Este artigo é a última parte de uma série de quatro partes em que explicamos como prever o valor de vida útil do cliente (CLV, na sigla em inglês) usando o AI Platform no Google Cloud. Neste artigo, mostramos como usar o AutoML Tables para realizar as previsões.
Os artigos desta série incluem:
- Parte 1: Introdução. Apresenta o conceito de CLV e duas técnicas de modelagem para prevê-lo.
- Parte 2: como treinar o modelo, aborda como preparar os dados e treinar os modelos.
- Parte 3: Como implantar na produção. Descreve como implantar os modelos discutidos na parte 2 em um sistema de produção.
- Parte 4: Como usar o AutoML Tables (este artigo). Mostra como usar o AutoML Tables para criar e implantar um modelo.
O processo descrito neste artigo depende dos mesmos passos de processamento de dados no BigQuery descritas na parte 2 da série. Neste artigo, mostramos como fazer o upload desse conjunto de dados do BigQuery para o AutoML Tables e criar um modelo. Também mostramos como integrar o modelo do AutoML ao sistema de produção descrito na parte 3.
O código para implementar este sistema está no mesmo repositório do GitHub que a série original. Este artigo discute como usar o código para o AutoML Tables nesse repositório.
Vantagens do AutoML Tables
Nas partes anteriores da série, você viu como prever o CLV usando um modelo estatístico e um modelo DNN implementado no TensorFlow. O AutoML Tables tem várias vantagens sobre os outros dois métodos:
- Nenhuma codificação é necessária para criar o modelo. Há uma IU de console que permite criar, treinar, gerenciar e implantar conjuntos de dados e modelos.
- Adicionar ou alterar recursos é fácil e pode ser feito diretamente na interface do console.
- O processo de treinamento é automatizado, incluindo o ajuste de hiperparâmetro.
- O AutoML Tables procura a melhor arquitetura para o conjunto de dados, aliviando a necessidade de escolher entre as muitas opções disponíveis.
- O AutoML Tables fornece uma análise detalhada do desempenho de um modelo treinado, incluindo a importância do recurso.
Como resultado, pode levar menos tempo e custar menos para desenvolver e treinar um modelo totalmente otimizado usando o AutoML Tables.
Uma implantação de produção de uma solução do AutoML Tables requer que você use a API do cliente Python para criar e implantar modelos e executar previsões. Neste artigo, mostramos como criar e treinar modelos do AutoML Tables usando a API do cliente. Para orientações sobre como executar essas etapas usando o console do AutoML Tables, consulte a documentação do AutoML Tables.
Como instalar o código
Se você não instalou o código da série original, siga os mesmos passos descritos na parte 2 da série original para instalar o código. O arquivo README no repositório do GitHub descreve todas as etapas necessárias para preparar o ambiente, instalar o código e configurar o AutoML Tables em seu projeto.
Se você já tiver instalado o código, execute estes passos extras para concluir a instalação para este artigo:
- Ative a API AutoML Tables em seu projeto.
- Ative o ambiente do miniconda instalado anteriormente.
- Instale a biblioteca de cliente Python conforme descrito na documentação do AutoML Tables.
- Crie e faça o download de um arquivo de chave de API e salve-o em um local conhecido para uso posterior com a biblioteca de cliente.
Como executar o código
Para muitos dos passos deste artigo, você executa comandos em Python. Depois de preparar seu ambiente e instalar o código, você tem as opções a seguir para executar o código:
Execute o código em um notebook do Jupyter. Na janela de terminal no ambiente do miniconda ativado, execute o comando a seguir:
$ (clv) jupyter notebookO código para cada uma das etapas neste artigo está em um bloco de notas no repositório de código chamado
notebooks/clv_automl.ipynb. Abra esse bloco de notas na interface do Jupyter. É possível, então, executar cada um dos passos conforme segue o tutorial.Execute o código como um script Python. As etapas de código deste tutorial estão no repositório de código no arquivo
clv_automl/clv_automl.py. O script usa argumentos na linha de comando para parâmetros configuráveis, como o ID do projeto, o local do arquivo de chave de API, a região do Google Cloud e o nome do conjunto de dados do BigQuery. Execute o script na janela de terminal no ambiente do miniconda ativado, substituindo[YOUR_PROJECT]pelo nome do projeto do Google Cloud:$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
Para ver a lista completa de parâmetros e valores padrão, consulte o método
create_parserno script ou execute o script sem argumentos para ver a documentação de uso.Depois de instalar o ambiente do Cloud Composer conforme descrito no README (em inglês), execute o código executando os DAGs, conforme descrito mais adiante em Como executar os DAGs.
Como preparar os dados
Este artigo usa os mesmos passos do conjunto de dados e da preparação de dados no BigQuery descritos na parte 2 da série original. Depois de concluir a agregação dos dados, conforme descrito neste artigo, você estará pronto para criar um conjunto de dados para uso com o AutoML Tables.
Como criar o conjunto de dados do AutoML Tables
Para começar, faça o upload dos dados que você preparou no BigQuery para o AutoML Tables.
Para inicializar o cliente, configure o nome do arquivo de chave para o nome do arquivo que você fez o download no passo de instalação:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Crie o conjunto de dados:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Como importar os dados do BigQuery
Depois de criar o conjunto de dados, importe os dados do BigQuery.
Importe os dados do BigQuery para o conjunto de dados do AutoML Tables:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Como treinar o modelo
Depois de criar o conjunto de dados do AutoML para os dados de CLV, crie o modelo do AutoML Tables.
Veja as especificações de coluna do AutoML Tables para cada coluna no conjunto de dados:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}As especificações de coluna são necessárias em passos posteriores.
Atribua uma das colunas como o rótulo para o modelo do AutoML Tables:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)Esse código usa a mesma coluna de rótulo (
target_monetary) que o modelo de DNN do TensorFlow na parte 2.Defina os recursos para treinar o modelo:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')Os recursos usados para treinar o modelo do AutoML Tables são os mesmos usados para treinar o modelo de DNN do TensorFlow na parte 2 da série original. No entanto, adicionar ou subtrair recursos do modelo é muito mais fácil com o AutoML Tables. Depois que um recurso é criado no BigQuery, ele é incluído automaticamente no modelo, a menos que você o remova explicitamente, conforme mostrado no snippet de código anterior.
Defina as opções para criar o modelo. O objetivo de otimização da minimização do erro absoluto médio, representado pelo parâmetro
MINIMIZE_MAE, é recomendado para este conjunto de dados.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }Para mais informações, consulte a documentação do AutoML Tables sobre os objetivos da otimização.
Crie o modelo e comece o treinamento:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameO valor de retorno da chamada do cliente (
create_model_response) é retornado imediatamente. O valorcreate_model_response.result()é uma promessa, que fica bloqueada até que o treinamento seja concluído. O valormodel_nameé um caminho de recurso necessário para outras chamadas de clientes que operam no modelo.
Como avaliar o modelo
Depois que o treinamento de modelo estiver concluído, será possível recuperar as estatísticas de avaliação do modelo. Use o Console do Google Cloud ou a API do cliente.
Para usar o console, no console do AutoML Tables, acesse a guia Avaliar:

Para usar a API do cliente, recupere as estatísticas de avaliação do modelo:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]Você vê uma saída semelhante a esta:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
A raiz do erro médio quadrado de 853.481 compara-se favoravelmente aos modelos probabilísticos e de TensorFlow usados na série original. No entanto, conforme discutido na parte 2, é aconselhável testar cada uma das técnicas fornecidas com seus dados para ver qual apresenta o melhor desempenho.
Como implantar o modelo do AutoML
Os DAGs do Cloud Composer da série original foram atualizados para incluir o modelo do AutoML Tables para treinamento e predição. Para informações gerais sobre o funcionamento dos DAGs do Cloud Composer, consulte a seção sobre como automatizar a solução na parte 3 dos artigos originais.
É possível instalar o sistema de orquestração do Cloud Composer para essa solução seguindo as instruções no README.
Os DAGs atualizados chamam métodos no script clv_automl/clv_automl.py que replicam as chamadas de código do cliente mostradas anteriormente para criar o modelo e executar previsões.
O DAG de treinamento
O DAG atualizado para treinamento inclui tarefas para criar um modelo do AutoML Tables. O diagrama a seguir mostra o novo DAG para treinamento.

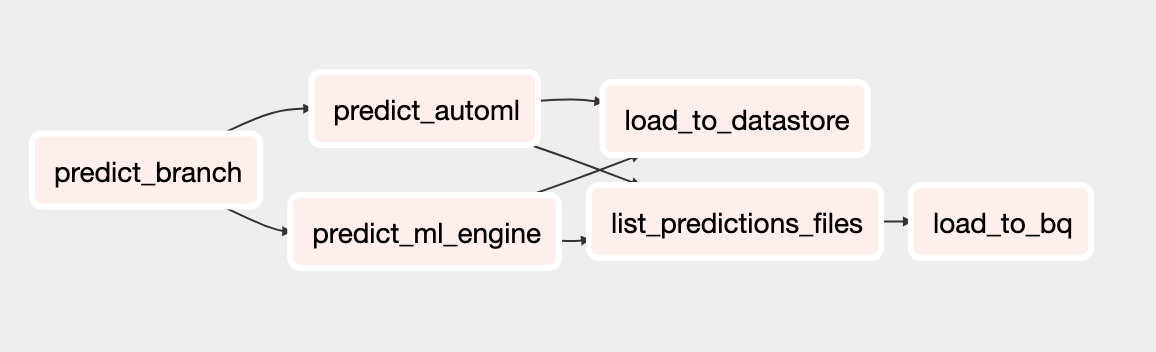
O DAG de previsão
O DAG atualizado para predição inclui tarefas para executar predições em lote com o modelo do AutoML Tables. O diagrama a seguir mostra o novo DAG para previsões.
Como executar os DAGs
Para acionar os DAGs manualmente, execute os comandos na seção Executar DAGs do arquivo README no Cloud Shell ou usando a Google Cloud CLI.
Para executar o DAG
build_train_deploy:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'Execute o DAG
predict_serve:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
A seguir
- Leia o conjunto completo de tutoriais de CLV.
- Execute o exemplo completo no repositório do GitHub.
- Saiba mais sobre outras soluções de previsão preditiva.
- Conheça arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.