Este documento está dirigido a desarrolladores de software y administradores de bases de datos que deseen migrar aplicaciones existentes o diseñar aplicaciones nuevas para usar con Bigtable como almacén de datos. En este documento, se aplican tus conocimientos de Apache Cassandra para usar Bigtable.
Bigtable y Cassandra son bases de datos distribuidas. Implementan almacenes de pares clave-valor multidimensionales que pueden admitir decenas de miles de consultas por segundo (QPS), almacenamiento que escala verticalmente hasta petabytes de datos y tolerancia a fallas del nodo.
Si bien los conjuntos de atributos de estas bases de datos son similares en un alto nivel, sus arquitecturas subyacentes y detalles de interacción difieren en formas que es importante comprender. En este documento, se destacan las similitudes y diferencias entre los dos sistemas de bases de datos.
Cómo usar este documento
No es necesario que leas este documento de principio a fin. Si bien en este documento se proporciona una comparación de las dos bases de datos, también puedes enfocarte en los temas que se aplican a tu caso de uso o intereses.
Comparar dos bases de datos consolidadas no es una tarea simple. Para lograr este objetivo, en este documento se hace lo siguiente:
- Se compara la terminología, que puede variar entre las dos bases de datos.
- Se proporciona una descripción general de los dos sistemas de base de datos.
- Se observa cómo cada base de datos maneja el modelado de datos para comprender las diferentes consideraciones de diseño.
- Se compara la ruta de acceso que toman los datos durante las operaciones de escritura y lectura.
- Se examina el diseño de datos físicos para comprender los aspectos de la arquitectura de la base de datos.
- Se describe cómo configurar la replicación geográfica para que cumpla con tus requisitos y cómo abordar el tamaño del clúster.
- Se revisa los detalles sobre la administración, la supervisión y la seguridad de los clústeres.
Comparación de terminología
Aunque muchos de los conceptos que se usan en Bigtable y Cassandra son similares, cada base de datos tiene convenciones de nombres un poco diferentes y diferencias sutiles.
Uno de los componentes básicos de ambas bases de datos es la tabla de strings ordenada (SSTable). En ambas arquitecturas, se crean SSTables a fin de conservar los datos que se usan para responder a las consultas de lectura.
En una entrada de blog (2012), Ilya Grigorik escribe lo siguiente: “Un SSTable es una abstracción simple que sirve para almacenar de manera eficiente grandes cantidades de pares clave-valor y, al mismo tiempo, optimizar las cargas de trabajo de alta capacidad de procesamiento y lectura o escritura secuenciales”.
En la siguiente tabla, se definen y describen los conceptos compartidos y la terminología correspondiente que usa cada producto:
| Cassandra | Bigtable |
|---|---|
|
clave primaria: un valor de campo único o multicampo que determina la ubicación y el orden de los datos. clave de partición: un valor de campo único o multicampo que determina la ubicación de los datos mediante un hash coherente. columna de agrupamiento en clústeres: un valor de campo único o multicampo que determina el orden de los datos lexicográfico dentro de una partición. |
Clave de fila: una string de bytes única y exclusiva que determina la ubicación de los datos mediante un orden lexicográfico. Las claves compuestas se imitan mediante la unión de los datos de varias columnas con ayuda de un delimitador común, por ejemplo, los símbolos de hash (#) o de porcentaje (%). |
| nodo: una máquina responsable de leer y escribir datos asociados con una serie de rangos de hash de partición de clave primaria. En Cassandra, los datos se almacenan en el almacenamiento a nivel de bloque que está conectado al servidor de nodos. | nodo: un recurso de procesamiento virtual responsable de leer y escribir datos asociados con una serie de rangos de claves de fila. En Bigtable, los datos no se ubican junto con los nodos de procesamiento. En su lugar, se almacenan en Colossus, el sistema de archivos distribuido de Google. Los nodos tienen responsabilidad temporal para entregar varios rangos de datos en función de la carga de la operación y del estado de otros nodos en el clúster. |
|
centro de datos: es similar a un clúster de Bigtable, excepto que algunos aspectos de la topología y la estrategia de replicación se pueden configurar en Cassandra. bastidor: una agrupación de nodos en un centro de datos que influye en la ubicación de la réplica. |
clúster: Es un grupo de nodos en la misma zona geográfica de Google Cloud, que se usa para reducir los problemas de latencia y replicación. |
| clúster: Una implementación de Cassandra que consta de una colección de centros de datos. | instancia: Un grupo de clústeres de Cloud Bigtable en diferentes zonas o regiones de Google Cloud entre las operaciones de replicación y enrutamiento de conexión. |
| vnode: un rango fijo de valores de hash asignados a un nodo físico específico. Los datos en un vnode se almacenan de forma física en el nodo de Cassandra en una serie de SSTables. | tablet: una SSTable que contiene todos los datos de un rango contiguo de claves de fila ordenadas de forma lexicográfica. Los tablets no se almacenan en nodos de Bigtable, sino en una serie de SSTables en Colossus. |
| factor de replicación: la cantidad de réplicas de un vnode que se mantienen en todos los nodos del centro de datos. El factor de replicación se configura de forma independiente para cada centro de datos. | replicación: el proceso de replicación de los datos almacenados en Bigtable en todos los clústeres de la instancia. La capa de almacenamiento de Colossus controla la replicación dentro de un clúster zonal. |
| table (antes conocida como familia de columnas): es una organización lógica de valores que se indexa por la clave primaria única. | table: Es una organización lógica de valores que se indexa mediante una clave de fila única. |
| keyspace: Es un espacio de nombres de tabla lógica que define el factor de replicación para las tablas que contiene. | No aplicable. Bigtable maneja los problemas de espacio de claves de manera transparente. |
| No aplicable | calificador de columna: Es una etiqueta para un valor almacenado en una tabla indexada por la clave de fila única. |
| No aplicable | Familia de columnas: Es un espacio de nombres especificado por el usuario que agrupa calificadores de columnas para lecturas y escrituras más eficientes |
| columna: Es la etiqueta de un valor almacenado en una tabla que se indexa con la clave primaria única. | columna: la etiqueta de un valor almacenado en una tabla que se indexa con la clave primaria única. El nombre de la columna se construye combinando la familia de columnas con el calificador de columna. |
| celda: un valor de marca de tiempo en una tabla asociada a la intersección de una clave primaria con la columna. | celda: un valor de marca de tiempo en una tabla asociada a la intersección de una clave de fila con el nombre de la columna. Se pueden almacenar y recuperar múltiples versiones con marca de tiempo para cada celda. |
| política de balanceo de cargas: una política que configuras en la lógica de la aplicación para enrutar las operaciones a un nodo apropiado en el clúster. La política tiene en cuenta la topología del centro de datos y los rangos de tokens del vnode. | perfil de aplicación: configuración que indica a Bigtable cómo enrutar una llamada a la API de cliente al clúster adecuado en la instancia. También puedes usar el perfil de la aplicación como una etiqueta de instancia para segmentar las métricas. Configuras el perfil de la aplicación en el servicio. |
| CQL: Es el lenguaje de consulta de Cassandra, un lenguaje como SQL que se usa para crear tablas, cambios de esquema, mutaciones de filas y consultas. | API de Bigtable: Son las bibliotecas cliente y las API de gRPC que se usan para la creación de instancias y clústeres, la creación de familias de tablas y columnas, las mutaciones de filas y las consultas. |
Descripciones generales de los productos
En las siguientes secciones, se proporciona una descripción general de la filosofía de diseño y los atributos clave de Bigtable y Cassandra.
Bigtable
Bigtable proporciona muchas de las funciones principales descritas en el documento de Bigtable: un sistema de almacenamiento distribuido para datos estructurados. Bigtable separa los nodos de procesamiento, que entregan solicitudes de clientes, desde la administración de almacenamiento subyacente. Los datos se almacenan en Colossus. La capa de almacenamiento replica de forma automática los datos para proporcionar una durabilidad que supera los niveles proporcionados por la replicación del sistema de archivos distribuido de Hadoop (HDFS) estándar en tres direcciones.
Esta arquitectura proporciona lecturas y escrituras coherentes dentro de un clúster, aumenta o disminuye la escala sin ningún costo de redistribución de almacenamiento y puede volver a balancear las cargas de trabajo sin modificar el clúster o el esquema. Si algún nodo de procesamiento de datos se ve afectado, el servicio de Bigtable lo reemplaza de manera transparente. Bigtable también admite la replicación asíncrona.
Además de gRPC y bibliotecas cliente para varios lenguajes de programación, Bigtable mantiene la compatibilidad con Apache de código abierto HBase, la biblioteca cliente para Java, una implementación alternativa del motor de base de datos de código abierto del documento de Bigtable.
En el diagrama siguiente, se muestra cómo Bigtable separa físicamente los nodos de procesamiento de la capa de almacenamiento:
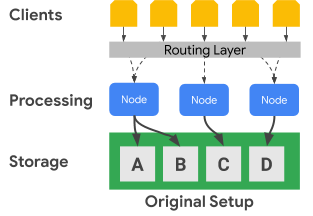
En el diagrama anterior, el nodo de procesamiento central solo es responsable de entregar las solicitudes de datos del conjunto de datos C en la capa de almacenamiento. Si Bigtable identifica que el rebalanceo de asignación de rango es necesario para un conjunto de datos, los rangos de datos de un nodo de procesamiento son fáciles de cambiar porque la capa de almacenamiento está separada de la de procesamiento.
En el siguiente diagrama, se muestra, en términos simplificados, un rebalanceo de rango de claves y un cambio de tamaño de clúster:
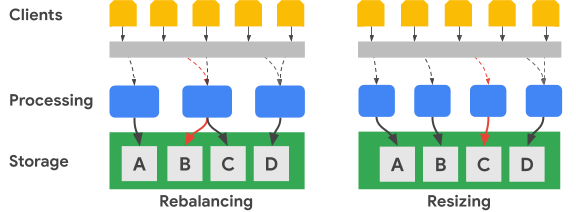
La imagen Rebalanceo ilustra el estado del clúster de Bigtable después de que el nodo de procesamiento más a la izquierda recibe una mayor cantidad de solicitudes para el conjunto de datos A. Después de que se realiza el rebalanceo, el nodo central, en lugar del nodo más a la izquierda, es responsable de entregar las solicitudes de datos para el conjunto de datos B. El nodo más a la izquierda continúa las solicitudes de entrega para el conjunto de datos A.
Bigtable puede reorganizar los rangos de claves de fila a fin de equilibrar los rangos de conjuntos de datos entre una mayor cantidad de nodos de procesamiento disponibles. La imagen Cambio de tamaño muestra el estado del clúster de Bigtable después de agregar un nodo.
Cassandra
Apache Cassandra es una base de datos de código abierto en la que influyen parcialmente los conceptos del documento de Bigtable. Usa una arquitectura de nodo distribuido, en la que el almacenamiento se ubica junto con los servidores que responden a las operaciones de los datos. Una serie de nodos virtuales (vnodes) se asignan de forma aleatoria a cada servidor para entregar una parte del espacio de claves del clúster.
Los datos se almacenan en los vnodes según la clave de partición. Por lo general, se usa una función hash coherente para generar un token a fin de determinar la ubicación de los datos. Al igual que con Bigtable, puedes usar un particionador de preservación de orden para la generación de tokens y, por lo tanto, para la ubicación de datos. Sin embargo, en la documentación de Cassandra se desaconseja este enfoque porque es probable que el clúster deje de estar balanceado, una condición que es difícil de solucionar. Por este motivo, en este documento, se da por sentado que usas una estrategia de hash coherente para generar tokens que generen una distribución de datos entre los nodos.
Cassandra proporciona tolerancia a errores a través de los niveles de disponibilidad que están correlacionados con el nivel de coherencia ajustable, lo que permite que un clúster entregue contenido a los clientes mientras uno o más nodos se ven afectados. Debes definir la replicación geográfica a través de una estrategia de topología de replicación de datos configurable.
Debes especificar un nivel de coherencia para cada operación. La configuración típica es QUORUM (o LOCAL_QUORUM en ciertas topologías de centros de múltiples datos). Esta configuración de nivel de coherencia requiere que la mayoría de los nodos de réplica respondan al nodo coordinador para que la operación se considere correcta. El factor de replicación, que configuras para cada espacio de claves, determina la cantidad de réplicas de datos que se almacenan en cada centro de datos en el clúster. Por ejemplo, es común usar un valor de factor de replicación de 3 para proporcionar un equilibrio práctico entre la durabilidad y el volumen de almacenamiento.
En el siguiente diagrama, se muestra en términos simplificados un clúster de seis nodos con el rango de claves de cada nodo dividido en cinco vnodes. En la práctica, puedes tener más nodos y es probable que tengas más vnodes.

En el diagrama anterior, puedes ver la ruta de una operación de escritura, con un nivel de coherencia de QUORUM, que se origina en una aplicación o servicio de cliente (Cliente). Para los fines de este diagrama, los rangos de claves se muestran como rangos alfabéticos. En realidad, los tokens producidos por un hash de la clave primaria son números enteros firmados muy grandes.
En este ejemplo, el hash de la clave es M y los vnodes para M están en los nodos 2, 4 y 6. El coordinador debe comunicarse con cada nodo en el que los rangos de hash de clave se almacenen de forma local para que se pueda procesar la escritura. Dado que el nivel de coherencia es QUORUM, dos réplicas (una mayoría) deben responder al nodo coordinador antes de que se notifique al cliente que la escritura se completó.
A diferencia de Bigtable, para mover o cambiar rangos de claves en Cassandra, se requiere que copies de forma física los datos de un nodo a otro. Si un nodo está sobrecargado con solicitudes para un rango de hash de token determinado, agregar el procesamiento para ese rango de tokens es más complejo en Cassandra en comparación con Bigtable.
Coherencia y replicación geográfica
Bigtable y Cassandra controlan la replicación y la coherencia geográfica (también conocida como multirregión) de manera diferente. Un clúster de Cassandra consiste en procesar nodos agrupados en bastidores, y los bastidores se agrupan en centros de datos. Cassandra usa una estrategia de topología de red que configuras para determinar cómo se distribuyen las réplicas de vnode entre los hosts en un centro de datos. Esta estrategia revela las raíces de Cassandra como una base de datos implementada originalmente en centros de datos físicos locales. Esta configuración también especifica el factor de replicación para cada centro de datos en el clúster.
Cassandra usa parámetros de configuración de centro de datos y bastidores para mejorar la tolerancia a errores de las réplicas de datos. Durante las operaciones de lectura y escritura, la topología determina los nodos participantes que se requieren para proporcionar garantías de coherencia. Cuando creas o extiendes un clúster, debes configurar de forma manual los nodos, bastidores y centros de datos. En un entorno de nube, una implementación típica de Cassandra trata una zona de la nube como un bastidor y una región de la nube como un centro de datos.
Puedes usar los controles de quórum de Cassandra a fin de ajustar las garantías de coherencia para cada operación de lectura o escritura. Los niveles de seguridad de la coherencia eventual pueden variar, incluidas las opciones que requieren un único nodo de réplica (ONE), una mayoría de nodos de réplica de un único centro de datos (LOCAL_QUORUM) o una mayoría de los nodos de réplica en todos los centros de datos (QUORUM)
En Bigtable, los clústeres son recursos zonales. Una instancia de Bigtable puede contener un solo clúster o puede ser un grupo de clústeres replicados por completo. Puedes colocar clústeres de instancias en cualquier combinación de zonas en cualquier región que ofrezca Google Cloud. Puedes agregar clústeres a una instancia, o quitarlos de ella, con un impacto mínimo en otros clústeres de la instancia.
En Bigtable, las escrituras se realizan (con coherencia en la lectura de tus escrituras) en un solo clúster, y serán de coherencia eventual en los otros clústeres de instancias. Debido a que el control de versiones de las celdas individuales dependen de la marca de tiempo, no se pierde ninguna escritura y cada clúster entrega las celdas que tienen disponibles las marcas de tiempo más actuales.
El servicio expone el estado de coherencia del clúster. La API de Cloud Bigtable proporciona un mecanismo para obtener un token de coherencia a nivel de tabla. Puedes usar este token para confirmar si todos los cambios que se realizaron en esa tabla antes de que se haya creado el token se replicaron por completo.
Compatibilidad con transacciones
Aunque ninguna base de datos admite transacciones complejas de varias filas, cada una tiene cierta compatibilidad con transacciones.
Cassandra tiene un método de transacción ligera (LWT) que proporciona atomicidad para las actualizaciones de los valores de columna en una sola partición. Cassandra también tiene una semántica de comparación y configuración que completa la operación de lectura de la fila y la comparación de valores antes de que se inicie una escritura.
Bigtable admite escrituras completamente coherentes de una sola fila dentro de un clúster. Las transacciones de una sola fila se habilitan más mediante las operaciones de lectura, modificación y escritura, y de verificación y mutación. Los perfiles de aplicación de enrutamiento de múltiples clústeres no admiten transacciones de fila única.
Modelo de datos
Bigtable y Cassandra organizan los datos en tablas que admiten búsquedas y análisis de rangos con el identificador único de la fila. Ambos sistemas se clasifican como almacenes de NoSQL de columna ancha.
En Cassandra, debes usar CQL para crear el esquema de tabla completo por adelantado, incluida la definición de clave primaria junto con los nombres de las columnas y sus tipos. Las claves primarias en Cassandra son valores compuestos únicos que constan de una clave de partición obligatoria y una clave de clúster opcional. La clave de partición determina la ubicación del nodo de una fila, y la clave del clúster determina el orden dentro de una partición. Cuando creas esquemas, debes tener en cuenta las posibles compensaciones entre ejecutar análisis eficientes dentro de una partición única y los costos del sistema asociados con el mantenimiento de particiones grandes.
En Bigtable, solo necesitas crear la tabla y definir sus familias de columnas con anticipación. Las columnas no se declaran cuando se crean las tablas, pero sí cuando las llamadas a la API de la aplicación agregan celdas a las filas de la tabla.
Las claves de fila se ordenan de manera lexicográfica en el clúster de Bigtable. Los nodos de Bigtable equilibran de forma automática la responsabilidad de los nodos para los rangos de claves, a menudo denominadas tablets y, a veces, divisiones. Con frecuencia, las claves de fila de Bigtable constan de varios valores de campo que se unen con el carácter separador de uso común que elijas (como un signo de porcentaje). Cuando se separan, los componentes de string individuales son análogos a los campos de una clave primaria de Cassandra.
Diseño de la clave de fila
En Bigtable, el identificador único de una fila de la tabla es la clave de fila. La clave de fila debe ser un solo valor único en toda la tabla. Puedes crear claves de varias partes si concatenas elementos dispares separados por un delimitador común. La clave de fila determina el orden de los datos globales en una tabla. El servicio de Bigtable determina de forma dinámica los rangos de claves que se asignan a cada nodo.
A diferencia de Cassandra, en la que el hash de la clave de partición determina la ubicación de la fila y las columnas de agrupamiento en clústeres determinan el orden, la clave de fila de Bigtable proporciona asignación y orden de nodos. Al igual que con Cassandra, debes diseñar una clave de fila en Bigtable para que las filas que deseas recuperar juntas se almacenen juntas. Sin embargo, en Bigtable, no es necesario diseñar la clave de fila para la posición y el orden antes de usar una tabla.
Tipos de datos
El servicio de Bigtable no aplica tipos de datos de una columna que el cliente envíe. Las bibliotecas cliente proporcionan métodos auxiliares para escribir valores de celdas como bytes, strings codificadas en UTF-8 y números enteros de 64 bits codificados big-endian (se requieren números enteros codificados de big-endian para las operaciones de incremento atómico).
Familia de columnas
En Bigtable, una familia de columnas determina qué columnas de una tabla se almacenan y se recuperan juntas. Cada tabla necesita al menos una familia de columnas, aunque las tablas suelen tener más (el límite es de 100 familias de columnas para cada tabla). Debes crear familias de columnas de forma explícita antes de que una aplicación pueda usarlas en una operación.
Calificadores de columnas
Cada valor que se almacena en una tabla en una clave de fila se asocia con una etiqueta llamada calificador de columna. Debido a que los calificadores de columnas son solo etiquetas, no hay un límite práctico para la cantidad de columnas que puedes tener en una familia de columnas. Los calificadores de columnas suelen usarse en Bigtable para representar datos de aplicación.
celdas
En Bigtable, una celda es la intersección de la clave de fila y el nombre de la columna (una familia de columnas combinada con un calificador de columna). Cada celda contiene uno o más valores con marcas de tiempo que el cliente puede proporcionar o que el servicio aplica de forma automática. Los valores de celda antiguos se reclaman en función de una política de recolección de elementos no utilizados que se configura a nivel de la familia de columnas.
Índices secundarios
Bigtable no admite índices secundarios. Si se requiere un índice, te recomendamos que uses un diseño de tabla que use una segunda tabla con una clave de fila diferente.
Conmutación por error y balanceo de cargas de clientes
En Cassandra, el cliente controla el balanceo de cargas de las solicitudes. El controlador de cliente establece una política que se especifica como parte de la configuración o de manera programática durante la creación de la sesión. El clúster informa la política sobre los centros de datos más cercanos a la aplicación, y el cliente identifica los nodos de esos centros de datos para entregar una operación.
El servicio de Bigtable enruta las llamadas a la API a un clúster de destino en función de un parámetro (un identificador de perfil de aplicación) que se proporciona con cada operación. Los perfiles de aplicación se mantienen dentro del servicio de Bigtable. Las operaciones de cliente que no seleccionan un perfil usan uno predeterminado.
Bigtable tiene dos tipos de políticas de enrutamiento de perfil de aplicación: de un solo clúster y de múltiples clústeres. Un perfil de múltiples clústeres enruta las operaciones al clúster disponible más cercano. Los clústeres en la misma región se consideran equidistantes desde la perspectiva del router de la operación. Si el nodo responsable del rango de claves solicitado está sobrecargado o no está disponible temporalmente en un clúster, este tipo de perfil proporciona conmutación por error automática.
En términos de Cassandra, una política de múltiples clústeres proporciona los beneficios de conmutación por error de una política de balanceo de cargas que conoce los centros de datos.
Un perfil de aplicación que tiene enrutamiento de un solo clúster dirige todo el tráfico a un solo clúster. La coherencia sólida de las filas y las transacciones de una sola fila solo están disponibles en los perfiles que tienen enrutamiento de un solo clúster.
El problema de un enfoque de clúster único es que, en una conmutación por error, la aplicación debe poder volver a intentarlo con un identificador de perfil de aplicación alternativo o debes realizar la conmutación por error de forma manual de perfiles de enrutamiento de un solo clúster afectados.
Enrutamiento de operaciones
Cassandra y Bigtable usan métodos diferentes a fin de seleccionar el nodo de procesamiento para las operaciones de lectura y escritura. En Cassandra, se identifica la clave de partición, mientras que en Bigtable se usa la clave de fila.
En Cassandra, el cliente primero inspecciona la política de balanceo de cargas. Este objeto del cliente determina el centro de datos al que se enruta la operación.
Una vez identificado el centro de datos, Cassandra se comunica con un nodo coordinador para administrar la operación. Si la política reconoce tokens, el coordinador es un nodo que entrega datos de la partición de vnode de destino. De lo contrario, el coordinador es un nodo aleatorio. El nodo coordinador identifica los nodos en los que se encuentran las réplicas de datos de la clave de partición de la operación y, luego, le indica a esos nodos que realicen la operación.
En Bigtable, como se mencionó antes, cada operación incluye un identificador de perfil de aplicación. El perfil de la aplicación se define a nivel de servicio. La capa de enrutamiento de Bigtable inspecciona el perfil a fin de elegir el clúster de destino apropiado para la operación. Luego, la capa de enrutamiento proporciona una ruta para que la operación llegue a los nodos de procesamiento correctos mediante la clave de fila de la operación.
Proceso de escritura de datos
Ambas bases de datos están optimizadas para las operaciones de escritura rápidas, y usan un proceso similar para completar una operación de escritura. Sin embargo, los pasos que toman las bases de datos varían un poco, especialmente para Cassandra, en el que, según el nivel de coherencia de la operación, es posible que se requiera la comunicación con nodos participantes adicionales.
Después de que la solicitud de escritura se enruta a los nodos (Cassandra), o nodo (Bigtable), adecuados, las escrituras primero se conservan en el disco de forma secuencial, en un registro de confirmación (Cassandra) o en un registro compartido (Bigtable). Luego, las escrituras se insertan en una tabla en la memoria (también conocida como memtable) que se ordena como SSTables.
Después de estos dos pasos, el nodo responde para indicar que la escritura se completó. En Cassandra, varias réplicas (según el nivel de coherencia especificado para cada operación) deben responder antes de que el coordinador informe al cliente que se completó la escritura. En Bigtable, ya que cada clave de fila se asigna solo a un solo nodo en cualquier momento, solo se necesita una respuesta del nodo para confirmar que una escritura se realizó de forma correcta.
Luego, si es necesario, puedes vaciar la memtable en el disco en forma de una nueva SSTable. En Cassandra, el vaciado ocurre cuando el registro de confirmación alcanza un tamaño máximo o cuando la memtable excede el umbral que configuraste. En Bigtable, se inicia un vaciado para crear SSTables inmutables nuevas cuando la memtable alcanza un tamaño máximo que especifica el servicio. Periódicamente, un proceso de compactación combina SSTables para un rango de claves dado en una solo SSTable.
Actualizaciones de datos
Ambas bases de datos controlan las actualizaciones de datos de manera similar. Sin embargo, Cassandra permite solo un valor por cada celda, mientras que Bigtable puede mantener una gran cantidad de valores con versión para cada celda.
Cuando se modifica el valor en la intersección de un identificador de fila único y una columna, la actualización se conserva como se describió antes en la sección de proceso de escritura de datos. La marca de tiempo de escritura se almacena junto con el valor en la estructura de SSTable.
Si no vaciaste una celda actualizada en una SSTable, solo puedes almacenar el valor de la celda en la memtable, pero las bases de datos diferirán de lo que se almacena. Cassandra guarda solo el valor más reciente en la memtable, mientras que Bigtable guarda todas las versiones en la memtable.
Como alternativa, si vaciaste al menos una versión de un valor de celda en el disco en SSTables independientes, las bases de datos manejan las solicitudes de esos datos de manera diferente. Cuando se solicita la celda desde Cassandra, solo se muestra el valor más reciente de acuerdo con la marca de tiempo. En otras palabras, gana la última escritura. En Bigtable, debes usar filtros para controlar qué versiones de las celdas muestra una solicitud de lectura.
Eliminaciones de filas
Debido a que ambas bases de datos usan archivos de SSTable inmutables para conservar datos en el disco, no es posible borrar una fila de inmediato. Para garantizar que las consultas muestren los resultados correctos después de que se borre una fila, ambas bases de datos manejan las eliminaciones mediante el mismo mecanismo. Primero se agrega un marcador (llamado tombstone en Cassandra) a la memtable. Finalmente, una SSTable recién escrita contiene un marcador con una marca de tiempo que indica que el identificador de fila único se borra y no se debe mostrar en los resultados de la consulta.
Tiempo de vida
El tiempo de actividad (TTL) en las dos bases de datos es similar, excepto por una diferencia. En Cassandra, puedes configurar el TTL para una columna o una tabla, mientras que, en Bigtable, solo puedes configurar el TTL para la familia de columnas. Existe un método para Bigtable que puede simular el TTL a nivel de la celda.
Recolección de elementos no utilizados
Debido a que las actualizaciones o eliminaciones inmediatas de datos no son posibles con las SSTables inmutables, como se mencionó antes, la recolección de elementos no utilizados se produce durante un proceso llamado compactación. Este proceso quita las celdas o filas que no deben entregarse en los resultados de la consulta.
El proceso de recolección de elementos no utilizados excluye una fila o celda cuando se produce una combinación de SSTable. Si existe un marcador, o tombstone, para una fila, esa fila no se incluye en la SSTable resultante. Ambas bases de datos pueden excluir una celda de la SSTable combinada. Si la marca de tiempo de la celda excede una calificación de TTL, las bases de datos excluyen la celda. Si hay dos versiones con marca de tiempo para una celda determinada, Cassandra solo incluye el valor más reciente en la SSTable combinada.
Ruta de lectura de datos
Cuando una operación de lectura llega al nodo de procesamiento adecuado, el proceso de lectura a fin de obtener datos para satisfacer un resultado de la consulta es el mismo en ambas bases de datos.
Para cada SSTable en el disco que podría contener resultados de consulta, se verifica un filtro de Bloom a fin de determinar si cada archivo contiene filas que se mostrarán. Como los filtros de Bloom garantizan que nunca se proporcione un falso negativo, todas las SSTables aptas se agregan a una lista de candidatas para que se incluya en el procesamiento de resultados de lectura adicional.
La operación de lectura se realiza mediante una vista combinada creada a partir de la memtable y las SSTables candidatas en el disco. Debido a que todas las claves están ordenadas de forma lexicográfica, es eficiente obtener una vista combinada que se analice para obtener resultados de consultas.
En Cassandra, un conjunto de nodos de procesamiento determinados por el nivel de coherencia de la operación debe participar en la operación. En Bigtable, solo se debe consultar el nodo responsable del rango de claves. En Cassandra, debes considerar las implicaciones del tamaño del procesamiento porque es probable que múltiples nodos procesen cada lectura.
Los resultados de la lectura se pueden limitar en el nodo de procesamiento de maneras un tanto diferentes.
En Cassandra, la cláusula WHERE en una consulta de CQL restringe las filas que se muestran. La restricción es que las columnas de la clave primaria o las columnas incluidas en un índice secundario pueden usarse para limitar los resultados.
Bigtable ofrece una amplia variedad de filtros de filtro que afectan las filas o celdas que recupera una consulta de lectura.
Existen tres categorías de filtros:
- Filtros de límite, que controlan las filas o celdas que incluye la respuesta.
- Filtros de modificación, que afectan los datos o metadatos de las celdas individuales.
- Filtros compuestos, que te permiten combinar múltiples filtros en un filtro.
Los filtros de límite son los más usados, por ejemplo, la expresión regular de la familia de columnas y la expresión regular del calificador de columna.
Almacenamiento de datos físicos
Bigtable y Cassandra almacenan datos en SSTables, que se combinan con regularidad durante una fase de compactación. La compresión de datos de SSTable ofrece beneficios similares para reducir el tamaño de almacenamiento. Sin embargo, la compresión se aplica de forma automática en Bigtable y es una opción de configuración en Cassandra.
Cuando compares las dos bases de datos, debes comprender cómo cada una almacena de forma física los datos en los siguientes aspectos:
- La estrategia de distribución de datos
- El número de versiones de celdas disponibles
- El tipo de disco de almacenamiento
- El mecanismo de durabilidad y replicación de los datos
Distribución de datos
En Cassandra, un hash coherente de las columnas de partición de la clave primaria es el método recomendado para determinar la distribución de datos en las distintas SSTables que entregan los nodos del clúster.
Bigtable usa un prefijo de variable para la clave de fila completa a fin de colocar los datos en SSTables de manera lexicográfica.
Versiones de celdas
Cassandra conserva solo una versión activa del valor de una celda. Si se realizan dos operaciones de escritura en una celda, una política de “la última escritura gana” garantiza que solo se muestre un valor.
Bigtable no limita la cantidad de versiones con marcas de tiempo para cada celda. Es posible que se apliquen otros límites de tamaño de fila. Si la solicitud del cliente no la establece, el servicio de Bigtable determina la marca de tiempo en el momento en que el nodo de procesamiento recibe la mutación. Las versiones de las celdas se pueden reducir con una política de recolección de elementos no utilizados que puede ser diferente para la familia de columnas de cada tabla o se puede filtrar desde un conjunto de resultados de consultas a través de la API.
Almacenamiento en disco
Cassandra almacena SSTables en discos conectados a cada nodo del clúster. Para volver a balancear los datos en Cassandra, los archivos deben copiarse físicamente entre los servidores.
Bigtable usa Colossus para almacenar SSTables. Debido a que Bigtable usa este sistema de archivos distribuido, es posible que el servicio de Bigtable reasigne SSTables de forma casi instantánea a diferentes nodos.
Replicación y durabilidad de datos
Cassandra entrega la durabilidad de los datos a través de la configuración del factor de replicación. El factor de replicación determina la cantidad de copias de SSTable que se almacenan en nodos diferentes en el clúster. Una configuración típica del factor de replicación es 3, que aún permite garantías de coherencia más sólidas con QUORUM o LOCAL_QUORUM, incluso si se produce una falla de nodo.
Con Bigtable, se proporcionan altas garantías de durabilidad de datos a través de la replicación que proporciona Colossus.
En el siguiente diagrama, se ilustra el diseño de datos físicos, los nodos de procesamiento computacionales y la capa de enrutamiento para Bigtable:

En la capa de almacenamiento de Colossus, cada nodo se asigna para entregar los datos que se almacenan en una serie de SSTables. Esas SSTables contienen los datos de los rangos de claves de fila que se asignan de forma dinámica a cada nodo. Si bien en el diagrama se muestran tres SSTables para cada nodo, es probable que haya más, ya que lqs SSTables se crean de forma continua a medida que los nodos reciben cambios nuevos en los datos.
Cada nodo tiene un registro compartido. Las escrituras procesadas por cada nodo se conservan de inmediato en el registro compartido antes de que el cliente reciba una confirmación de escritura. Debido a que una operación de escritura en Colossus se replica varias veces, la durabilidad está garantizada incluso si se produce una falla en el hardware de nodos antes de que los datos se conserven en una SSTable para el rango de filas.
Interfaces de aplicaciones
En un principio, el acceso a la base de datos de Cassandra se expuso a través de una API de Thrift, pero este método de acceso está obsoleto. La interacción del cliente recomendada es a través de CQL.
Al igual que la API de Thrift original de Cassandra, el acceso a la base de datos de Bigtable se proporciona a través de una API que lee y escribe datos según las claves de fila proporcionadas.
Al igual que Cassandra, Bigtable tiene una interfaz de línea de comandos, denominada CLI de cbt, y bibliotecas cliente que admiten muchos lenguajes de programación comunes. Estas bibliotecas se basan en las APIs de gRPC y REST. Las aplicaciones que se escriben para Hadoop y dependen de la biblioteca de código abierto de Apache HBase para Java pueden conectarse sin cambios significativos a Bigtable. Para las aplicaciones que no requieren compatibilidad con HBase, te recomendamos que uses el cliente integrado de Java para Bigtable.
Los controles de administración de identidades y accesos (IAM) de Bigtable están completamente integrados en Google Cloud, y las tablas también se pueden usar como una fuente de datos externa de BigQuery.
Configuración de la base de datos
Cuando configuras un clúster de Cassandra, hay varias decisiones de configuración que debes tomar y pasos que completar. Primero, debes configurar los nodos del servidor para que proporcionen capacidad de procesamiento y aprovisionen el almacenamiento local. Cuando usas un factor de replicación de tres, la configuración recomendada y más común, debes aprovisionar el almacenamiento para almacenar tres veces la cantidad de datos que esperas guardar en tu clúster. También debes determinar y establecer la configuración de los vnodes, los bastidores y la replicación.
La separación del procesamiento del almacenamiento en Bigtable simplifica el escalamiento vertical de los clústeres en comparación con Cassandra. En un clúster con ejecución normal, por lo general, solo te preocupa el almacenamiento total que usan las tablas administradas, lo que determina la cantidad mínima de nodos, y tienes suficientes nodos para mantener las QPS actuales.
Puedes ajustar rápidamente el tamaño del clúster de Bigtable si el clúster está aprovisionado de forma insuficiente o en exceso según la carga de producción.
Almacenamiento de Bigtable
Además de la ubicación geográfica del clúster inicial, la única decisión que debes tomar cuando creas la instancia de Bigtable es con respecto al tipo de almacenamiento. Bigtable ofrece dos opciones para el almacenamiento: unidades de estado sólido (SSD) o unidades de disco duro (HDD). Todos los clústeres de una instancia deben compartir el mismo tipo de almacenamiento.
Cuando tienes en cuenta las necesidades de almacenamiento con Bigtable, no necesitas tener en cuenta las réplicas de almacenamiento, como lo harías con el ajuste de tamaño de un clúster de Cassandra. No hay pérdida de densidad de almacenamiento para lograr tolerancia a errores como se ve en Cassandra. Además, dado que no es necesario aprovisionar el almacenamiento de forma explícita, solo se te cobrará por el almacenamiento en uso.
SSD
La capacidad del nodo SSD de 5 TB, que es preferible para la mayoría de las cargas de trabajo, proporciona mayor densidad de almacenamiento en comparación con la configuración recomendada para las máquinas Cassandra, que tienen una densidad de almacenamiento máxima práctica de menos de 2 TB para cada nodo. Cuando evalúes las necesidades de capacidad de almacenamiento, recuerda que Bigtable solo cuenta una copia de los datos, en comparación, Cassandra debe dar cuenta de tres copias de los datos en la mayoría de las configuraciones.
Si bien las QPS de escritura para SSD son casi iguales que el HDD, la SSD proporciona una QPS de lectura significativamente mayor que el HDD. El almacenamiento SSD tiene un precio o un costo cercano a los discos persistentes SSD aprovisionados y varía según la región.
HDD
El tipo de almacenamiento HDD permite una densidad de almacenamiento considerable: 16 TB para cada nodo. La compensación es que las lecturas aleatorias son mucho más lentas y solo admiten 500 filas de lectura por segundo para cada nodo. Se prefiere HDD para las cargas de trabajo de escritura intensiva en la que se espera que las lecturas sean análisis de rango asociados con el procesamiento por lotes. El almacenamiento HDD tiene un precio igual o cercano al asociado con Cloud Storage y varía según la región.
Consideraciones de tamaño del clúster
Cuando dimensiones una instancia de Bigtable con el fin de prepararte para migrar una carga de trabajo de Cassandra, hay consideraciones cuando comparas clústeres de Cassandra de un solo centro de datos con instancias de Bigtable de un solo clúster, y clústeres de múltiples centros de datos de Cassandra con instancias de Bigtable de múltiples clústeres. En los lineamientos de las siguientes secciones, se da por sentado que no se necesitan cambios significativos en el modelo de datos para migrar y que hay una compresión de almacenamiento equivalente entre Cassandra y Bigtable.
Un clúster de un único centro de datos
Cuando comparas un clúster de un único centro de datos único con una instancia de Bigtable de un solo clúster, primero debes considerar los requisitos de almacenamiento. Puedes estimar el tamaño no replicado de cada espacio de claves mediante el comando de estadísticas de la tabla nodetool y dividir el tamaño de almacenamiento vaciado total por el factor de replicación del espacio de claves. Luego, divide la cantidad de almacenamiento no replicado de todos los espacios de claves por 3.5 TB (5 TB * 0.70) a fin de determinar la cantidad sugerida de nodos SSD para controlar solo el almacenamiento. Como se analizó, Bigtable controla la replicación y la durabilidad del almacenamiento dentro de un nivel independiente que es transparente para el usuario.
A continuación, debes considerar los requisitos de procesamiento para la cantidad de nodos. Puedes consultar las métricas de la aplicación cliente y del servidor de Cassandra para obtener una cantidad aproximada de las lecturas y escrituras continuas que se ejecutaron. Si quieres calcular la cantidad mínima de nodos SSD para realizar la carga de trabajo, divide esa métrica por 10,000. Es probable que necesites más nodos para las aplicaciones que requieren resultados de consultas de baja latencia. Google recomienda que pruebes el rendimiento de Bigtable con datos y consultas representativos a fin de establecer una métrica para las QPS por nodo que sea factible para tu carga de trabajo.
La cantidad de nodos necesarios para el clúster debe ser igual a las mayores necesidades de almacenamiento y procesamiento. Si tienes dudas sobre tus necesidades de almacenamiento o capacidad de procesamiento, puedes hacer coincidir la cantidad de nodos de Bigtable con la cantidad de máquinas típicas de Cassandra. Puedes aumentar o reducir el escalamiento de un clúster de Bigtable para que coincida con las necesidades de carga de trabajo con un esfuerzo mínimo y sin tiempo de inactividad.
Un clúster de múltiples centros de datos
Con los clústeres de múltiples centros de datos, es más difícil determinar la configuración de una instancia de Bigtable. Lo ideal sería tener un clúster en la instancia para cada centro de datos en la topología de Cassandra. Cada clúster de Bigtable en la instancia debe almacenar todos los datos dentro de la instancia y debe poder controlar la tasa de inserción total en todo el clúster. Los clústeres en una instancia se pueden crear en cualquier región de la nube compatible en todo el mundo.
La técnica para estimar las necesidades de almacenamiento es similar al enfoque para los clústeres de un único centro de datos. Usa nodetool para capturar el tamaño de almacenamiento de cada espacio de claves en el clúster de Cassandra y, luego, divide ese tamaño por la cantidad de réplicas. Debes recordar que el espacio de claves de una tabla puede tener diferentes factores de replicación para cada centro de datos.
La cantidad de nodos en cada clúster de una instancia debe poder manejar todas las operaciones de escritura en el clúster y todas las lecturas en al menos dos centros de datos para mantener los objetivos de nivel de servicio (SLO) durante una interrupción del clúster. Un enfoque común al comienzo es que todos los clústeres tengan la capacidad de nodo equivalente del centro de datos más activo del clúster de Cassandra. Los clústeres de Bigtable en una instancia pueden escalarse verticalmente o reducirse de forma individual para que coincidan con las necesidades de carga de trabajo sin tiempo de inactividad.
Administración
Bigtable proporciona componentes completamente administrados para las funciones de administración comunes que se realizan en Cassandra.
copia de seguridad y restauración
Bigtable proporciona dos métodos para cubrir las necesidades comunes de copias de seguridad: las copias de seguridad de Bigtable y las exportaciones de datos administrados.
Puedes pensar que las copias de seguridad de Bigtable son análogas a una versión administrada de la función de instantáneas nodetool de Cassandra.
Las copias de seguridad de Bigtable crean copias de una tabla que se pueden restablecer, que se almacenan como objetos miembros de un clúster. Puedes restablecer copias de seguridad como una tabla nueva en el clúster que inició la copia de seguridad. Estas copias de seguridad se diseñaron para crear puntos de restablecimiento si se produce una corrupción a nivel de la aplicación. Las copias de seguridad que creas a través de esta utilidad no consumen recursos de nodo y tienen precios iguales o cercanos a los de Cloud Storage. Puedes invocar las copias de seguridad de Bigtable de manera programática o a través de la consola de Google Cloud para Bigtable.
Otra forma de crear una copia de seguridad de Bigtable es usar una exportación de datos administrada en Cloud Storage. Puedes exportar en los formatos de archivo de secuencia de Avro, Parquet o Hadoop. En comparación con las copias de seguridad de Bigtable, las exportaciones tardan más en ejecutarse y generan costos de procesamiento adicionales porque las exportaciones usan Dataflow. Sin embargo, estas exportaciones crean archivos de datos portátiles que puedes consultar sin conexión o importar a otro sistema.
Cambiar el tamaño
Debido a que Bigtable separa el almacenamiento y el procesamiento, puedes agregar o quitar nodos de Bigtable en respuesta a la demanda de la consulta de forma más fluida que en Cassandra. La arquitectura homogénea de Cassandra requiere que vuelvas a balancear los nodos (o vnodos) en las máquinas del clúster.
Puedes cambiar el tamaño del clúster de forma manual en la consola de Google Cloud o de manera programática con la API de Cloud Bigtable. Agregar nodos a un clúster puede producir mejoras de rendimiento notables en cuestión de minutos. Algunos clientes usaron con éxito un escalador automático de código abierto desarrollado por Spotify.
Mantenimiento interno
El servicio de Bigtable maneja sin problemas tareas comunes de mantenimiento interno de Cassandra, como parches de SO, recuperación de nodos, reparación de nodos, supervisión de compactación de almacenamiento y rotación de certificados SSL.
Monitoring
Conectar Bigtable a una visualización de métricas o a alertas no requiere esfuerzo de administración ni de desarrollo. En la página de la consola de Google Cloud de Bigtable, se incluyen paneles precompilados para realizar un seguimiento de las métricas de capacidad de procesamiento y uso a nivel de instancia, clúster y tabla. Las vistas y alertas personalizadas se pueden crear en los paneles de Cloud Monitoring, en los que las métricas están disponibles de forma automática.
Key Visualizer de Bigtable, una función de supervisión de la consola de Google Cloud, te permite realizar ajustes de rendimiento avanzados.
IAM y seguridad
En Bigtable, la autorización está completamente integrada en el framework de IAM de Google Cloud, y requiere una configuración y un mantenimiento mínimos. Las cuentas de usuario y contraseñas locales no se comparten con las aplicaciones cliente. En su lugar, se otorgan permisos y roles detallados a usuarios a nivel de la organización y cuentas de servicio.
Bigtable encripta de forma automática todos los datos en reposo y en tránsito. No hay opciones para inhabilitar estas funciones. Todo el acceso de administrador está completamente registrado. Puedes usar los Controles del servicio de VPC para manejar el acceso a las instancias de Bigtable desde fuera de las redes aprobadas.
¿Qué sigue?
- Lee sobre el diseño del esquema de Bigtable.
- Prueba el codelab de Bigtable para usuarios de Cassandra.
- Obtén más información sobre el emulador de Bigtable.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.