubernetes.
- O Google Kubernetes Engine (GKE), que oferece um ambiente gerenciado para implantação, gerenciamento e escalonamento de aplicativos em contêineres usando a infraestrutura do Google. O ambiente do GKE consiste em várias máquinas (instâncias do Compute Engine) agrupadas para formar um cluster.
Objetivos
- Implantar o ECK no GKE.
- Carregar dados de amostra no cluster do ECK.
- Implantar o Elastic Cloud.
- Fazer um snapshot e carregar os dados no Cloud Storage.
- Restaurar a instância do ECK com o snapshot armazenado.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Compute Engine
- GKE
- Cloud Storage
- Elastic Cloud (consulte o Google Cloud Marketplace)
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
No Cloud Shell, ative as APIs do Compute Engine e do GKE:
gcloud services enable compute.googleapis.com \ container.googleapis.comEssas APIs são usadas para provisionar os recursos de computação necessários para implantar os recursos do GKE necessários para este tutorial. Esse processo pode levar alguns minutos. Quando ele for concluído, continue.
Defina a zona de computação padrão em que você implantará o banco de dados e os recursos de computação:
gcloud config set compute/zone us-central1-a export COMPUTE_ZONE=us-central1-aO tutorial usa
us-central1-apara a zona. Também é possível implantar em uma zona de sua escolha. Para mais informações, consulte Geografia e regiões.
Como implantar o ECK em um cluster do GKE
Nas seções a seguir, você configura a infraestrutura e o software necessários para executar o Elastic Cloud no Google Cloud.
Como provisionar uma conta de serviço para criar e gerenciar clusters do GKE
Nesta seção, você criará uma conta de serviço usada para criar e gerenciar o cluster do GKE para este tutorial. O cluster é uma instância de máquina virtual (VM) no Compute Engine que herda a conta de serviço padrão do Compute Engine por padrão. Esta conta de serviço tem mais permissões do que o tutorial exige. Como prática recomendada, siga o princípio do menor privilégio ao criar a conta de serviço.
Nas etapas a seguir, você concede os papéis de Leitor Monitoring (roles/monitoring.viewer ), Gravador de métricas do Monitoring
(roles/monitoring.metricWriter ) e ao Gravador de registros (roles/logging.logWriter) do IAM à conta de serviço. Você também concede o papel Administrador do Compute (roles/compute.admin) à conta de serviço. Esse papel fornece controle total de todos os recursos do Compute Engine. O tutorial não requer esse papel.
No entanto, se você continuar usando essa conta de serviço com o cluster e precisar adicionar nós de computação, o papel de administrador do Compute permitirá que você provisione os recursos extras de computação.
No Cloud Shell, defina o ID do projeto do Google Cloud como uma variável e defina o nome da conta de serviço:
export PROJECT_ID=$(gcloud config get-value project 2> /dev/null) export SA_ID=eck-saCrie a conta de serviço e uma nova variável com o endereço de e-mail da conta de serviço:
gcloud iam service-accounts create $SA_ID --display-name=$SA_ID export GKE_SA_EMAIL=$(gcloud iam service-accounts list \ --filter=displayName:"$SA_ID" --format='value(email)')A sincronização dos metadados pode demorar um pouco. Após a sincronização, o endereço de e-mail será exibido na variável. Até lá, a variável ficará em branco.
Verifique se a variável de ambiente local está definida com o ID da conta de serviço:
echo $GKE_SA_EMAILSe a saída estiver em branco, execute novamente o comando
exportanterior até que a variável seja preenchida. Se a variável de ambiente estiver definida, você verá o ID da conta de serviço, que se parece com um endereço de e-mail.Depois que os metadados forem sincronizados, anexe as vinculações de política à conta de serviço:
gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/logging.logWriter gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/monitoring.metricWriter gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/monitoring.viewer gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/storage.admin gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/compute.admin
Como criar o cluster do GKE
A próxima etapa é implantar seu cluster. O comando a seguir cria um cluster de três nós usando o tipo de máquina n1-standard-4 com discos permanentes de 256 GB (SSD, na sigla em inglês). É possível alterar esses recursos.
No Cloud Shell, implante o cluster:
gcloud container clusters create "eck-tutorial" \ --project $PROJECT_ID --zone $COMPUTE_ZONE \ --service-account $GKE_SA_EMAIL \ --no-enable-basic-auth --machine-type "n1-standard-4" \ --image-type "COS" --disk-type "pd-standard" \ --disk-size "256" --metadata disable-legacy-endpoints=true \ --num-nodes "3" \ --enable-ip-alias --no-issue-client-certificateReceba as credenciais de autenticação para que
kubectlpossa interagir com seu novo cluster:gcloud container clusters get-credentials eck-tutorial
Primeiros passos com o ECK
A próxima etapa é configurar o ECK para ser executado na infraestrutura provisionada.
Como implantar o operador do Elasticsearch
O padrão Operator do Kubernetes permite recursos personalizados no Kubernetes. O Operador do Elasticsearch usa esse padrão para implantar componentes do Elastic Stack no Kubernetes.
No Cloud Shell, instale as definições de recursos personalizados (CRDs):
kubectl apply -f https://download.elastic.co/downloads/eck/1.0.1/all-in-one.yaml(Opcional) Monitore os registros do operador:
watch kubectl -n elastic-system logs -f statefulset.apps/elastic-operatorNormalmente, o ECK fica pronto menos de um minuto depois de instalar os CRDs.
Como gerar o secret para acessar o Cloud Storage
A próxima etapa é permitir que o novo cluster do Elasticsearch leia e grave snapshots em um bucket do Cloud Storage.
No Cloud Shell, gere uma chave de conta de serviço e um secret do Kubernetes:
gcloud iam service-accounts keys create ~/gcs.client.default.credentials_file \ --iam-account=$GKE_SA_EMAIL kubectl create secret generic gcs-credentials \ --from-file=gcs.client.default.credentials_fileCrie um bucket do Cloud Storage para os snapshots e exiba o nome do bucket:
export GCSBUCKET=$RANDOM-eck-gcs-snapshot && gsutil mb gs://$GCSBUCKETCopie o nome do bucket porque você precisará dele para uma etapa posterior.
Como implantar o Elastic Stack
No Cloud Shell, aplique uma especificação de cluster de amostra, que implanta servidores para Elasticsearch, Kibana e APM Server no cluster:
cat << 'EOF' > ~/eck.yaml apiVersion: elasticsearch.k8s.elastic.co/v1 kind: Elasticsearch metadata: name: quickstart spec: version: 7.6.1 secureSettings: - secretName: gcs-credentials nodeSets: - name: default count: 3 config: node.master: true node.data: true node.ingest: true node.store.allow_mmap: false podTemplate: spec: initContainers: - name: install-plugins command: - sh - -c - | bin/elasticsearch-plugin install --batch repository-gcs --- apiVersion: kibana.k8s.elastic.co/v1 kind: Kibana metadata: name: kibana-sample spec: version: 7.6.1 count: 1 elasticsearchRef: name: quickstart --- apiVersion: apm.k8s.elastic.co/v1 kind: ApmServer metadata: name: apm-server-sample spec: version: 7.6.1 count: 1 elasticsearchRef: name: quickstart EOF kubectl apply -f eck.yaml(Opcional) Veja o status da sua implantação:
watch kubectl get elasticsearch,kibana,apmserverQuando os indicadores de integridade dos três serviços estiverem verdes, o cluster estará em execução.
Como criar um balanceador de carga e fazer login no Kibana
Por padrão, os serviços no cluster têm apenas endereços IP internos e não podem ser acessados pela Internet pública. Se você executar o comando kubectl get services, verá como todos os serviços têm um endereço IP interno e nenhum endereço IP externo. Para se conectar ao Kibana por meio do navegador da Web, você precisa expor o aplicativo, que pode ser feito de várias maneiras, cada uma com suas próprias vantagens e vantagens. Neste tutorial, você criará um balanceador de carga.
No Cloud Shell, crie o balanceador de carga:
kubectl expose deployment kibana-sample-kb \ --type=LoadBalancer \ --port 5601 \ --target-port 5601Esse balanceador de carga recebe solicitações na porta
5601, que é a porta padrão para o serviço Kibana.Verifique se há um novo serviço de balanceador de carga chamado
kibana-sample-kb:watch kubectl get servicesAguarde o provisionamento do endereço IP externo.
Quando o endereço aparecer, copie o URL na variável
EXTERNAL_IPe cole o URL inteiro no navegador para carregar o portal do Kibana:https://EXTERNAL_IP:5601
Se estiver usando o Google Chrome, clique em Avançado e em Continuar mesmo assim.
Faça login no portal usando o nome de usuário
elastic. Para descobrir a senha e defini-la como uma variável, no Cloud Shell, execute o seguinte comando:PASSWORD=$(kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode) && echo $PASSWORDSe você quiser alterar essa senha posteriormente, convém salvá-la em um local seguro.
Como carregar e preparar dados de amostra
Ao fazer login no Kibana pela primeira vez, você terá que começar a usar dados de amostra.
No portal do Kibana, clique em Experimentar nossos dados de amostra:
No card Dados de voo de amostra, clique em Adicionar dados para acrescentar os dados de voo de amostra.
Para se familiarizar com as amostras, explore o painel e o mapa.
Como consultar dados do Elasticsearch
A próxima etapa é verificar se você pode consultar os dados do Elasticsearch. Primeiro, você encaminha a porta 9200 (a porta que o serviço Elasticsearch escuta) do cluster ECK para sua máquina local. Depois, você executa consultas de teste nos dados.
No Cloud Shell, ative o encaminhamento de portas:
kubectl port-forward service/quickstart-es-http 9200Na barra de menus do Cloud Shell, clique em Abrir uma nova guia. Uma segunda sessão do Cloud Shell é iniciada.
Armazene a senha de usuário do Elastic como uma variável local:
PASSWORD=$(kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode)Teste a conectividade:
curl -u "elastic:$PASSWORD" -k "https://localhost:9200"A resposta será semelhante a:
{ "name" : "quickstart-es-default-0", "cluster_name" : "quickstart", "cluster_uuid" : "ifdFjTixQ9q7sVc7uUpSnA", "version" : { "number" : "7.6.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b", "build_date" : "2020-02-29T00:15:25.529771Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }Conte o número de documentos no conjunto de dados de amostra:
curl -u "elastic:$PASSWORD" -k "https://localhost:9200/kibana_sample_data_flights/_count"A resposta será semelhante a:
{"count":13059,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}A saída indica que o índice contém 13.059 documentos.
Feche a segunda sessão do terminal do Cloud Shell, mas mantenha a sessão original aberta.
Na sessão original do Cloud Shell, pressione Control+C para parar o encaminhamento de portas, já que ele não é mais necessário.
Como registrar um registro de snapshot
Para criar e restaurar snapshots, é necessário registrar um repositório de snapshots.
No portal do Kibana, clique em Criar snapshot e Restaurar no menu Elasticsearch e em Registrar um repositório:
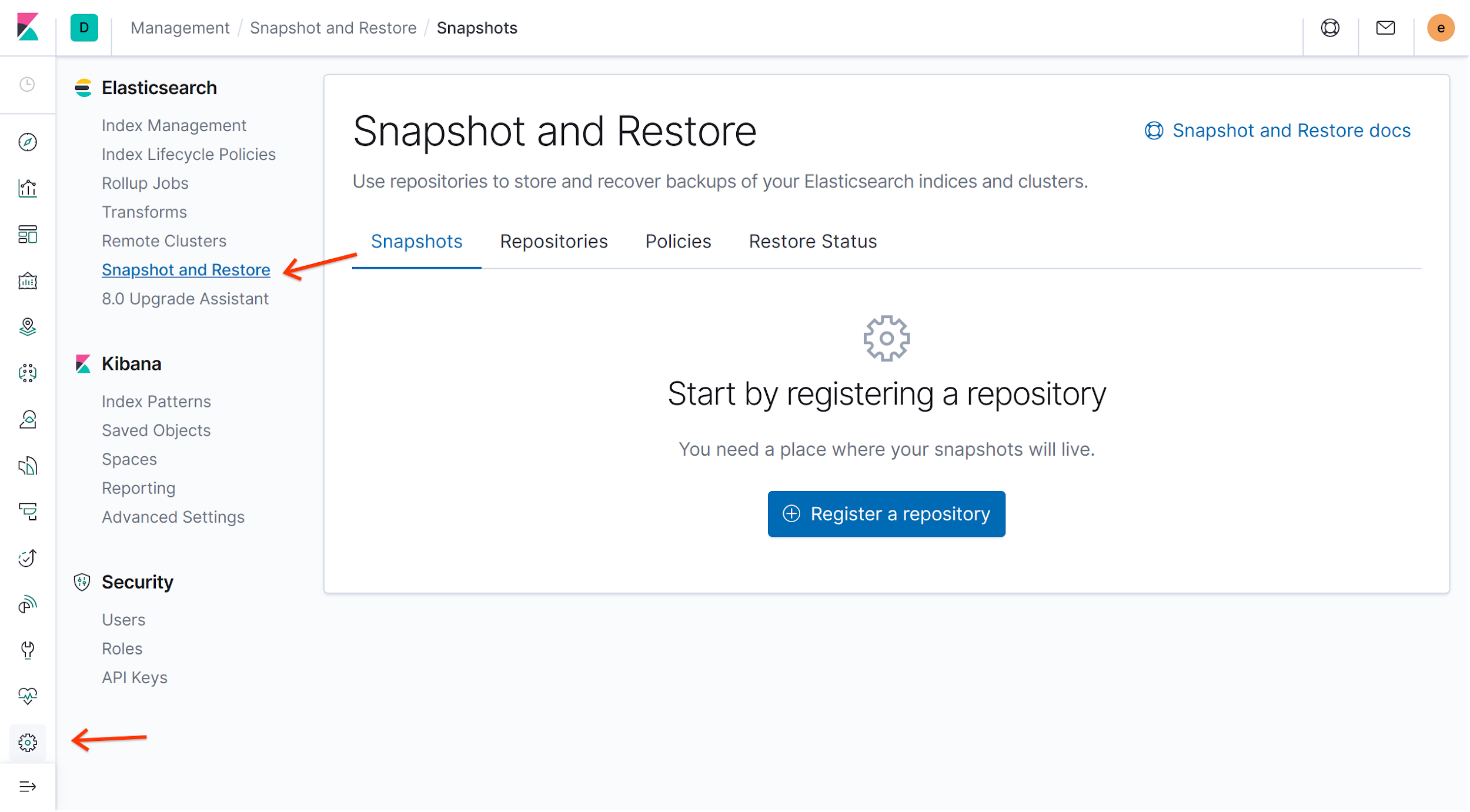
Na página Registrar repositório, digite
examplerepono campo Nome, selecione Google Cloud Storage como o tipo de repositório e em seguida, clique em Avançar: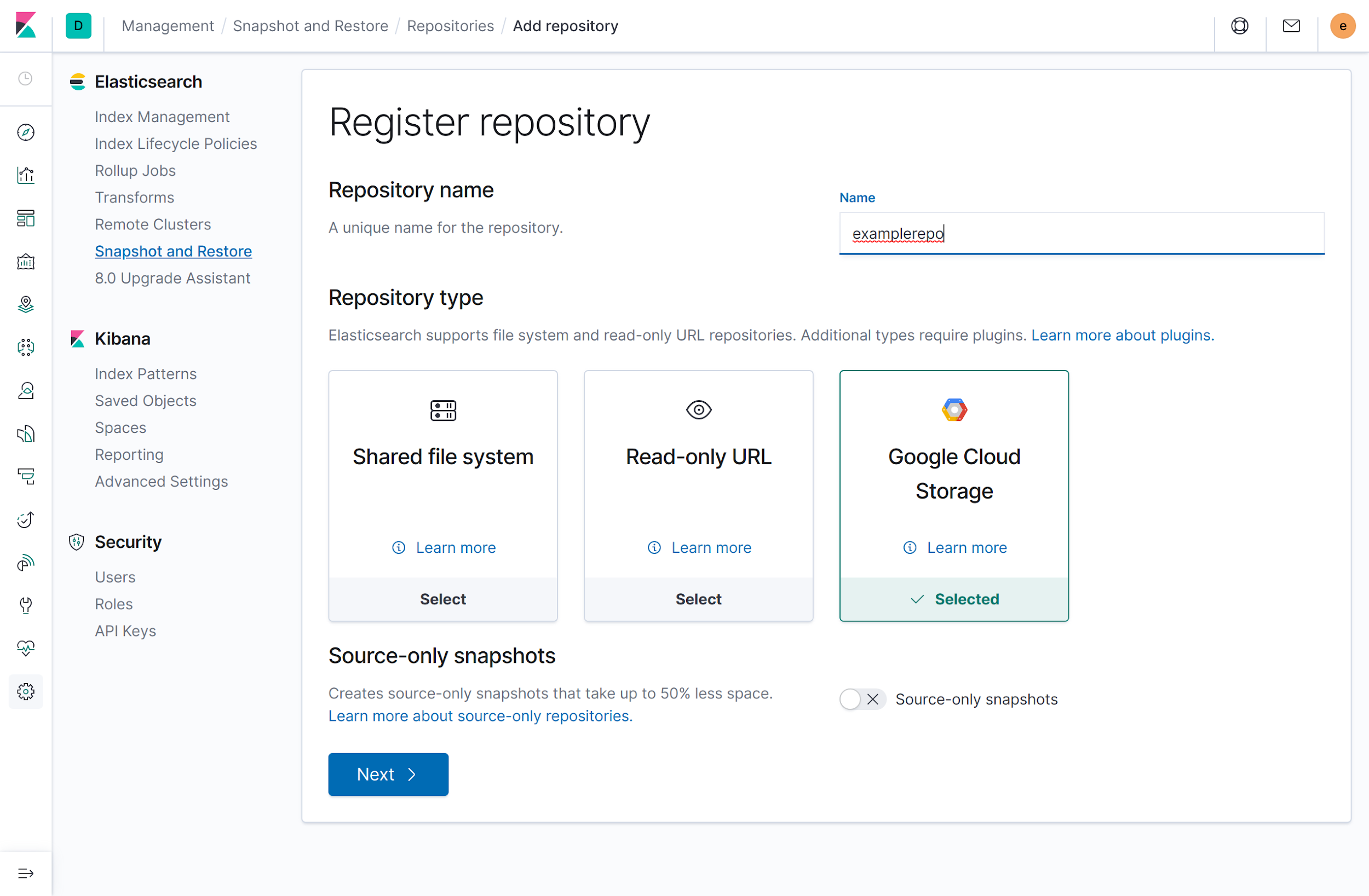
Digite os seguintes detalhes de configuração:
- Em Cliente, insira
default. Em Bucket, insira o nome do bucket que você criou anteriormente em Gerar o secret para acessar o Cloud Storage.
Se você não conseguir se lembrar do nome do bucket, faça o seguinte:
No Cloud Shell, liste todos os buckets:
gsutil lsPara localizar seu bucket, revise a lista.
No portal, insira o nome do bucket sem o esquema de nomenclatura
gs://da etapa anterior. Por exemplo, se o URI do bucket forgs://1234-eck-gcs-snapshot, insira1234-eck-gcs-snapshot.
Deixe o restante dos campos em branco.
- Em Cliente, insira
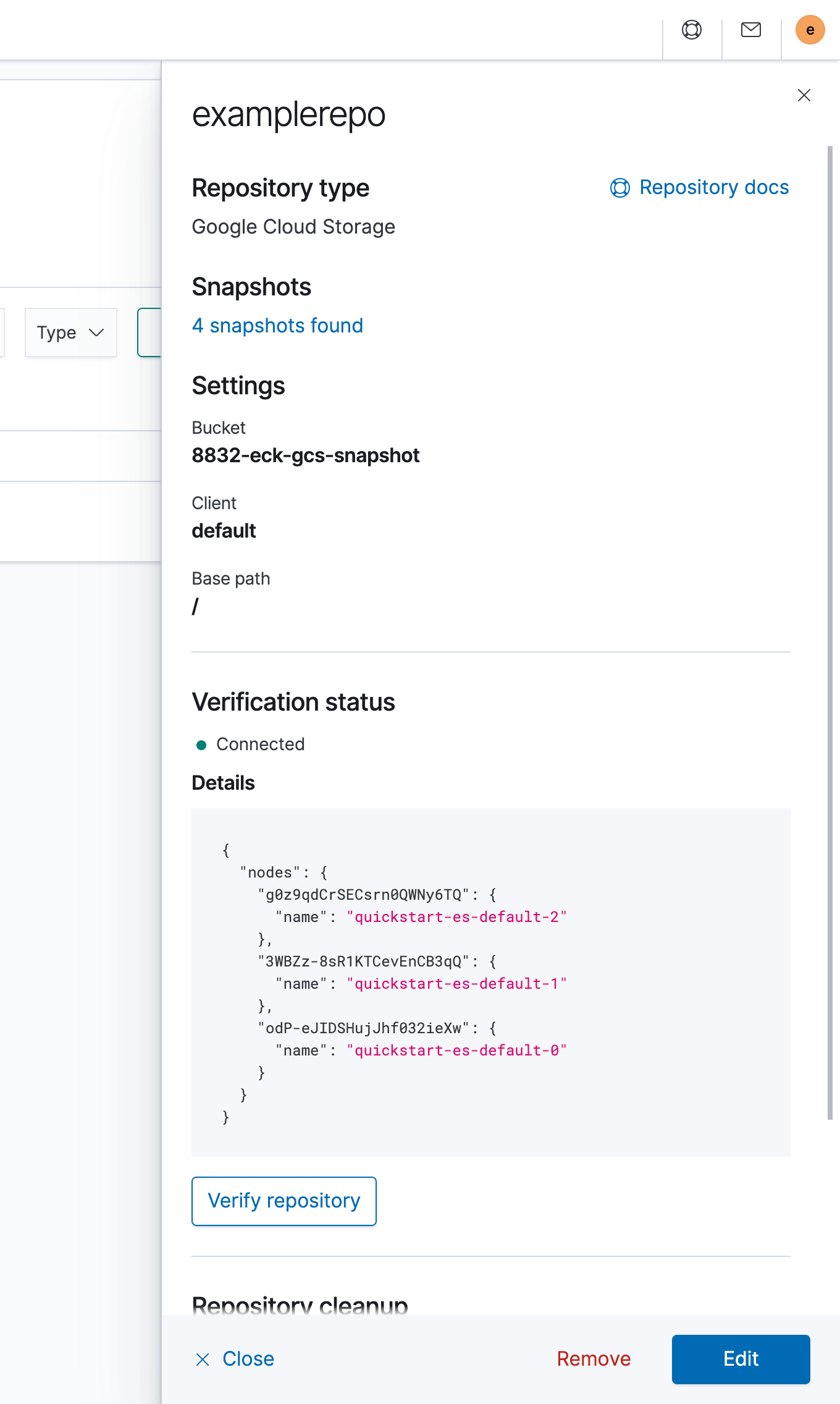
Clique em Registrar.
No painel de detalhes do repositório, clique em Verificar repositório para garantir que você esteja conectado. O diagrama a seguir mostra uma conexão bem-sucedida:
Primeiros passos com o Elastic Cloud
Agora você já pode configurar um cluster hospedado no Elastic Cloud e migrar os dados para ele.
Como iniciar um cluster
Acesse a página do Elastic Cloud no Cloud Marketplace.
Se você aceitar os preços mostrados na página, clique em Comprar e, em seguida, selecione Assinar.
Clique em Ativar para ativar as APIs. Você será redirecionado para a página API e Serviços do serviço Elastic Cloud.
Clique em Gerenciar pelo Elastic:
Para confirmar que você quer ser redirecionado para o site do Elastic Cloud, clique em Confirmar.
Para registrar sua conta do Elastic Cloud, preencha o formulário. Sua conta de e-mail foi verificada.
Quando solicitado, crie uma senha e faça login.
No portal principal do Elastic Cloud, clique em Criar implantação.
Faça o seguinte:
- Nomeie o cluster
example-ec. - Selecione Google Cloud como plataforma de nuvem.
- Selecione
us-central1como a região. - Deixe todas as outras opções nos valores padrão.
- Nomeie o cluster
Clique em Criar implantação.
Depois de alguns minutos, o cluster em funcionamento no Elastic Cloud será provisionado e você será direcionado automaticamente para o painel de implantação da sua instância.
Como preparar o snapshot do ECK
A próxima etapa é criar um snapshot da sua instância do ECK e migrá-la para a instância do Elastic Cloud.
Como criar o snapshot do ECK
Para criar um snapshot, é necessário configurar uma política de snapshot no cluster do ECK. Depois de criar um único snapshot, essa política será excluída porque é necessária apenas para essa migração única.
Em um navegador da Web no cluster do ECK, faça login no Kibana copiando o endereço IP externo do balanceador de carga que você criou anteriormente no cluster do GKE.
No menu do Elasticsearch, clique em Criar snapshot e Restaurar:
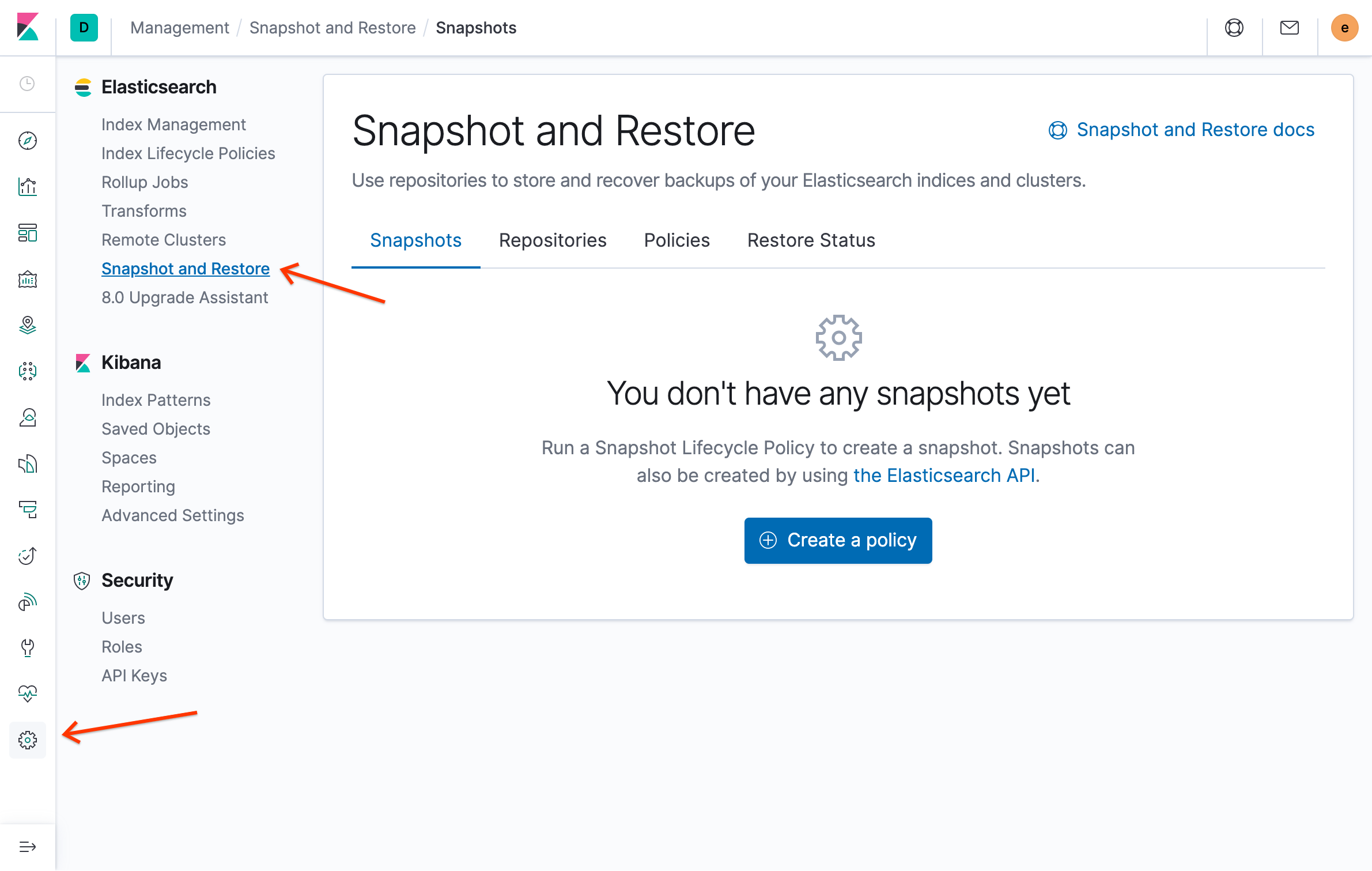
Clique em Criar uma política.
No campo Nome da política, digite
onetime-migration.No campo Nome do snapshot, digite
<onetime-migration-{now/d}>.Deixe as outras configurações nos valores padrão e clique em Avançar:
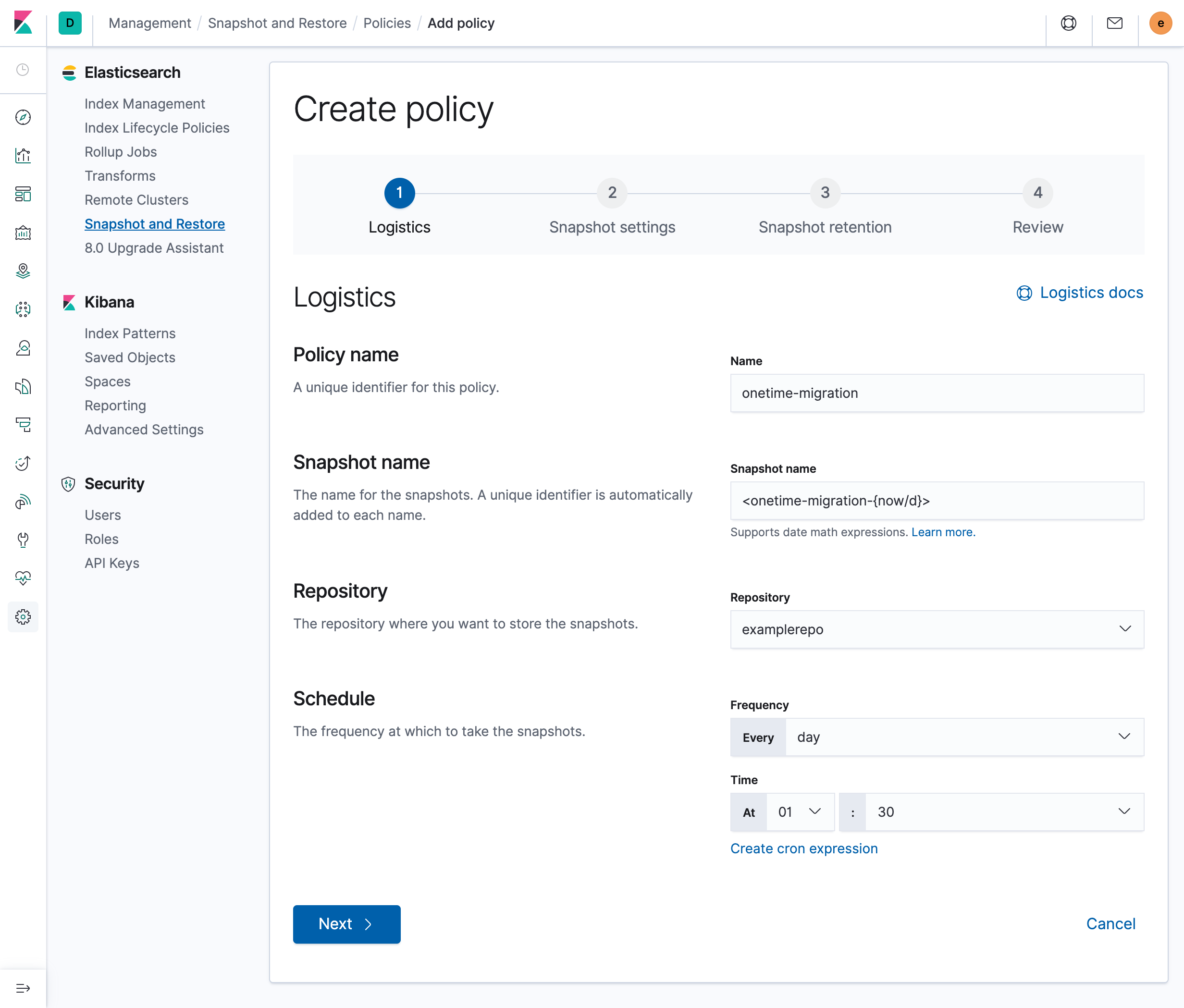
Na página Configurações de snapshot, deixe as configurações com os valores padrão e clique em Avançar.
Quando for solicitada uma política de retenção de snapshots, deixe todos os campos em branco e clique em Avançar. Como você está criando um snapshot único, não é necessária uma política de retenção.
Na página Revisar política, clique em Criar política.
No painel de resumo da política, clique em Fechar.
Na seção Ações da página de visão geral Criar snapshot e Restaurar, clique em Executar agora e clique em Executar política na nova janela:
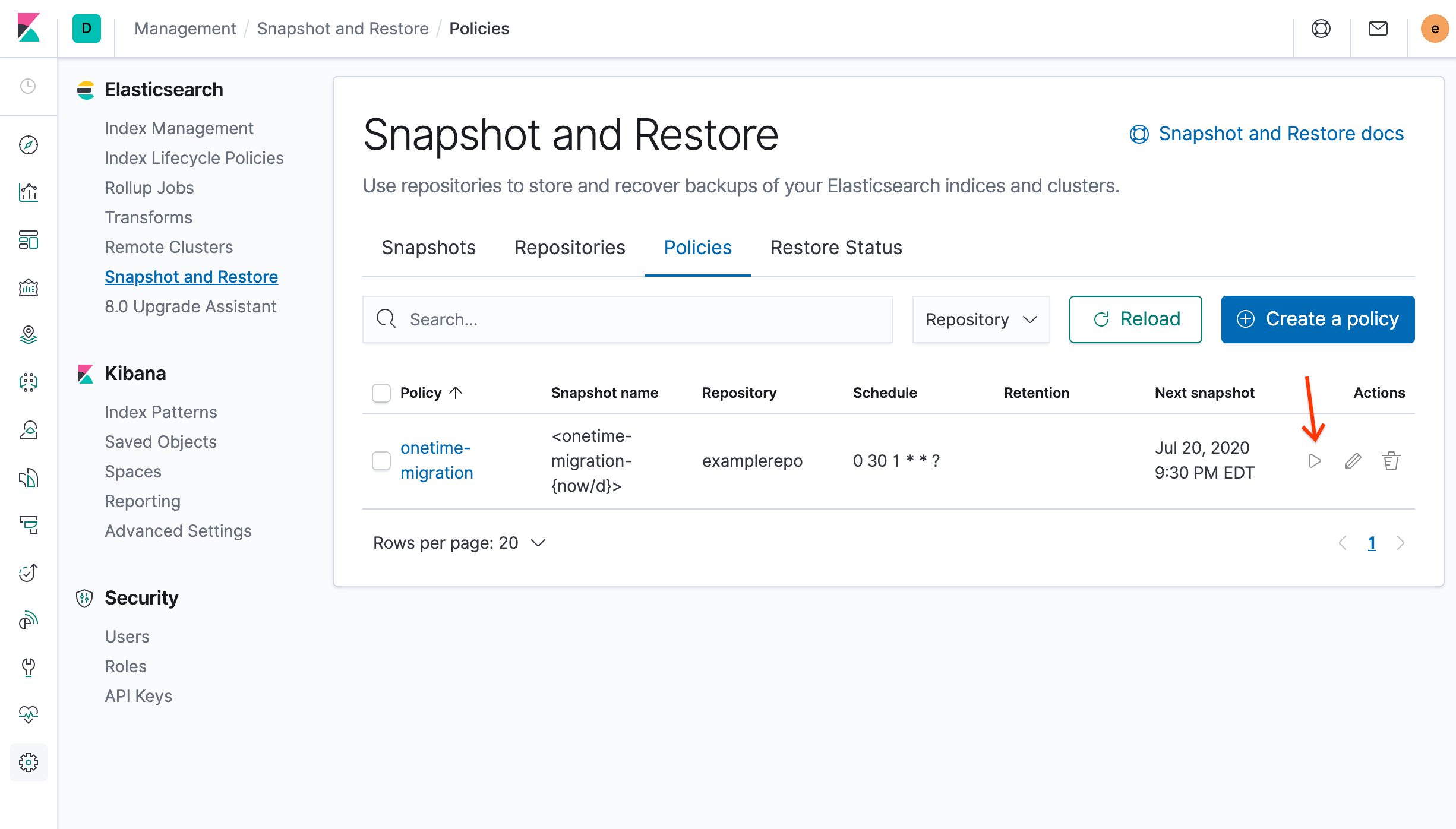
Para verificar seu novo snapshot, na guia Snapshots, clique no snapshot com carimbo de data/hora que começa com
onetime-migration. Os detalhes do snapshot são exibidos: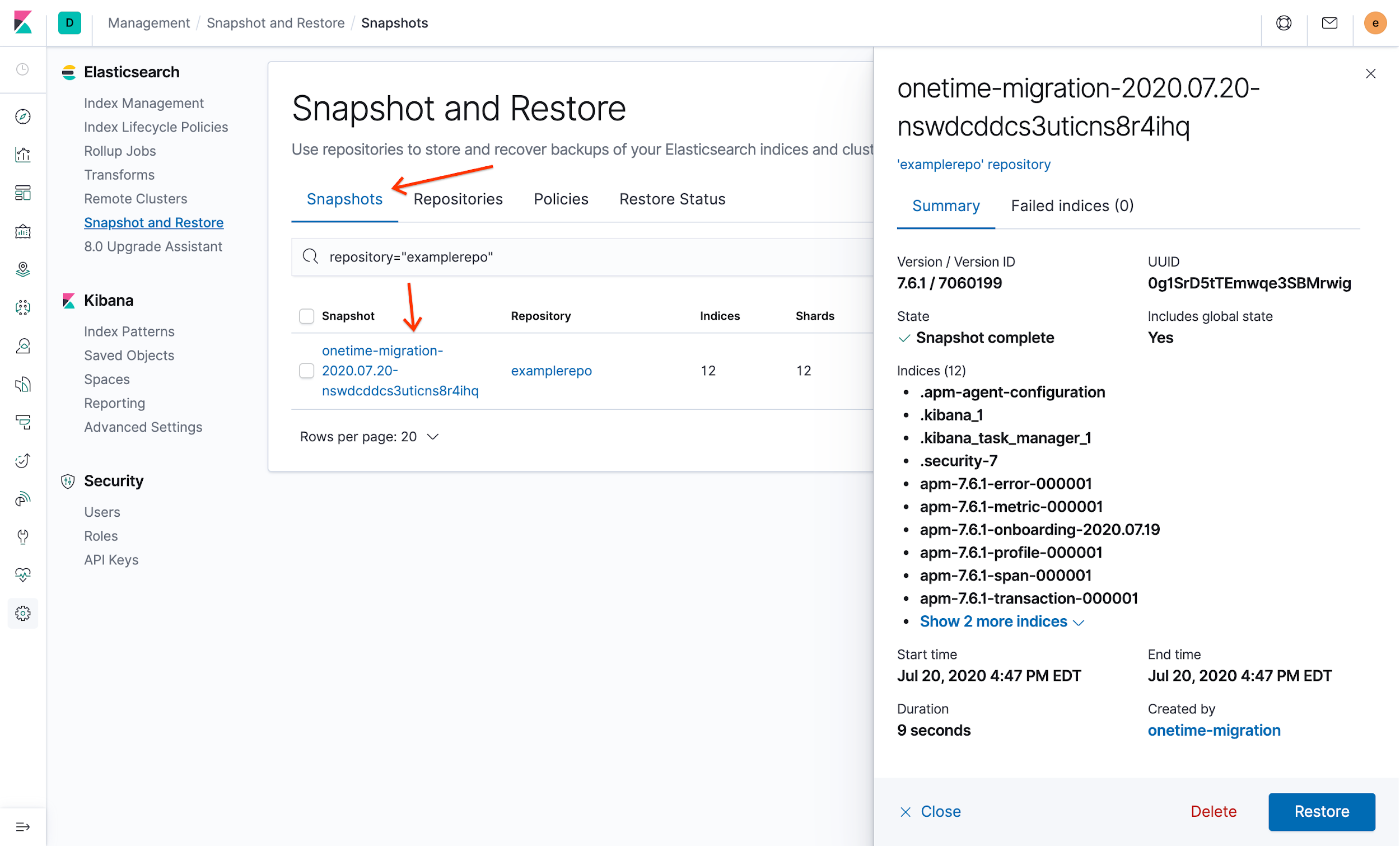
Como excluir a política de snapshot
Agora que o snapshot da instância do ECK está no Cloud Storage, é possível excluir a política de snapshots.
- No portal do Kibana, clique em Gerenciamento, depois em Criar snapshot e Restaurar e depois clique na guia Políticas.
- Na seção Ações da política de migração única, clique em Excluir.
- Para confirmar que você quer excluir a política, clique em Excluir política.
A exclusão da política não afeta snapshots criados com ela. No entanto, isso impede que você tire mais snapshots com base nessa política.
Como mover o snapshot para o Elastic Cloud
A próxima etapa é tirar o snapshot de dados recém-criado e restaurá-lo na instância no Elastic Cloud.
Como criar e configurar uma nova conta de serviço
A primeira etapa é criar uma conta de serviço que o Elastic Cloud use para acessar o Cloud Storage. Depois, ative o acesso.
No Cloud Shell, crie a conta de serviço:
gcloud iam service-accounts create ecloud-sa \ --display-name "Elasticcloud Service Account" export ec_sa=$(gcloud iam service-accounts list \ --filter=displayName:"Elasticcloud Service Account" \ --format='value(email)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$ec_sa --role roles/storage.admin gsutil iam ch serviceAccount:$ec_sa:roles/storage.admin gs://$GCSBUCKETCrie uma chave para essa conta de serviço e faça o download dela na sua máquina cliente local:
gcloud iam service-accounts keys create ~/ec-sa.json --iam-account $ec_saA resposta será semelhante a:
created key [e44da1202f82f8f4bdd9d92bc412d1d8a837fa83] of type [json] as [/usr/home/username/ec-sa.json] for [ecloud-sa@project-id.iam.gserviceaccount.com]
Copie o caminho absoluto e o nome do arquivo de saída. Eles são necessários para fazer o download do arquivo.
Clique em Mais e, em seguida, clique em Fazer o download do arquivo:
Insira o caminho absoluto e o nome do arquivo da chave que você copiou na etapa anterior e clique em Fazer o download. A chave JSON é transferida por download para sua máquina local.
Na página do Elasticsearch Service da implantação no Elastic Cloud, clique em Segurança e em Adicionar configurações:
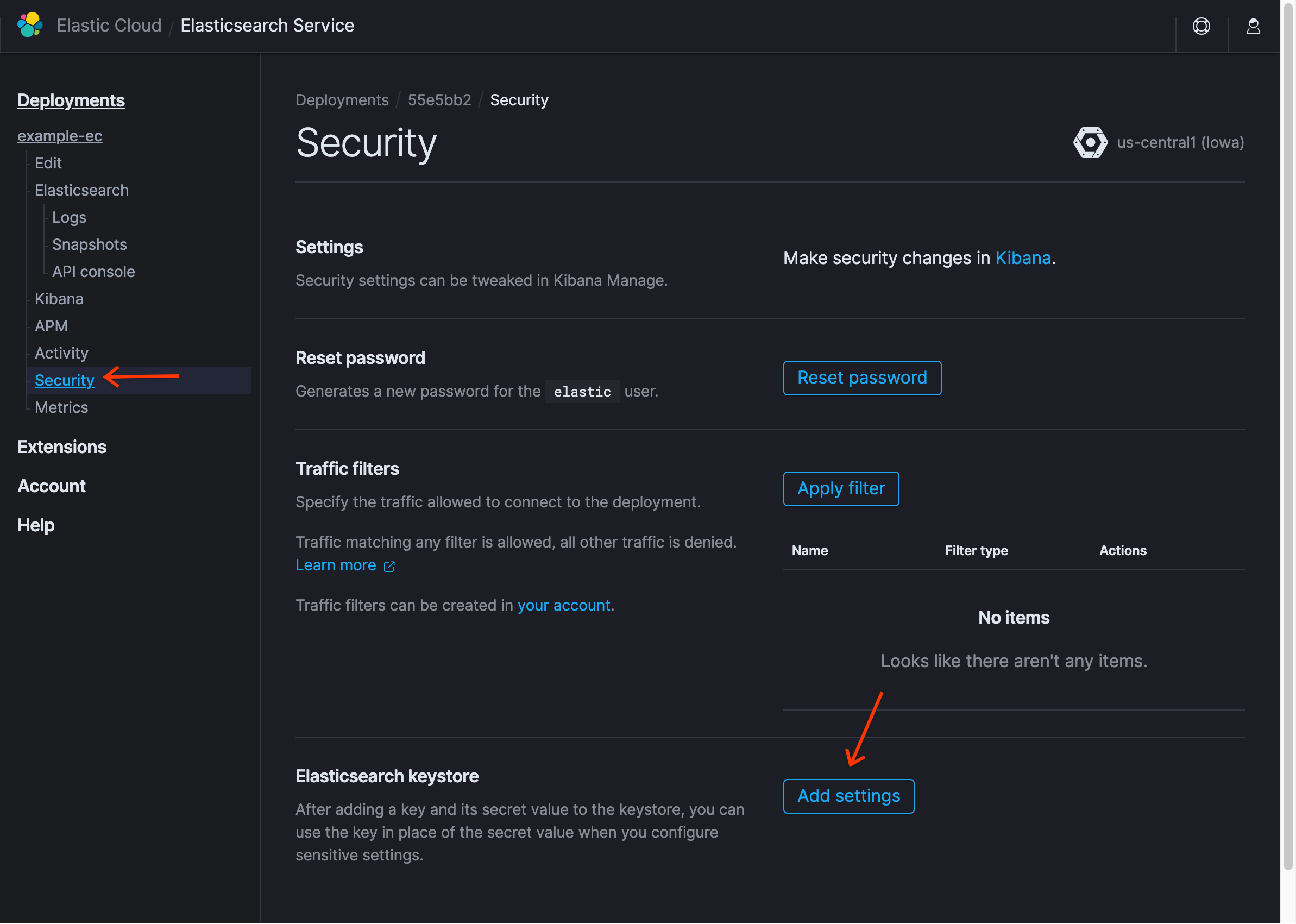
Em Nome da configuração, insira
gcs.client.default.credentials_filee selecione Bloco/arquivo JSON.Usando um editor de texto na máquina local, abra a chave JSON que você baixou e copie o texto no campo Secret e clique em Salvar. Você verá a nova entrada no keystore.
Clique em Redefinir senha para conseguir uma nova senha para o usuário
elastice anote-a.Na instrução Fazer alterações de segurança no Kibana, clique em Kibana.
Usando essas credenciais, faça login no Kibana.
Quando solicitado, clique em Explorar por conta própria e não carregue dados de amostra.
Como criar um repositório
No portal do Kibana, clique no ícone de menu () e em Gerenciamento de pilha:
No Elasticsearch, clique em Criar snapshot e Restaurar.
Clique na guia Repositórios e, em seguida, clique em Registrar um repositório:
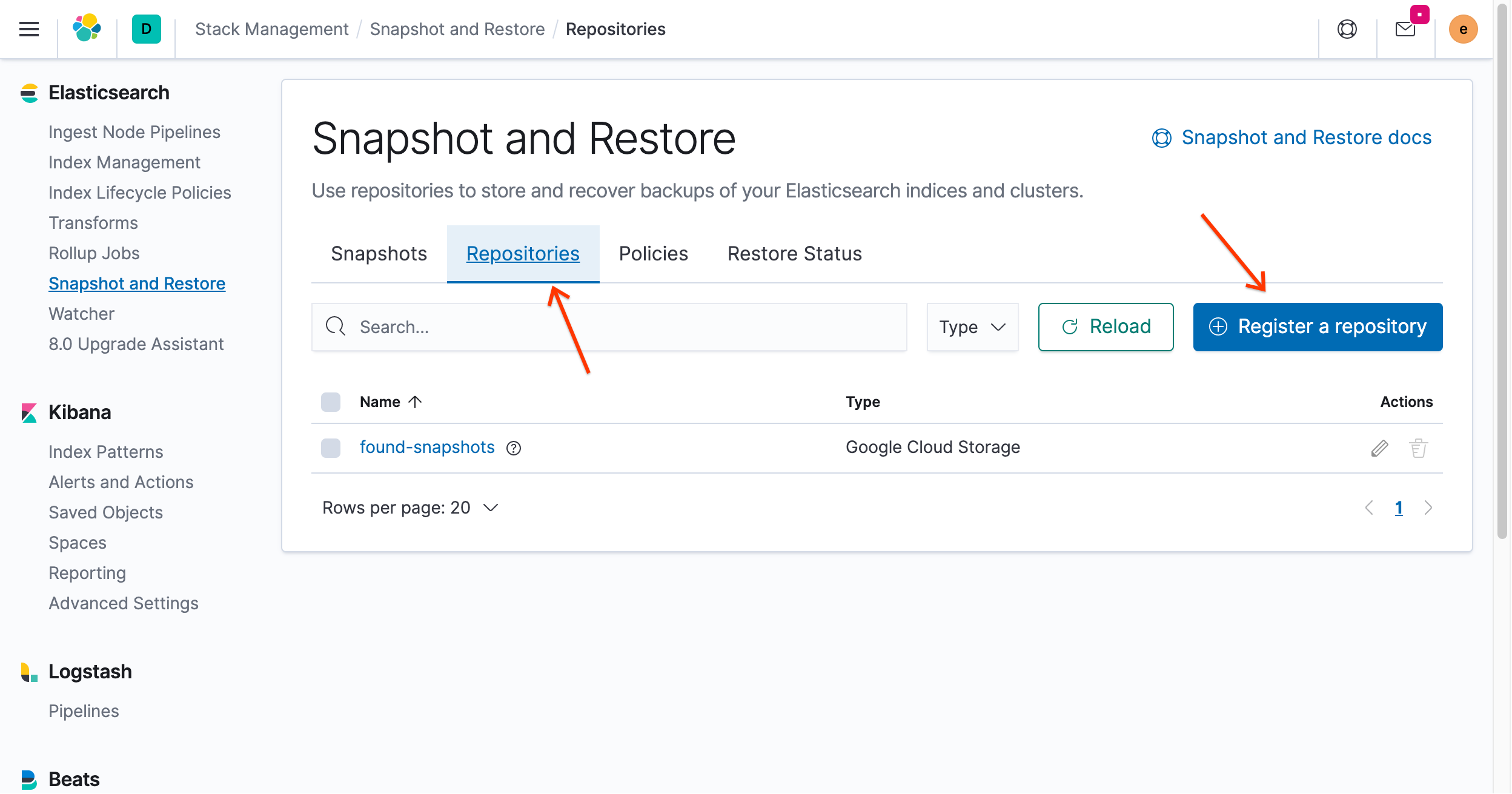
Para o nome do repositório, insira
examplerepo.Selecione Google Cloud Storage.
Clique em Avançar.
No campo Bucket, insira o nome do bucket que você criou anteriormente em Gerar o secret para acessar o Cloud Storage.
Insira o nome do bucket sem o esquema de nomenclatura
gs://. Por exemplo, se o URI do bucket forgs://1234-eck-gcs-snapshot, insira1234-eck-gcs-snapshot.Deixe os outros campos em branco e clique em Registrar.
Para verificar a conexão, clique em Verificar repositório.
Clique em Fechar.
Como restaurar o snapshot
No portal do Kibana, clique na guia Snapshots e, no menu suspenso Repositório, selecione
examplerepo: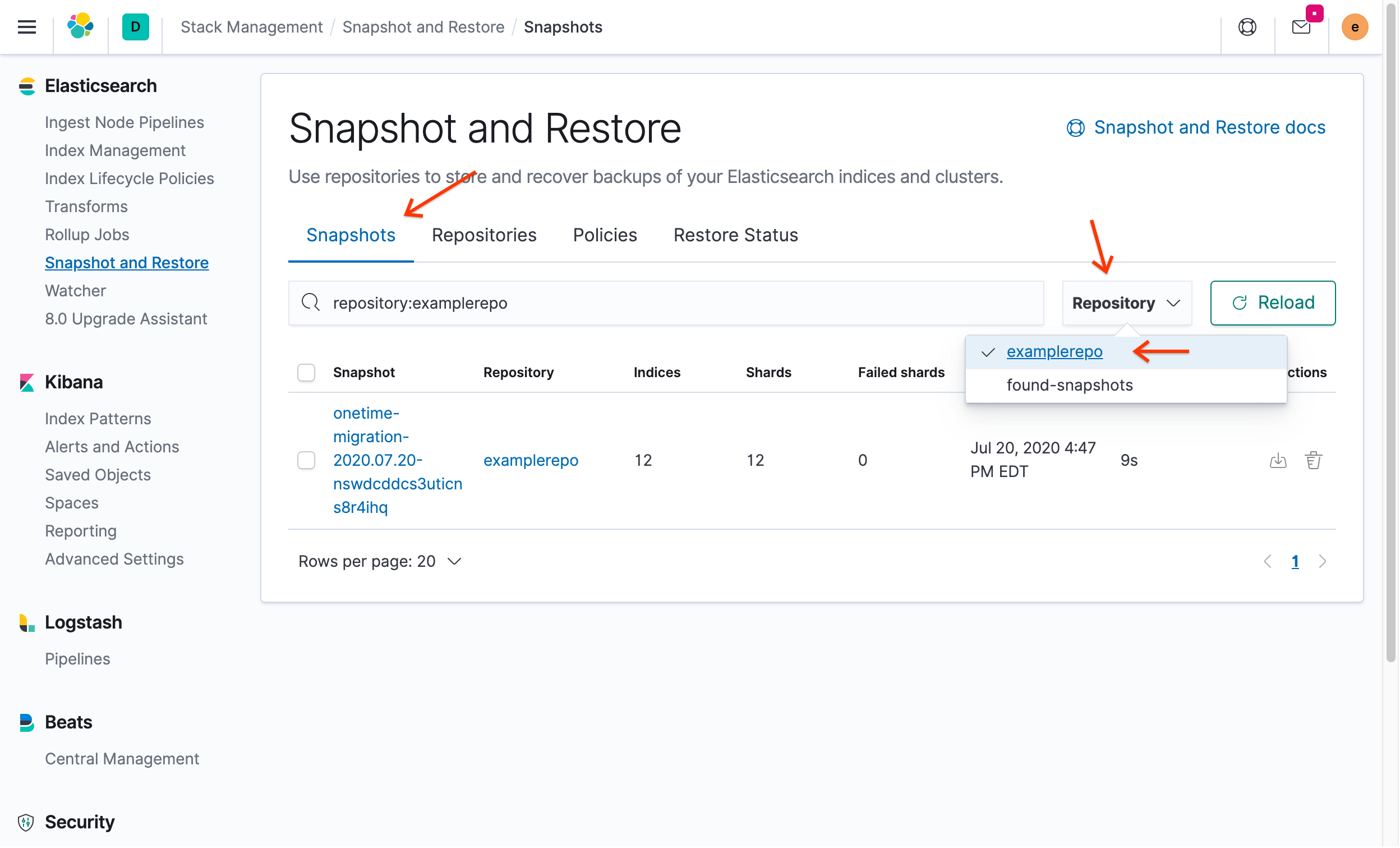
Você verá o snapshot criado anteriormente no ECK.
Em Ações, clique em Restaurar.
Desative a opção Todos os índices, incluindo índices do sistema:
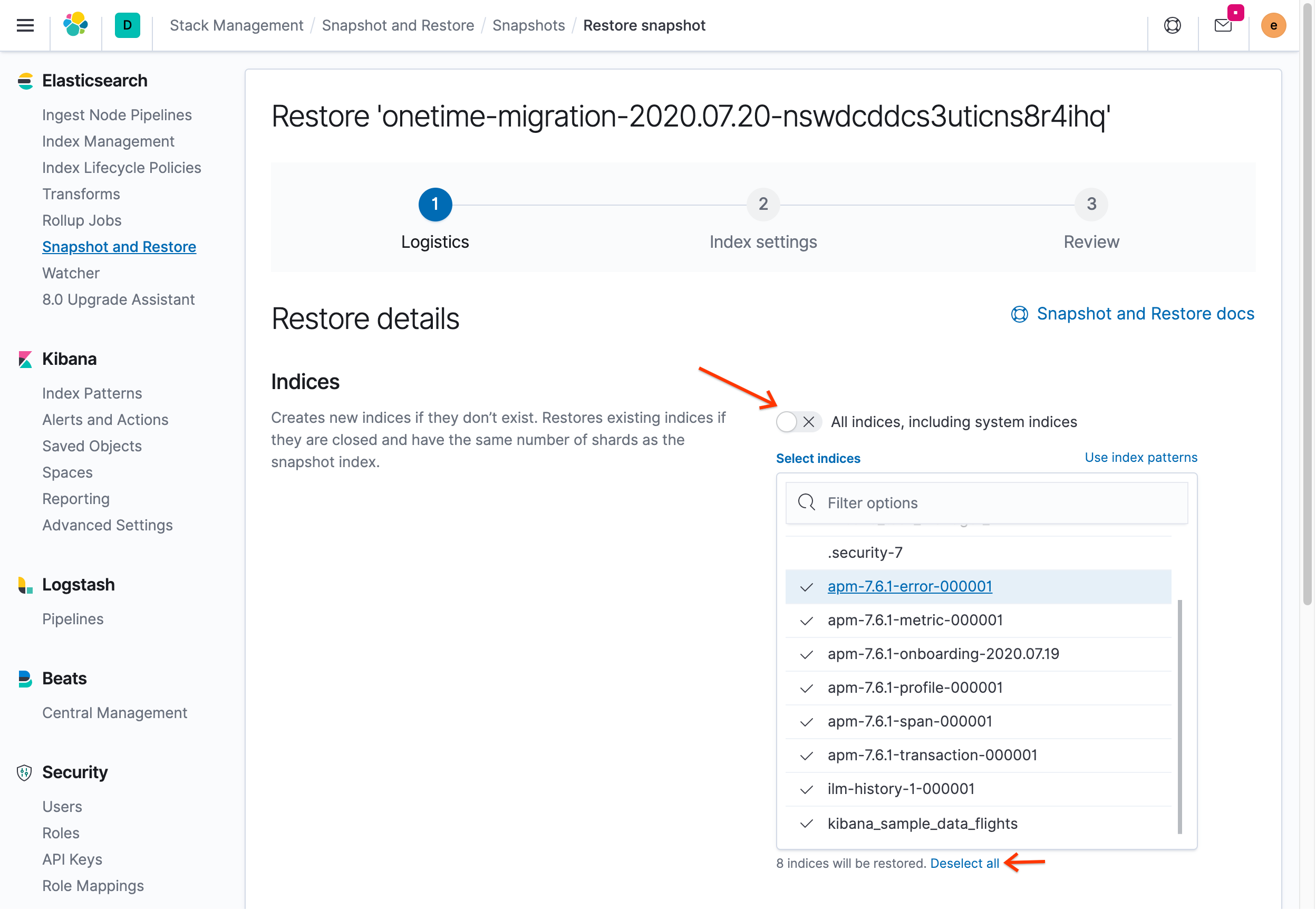
Clique em Desmarcar tudo e selecione novamente kibana_sample_data_flights, ilm-history-1-000001 e todos os índices com o prefixo apm-. Não selecione nenhum índice que tenha um ponto antes do nome porque ele é um índice do sistema.
Se você tentar restaurar usando as configurações padrão, receberá uma mensagem de erro semelhante a esta:
[snapshot_restore_exception] [examplerepo:onetime-migration2020.07.07-mt2pg1p7sb2sci9fs-yxlw/7OdEOWYVRQyIh9S2NaPypQ] cannot restore index [.security-7] because an open index with same name already exists in the cluster. Either close or delete the existing index or restore the index under a different name by providing a rename pattern and replacement name
Esse erro ocorre porque os índices do sistema não podem ser restaurados. Se você seguir as instruções da mensagem, o Kibana poderá não funcionar mais corretamente. O procedimento para fechar ou excluir um índice aberto existente é apenas para índices que não sejam do sistema.
Não altere os valores padrão das configurações e clique em Avançar.
No menu Configurações de índice, deixe todas as configurações como padrão e clique em Avançar.
Na página Restaurar detalhes, clique em Restaurar snapshot.
Quando o processo de restauração for concluído, você será levado ao painel Restaurar status, que mostra que os dados foram restaurados.
Em Kibana, clique em Padrões de indexação para restaurar o índice.
Clique em Criar padrão de índice.
Você verá alguns índices disponíveis. Procure o índice kibana_sample_data_flights, criado automaticamente pelo ECK.
Insira
kibno campo Padrão de indexação. Observe quekibana_sample_data_flightscorresponde ao padrão.Clique em Próxima etapa.
No menu suspenso Nome do campo "Filtro de tempo", selecione carimbo de data/hora.
Clique em Criar padrão de índice.
(Opcional) Se você clicar em Descobrir, verá que os dados brutos aparecem como exibido anteriormente no ambiente ECK.
No menu principal, role até o final do menu e, na seção Gerenciamento, clique em Ferramentas de desenvolvedor.
No lado esquerdo, insira
GET /kibana_sample_data_flights/_counte clique no botão para enviar uma solicitação. A saída mostra que 13.059 documentos foram contados, o que corresponde ao número de documentos encontrados no índice no ECK.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste tutorial, exclua o projeto do Google Cloud criado para este tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Configure o Elasticsearch no Elastic Cloud usando o Google Cloud no Cloud Marketplace.
- Leia sobre as práticas recomendadas do Kubernetes no blog do Google Cloud.
- Use tutoriais para começar a usar o GKE.
- Confira o conteúdo de migração de dados do Google Cloud. Confira o Centro de arquitetura do Cloud.