Questo documento descrive come configurare una pipeline di integrazione continua/deployment continuo (CI/CD) per l'elaborazione dei dati implementando metodi CI/CD con prodotti gestiti su Google Cloud. I data scientist e gli analisti possono adattare le metodologie delle pratiche CI/CD per contribuire a garantire un'elevata qualità, manutenibilità e adattabilità dei processi e dei flussi di lavoro dei dati. I metodi che puoi applicare sono i seguenti:
- Controllo della versione del codice sorgente.
- Creazione, test e deployment automatici delle app.
- Isolamento e separazione dell'ambiente dalla produzione.
- Procedure replicabili per la configurazione dell'ambiente.
Questo documento è rivolto a data scientist e analisti che creano job di elaborazione dati ricorrenti per contribuire a strutturare la loro ricerca e sviluppo (R&D) in modo da gestire in modo sistematico e automatico i carichi di lavoro di elaborazione dati.
Architettura
Il seguente diagramma mostra una visualizzazione dettagliata dei passaggi della pipeline CI/CD.

Le implementazioni negli ambienti di test e di produzione sono suddivise in due diverse pipeline Cloud Build: una di test e una di produzione.
Nel diagramma precedente, la pipeline di test è costituita dai seguenti passaggi:
- Uno sviluppatore esegue il commit delle modifiche al codice in Cloud Source Repositories.
- Le modifiche al codice attivano una build di test in Cloud Build.
- Cloud Build crea il file JAR autoeseguibile e lo esegue nel bucket JAR di test su Cloud Storage.
- Cloud Build esegue il deployment dei file di test nei bucket dei file di test su Cloud Storage.
- Cloud Build imposta la variabile in Cloud Composer in modo da fare riferimento al file JAR appena disegnato.
- Cloud Build testa il flusso di lavoro di elaborazione dei dati Directed Acyclic Graph (DAG) e lo esegue nel bucket Cloud Composer su Cloud Storage.
- Il file DAG del flusso di lavoro viene disegnato in Cloud Composer.
- Cloud Build attiva l'esecuzione del flusso di lavoro di elaborazione dei dati appena disegnato.
- Una volta superato il test di integrazione del flusso di lavoro di elaborazione dei dati, viene pubblicato su Pub/Sub un messaggio contenente un riferimento all'ultimo JAR autoeseguibile (ottenuto dalle variabili Airflow) nel campo dei dati del messaggio.
Nel diagramma precedente, la pipeline di produzione è costituita dai seguenti passaggi:
- La pipeline di deployment in produzione viene attivata quando un messaggio viene pubblicato in un argomento Pub/Sub.
- Uno sviluppatore approva manualmente la pipeline di deployment di produzione e la compilazione viene eseguita.
- Cloud Build copia il file JAR a esecuzione automatica più recente dal bucket JAR di test al bucket JAR di produzione su Cloud Storage.
- Cloud Build testa il DAG del flusso di lavoro di elaborazione dei dati di produzione e lo esegue nel bucket Cloud Composer su Cloud Storage.
- Il file DAG del flusso di lavoro di produzione viene disegnato in Cloud Composer.
In questo documento sull'architettura di riferimento, il flusso di lavoro di elaborazione dei dati di produzione viene implementato nello stesso ambiente Cloud Composer del flusso di lavoro di test per fornire una visione consolidata di tutti i flussi di lavoro di elaborazione dei dati. Ai fini di questa architettura di riferimento, gli ambienti sono separati utilizzando diversi bucket Cloud Storage per contenere i dati di input e output.
Per separare completamente gli ambienti, sono necessari più ambienti Cloud Composer creati in progetti diversi, che per impostazione predefinita sono separati tra loro. Questa separazione contribuisce a proteggere l'ambiente di produzione. Questo approccio esula dall'ambito di questo tutorial. Per ulteriori informazioni su come accedere alle risorse in più progetti Google Cloud, consulta Impostare le account di servizio account.
Il flusso di lavoro di elaborazione dei dati
Le istruzioni su come Cloud Composer esegue il flusso di lavoro di elaborazione dei dati sono definite in un DAG scritto in Python. Nel DAG, tutti i passaggi del flusso di lavoro di elaborazione dei dati sono definiti insieme alle dipendenze tra di loro.
La pipeline CI/CD esegue automaticamente il deployment della definizione del DAG da Cloud Source Repositories a Cloud Composer in ogni build. Questa procedura garantisce che Cloud Composer sia sempre aggiornato con la definizione del flusso di lavoro più recente senza alcun intervento umano.
Nella definizione del DAG per l'ambiente di test, viene definito un passaggio di test end-to-end oltre al flusso di lavoro di elaborazione dei dati. Il passaggio di test consente di assicurarsi che il flusso di lavoro di elaborazione dei dati funzioni correttamente.
Il flusso di lavoro di elaborazione dei dati è illustrato nel seguente diagramma.
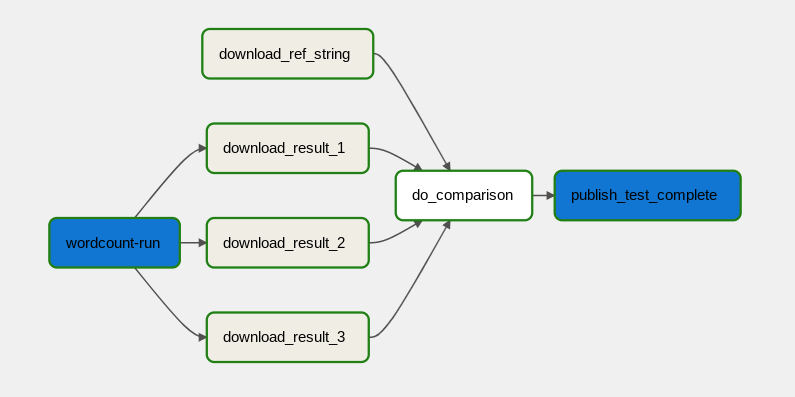
Il flusso di lavoro di elaborazione dei dati è costituito dai seguenti passaggi:
- Esegui il processo di dati WordCount in Dataflow.
Scarica i file di output dal processo di conteggio delle parole. Il processo WordCount genera tre file:
download_result_1download_result_2download_result_3
Scarica il file di riferimento, denominato
download_ref_string.Verifica il risultato rispetto al file di riferimento. Questo test di integrazione aggrega tutti e tre i risultati e li confronta con il file di riferimento.
Pubblica un messaggio in Pub/Sub dopo che il test di integrazione è stato superato.
L'utilizzo di un framework di orchestrazione delle attività come Cloud Composer per gestire il flusso di lavoro di elaborazione dei dati contribuisce ad alleviare la complessità del codice del flusso di lavoro.
Ottimizzazione dei costi
In questo documento utilizzerai i seguenti componenti fatturabili di Google Cloud:
Passaggi successivi
- Scopri di più sulla distribuzione continua in stile GitOps con Cloud Build.
- Scopri di più sui pattern dei casi d'uso comuni di Dataflow.
- Scopri di più sull'ingegneria delle release.
- Per altre architetture di riferimento, diagrammi e best practice, visita il Cloud Architecture Center.