A maioria dos balanceadores de carga usa uma abordagem de hash round-robin ou baseada em fluxo para distribuir o tráfego. Os balanceadores de carga que usam essa abordagem podem ter dificuldade de adaptação quando a demanda excede a capacidade de veiculação disponível. Neste tutorial, mostramos como o Cloud Load Balancing otimiza a capacidade global de aplicativos, resultando em uma melhor experiência do usuário e custos menores em comparação com a maioria das implementações de balanceamento de carga.
Este artigo faz parte de uma série de práticas recomendadas para produtos do Cloud Load Balancing. Este tutorial é acompanhado pelo documento Otimizações de capacidade do aplicativo com balanceamento de carga global, um artigo conceitual que explica os mecanismos subjacentes do estouro do balanceamento de carga global em mais detalhes. Para se aprofundar mais na latência, consulte Como otimizar a latência do aplicativo com o Cloud Load Balancing.
Neste tutorial, pressupomos que você tenha alguma experiência com o Compute Engine. Também é preciso conhecer os princípios básicos do balanceador de carga de aplicativo externo.
Objetivos
Neste tutorial, você configura um servidor da Web simples que executa um aplicativo com uso intenso da CPU que calcula conjuntos de Mandelbrot. Para começar, calcule a capacidade da rede usando as ferramentas de teste de carga siege e httperf (páginas em inglês). Em seguida, você escalona a rede para várias instâncias de VM em uma única região e mede o tempo de resposta sob carga. Por fim, escalona a rede para várias regiões usando o balanceamento de carga global e, em seguida, mede o tempo de resposta do servidor sob carga e o compara com o balanceamento de carga de região única. Realizar essa sequência de testes permite ver os efeitos positivos do gerenciamento de carga entre regiões do Cloud Load Balancing.
A velocidade de comunicação da rede de uma arquitetura típica de servidor de três camadas geralmente é limitada pela velocidade do servidor de aplicativos ou pela capacidade do banco de dados, e não pela carga da CPU no servidor da Web. Depois de percorrer o tutorial, use as mesmas ferramentas de teste de carga e as configurações de capacidade para otimizar o comportamento do balanceamento de carga em um aplicativo real.
Você vai:
- saber como usar as ferramentas para teste de carga (
siegeehttperf); - determinar a capacidade de veiculação de uma única instância de VM;
- medir efeitos da sobrecarga com balanceamento de carga de região única;
- medir efeitos do estouro para outra região com balanceamento de carga global.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud, entre eles:
- Compute Engine
- regras de encaminhamento e balanceamento de carga
Use a calculadora de preços para gerar uma estimativa de custo com base no uso projetado.
Antes de começar
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative a API Compute Engine.
Configurar o ambiente
Nesta seção, você define as configurações do projeto, a rede VPC e as regras de firewall básicas necessárias para concluir o tutorial.
Iniciar uma instância do Cloud Shell
Abra o Cloud Shell no Console do Google Cloud. Exceto quando observado de outra forma, você executa o restante do tutorial dentro do Cloud Shell.
Definir configurações do projeto
Para facilitar a execução de comandos gcloud, defina propriedades para que você não precise fornecer opções para essas propriedades com cada comando.
Defina o projeto padrão usando o código do projeto de
[PROJECT_ID]:gcloud config set project [PROJECT_ID]
Defina a zona padrão do Compute Engine usando a zona preferida para
[ZONE]e depois a defina como uma variável de ambiente para uso posterior:gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
Criar e configurar a rede VPC
Crie uma rede VPC para teste:
gcloud compute networks create lb-testing --subnet-mode auto
Defina uma regra de firewall para permitir tráfego interno:
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11Defina uma regra de firewall para permitir que o tráfego SSH se comunique com a rede VPC:
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
Como determinar a capacidade de exibição de uma única instância de VM
Para examinar as características de desempenho de um tipo de instância de VM, você fará o seguinte:
Configure uma instância de VM que exiba a carga de trabalho de exemplo (a instância do servidor da Web).
Crie uma segunda instância de VM na mesma zona (a instância de teste de carga).
Com a segunda instância de VM, você medirá o desempenho usando ferramentas simples de teste de carga e de medição de desempenho. Você usará essas medições posteriormente no tutorial para ajudar a definir a configuração correta da capacidade de balanceamento de carga para o grupo de instâncias.
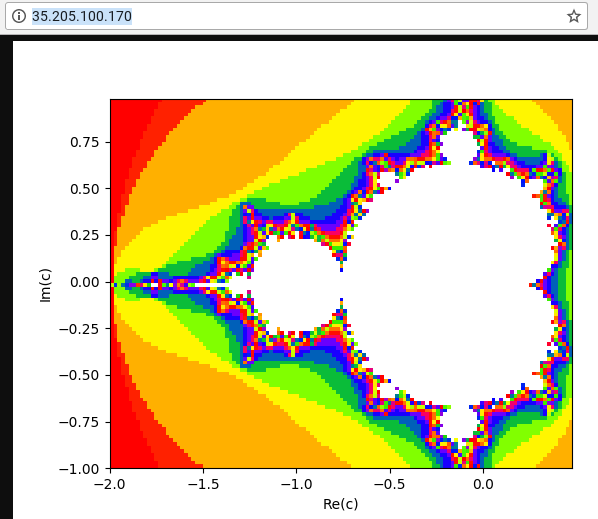
A primeira instância de VM usa um script Python para criar uma tarefa intensiva de CPU calculando e exibindo uma imagem de um conjunto de Mandelbrot em cada solicitação para o caminho raiz (/). O resultado não é armazenado em cache. Durante o tutorial, você consegue o script Python no repositório do GitHub usado nesta solução.
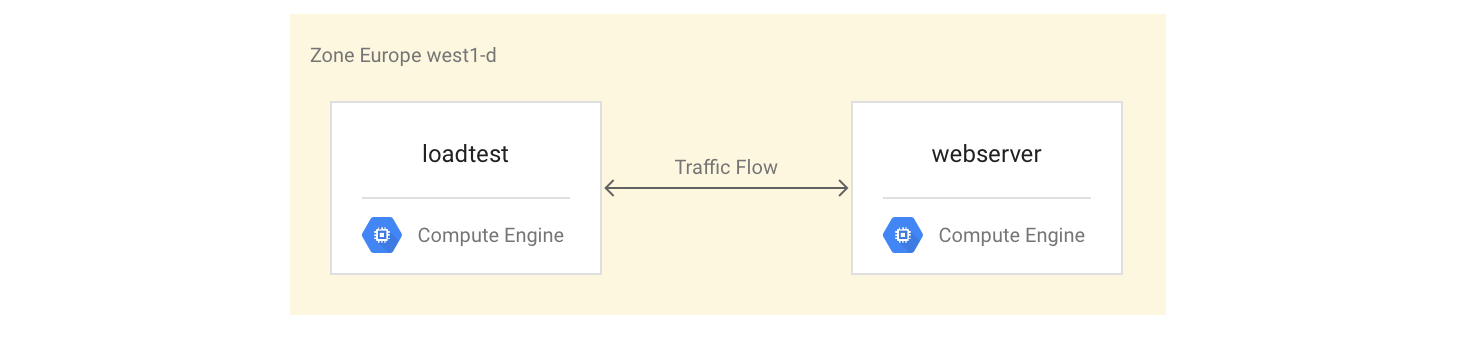
Como configurar as instâncias de VM
Configure a instância de VM
webservercomo uma instância de VM de quatro núcleos instalando e iniciando o servidor Mandelbrot:gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-10 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Crie uma regra de firewall para permitir acesso externo à instância
webserverda sua própria máquina:gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverConsiga o endereço IP da instância
webserver:gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"Em um navegador da Web, acesse o endereço IP retornado pelo comando anterior. Você vê um conjunto de Mandelbrot calculado:
Crie a instância de teste de carga:
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-10 \ --image-project=debian-cloud
Como testar as instâncias de VM
A próxima etapa é executar solicitações para avaliar as características de desempenho da instância de VM do teste de carga.
Use o comando
sshpara se conectar à instância de VM para teste de carga:gcloud compute ssh loadtest
Na instância de teste de carga, instale o siege e httperf (links em inglês) como as ferramentas do teste de carga:
sudo apt-get install -y siege httperf
A ferramenta
siegepermite simular solicitações de um número especificado de usuários, fazendo solicitações subsequentes apenas depois que os usuários receberam uma resposta. Isso dá insights sobre a capacidade e os tempos de resposta esperados para aplicativos em um ambiente real.A ferramenta
httperfpermite enviar um número específico de solicitações por segundo, independentemente do recebimento de respostas ou erros. Isso dá insights sobre como aplicativos respondem a uma carga específica.Cronometre uma solicitação simples para o servidor da Web:
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserverVocê recebe uma resposta como 0,395260. Isso significa que o servidor demorou 395 milissegundos (ms) para responder à solicitação.
Use o seguinte comando para executar 20 solicitações de quatro usuários em paralelo:
siege -c 4 -r 20 webserver
Você verá uma saída semelhante a esta:
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
A saída é explicada totalmente no manual de siege, mas é possível ver neste exemplo que os tempos de resposta variaram entre 0,37 s e 0,7 s. Em média, 5,05 solicitações por segundo foram respondidas. Esses dados ajudam a estimar a capacidade de veiculação do sistema.
Execute os seguintes comandos para validar as descobertas usando a ferramenta para teste de carga
httperf:httperf --server webserver --num-conns 500 --rate 4
Esse comando executa 500 solicitações na taxa de 4 solicitações por segundo, o que é menor que as 5,05 transações por segundo que
siegecompletou.Você verá uma saída semelhante a esta:
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
A saída é explicada no arquivo httperf README. Observe a linha que começa com
Connection time [ms], que mostra que as conexões demoraram entre 369,6 e 487,8 ms no total e não geraram erros.Repita o teste três vezes, definindo a opção
ratecomo cinco, sete e dez solicitações por segundo.Os blocos a seguir mostram os comandos
httperfe a saída deles (mostrando apenas as linhas relevantes com informações do tempo de conexão).Comando para cinco solicitações por segundo:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
Resultados para cinco solicitações por segundo:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Comando para sete solicitações por segundo:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
Resultados para sete solicitações por segundo:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Comando para 10 solicitações por segundo:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
Resultados para 10 solicitações por segundo:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Saia da instância
webserver:exit
É possível concluir a partir dessas medições que o sistema tem uma capacidade de aproximadamente cinco solicitações por segundo (RPS, na sigla em inglês). Com cinco solicitações por segundo, a instância de VM reage com uma latência comparável a quatro conexões. Com sete e dez conexões por segundo, o tempo médio de resposta aumenta drasticamente para mais de dez segundos com vários erros de conexão. Em outras palavras, tudo o que excede a cinco solicitações por segundo causa lentidões significativas.
Em um sistema mais complexo, a capacidade do servidor é determinada de maneira semelhante, mas depende muito da capacidade de todos os componentes. Use as ferramentas siege e httperf com o monitoramento de carga de CPU e E/S de todos os componentes (por exemplo, o servidor front-end, o servidor de aplicativos e o servidor de banco de dados) para ajudar a identificar gargalos. Isso, por sua vez, ajuda a ativar o escalonamento ideal para cada componente.
Como medir efeitos de sobrecarga com um balanceador de carga de região única
Nesta seção, você examina os efeitos de sobrecarga em balanceadores de carga de região única, como balanceadores de carga típicos usados no local ou o balanceador de carga de rede do Google Cloud. Também é possível observar esse efeito com um balanceador de carga HTTP(S) quando ele é usado em uma implantação regional (em vez de global).
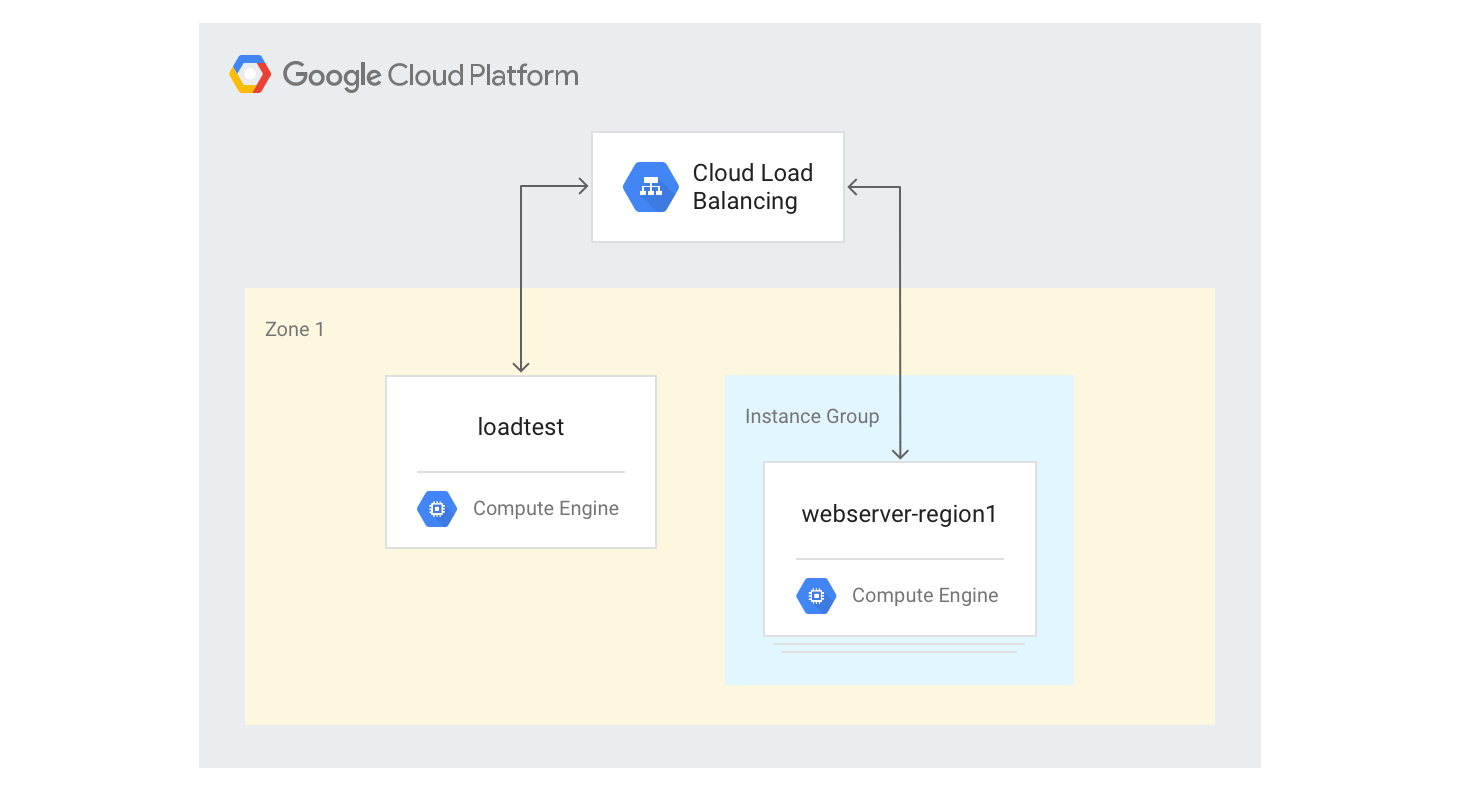
Como criar o balanceador de carga HTTP(S) de região única
Nas etapas a seguir, descrevemos como criar um balanceador de carga HTTP(S) de região única com um tamanho fixo de três instâncias de VM.
Crie um modelo de instância para as instâncias de VM do servidor da Web usando o script Python de geração de Mandelbrot usado anteriormente. Execute os comandos a seguir no Cloud Shell:
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-10 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Crie um grupo de instâncias gerenciadas com três instâncias com base no modelo da etapa anterior:
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversCrie a verificação de integridade, o serviço de back-end, o mapa de URLs, o proxy de destino e a regra de encaminhamento global necessários para gerar o balanceamento de carga HTTP:
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80Consiga o endereço IP da regra de encaminhamento:
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
A saída é o endereço IP público do balanceador de carga criado por você.
Em um navegador, acesse o endereço IP retornado pelo comando anterior. Depois de alguns minutos, você verá a mesma imagem de Mandelbrot vista anteriormente. No entanto, desta vez, a imagem é veiculada a partir de uma das instâncias de VM no grupo recém-criado.
Faça login na máquina
loadtest:gcloud compute ssh loadtest
Na linha de comando da máquina
loadtest, teste a resposta do servidor com diferentes números de solicitações por segundo (RPS). Certifique-se de usar valores de RPS no intervalo entre 5 e 20.Por exemplo, o comando a seguir gera 10 RPS. Substitua
[IP_address]pelo endereço IP do balanceador de carga de uma etapa anterior deste procedimento.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
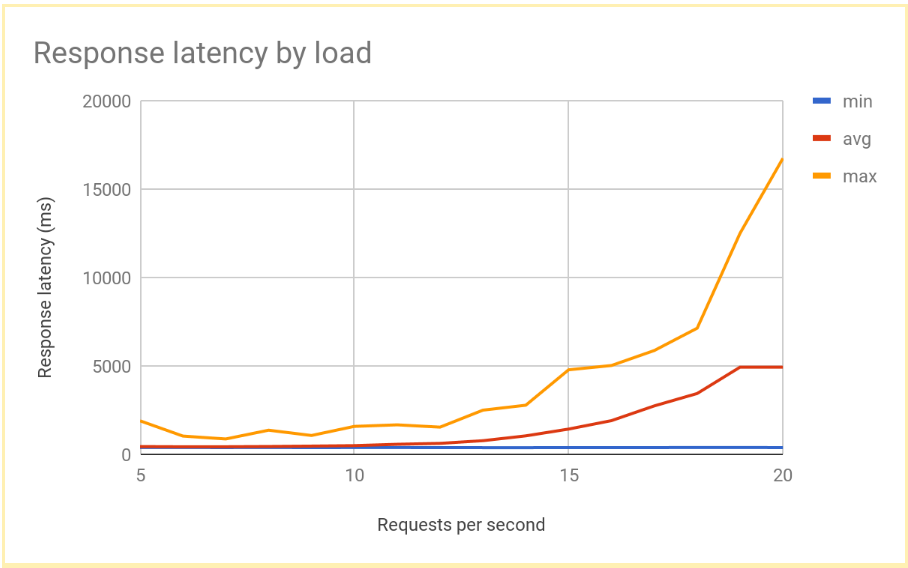
A latência de resposta aumenta significativamente à medida que o número de RPS passa 12 ou 13 RPS. Aqui está uma visualização dos resultados típicos:
Saia da instância de VM
loadtest:exit
Esse desempenho é típico de um sistema com balanceamento de carga regional. À medida que a carga passa a capacidade de veiculação, a média e a latência máxima de solicitação aumentam rapidamente. Com 10 RPS, a latência média da solicitação é próxima de 500 ms, mas com 20 RPS a latência é de 5.000 ms. A latência aumentou 10 vezes, e a experiência do usuário se deteriora rapidamente, o que leva o usuário a sair ou a tempos limite de aplicativos, ou ambos.
Na próxima seção, você adicionará uma segunda região à topologia de balanceamento de carga e comparará como o failover entre regiões afeta a latência do usuário final.
Como medir efeitos de estouro para outra região
Se você usar um aplicativo global com um balanceador de carga de aplicativo externo e tiver back-ends implantados em várias regiões, quando ocorrer sobrecarga de capacidade em uma única região, o tráfego fluirá automaticamente para outra região. Valide isso adicionando um segundo grupo de instâncias de VM em outra região à configuração criada na seção anterior.
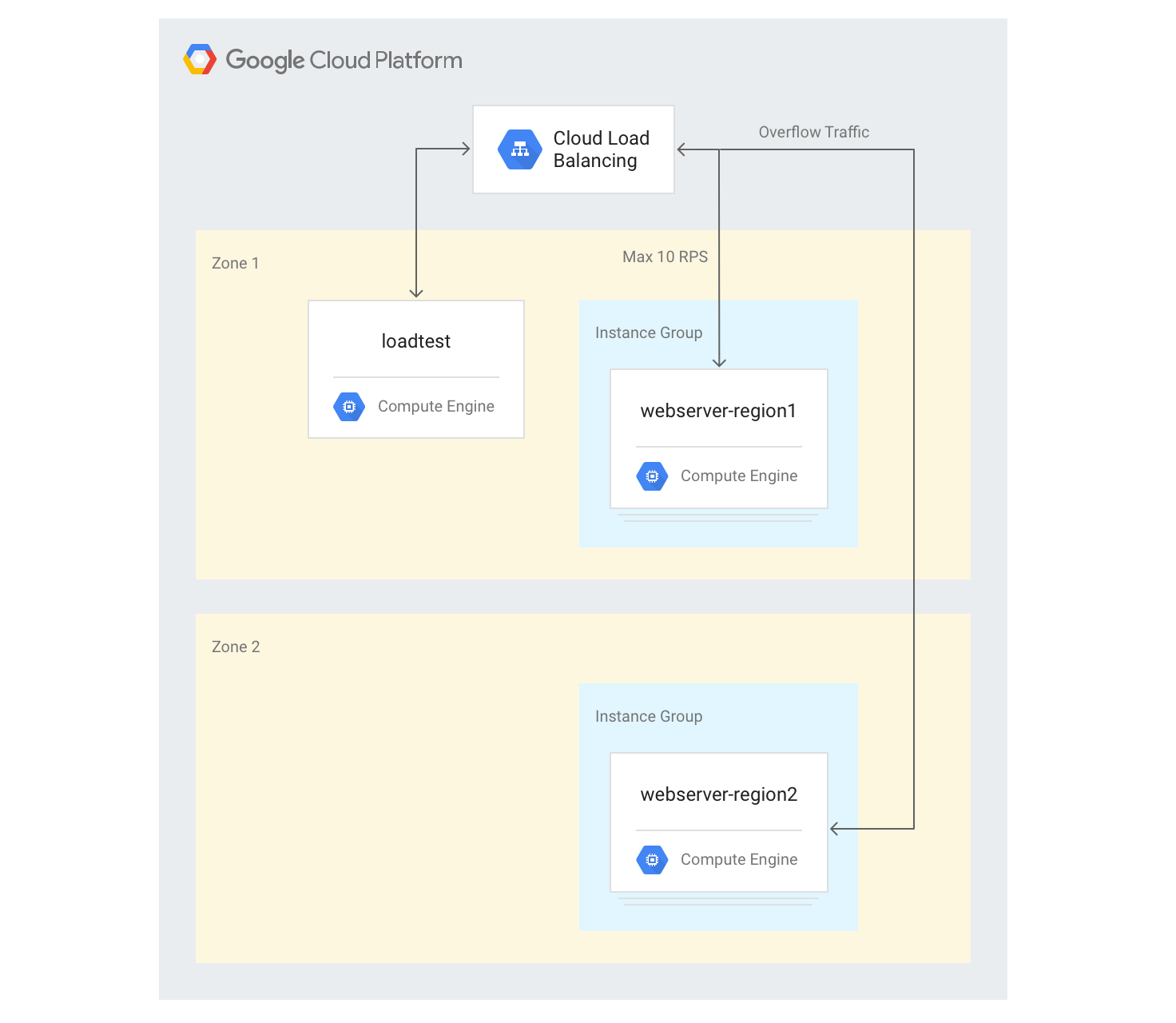
Como criar servidores em várias regiões
Nas etapas a seguir, você adicionará outro grupo de back-ends em outra região e atribuirá uma capacidade de 10 RPS por região. Em seguida, é possível ver como o balanceamento de carga reage quando esse limite é excedido.
No Cloud Shell, escolha uma zona em uma região diferente da zona padrão e a defina como uma variável de ambiente:
export ZONE2=[zone]
Crie um novo grupo de instâncias na segunda região com três instâncias de VM:
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2Adicione o grupo de instâncias ao serviço de back-end existente com uma capacidade máxima de 10 RPS:
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10Ajuste
max-ratepara 10 RPS para o serviço de back-end existente:gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10Depois que todas as instâncias forem inicializadas, faça login na instância de VM
loadtest:gcloud compute ssh loadtest
Execute 500 solicitações a 10 RPS. Substitua
[IP_address]pelo endereço IP do balanceador de carga:httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
Você verá resultados como estes:
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
Os resultados são semelhantes aos produzidos pelo balanceador de carga regional.
Como a ferramenta de teste executa imediatamente uma carga completa e não aumenta lentamente a carga como uma implementação real, você precisa repetir o teste algumas vezes para que o mecanismo de estouro entre em vigor. Execute 500 solicitações 5 vezes a 20 RPS. Substitua
[IP_address]pelo endereço IP do balanceador de carga:for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; doneVocê verá resultados como estes:
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
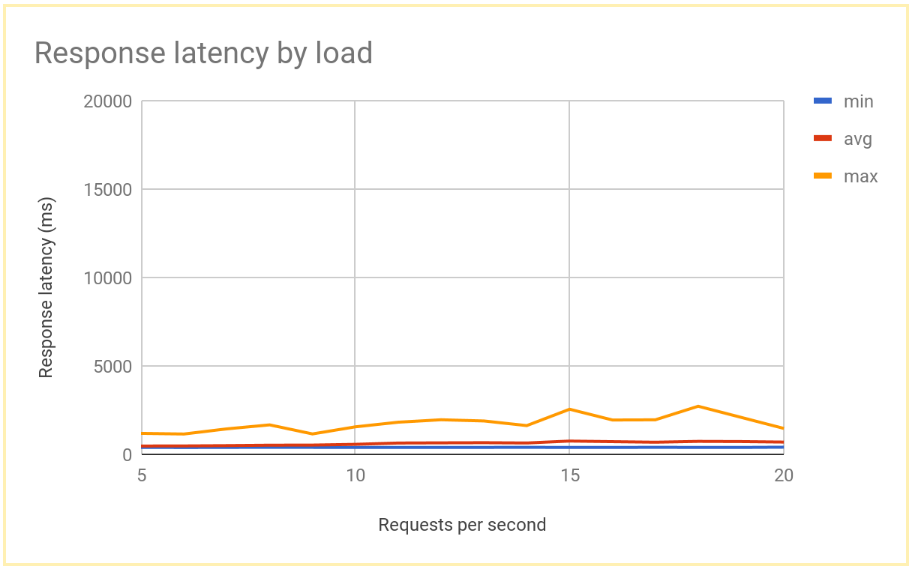
Depois que o sistema se estabiliza, o tempo médio de resposta é de 400 ms a 10 RPS e só aumenta para 700 ms a 20 RPS. Isso é uma grande melhoria em relação ao atraso de 5.000 ms oferecido por um balanceador de carga regional e resulta em uma experiência de usuário muito melhor.
O gráfico a seguir mostra o tempo de resposta medido pelo RPS usando-se o balanceamento de carga global:
Como comparar resultados do balanceamento de carga regional e global
Depois de estabelecer a capacidade de um único node, compare a latência observada por usuários finais em uma implantação baseada na região com a latência em uma arquitetura de balanceamento de carga global. O número de solicitações em uma única região é menor que a capacidade de veiculação total nessa região, mas os dois sistemas têm uma latência de usuário final semelhante porque os usuários sempre são redirecionados para a região mais próxima.
Quando a carga para uma região ultrapassa a capacidade de exibição dessa região, a latência do usuário final muda significativamente entre as soluções:
Soluções de balanceamento de carga regional são sobrecarregadas quando o tráfego ultrapassa a capacidade porque o tráfego não pode fluir para outro lugar, exceto para as instâncias de VM de back-end sobrecarregadas. Isso inclui balanceadores de carga locais tradicionais,Balanceadores de carga de rede de passagem externa no Google Cloud e Balanceadores de carga de aplicativos externos em uma única configuração de região (por exemplo, usando rede Nível padrão). As latências de solicitação médias e máximas aumentam mais do que dez vezes, levando a experiências do usuário precárias. Isso, por sua vez, pode levar a uma desistência significativa de usuários.
Os balanceadores de carga de aplicativo externos globais com back-ends em várias regiões permitem que o tráfego transborde para a região mais próxima com capacidade de disponibilização disponível. Isso leva a um aumento mensurável, mas comparativamente baixo, na latência do usuário final e oferece uma experiência do usuário muito melhor. Se o aplicativo não conseguir escalonar horizontalmente em uma região com rapidez suficiente, o balanceador de carga de aplicativo externo global é a opção recomendada. Mesmo durante a falha em toda a região dos servidores de aplicativos do usuário, o tráfego é redirecionado rapidamente para outras regiões e ajuda a evitar uma interrupção total do serviço.
Limpeza
Exclua o projeto
O jeito mais fácil de evitar cobranças é excluir o projeto que você criou para o tutorial.
Para excluir o projeto:
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
As páginas a seguir fornecem mais informações e um plano de fundo sobre as opções de balanceamento de carga do Google:
- Como otimizar a latência do aplicativo com o Cloud Load Balancing
- Codelab Networking 101
- Balanceador de carga de rede de passagem externo
- Balanceador de carga de aplicativo externo
- Balanceador de carga de rede de proxy externo