Introdução
Este documento explica como pesquisadores, cientistas de dados, equipes de TI ou organizações de saúde e ciências da vida podem usar a API Cloud Healthcare para remover informações de identificação pessoal (PII, na sigla em inglês) e informações protegidas de saúde (PHI) dos dados de imagens e comunicações digitais em medicina (DICOM). Esse processo, conhecido como desidentificação, garante a privacidade do paciente e prepara dados DICOM para uso em pesquisa, compartilhamento de dados e aprendizado de máquina.
O tutorial complementar, Como usar a API Cloud Healthcare para desidentificar imagens médicas, orienta você em dois casos de uso de desidentificação de dados de imagens médicas usando a API Cloud Healthcare.
Como funciona a desidentificação de dados de DICOM
As imagens médicas adquiridas para fins médicos podem ter importantes usos secundários em projetos de pesquisa e bibliotecas de ensino. No entanto, talvez seja necessário remover ou modificar elementos de dados confidenciais (PII ou PHI) das imagens DICOM antes de analisá-las ou compartilhá-las com colaboradores autorizados.
O diagrama a seguir mostra vários pipelines de imagens médicas de fontes locais que são roteadas para o Google Cloud e anonimizados pela operação de desidentificação da API Cloud Healthcare.

Primeiro, faça o upload das imagens médicas formatadas em DICOM para o Cloud Storage e, em seguida, para a API Cloud Healthcare. Como alternativa, faça upload das imagens DICOM diretamente para a API Cloud Healthcare. As imagens médicas, que são mantidas em um armazenamento DICOM na API Cloud Healthcare, são roteadas por meio do processo de desidentificação da API Cloud Healthcare para anonimizar as imagens e os metadados associados.
Por exemplo, como pesquisador médico, você tem acesso a imagens de raio-x de fraturas espinhais de pacientes em um sistema de comunicação e arquivamento de imagem (PACS, na sigla em inglês) local. É possível mover os dados de pixel de imagem para o Cloud Storage usando o Serviço de transferência do Cloud Storage, o Transfer Appliance ou um dos produtos de conectividade híbrida. Em seguida, copie ou mova os dados do Cloud Storage para a API Cloud Healthcare. Depois que os dados estiverem na API Cloud Healthcare, você poderá usá-los como backup, visualizá-los remotamente ou permitir que eles sejam acessados por serviços e aplicativos de nuvem aprovados de terceiros.
Em outro cenário, envie imagens DICOM desidentificadas ao AutoML Vision para treinar um modelo para ajudar as equipes de saúde a detectar fraturas de coluna nos raios-x. Dessa forma, você cria uma ferramenta de suporte a decisões médicas usando seus próprios dados.
API Cloud Healthcare
A API Cloud Healthcare oferece uma solução gerenciada para armazenar e acessar dados de saúde no Google Cloud, fornecendo uma ponte crítica entre sistemas de atendimento e aplicativos hospedados no Google Cloud.
Em um projeto do Google Cloud, os dados ingeridos por meio da API Cloud Healthcare são armazenados em um conjunto de dados que reside em uma localização geográfica correspondente a uma região do Google Cloud. A API Cloud Healthcare é compatível com as regiões listadas em Regiões. Para ver uma lista de produtos do Google Cloud e as regiões em que são implementados, consulte Locais do Cloud.
Como cada modalidade de dados de saúde, por exemplo, DICOM, Recursos rápidos de interoperabilidade de saúde (FHIR, na sigla em inglês) e HL7v2, tem características estruturais e de processamento diferentes, os conjuntos de dados são divididos em armazenamentos específicos por modalidade.
O diagrama a seguir mostra como a API Cloud Healthcare organiza dados médicos por local, conjunto de dados e armazenamento.

Cada conjunto de dados contém um ou mais armazenamentos que atendem à mesma modalidade ou a diferentes modalidades, conforme necessário pelo aplicativo. Usar vários armazenamentos no mesmo conjunto de dados pode ser apropriado se um aplicativo processar diferentes tipos de dados. Por exemplo, separe os dados de acordo com o hospital, a consulta ou o departamento de origem. Um aplicativo pode acessar quantos conjuntos de dados ou armazenamentos forem necessários sem prejudicar o desempenho. É importante projetar o conjunto de dados geral e a arquitetura de armazenamento para atender às metas amplas da sua organização, como proximidade para calcular recursos ou usuários finais, particionamento ou controle de acesso.
O diagrama a seguir mostra dois conjuntos de dados que contêm armazenamentos HL7v2, DICOM e FHIR.
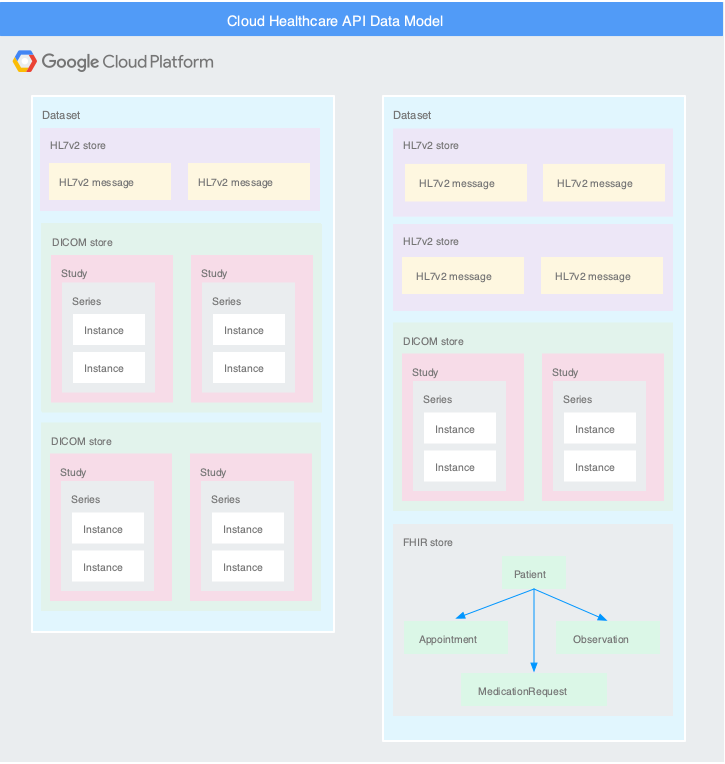
É possível copiar imagens DICOM para um armazenamento DICOM ou armazená-las dentro de um conjunto de dados de várias fontes. Para mais informações, consulte Como criar e gerenciar armazenamentos DICOM.
Como desidentificar os dados DICOM
A API Cloud Healthcare inclui ferramentas de desidentificação que podem editar (remover) ou modificar de modo escalonável o conteúdo confidencial de texto e imagens, com base na configuração especificada.
Essas ferramentas operam em textos e imagens codificados em formatos de registros médicos específicos, como DICOM e FHIR. Quando você trabalha com instâncias DICOM, os componentes de uma chamada de API de desidentificação são os seguintes:
- Origem: um conjunto de dados ou armazenamento DICOM que contém uma ou mais instâncias DICOM com dados confidenciais. O tutorial complementar usa um conjunto de dados, mas você pode modificar os exemplos para trabalhar em um único armazenamento DICOM.
- O que desidentificar: parâmetros de configuração que especificam como processar o conjunto de dados. É possível configurar a operação do DICOM para desidentificar os metadados da instância DICOM usando palavras-chave de tag, ofuscando o texto gravado em imagens DICOM ou ambos.
- Destino: a desidentificação não afeta o conjunto de dados original nem os dados dele. Em vez disso, as cópias processadas dos dados originais são gravadas em um novo conjunto de dados ou armazenamento DICOM, chamado de destino. O tutorial complementar usa um conjunto de dados, mas você pode modificar os exemplos para trabalhar em um armazenamento DICOM.
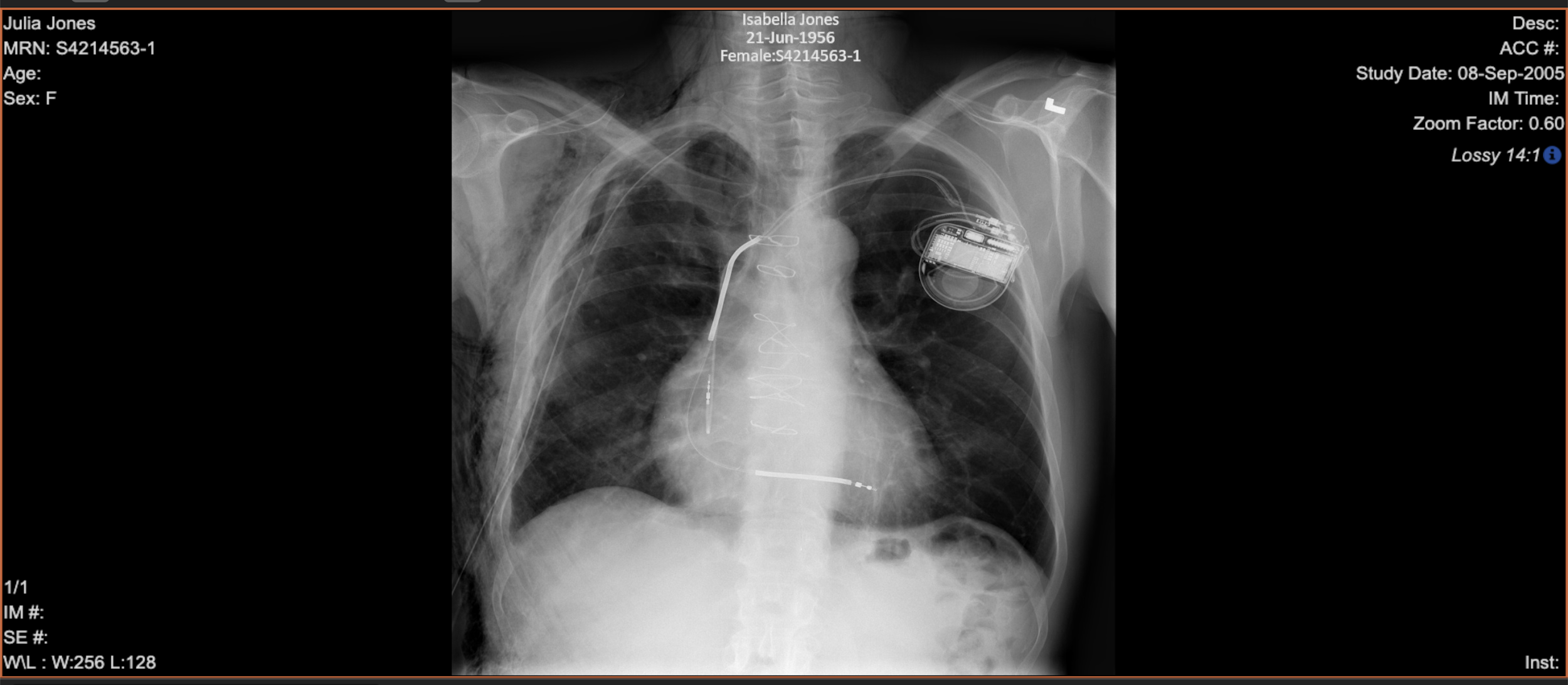
As duas imagens a seguir mostram um exemplo de imagem de raio-x antes e depois da desidentificação, em que o objetivo é remover ou modificar todos os metadados e o texto gravado associado à imagem.
A primeira imagem mostra uma imagem de raio-x com dados PII e PHI de amostra que aparecem nos metadados e no texto gravado.
A segunda imagem mostra a mesma imagem de raio-x com todos os metadados PII e PHI de amostra removidos ou ocultos.
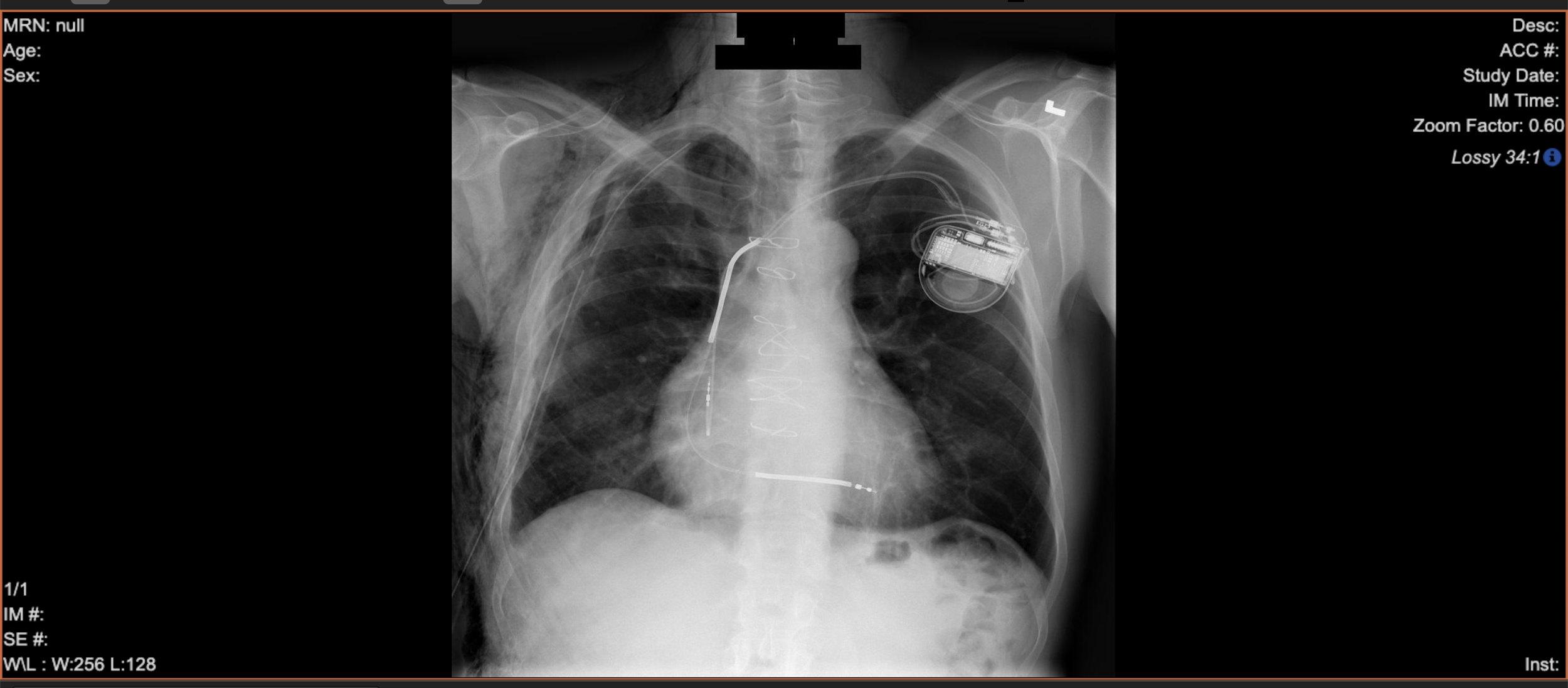
Após a desidentificação, todos os metadados da imagem são removidos, e todo o texto gravado na imagem é oculto com um retângulo opaco. Essa configuração de desidentificação é útil quando você precisa apenas dos dados de pixel de imagem para análise adicional, treinamento do modelo de aprendizado de máquina (ML) ou inferência.
Por exemplo, talvez você queira treinar um modelo de classificação de imagem para determinar se há uma fratura presente em um raio-x. Para treinar esse modelo, você precisa de um grande número de amostras de imagem, algumas com fraturas e outras sem. No entanto, você não precisará de informações confidenciais, como gênero, idade ou data de nascimento do paciente, porque essas informações não são relevantes para o modelo.
Ou convém analisar a progressão de uma determinada doença em uma população de pacientes à medida que os pacientes envelhecem. Nesse caso, você precisa saber informações como a idade e o gênero do paciente, além da data de cada estudo, porque essas informações são relevantes para a análise médica. Você tem a opção de manter alguns dos metadados e editar outras informações identificáveis sobre os pacientes, como os nomes e os registros médicos.
A prática recomendada é alterar as datas em qualquer estudo para que os cronogramas relativos sejam mantidos, mas a combinação com um paciente seja quase impossível. Para mais informações, consulte mudança de data.
Acesso necessário e papéis de gerenciamento de identidade e acesso
No Google Cloud, o acesso aos recursos é gerenciado por meio dos papéis do gerenciamento de identidade e acesso (IAM, na sigla em inglês). O acesso à API Cloud Healthcare requer que sua conta (IAM) tenha os papéis apropriados para a função que você quer executar.
É possível usar uma conta de usuário (a que você usa para acessar o console do Google Cloud) ou uma conta de serviço do IAM. O tutorial complementar usa uma conta de serviço, exceto para a visualização de imagens médicas, para a qual você precisa usar uma conta de usuário. As informações gerais apresentadas aqui se aplicam a todos os tipos de conta.
Para criar o conjunto de dados de destino, você precisa ter pelo menos a permissão healthcare.datasets.deidentify no conjunto de dados de origem e a permissão healthcare.datasets.create no projeto do Google Cloud. O
papel de IAM de administrador do conjunto de dados do Healthcare inclui essas
duas permissões.
Para informações sobre como controlar o acesso a conjuntos de dados e armazenamentos DICOM, consulte Como controlar o acesso aos recursos da API Cloud Healthcare. Para informações sobre as permissões necessárias para métodos de conjunto de dados, consulte Controle de acesso ou a API Cloud Healthcare.
Visualizadores de imagens médicas
Os seguintes visualizadores DICOM são integrados à API Cloud Healthcare, e você pode usá-los para visualizar imagens antes e depois da desidentificação:
Para que o visualizador funcione corretamente, suas credenciais de login precisam ter o papel healthcare.dicomViewer.
Estrutura da API
É possível acessar e gerenciar dados em conjuntos de dados e armazenamentos da API Cloud Healthcare usando uma API REST que identifica cada armazenamento pelo projeto, local, conjunto de dados, tipo e nome na nuvem. A API Cloud Healthcare implementa padrões específicos da modalidade para cada tipo de acesso, que são consistentes com os padrões do setor para cada uma delas. Por exemplo, a API Cloud Healthcare fornece operações nativas para ler estudos e séries DICOM que sejam consistentes com o padrão DICOMweb.
As operações que acessam um armazenamento específico por modalidade usam um caminho de solicitação que consiste em um caminho base e um caminho de solicitação específico. As operações administrativas, que geralmente operam apenas em locais, conjuntos de dados e armazenamentos de dados, podem usar apenas o caminho base.
Para fazer referência a um armazenamento específico em um conjunto de dados da API Cloud Healthcare, use um caminho base estruturado assim:
/projects/project/locations/location/datasets/dataset/store-type/store-name
Substitua:
project: seu projeto do Google Cloud.location: a zona em que seus recursos estão localizadosdataset: o nome do conjunto de dadosstore-type: o tipo de armazenamento de dadosstore-name: o nome do seu armazenamento de dados
Veja a seguir um exemplo de caminho base:
/projects/MyProj/locations/us-central1/datasets/dataset1/dicomStores/dicomstore1
O exemplo de caminho anterior faz referência a um armazenamento DICOM da API Cloud Healthcare no projeto MyProj do Google Cloud, na região US-central, em um conjunto de dados chamado dataset1 e com o nome dicomstore1.
Para acessar um dado, você combina o caminho base com um caminho de solicitação formatado de acordo com o padrão da modalidade apropriado. Por exemplo, as solicitações DICOMweb para um armazenamento DICOM podem ter esta aparência:
base-path/dicomWeb/studies/{study_id}/series?PatientName={patient_name}
A parte base-path do caminho representa um caminho base específico para essa solicitação. A parte {study_id} do caminho identifica um estudo DICOM específico, e o nome do paciente é especificado por {patient_name}.
No exemplo anterior, a especificação do caminho é consistente com a estrutura de caminho padrão do DICOMweb.
Desidentificação usando tags e configuração de edição de imagem
A desidentificação de dados DICOM inclui dois processos:
- Como desidentificar metadados DICOM
- Como editar texto gravado em imagens
Na API Cloud Healthcare, a desidentificação de metadados é baseada em tags DICOM, e a edição de texto gravado é realizada por meio da opção TextRedactionMode.
Como usar tags e perfis para desidentificação
É possível desidentificar instâncias DICOM com base em palavras-chave de tag nos metadados DICOM. Os seguintes métodos de filtragem de tags estão disponíveis no objeto DicomConfig:
keepList: uma lista de tags a serem mantidas. Remove todas as outras tags.removeList: uma lista de tags a serem removidas. Mantém todas as outras tags.TagFilterProfile: um perfil de filtragem de tags que especifica quais tags manter ou remover.
Tags de atributo mínimo de DICOM
As seguintes tags são os atributos mínimos de uma instância DICOM válida na API Cloud Healthcare:
StudyInstanceUIDSeriesInstanceUIDSOPInstanceUIDTransferSyntaxUIDMediaStorageSOPInstanceUIDMediaStorageSOPClassUIDPixelDataRowsColumnsSamplesPerPixelBitsAllocatedBitsStoredHighbitPhotometricInterpretationPixelRepresentationNumberOfFrames
keepList
Para usar o método de filtragem de tags keepList, é necessário fornecer uma lista de nomes de tags. Essas tags são as únicas retidas nos recursos desidentificados. Quando você especifica uma tag keeplist no objeto DicomConfig, as tags de atributo mínimo DICOM são adicionadas por padrão.
Se nenhuma tag keeplist for fornecida, nenhuma tag DICOM no conjunto de dados será removida. Geralmente, quando uma tag é mantida, ela aparece como inalterada na saída em comparação com a original. No entanto, as tags StudyInstanceUID, SeriesInstanceUID, SOPInstanceUID e MediaStorageSOPInstanceUID são geradas novamente com valores novos e exclusivos na saída.
removeList
Especifique uma tag removeList no objeto DicomConfig. A operação de desidentificação remove somente as tags especificadas na lista. Se nenhuma tag removeList for fornecida, a operação de desidentificação continuará normalmente, mas nenhuma tag DICOM no conjunto de dados de destino será editada.
As tags de atributo mínimo DICOM não podem ser adicionadas a uma removeList.
TagFilterProfile
Em vez de especificar quais tags manter ou remover, use o perfil TagFilterProfile. Esse perfil predefinido determina como as tags são tratadas e modificadas. Por exemplo, o perfil MINIMAL_KEEP_LIST_PROFILE mantém apenas as tags necessárias para produzir recursos DICOM válidos e remove todas as outras tags. Para mais informações, consulte a documentação TagFilterProfile.
Recomendamos o perfil TagFilterProfile como um método de filtragem de tags, especialmente para usuários não técnicos, porque o perfil pré-selecionado significa que não há necessidade de analisar e entender todas as tags DICOM e seus conteúdos.
Perfis usados com frequência
Realize um dos casos de uso de desidentificação comuns do setor, removendo tags com base nos perfis de confidencialidade do atributo padrão DICOM, usando o perfil ATTRIBUTE_CONFIDENTIALITY_BASIC_PROFILE.
Outro perfil usado com frequência é DEIDENTIFY_TAG_CONTENTS, que inspeciona metadados no conteúdo da tag e substitui o texto confidencial. Ao usar o perfil DEIDENTIFY_TAG_CONTENTS, você também pode aplicar configurações como tipos de informações e transformações primitivas. Tipos de informações e transformações primitivas não podem ser aplicados aos outros perfis.
Use tipos de informações para definir quais dados são verificados ao realizar a desidentificação com tags. Um tipo de informação é um tipo de dado confidencial, como nome, endereço de e-mail, número de telefone, número de identificação ou número de cartão de crédito do paciente. Para mais informações, consulte detectores InfoTypes e infoType.
As transformações primitivas são regras usadas para transformar um valor de entrada. Personalize como as tags DICOM são desidentificadas aplicando uma transformação primitiva a cada tipo de informação da tag. Por exemplo, desidentifique o sobrenome de um paciente e substitua-o por uma série de asteriscos. Para informações sobre transformações primitivas, consulte opções de transformação primitiva.
O tutorial complementar fornece um caso de uso para o perfil MINIMAL_KEEP_LIST_PROFILE.
Tipos de informações padrão
Por padrão, o perfil DEIDENTIFY_TAG_CONTENTS lida com os seguintes tipos de informações:
AGECREDIT_CARD_NUMBERDATEEMAIL_ADDRESSIP_ADDRESSLOCATIONMAC_ADDRESSPERSON_NAMEPHONE_NUMBERSWIFT_CODEUS_DRIVERS_LICENSE_NUMBERUS_PASSPORTUS_SOCIAL_SECURITY_NUMBERUS_VEHICLE_IDENTIFICATION_NUMBERUS_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER
Se você precisar modificar apenas os tipos de informações na lista anterior, poderá usar o perfil DEIDENTIFY_TAG_CONTENTS sem parâmetros adicionais.
Como editar texto gravado em imagens
A API Cloud Healthcare pode editar textos confidenciais gravados em imagens. Os dados confidenciais, como PII ou PHI, são detectados pela API Cloud Healthcare, que os oculta com um retângulo opaco. A API Cloud Healthcare retorna as mesmas imagens DICOM da entrada, mas qualquer texto identificado como contendo informações confidenciais, de acordo com seus critérios, é editado.
É possível editar texto gravado em imagens ao especificar uma opção TextRedactionMode dentro de um objeto ImageConfig.
REDACT_ALL_TEXT: edita todo o texto gravado de imagens DICOM em um conjunto de dados.REDACT_SENSITIVE_TEXT: edita texto gravado confidencial de imagens DICOM em um conjunto de dados.
Ao especificar REDACT_SENSITIVE_TEXT, você edita default infoTypes e custom infoType como identificadores de pacientes. Informações como números de registros médicos (MRNs) são editadas a partir de imagens.
Para mais informações sobre a configuração da edição de imagens, consulte Como editar texto gravado de imagens.
A seguir
- Como usar a API Cloud Healthcare para desidentificar imagens médicas
- Introdução à API Cloud Healthcare, parte 1
- Introdução à API Cloud Healthcare, parte 2
- Introdução à API Cloud Healthcare, parte 3
- Anúncio da API Cloud Healthcare Beta
- Para mais informações sobre os recursos do DICOM, consulte a declaração de conformidade do DICOM
Para mais informações sobre a API Cloud Healthcare, incluindo informações sobre suporte para FHIR e HL7v2, consulte a documentação da API Cloud Healthcare
Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.