In dieser Anleitung erfahren Sie, wie Sie die Elastic Stack-Plattform in verschiedenen Umgebungen einrichten und eine einfache Datenmigration aus Elastic Cloud on Kubernetes (ECK) nach Elastic Cloud in Google Cloud durchführen.
Wenn Organisationen zu Google Cloud wechseln, sind Migrationsstrategien wichtig. Unabhängig davon, ob Sie von einer anderen Cloud-Umgebung oder einer lokalen Umgebung aus wechseln, müssen Geschäftsprozesse mit minimaler Unterbrechung fortgesetzt werden. Die Datenplattform, die Analysedaten verarbeitet, speichert und bereitstellt, kann oft wichtige Einblicke in den Betrieb Ihrer Unternehmens- und Anwendungsinfrastruktur bieten. In vielen Organisationen ist Elastic Stack eine wichtige Komponente, die entsprechende Informationen liefert.
Diese Anleitung richtet sich an Daten- und Unternehmensarchitekten sowie Systemadministratoren, die an der Migration von Systemen und Anwendungen zu Google Cloud beteiligt sind. In dieser Anleitung lernen Sie, wie Sie den Elastic Stack in verschiedenen Umgebungen in Google Cloud instanziieren.
Diese Anleitung wurde mit ECK Version 1.0.1 entwickelt und getestet.
Schlüsselkomponenten
Diese Anleitung interagiert mit den folgenden Technologien:
- Der Elastic Stack ist eine Plattform, die aus den folgenden Hauptkomponenten besteht:
- Elasticsearch ist eine verteilte, JSON-basierte Such- und Analyse-Engine, die für horizontale Skalierbarkeit, maximale Zuverlässigkeit und eine einfachere Verwaltung entwickelt wurde.
- Kibana bringt Ihre Daten in Form und ist die erweiterbare Benutzeroberfläche zum Konfigurieren und Verwalten aller Aspekte des Elastic Stack.
- Beats sind einfache Shipper, die Daten von Edge-Maschinen an Logstash und Elasticsearch senden.
- Logstash ist eine dynamische Datenerfassungspipeline mit einem erweiterbaren Plug-in-System und starker Elasticsearch-Synergie.
- Elastic Cloud ist ein gehosteter und verwalteter Elasticsearch- und Kibana-Dienst, der in Google Cloud ausgeführt werden kann.
- ECK erweitert die grundlegenden Kubernetes-Orchestrierungsfunktionen für die Einrichtung und Verwaltung von Elasticsearch, Kibana und APM Server in Kubernetes.
- Google Kubernetes Engine (GKE) ist eine verwaltete Umgebung für das Deployment, die Verwaltung und die Skalierung von containerisierten Anwendungen in der Google-Infrastruktur. Die GKE-Umgebung besteht aus mehreren Maschinen (Compute Engine-Instanzen), die zusammen einen Cluster bilden.
Ziele
- Deployment von ECK auf GKE
- Beispieldaten in den ECK-Cluster laden
- Elastic Cloud bereitstellen
- Einen Snapshot erstellen und die Daten in Cloud Storage laden
- ECK-Instanz mit dem gespeicherten Snapshot wiederherstellen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Compute Engine
- GKE
- cl
- Elastic Cloud (siehe Google Cloud Marketplace)
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Aktivieren Sie in Cloud Shell die Compute Engine und GKE APIs:
gcloud services enable compute.googleapis.com \ container.googleapis.comMit diesen APIs werden die Rechenressourcen bereitgestellt, die zum Bereitstellen der für diese Anleitung erforderlichen GKE-Ressourcen erforderlich sind. Der Vorgang kann einige Minuten dauern. Wenn er abgeschlossen wurde, können Sie fortfahren.
Legen Sie die standardmäßige Compute-Zone für die Bereitstellung der Datenbank und der Rechenressourcen fest:
gcloud config set compute/zone us-central1-a export COMPUTE_ZONE=us-central1-aIn der Anleitung wird
us-central1-afür die Zone verwendet. Sie können die Funktion auch in einer Zone Ihrer Wahl bereitstellen. Weitere Informationen finden Sie unter Geografie und Regionen.
ECK in einem GKE-Cluster bereitstellen
In den folgenden Abschnitten richten Sie die erforderliche Infrastruktur und Software ein, um Elastic Cloud in Google Cloud auszuführen.
Dienstkonto zum Erstellen und Verwalten von GKE-Clustern bereitstellen
In diesem Abschnitt erstellen Sie ein Dienstkonto, mit dem Sie den GKE-Cluster im Rahmen dieser Anleitung erstellen und verwalten. Der Cluster ist eine VM-Instanz in Compute Engine, die das Compute Engine-Standarddienstkonto standardmäßig übernimmt. Dieses Dienstkonto hat mehr Berechtigungen als in der Anleitung erforderlich. Als Best Practice wird das Prinzip der geringsten Berechtigung beim Erstellen des Dienstkontos empfohlen.
In den folgenden Schritten erteilen Sie dem Dienstkonto die IAM-Rollen Monitoring-Betrachter (roles/monitoring.viewer), Monitoring-Messwert-Autor (roles/monitoring.metricWriter) und Logautor (roles/logging.logWriter). Sie erteilen ihm außerdem die Rolle „Compute-Administrator“ (roles/compute.admin). Diese Rolle ermöglicht eine vollständige Kontrolle aller Compute Engine-Ressourcen. In dieser Anleitung ist diese Rolle nicht erforderlich.
Wenn Sie jedoch dieses Dienstkonto weiterhin mit dem Cluster verwenden und Rechenknoten hinzufügen müssen, können Sie mit der Compute Admin-Rolle die zusätzlichen Rechenressourcen bereitstellen.
Legen Sie in Cloud Shell die Google Cloud-Projekt-ID als Variable fest und geben Sie den Namen des Dienstkontos an:
export PROJECT_ID=$(gcloud config get-value project 2> /dev/null) export SA_ID=eck-saErstellen Sie das Dienstkonto und eine neue Variable mit der E-Mail-Adresse des Dienstkontos:
gcloud iam service-accounts create $SA_ID --display-name=$SA_ID export GKE_SA_EMAIL=$(gcloud iam service-accounts list \ --filter=displayName:"$SA_ID" --format='value(email)')Es kann einen Moment dauern, bis die Metadaten synchronisiert werden. Bei der Synchronisierung wird die E-Mail-Adresse in der Variablen angezeigt. Bis dahin ist die Variable leer.
Prüfen Sie, ob für die lokale Umgebungsvariable die ID des Dienstkontos festgelegt wurde:
echo $GKE_SA_EMAILWenn die Ausgabe leer ist, führen Sie den vorherigen
export-Befehl noch einmal aus, bis die Variable angegeben wird. Wenn die Umgebungsvariable festgelegt ist, wird die Dienstkonto-ID angezeigt, die wie eine E-Mail-Adresse aussieht.Nachdem die Metadaten synchronisiert wurden, hängen Sie die Richtlinienbindungen an das Dienstkonto an:
gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/logging.logWriter gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/monitoring.metricWriter gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/monitoring.viewer gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/storage.admin gcloud projects add-iam-policy-binding $PROJECT_ID --member serviceAccount:$GKE_SA_EMAIL --role roles/compute.admin
GKE-Cluster erstellen
Im nächsten Schritt stellen Sie Ihren Cluster bereit. Mit dem folgenden Befehl erstellen Sie einen Cluster mit drei Knoten, wobei der Maschinentyp n1-standard-4 mit 256 GB nichtflüchtigem SSD-Speicher verwendet wird. Sie können diese Ressourcen ändern.
Stellen Sie den Cluster in Cloud Shell bereit:
gcloud container clusters create "eck-tutorial" \ --project $PROJECT_ID --zone $COMPUTE_ZONE \ --service-account $GKE_SA_EMAIL \ --no-enable-basic-auth --machine-type "n1-standard-4" \ --image-type "COS" --disk-type "pd-standard" \ --disk-size "256" --metadata disable-legacy-endpoints=true \ --num-nodes "3" \ --enable-ip-alias --no-issue-client-certificateRufen Sie die Anmeldedaten zur Authentifizierung ab, damit
kubectlmit Ihrem neuen Cluster interagieren kann:gcloud container clusters get-credentials eck-tutorial
Erste Schritte mit ECK
Im nächsten Schritt richten Sie ECK ein, damit es in der bereitgestellten Infrastruktur ausgeführt wird.
Elasticsearch-Operator bereitstellen
Das Muster des Kubernetes Operator ermöglicht benutzerdefinierte Ressourcen in Kubernetes. Der Elasticsearch-Operator verwendet dieses Muster, um Komponenten des Elastic Stack auf Kubernetes bereitzustellen.
Installieren Sie in Cloud Shell die benutzerdefinierten Ressourcendefinitionen (CRD):
kubectl apply -f https://download.elastic.co/downloads/eck/1.0.1/all-in-one.yamlOptional: Überwachen Sie die Operatorlogs:
watch kubectl -n elastic-system logs -f statefulset.apps/elastic-operatorIn der Regel ist ECK weniger als eine Minute nach der Installation der CRD bereit.
Secret für den Zugriff auf Cloud Storage generieren
Als Nächstes aktivieren Sie den neuen Elasticsearch-Cluster, um Snapshots in einem Cloud Storage-Bucket zu lesen und zu schreiben.
Generieren Sie in Cloud Shell einen Dienstkontoschlüssel und ein Kubernetes Secret:
gcloud iam service-accounts keys create ~/gcs.client.default.credentials_file \ --iam-account=$GKE_SA_EMAIL kubectl create secret generic gcs-credentials \ --from-file=gcs.client.default.credentials_fileErstellen Sie einen Cloud Storage-Bucket für die Snapshots und rufen Sie den Namen des Buckets auf:
export GCSBUCKET=$RANDOM-eck-gcs-snapshot && gsutil mb gs://$GCSBUCKETKopieren Sie den Namen des Buckets, da Sie ihn später benötigen.
Elastic Stack bereitstellen
Wenden Sie in Cloud Shell eine Beispiel-Clusterspezifikation an, die Server für Elasticsearch, Kibana und APM Server in Ihrem Cluster bereitstellt:
cat << 'EOF' > ~/eck.yaml apiVersion: elasticsearch.k8s.elastic.co/v1 kind: Elasticsearch metadata: name: quickstart spec: version: 7.6.1 secureSettings: - secretName: gcs-credentials nodeSets: - name: default count: 3 config: node.master: true node.data: true node.ingest: true node.store.allow_mmap: false podTemplate: spec: initContainers: - name: install-plugins command: - sh - -c - | bin/elasticsearch-plugin install --batch repository-gcs --- apiVersion: kibana.k8s.elastic.co/v1 kind: Kibana metadata: name: kibana-sample spec: version: 7.6.1 count: 1 elasticsearchRef: name: quickstart --- apiVersion: apm.k8s.elastic.co/v1 kind: ApmServer metadata: name: apm-server-sample spec: version: 7.6.1 count: 1 elasticsearchRef: name: quickstart EOF kubectl apply -f eck.yaml(Optional) Überwachen Sie den Status der Bereitstellung:
watch kubectl get elasticsearch,kibana,apmserverWenn die Statusanzeigen für die drei Dienste grün sind, wird der Cluster ausgeführt.
Load-Balancer erstellen und bei Kibana anmelden
Standardmäßig haben die Dienste im Cluster nur interne IP-Adressen und können nicht über das öffentliche Internet aufgerufen werden. Wenn Sie den Befehl kubectl get services ausführen, sehen Sie, dass alle Dienste eine interne IP-Adresse und keine externe IP-Adresse haben. Wenn Sie eine Verbindung zu Kibana über Ihren Webbrowser herstellen möchten, müssen Sie die Anwendung verfügbar machen. Dafür gibt es mehrere Möglichkeiten, die jeweils ihre eigenen Vor- und Nachteile haben. In dieser Anleitung erstellen Sie einen Load-Balancer.
Erstellen Sie den Load-Balancer in Cloud Shell:
kubectl expose deployment kibana-sample-kb \ --type=LoadBalancer \ --port 5601 \ --target-port 5601Dieser Load-Balancer nimmt Anfragen an Port
5601an. Dies ist der Standardport für den Kibana-Dienst.Suchen Sie nach einem neuen Load-Balancer-Dienst mit dem Namen
kibana-sample-kb:watch kubectl get servicesWarten Sie, bis die externe IP-Adresse bereitgestellt wurde.
Wenn die Adresse angezeigt wird, kopieren Sie die URL in die Variable
EXTERNAL_IPund fügen dann die gesamte URL in den Browser ein, um das Kibana-Portal zu laden:https://EXTERNAL_IP:5601
Wenn Sie Google Chrome verwenden, klicken Sie auf Erweitert und dann auf Trotzdem fortfahren.
Melden Sie sich mit dem
elastic-Nutzernamen im Portal an. Führen Sie in Cloud Shell den folgenden Befehl aus, um das Passwort zu ermitteln und eine Variable festzulegen:PASSWORD=$(kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode) && echo $PASSWORDWenn Sie dieses Passwort später ändern möchten, sollten Sie es an einem sicheren Ort speichern.
Beispieldaten laden und vorbereiten
Wenn Sie sich zum ersten Mal in Kibana anmelden, werden Sie aufgefordert, mit Beispieldaten zu starten.
Klicken Sie im Kibana-Portal auf Try our sample data:

Klicken Sie auf der Karte Sample Flight Data auf Add Data, um die Beispielflugdaten hinzuzufügen.
Sehen Sie sich das Dashboard und die Karte an, damit Sie sich mit den Beispielen vertraut machen.
Elasticsearch-Daten abfragen
Als Nächstes prüfen Sie, ob Sie die Elasticsearch-Daten abfragen können. Dazu leiten Sie zuerst Port 9200 (den Port, der vom Elasticsearch-Dienst überwacht wird) vom ECK-Cluster an Ihren lokalen Rechner weiter. Dann nehmen Sie Testabfragen für die Daten vor.
Aktivieren Sie in Cloud Shell die Portweiterleitung:
kubectl port-forward service/quickstart-es-http 9200Klicken Sie in der Menüleiste von Cloud Shell auf Neuen Tab öffnen. Eine zweite Cloud Shell-Sitzung wird gestartet.
Speichern Sie das Passwort des Elastic-Nutzers als lokale Variable:
PASSWORD=$(kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode)Testen Sie die Verbindung:
curl -u "elastic:$PASSWORD" -k "https://localhost:9200"Die Ausgabe sieht etwa so aus:
{ "name" : "quickstart-es-default-0", "cluster_name" : "quickstart", "cluster_uuid" : "ifdFjTixQ9q7sVc7uUpSnA", "version" : { "number" : "7.6.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b", "build_date" : "2020-02-29T00:15:25.529771Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }Zählen Sie die Anzahl der Dokumente in Ihrem Beispiel-Dataset:
curl -u "elastic:$PASSWORD" -k "https://localhost:9200/kibana_sample_data_flights/_count"Die Ausgabe sieht dann ungefähr so aus:
{"count":13059,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}Die Ausgabe gibt an, dass der Index 13.059 Dokumente enthält.
Schließen Sie die zweite Cloud Shell-Terminalsitzung, behalten Sie jedoch Ihre ursprüngliche Sitzung bei.
Drücken Sie in der ursprünglichen Cloud Shell-Sitzung Strg+C, um die Portweiterleitung zu beenden, da sie nicht mehr benötigt wird.
Snapshot-Registry registrieren
Damit Sie Snapshots erstellen und wiederherstellen können, müssen Sie ein Snapshot-Repository registrieren.
Klicken Sie im Kibana-Portal im Menü Elasticsearch auf Snapshot und Wiederherstellung und dann auf Repository registrieren:

Geben Sie auf der Seite Repository registrieren den Wert
examplerepoin das Feld Name ein, wählen Sie Google Cloud Storage als Repository-Typ aus und klicken Sie dann auf Weiter:
Geben Sie die folgenden Konfigurationsdetails ein:
- Geben Sie bei Client den Wert
defaultein. Geben Sie unter Bucket den Bucket-Namen ein, den Sie zuvor unter Secret für den Zugriff auf Cloud Storage generieren erstellt haben.
Wenn Sie den Namen des Buckets vergessen haben, gehen Sie so vor:
Listen Sie in Cloud Shell alle Buckets auf:
gsutil lsGehen Sie die Liste durch, um Ihren Bucket zu finden.
Geben Sie im Portal den Bucket-Namen ohne das Benennungsschema
gs://aus dem vorherigen Schritt ein. Wenn Ihr Bucket-URI beispielsweisegs://1234-eck-gcs-snapshotlautet, geben Sie1234-eck-gcs-snapshotein.
Lassen Sie die anderen Felder leer.
- Geben Sie bei Client den Wert
Klicken Sie auf Registrieren.
Klicken Sie im Detailbereich des Repositorys auf Repository überprüfen, um zu prüfen, ob eine Verbindung besteht. Das folgende Diagramm zeigt eine erfolgreiche Verbindung:

Erste Schritte mit Elastic Cloud
Jetzt können Sie einen gehosteten Cluster in Elastic Cloud einrichten und die Daten zu diesem neuen Cluster migrieren.
Cluster starten
Rufen Sie in Cloud Marketplace die Seite Elastic Cloud auf.
Wenn Sie mit den auf der Seite angezeigten Preisen einverstanden sind, klicken Sie auf Kaufen und dann auf Abonnieren.
Klicken Sie auf Aktivieren, um die APIs zu aktivieren. Sie werden zur Seite API und Dienste für den Elastic Cloud-Dienst weitergeleitet.
Klicken Sie auf Über Elastic verwalten:

Klicken Sie auf Bestätigen, um zu bestätigen, dass Sie zur Elastic Cloud-Website weitergeleitet werden sollen.
Füllen Sie das Formular aus, um Ihr Elastic Cloud-Konto zu registrieren. Ihr E-Mail-Konto wurde bestätigt.
Erstellen Sie ein Passwort, wenn Sie dazu aufgefordert werden, und melden Sie sich an.
Klicken Sie im Hauptportal für Elastic Cloud auf Deployment erstellen.
Gehen Sie so vor:
- Legen Sie für Ihren Cluster den Namen
example-ecfest. - Wählen Sie Google Cloud als Cloud-Plattform aus.
- Wählen Sie
us-central1als Region aus. - Behalten Sie bei allen anderen Optionen die Standardwerte bei.
- Legen Sie für Ihren Cluster den Namen
Klicken Sie auf Deployment erstellen.
Nach einigen Minuten wird der funktionsfähige Cluster in Elastic Cloud bereitgestellt und Sie werden automatisch zum Deployment-Dashboard für Ihre Instanz weitergeleitet.
Snapshot von ECK vorbereiten
Im nächsten Schritt erstellen Sie einen Snapshot Ihrer ECK-Instanz und migrieren ihn in Ihre Elastic Cloud-Instanz.
ECK-Snapshot erstellen
Zum Erstellen eines Snapshots müssen Sie im ECK-Cluster eine Snapshot-Richtlinie einrichten. Nachdem Sie einen einzelnen Snapshot erstellt haben, wird diese Richtlinie gelöscht, da sie nur für diese einmalige Migration erforderlich ist.
Melden Sie sich in einem Webbrowser im ECK-Cluster in Kibana an. Kopieren Sie dazu die externe IP-Adresse des Load-Balancers, den Sie zuvor in Ihrem GKE-Cluster erstellt haben.
Klicken Sie im Menü Elasticsearch auf Snapshot und Wiederherstellung:
Klicken Sie auf Richtlinie erstellen.
Geben Sie im Feld Richtlinienname den Namen
onetime-migrationein.Geben Sie im Feld Snapshotname
<onetime-migration-{now/d}>ein.Behalten Sie für alle anderen Einstellungen den Standardwert bei und klicken Sie auf Weiter:

Behalten Sie auf der Seite Snapshot-Einstellungen die Standardwerte bei und klicken Sie dann auf Weiter.
Wenn Sie zur Eingabe einer Aufbewahrungsrichtlinie für Snapshots aufgefordert werden, lassen Sie alle Felder leer und klicken Sie dann auf Weiter. Da Sie einen einmaligen Snapshot erstellen, ist keine Aufbewahrungsrichtlinie erforderlich.
Klicken Sie auf der Seite Richtlinie überprüfen auf Richtlinie erstellen.
Klicken Sie im Zusammenfassungsbereich der Richtlinie auf Schließen.
Klicken Sie auf der Übersichtsseite Snapshot und Wiederherstellung unter Aktionen auf Jetzt ausführen. Klicken Sie im neuen Fenster auf Richtlinie ausführen:

Klicken Sie zum Bestätigen des neuen Snapshots auf dem Tab Snapshots auf den mit Zeitstempel versehenen Snapshot, der mit
onetime-migrationbeginnt. Die Snapshot-Details werden angezeigt:
Snapshot-Richtlinie löschen
Da sich der Snapshot der ECK-Instanz nun in Cloud Storage befindet, können Sie die Snapshot-Richtlinie löschen.
- Klicken Sie im Kibana-Portal auf Verwaltung, dann auf Snapshot und Wiederherstellung und anschließend auf den Tab Richtlinien.
- Klicken Sie im Abschnitt Aktionen bei der Richtlinie zur einmaligen Migration auf Löschen.
- Klicken Sie auf Richtlinie löschen, um zu bestätigen, dass Sie die Richtlinie löschen möchten.
Das Löschen der Richtlinie wirkt sich nicht auf Snapshots aus, die Sie mit der Richtlinie erstellt haben. Es werden jedoch keine Snapshots mehr auf der Grundlage dieser Richtlinie erstellt.
Snapshot in Elastic Cloud verschieben
Im nächsten Schritt stellen Sie den neu erstellten Daten-Snapshot in Ihrer Instanz in Elastic Cloud wieder her.
Neues Dienstkonto erstellen und konfigurieren
Zuerst erstellen Sie ein Dienstkonto, das Elastic Cloud für den Zugriff auf Cloud Storage verwendet. Anschließend aktivieren Sie den Zugriff.
Erstellen Sie in der Cloud Shell das Dienstkonto:
gcloud iam service-accounts create ecloud-sa \ --display-name "Elasticcloud Service Account" export ec_sa=$(gcloud iam service-accounts list \ --filter=displayName:"Elasticcloud Service Account" \ --format='value(email)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$ec_sa --role roles/storage.admin gsutil iam ch serviceAccount:$ec_sa:roles/storage.admin gs://$GCSBUCKETErstellen Sie einen Schlüssel für dieses Dienstkonto und laden Sie ihn auf Ihren lokalen Clientcomputer herunter:
gcloud iam service-accounts keys create ~/ec-sa.json --iam-account $ec_saDie Ausgabe sieht etwa so aus:
created key [e44da1202f82f8f4bdd9d92bc412d1d8a837fa83] of type [json] as [/usr/home/username/ec-sa.json] for [ecloud-sa@project-id.iam.gserviceaccount.com]
Kopieren Sie den absoluten Pfad und den Dateinamen aus der Ausgabe. Sie werden benötigt, um die Datei herunterzuladen.
Klicken Sie auf Mehr und dann auf Datei herunterladen:

Geben Sie den absoluten Pfad und Dateinamen des Schlüssels ein, den Sie im vorherigen Schritt kopiert haben, und klicken Sie auf Herunterladen. Der JSON-Schlüssel wird auf Ihren lokalen Rechner heruntergeladen.
Klicken Sie auf der Seite „Elasticsearch Service“ bei der Bereitstellung in Elastic Cloud auf Sicherheit und dann auf Einstellungen hinzufügen:

Geben Sie unter Einstellungsname
gcs.client.default.credentials_fileein und wählen Sie dann JSON-Block/Datei aus.Öffnen Sie mit einem Texteditor auf Ihrem lokalen Rechner den heruntergeladenen JSON-Schlüssel, kopieren Sie den Text in das Feld Secret und klicken Sie dann auf Speichern. Der neue Eintrag wird im Schlüsselspeicher angezeigt.
Klicken Sie auf Passwort zurücksetzen, um ein neues Passwort für den Nutzer
elasticanzufordern, und notieren Sie es.Klicken Sie unter Sicherheitsänderungen in Kibana vornehmen auf Kibana.
Melden Sie sich mit diesen Anmeldedaten in Kibana an.
Wenn Sie dazu aufgefordert werden, klicken Sie auf Erkunden und laden Sie keine Beispieldaten.
Repository erstellen
Klicken Sie im Kibana-Portal auf das Menüsymbol () und dann auf Stack Management:

Klicken Sie unter Elasticsearch auf Snapshot und Wiederherstellung.
Klicken Sie auf den Tab Repositories und dann auf Repository registrieren:

Geben Sie als Repository-Namen
examplerepoein.Wählen Sie Google Cloud Storage aus.
Klicken Sie auf Next (Weiter).
Geben Sie im Feld Bucket den Bucket-Namen ein, den Sie zuvor unter Secret für den Zugriff auf Cloud Storage generieren erstellt haben.
Geben Sie den Bucket-Namen ohne das Benennungsschema
gs://ein. Wenn Ihr Bucket-URI beispielsweisegs://1234-eck-gcs-snapshotlautet, geben Sie1234-eck-gcs-snapshotein.Lassen Sie die anderen Felder leer und klicken Sie auf Registrieren.
Klicken Sie auf Repository überprüfen, um die Verbindung zu prüfen.
Klicken Sie auf Schließen.
Snapshot wiederherstellen
Klicken Sie im Kibana-Portal auf den Tab Snapshots und wählen Sie dann im Drop-down-Menü Repository die Option
examplerepoaus: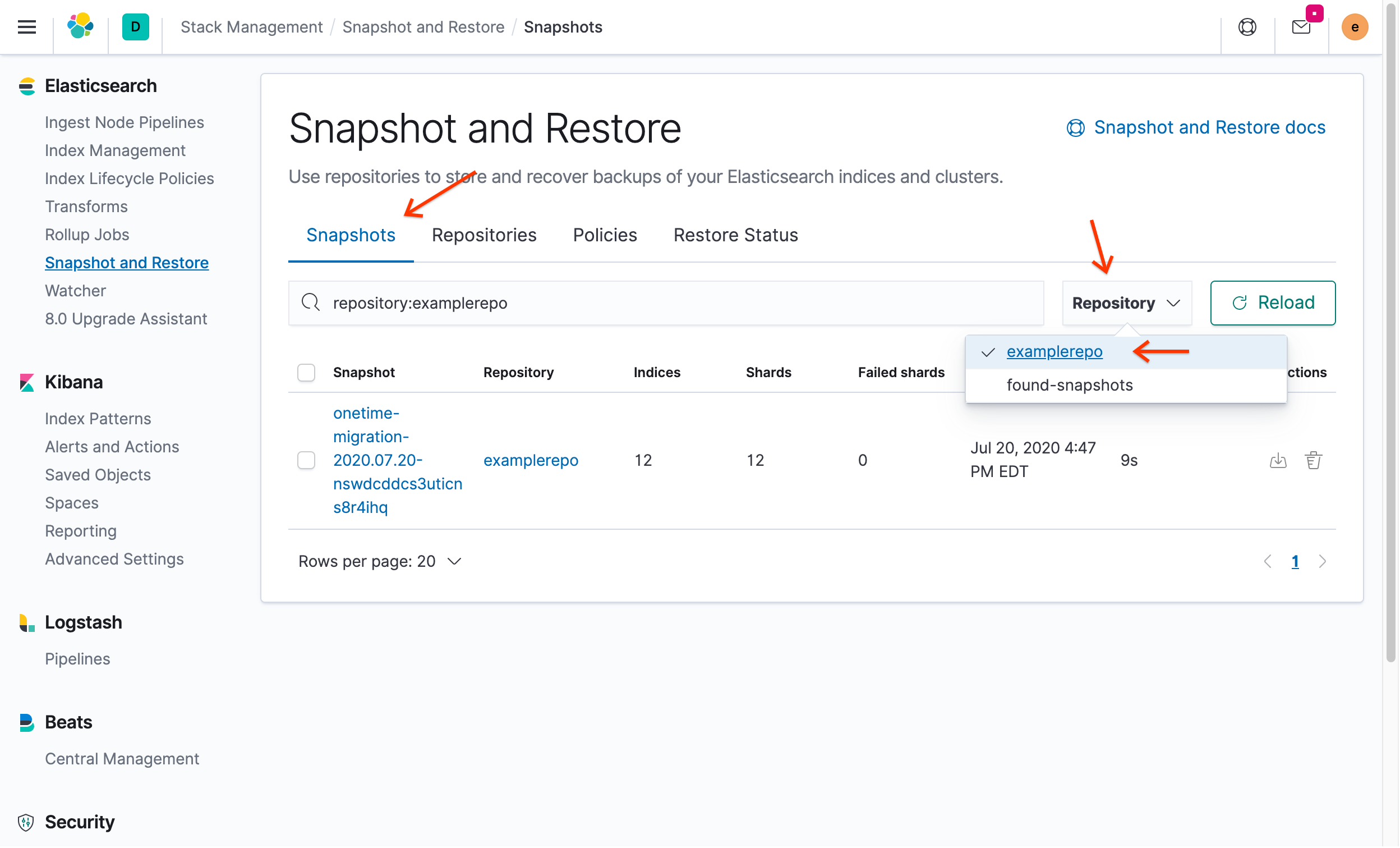
Sie sehen den Snapshot, den Sie zuvor in ECK erstellt haben.
Klicken Sie unter Aktionen auf Wiederherstellen.
Deaktivieren Sie die Option Alle Indexe, einschließlich Systemindexe:

Klicken Sie auf Auswahl aufheben und wählen Sie dann kibana_sample_data_flights, ilm-history-1-000001 und alle Indexe mit das Präfix apm- aus. Wählen Sie keinen Index aus, der einen Punkt vor seinem Namen hat, da es sich um einen Systemindex handelt.
Wenn Sie versuchen, die Standardeinstellungen wiederherzustellen, erhalten Sie eine Fehlermeldung ähnlich der folgenden:
[snapshot_restore_exception] [examplerepo:onetime-migration2020.07.07-mt2pg1p7sb2sci9fs-yxlw/7OdEOWYVRQyIh9S2NaPypQ] cannot restore index [.security-7] because an open index with same name already exists in the cluster. Either close or delete the existing index or restore the index under a different name by providing a rename pattern and replacement name
Dieser Fehler tritt auf, weil Indexe nicht indexiert werden können und sollten. Wenn Sie der Anleitung folgen, funktioniert Kibana möglicherweise nicht mehr richtig. Das Schließen oder Löschen eines vorhandenen offenen Indexes ist nur bei Nicht-Systemindexen möglich.
Behalten Sie in allen anderen Feldern die Standardwerte bei und klicken Sie auf Weiter.
Übernehmen Sie im Menü Indexeinstellungen alle Standardeinstellungen und klicken Sie dann auf Weiter.
Klicken Sie auf der Seite Details wiederherstellen auf Snapshot wiederherstellen.
Nach Abschluss der Wiederherstellung wird das Dashboard Status wiederherstellen angezeigt. Hier sehen Sie, dass Ihre Daten wiederhergestellt wurden.
Klicken Sie unter Kibana auf Indexmuster, um den Index wiederherzustellen.
Klicken Sie auf Indexmuster erstellen.
Es werden einige verfügbare Indexe angezeigt. Suchen Sie den Index kibana_sample_data_flights, den ECK automatisch erstellt hat.
Geben Sie
kibin das Feld Indexmuster ein. Beachten Sie, dasskibana_sample_data_flightsmit dem Muster übereinstimmt.Klicken Sie auf Next step (Nächster Schritt).
Wählen Sie im Drop-down-Menü Feldname des Zeitraumfilters die Option Zeitstempel aus.
Klicken Sie auf Indexmuster erstellen.
(Optional) Wenn Sie auf Entdecken klicken, sehen Sie die Rohdaten so wie zuvor in der ECK-Umgebung.
Scrollen Sie im Hauptmenü bis zum Ende des Menüs und klicken Sie unter Verwaltung auf Entwicklertools.
Geben Sie links
GET /kibana_sample_data_flights/_countein und klicken Sie auf „Anfrage senden“. Die Ausgabe zeigt, dass 13.059 Dokumente gezählt wurden, was der Anzahl der im ECK-Index gefundenen Dokumente entspricht.
Bereinigen
Wenn Sie vermeiden möchten, dass Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden, können Sie das dafür erstellte Google Cloud-Projekt löschen.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Elasticsearch in Elastic Cloud mit Google Cloud auf dem Cloud Marketplace einrichten
- Best Practices für Kubernetes im Google Cloud-Blog
- Anleitungen für die ersten Schritte mit GKE
- Referenzarchitekturen, Diagramme, Anleitungen und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center