本文档介绍调节 Google Cloud 资源以实现消息传递接口 (MPI) 最优性能的最佳做法。紧密耦合的高性能计算 (HPC) 工作负载通常使用 MPI 在进程和实例之间进行通信。正确调节底层系统和网络基础架构是实现 MPI 最优性能的关键所在。如果您在 Google Cloud 中运行基于 MPI 的代码,请使用这些做法以获得最优性能。
假设和要求
通常,Slurm 或 HTCondor 等工作负载调度器用于管理实例。本文档中的建议和最佳做法适用于所有调度器和工作流管理器。
具体如何使用各种调度器或工作流工具实现这些最佳做法不在本文档的探讨范围之内。实现工具以及这些工具的使用准则在其他文档和教程中提供。
本文档中提供的准则属于通用性质,可能并不适用于所有应用。我们建议您对应用进行基准测试,以便找到最高效或最具成本效益的配置。
使用 Bash 或 Ansible 脚本应用配置
Google 允许您使用 Bash 脚本或 Ansible 脚本(可在 Cloud MPI 代码库中找到)在 Compute Engine 实例上应用这些优化和最佳实践。
使用预先配置的 HPC 虚拟机映像
您可以使用基于 MPI 和紧密耦合的工作负载进行优化的 HPC 虚拟机 (VM) 映像(基于 CentOS 或 Rocky Linux),而不是手动应用本文档中介绍的最佳做法。HPC 虚拟机映像打包了这些最佳做法,并通过 Google Cloud Marketplace 免费提供。如需了解详情,请参阅创建支持 HPC 的虚拟机实例。
Compute Engine 配置
本部分介绍使应用实现最优计算性能的最佳做法。在系统中使用正确的机器类型和设置会对 MPI 性能产生重大影响。
使用紧凑放置政策
通过放置政策,您可以控制虚拟机在数据中心的放置。紧凑放置政策可以为单个可用性区域中的虚拟机放置提供低延迟拓扑。当前 API 可让您创建最多 150 个经过计算优化(C2、C2D 或 H3)的虚拟机,这些虚拟机的物理位置彼此接近。如果您需要超过 150 个虚拟机,请将虚拟机划分为多项放置政策。我们建议您使用满足工作负载要求的最低放置政策数量。
如需使用放置政策,请首先在给定区域创建与所需数量的虚拟机搭配的放置政策:
gcloud compute resource-policies create group-placement \ PLACEMENT_POLICY_NAME \ --collocation=collocated \ --vm-count=NUMBER_OF_VMs
然后使用该政策在所需可用区创建虚拟机:
gcloud compute instances create
INSTANCE1 INSTANCE2 INSTANCEn
--zone=us-central1-a --resource-policies=PLACEMENT_POLICY_NAME
--maintenance-policy=TERMINATE
某些情况下,您可能无法直接控制虚拟机的创建方式。例如,您可以使用一些未集成的第三方工具来创建虚拟机。如需将放置政策应用于现有虚拟机,请完成以下步骤:
停止要应用放置政策的虚拟机:
gcloud compute instances stop \ INSTANCE1 INSTANCE2 INSTANCEn
通过更新每个虚拟机的可用性政策,将虚拟机配置为在主机维护期间终止,并且在发生故障时不自动重启:
gcloud compute instances set-scheduling INSTANCE_NAME \ --maintenance-policy TERMINATE --no-restart-on-failure
应用放置政策:
gcloud compute instances add-resource-policies \ INSTANCE1 INSTANCE2 INSTANCEn \ --zone=us-central1-a --resource-policies=PLACEMENT_POLICY_NAME
使用计算优化实例
我们建议您使用 C2、C2D 或 H3 虚拟机运行 HPC 应用。这些虚拟机具有虚拟核心到物理核心的固定映射,并向客机操作系统公开 NUMA 单元架构,这两种特性对于紧密耦合的 HPC 应用性能至关重要。
H3 虚拟机由两个第 4 代 Intel Xeon 可扩展处理器 (Sapphire Rapids) 提供支持,具有总计 88 个核心、最高 352 GB 的 DDR5 内存,以及 3.0 GHz 的全核频率。这些虚拟机使用 Google 的自定义 Intel Infrastructure Processing Engine (IPU) 来提高网络性能。H3 虚拟机提供一种大小(88 个虚拟核心或 vCPU),该虚拟机由整个主机服务器组成,支持高达 200 Gbps 的网络吞吐量。为了确保最佳的性能一致性,H3 虚拟机的 CPU 不会过度使用。
C2 虚拟机最多可拥有 60 个 vCPU(30 个物理核心)和 240 GB RAM。它们还可以拥有高达 3 TiB 的本地 SSD 存储空间,并支持高达 100 Gbps 的网络吞吐量。C2 实例还利用第 2 代 Intel Xeon 可扩缩处理器 (Cascade Lake),与其他实例类型相比,可提供更多内存带宽和更高的时钟速度(高达 3.8 GHz)。C2 实例的性能通常比 N1 实例类型高达 40%。
C2D 虚拟机基于第 3 代 AMD EPYC Milan。与 C2 虚拟机相比,C2D 虚拟机利用了来自 AMD (Milan) 的处理器架构的进步、更高的 CPU 频率、更大的 L3 缓存、CCX 架构以及更高的内存带宽。C2D 虚拟机具有以下规范:
- 最多 112 个 vCPU(56 个核心)
- 高达 448 GB 内存
- 高达 3 TiB 本地 SSD 存储空间
- 每个虚拟机层级 1 网络性能支持高达 100 Gbps 的网络吞吐量。
为了减少机器之间的通信开销,我们建议您将工作负载整合到数量较少的 c2-standard-60、c2d-standard-112 或 h3-standard-88 虚拟机(总核心数相同)中,而不是启动数量更大的小型 C2、C2D 或 H3 虚拟机。
停用并发多线程
一些 HPC 应用通过在客机操作系统中停用并发多线程 (SMT) 来提高性能。并发多线程(也称为 Intel 超线程)会为节点上的每个物理核心分配两个 vCPU。对于许多常规计算任务或需要大量 I/O 的任务来说,SMT 可以显著提高应用吞吐量。对于两个虚拟核心均受计算限制的计算限制型作业来说,SMT 可能会影响应用的总体性能,并可能会增加作业的不可预测性。关闭 SMT 有助于使性能更具可预测性,并且可以减少作业时间。
对于所有虚拟机类型,您都可以在创建虚拟机时停用 SMT,但存在以下例外情况:
H3 虚拟机默认停用 SMT,您无法启用它。
在 vCPU 数量少于 2 个的机器类型(例如
n1-standard-1)或共享核心机器(例如e2-small)上运行的虚拟机。在 Tau T2D 机器类型上运行的虚拟机。
如需在创建虚拟机时停用 SMT,请在命令中添加设置为 1 的 --threads-per-core 标志,例如:
gcloud beta compute instances create VM_NAME
--zone=ZONE
--machine-type=MACHINE_TYPE
--threads-per-core=1
如需了解详情,请参阅有关配置并发多线程的文档。
调整用户限制
Unix 系统对系统资源(例如开放文件和任何用户可以使用的进程数量)进行了默认限制。这些限制可防止一个用户独占系统资源并影响其他用户工作。但是,HPC 环境中通常没有必要进行这些限制,因为用户之间不会直接共享集群中的计算节点。
您可以通过修改 /etc/security/limits.conf 文件并再次登录到节点来调整用户限制。如果是自动操作,您可以将这些更改引入虚拟机映像中,或在部署时通过使用 Deployment Manager、Terraform 或 Ansible 等工具调整限制。
调整用户限制时,请更改以下限制的值:
nproc- 进程数上限memlock- 最大锁定内存地址空间 (KB)stack- 堆栈大小上限 (KB)nofile- 最大打开文件数cpu- 最大 CPU 时间(分钟)rtprio- 非特权进程允许的最大实时优先级(Linux 2.6.12 及更高版本)
这些限制在大多数 Unix 和 Linux 系统(包括 Debian,CentOS、Rocky Linux 和 Red Hat)的 /etc/security/limits.conf 系统配置文件中进行配置。
如需更改用户限制,请使用文本编辑器更改以下值:
在
/etc/security/limits.conf中:* - nproc unlimited * - memlock unlimited * - stack unlimited * - nofile 1048576 * - cpu unlimited * - rtprio unlimited在
/etc/security/limits.d/20-nproc.conf中:* - nproc unlimited
启用可用区收回模式
可用区收回模式允许任何人设置在可用区内存不足时回收内存的积极方法。如果模式设置为零,则不会发生可用区收回。在这种情况下,系统会从系统的其他可用区或节点分配。
超出 NUMA 节点内存的作业以及扩展到 NUMA 节点之外的多核作业可以从启用可用区收回模式中受益。我们建议您将此值设置为 1。
sudo sysctl vm.zone_reclaim_mode=1
启用透明的大型页面
HPC 应用通常受益于透明的大型页面。
要启用透明的大型页面,请使用以下命令:
echo ‘always’ > /sys/kernel/mm/transparent_hugepage/enabled
echo ‘always’ > /sys/kernel/mm/transparent_hugepage/defrag
停用自动 NUMA 平衡
按操作系统自动进行 NUMA 平衡可能会产生开销,因此不建议用于 MPI 应用。
要停用自动 NUMA 平衡,请使用以下命令:
sudo sysctl kernel.numa_balancing=0
设置 SSH 主机密钥
Intel MPI 要求执行 mpirun 的节点的 ~/.ssh/known_hosts 文件中提供所有集群节点的主机密钥。您还必须将 SSH 密钥保存在 authorized_keys 中。
如需添加主机密钥,请运行以下命令:
ssh-keyscan -H 'cat HOSTFILE' >> ~/.ssh/known_hosts
另一种方法是运行以下命令,将 StrictHostKeyChecking=no 添加到 ~/.ssh/config 文件中:
Host *
StrictHostKeyChecking no
使用 Google 虚拟 NIC (gVNIC)
使用 Google 虚拟 NIC (gVNIC) 而非 Virtio-net 可以通过提供更好的通信性能和更高的吞吐量来提高 MPI 应用的可扩缩性。此外,gVNIC 是使用每个虚拟机 Tier_1 网络性能的虚拟机的前提条件。当您创建新虚拟机时,Virtio-net 是第一代或第二代机器系列(例如 C2 或 C2D)的默认虚拟网络接口。第三代机器系列(例如 C3 和 H3)仅使用 gVNIC 网络接口。如需了解如何为第一代和第二代机器系列启用 gVNIC,请参阅使用 Google 虚拟 NIC。
使用巨型帧
Virtual Private Cloud (VPC) 网络的默认最大传输单元 (MTU) 为 1460 字节。您可以将 VPC 网络配置为具有不同的 MTU,最高为 8896(巨型帧)。但是,只有在源接口和目标接口位于同一子网中并且使用子网主要 IPv4 范围内的内部 IPv4 地址进行通信时,才能使用大于 1600 的 MTU。
HPC 应用可以从使用巨型帧进行内部通信或访问并行文件系统中获益。为了帮助最大限度地减少网络数据包的处理开销,我们建议使用较大的数据包大小。您需要根据应用的具体情况验证较大的数据包大小。如需了解如何使用巨型帧和数据包大小,请参阅最大传输单元指南。
存储
许多 HPC 应用的性能主要取决于底层存储系统的性能。对于读取或写入大量数据或者创建或访问多个文件或对象的应用来说尤其如此。当多个等级同时访问存储系统时也是如此。
选择 NFS 文件系统或并行文件系统
以下是紧密耦合应用的主要存储方案。 每种方案都有自己的费用、性能配置文件、API 和一致性语义:
- 基于 NFS 的解决方案(如 Filestore 和 NetApp Cloud Volumes)是部署共享存储方案的最简单方式。这两种方案都在 Google Cloud 上完全代管,在以下情况下为最佳方案:当应用对单个数据集没有极致的 I/O 要求,并且在应用执行期间和更新期间计算节点之间没有数据共享时。如需了解性能限制,请参阅 Filestore 和 NetApp Cloud Volumes 文档。
- MPI 应用较常使用基于 POSIX 的并行文件系统。基于 POSIX 的方案包含开源 Lustr和完全受支持的 Luster 产品 DDN Storage EXAScaler Cloud。计算节点生成和共享数据时,它们通常依赖并行文件系统提供的极致性能,并支持完整的 POSIX 语义。Luster 等并行文件系统将数据传送到最大的超级计算机,并且可以支持数千个客户端。Luster 还支持 NetCDF 和 HDF5 等数据和 I/O 库,以及 MPI-IO,支持将并行 I/O 应用于一系列广泛的应用领域。
选择存储基础架构
您应根据应用性能要求选择文件系统的存储基础架构或存储层级。例如,如果您为不需要每次 I/O 操作次数 (IOPS) 很高的应用部署 SSD,则可能会增加成本,但收效不大。
代管式存储服务 Filestore 和 NetApp Cloud Volumes 提供几个根据容量进行扩缩的性能层级。
为了确定适合开源 Lustre 或 DDN Storage EXAScaler Cloud 的正确基础架构,您必须先了解使用标准永久性磁盘、SSD 永久性磁盘或本地 SSD 实现所需性能需要的 vCPU 和容量。如需详细了解如何确定正确的基础架构,请参阅块存储性能信息和优化永久性磁盘性能。例如,如果您使用 Luster,则可以通过用于元数据服务器 (MDS) 的 SSD 永久性磁盘和用于存储服务器 (OSS) 的标准永久性磁盘部署低成本、高带宽的解决方案。
网络设置
对于许多 HPC 应用而言,MPI 网络性能至关重要。对于 MPI 进程在不同节点上频繁通信或具有大量数据的紧密耦合应用来说,尤其如此。本部分介绍调节网络设置以实现最优 MPI 性能的最佳做法。
提高 tcp_*mem 设置
C2 和 C2D 虚拟机最多支持 32 Gbps 带宽(不包括 Tier_1 网络)。H3 虚拟机不使用 Tier_1 网络时,可达到高达 200 Gbps 的带宽。因此,这三种类型的虚拟机的带宽用量需要比 Linux 启用的默认带宽设置更多的 TCP 内存。
为提高网络性能,请提高 tcp_mem 值。
如需提高 TCP 内存限制,请在 /etc/sysctl.conf 中更新以下值:
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
如需在 /etc/sysctl.conf 中加载新值,请运行 sysctl -p。
使用网络配置文件
您可以使用与应用相应的网络配置文件来提高某些应用的性能。某些对网络延迟敏感的应用可以通过启用频繁轮询来改进。频繁轮询通过允许套接字层代码轮询网络设备的接收队列并停用网络中断,帮助减少网络接收路径中的延时。评估应用的延迟时间,以查看频繁轮询是否有所帮助。
网络延时配置文件会在重新启动后依然存在。如果您的系统已安装 tuned-adm,您可以通过运行以下命令启用低网络延时配置文件:
tuned-adm profile network-latency
如果您的系统未安装 tuned-adm,您可以通过将以下内容添加到 /etc/sysctl.conf 来启用频繁轮询:
net.core.busy_poll = 50
net.core.busy_read = 50
如需在 /etc/sysctl.conf 中加载新值,请运行 sysctl -p。
如果您的应用发送大型数据包并且它对带宽敏感,您可以使用以下命令启用网络吞吐量配置文件:
tuned-adm profile network-throughput
MPI 库和用户应用
最佳做法:
使用 Intel MPI使用 mpitune 执行 MPI Collective 调节
使用 MPI/OpenMP 混合模式
使用矢量指令和 Math Kernel Library 编译应用
使用适当的 CPU 编号
使用 Open MPI
MPI 库设置和 HPC 应用配置会影响应用性能。为了使 HPC 应用具有最佳性能,请务必微调这些设置或配置。本部分介绍在 Google Cloud 上运行 MPI 库和用户应用的最佳做法。
使用 Intel MPI
为了获得最优性能,我们建议您使用 Intel MPI 2021。
Google 提供了 google-hpc-compute 实用程序,以使 HPC MPI 工作负载具有较高的性能且易于在 Google Cloud 环境中运行。google-hpc-compute 实用程序适用于 EL7 和 EL8 发行版,包括 Rhel 7、CentOS 7、Rhel 8 和 Rocky Linux 8。google_install_impi 脚本提供了用于设置 IntelMPI 2021 的命令。
获取 google-hpc-compute 实用程序
google-hpc-compute 实用程序附带 HPC-CentOS-7 映像和 HPC-RL8-VM 映像。使用 HPC 虚拟机映像的新创建的虚拟机实例附带了该实用程序。
使用以下任一方法获取现有虚拟机实例上的实用程序:
使用 HPC-CentOS-7 映像创建的现有虚拟机实例。您可以通过发出以下命令来更新现有
google-hpc-compute实用程序:sudo yum update -y google-hpc-compute
使用 EL7/EL8 映像创建的现有虚拟机实例。 虽然我们建议您使用 HPC 虚拟机映像在 Google Cloud 上运行 HPC MPI 工作负载,但您可以通过使用以下命令添加
google-hpc-compute-el7-x86_64代码库来访问google-hpc-compute实用程序:cat > /etc/yum.repos.d/google-hpc-compute.repo << EOF [google-hpc-compute] name=Google HPC Compute baseurl=https://packages.cloud.google.com/yum/repos/google-hpc-compute-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=0 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOFgoogle-hpc-compute-el7-x86_64代码库位于虚拟机中后,您可以使用以下命令下载google-hpc-compute实用程序:sudo yum install -y google-hpc-compute
使用 google-hpc-compute 实用程序来支持 IntelMPI 2021
google_install_intelmpi 工具会安装 IntelMPI 2021.8 库。安装库时,请设置以下标志:
--install_dir <var>install_path</var>:配置安装的前缀目录。默认位置是/opt/intel。--impi_2021:安装 Intel MPI 2021.8,这是在 Google Cloud 上运行 MPI 作业的推荐版本。
该实用程序需要 sudo 模式才能安装 IntelMPI 库。
该命令会在 install_dir 目录中安装 MPI 库。
如需找到 MPI 库,请使用以下命令:
source install_path/mpi/latest/env/vars.sh
使用 mpitune 进行 MPI Collective 调节
MPI 实现有许多内部配置参数,它们与 MPI Collective 通信性能特别相关。IntelMPI 可让您根据 Google Cloud 环境指定算法和配置参数。
在 IntelMPI 2021 中,有一些内置调节配置参数通常适用于 Google Cloud 环境。您可以根据已部署的集群环境和应用特征生成自定义调节配置参数。根据 Intel 官方指南,我们建议使用 mpitune 或 mpitune_fast 实用程序生成自定义调节配置文件。
使用矢量指令和 Math Kernel Library 编译应用
C2 虚拟机支持 AVX2, AVX512 矢量指令。您可以使用 AVX 指令对许多 HPC 应用进行编译,从而提高其性能。如果使用 AVX2 而不是 AVX512,则某些应用的性能会更好。我们建议您针对工作负载尝试这两种类型的 AVX 指令。为了获得更好的科学计算性能,我们还建议您使用 Intel Math Kernel Library (Intel MKL)。
我们建议使用 Intel 编译器为 C2 实例构建 MPI 二进制文件。
AMD 特定优化
本部分包含针对基于 AMD 的系统的建议。
AMD 编译器/工具链
AMD 优化 CPU 编译器 (AOCC) 是一种高性能、生产级质量的代码生成工具,为构建和优化 C、C++ 的开发者提供各种选项,以及针对 32 位和 64 位 Linux 平台的 Fortran 应用。我们建议使用 AOCC 编译 C2D 中的 HPC 应用。使用 -march=znver3 标志生成在第 3 代 AMD EPYC 系列 CPU 上运行的指令。您还可以在使用 gcc 工具进行编译时使用相同的标志。
矢量指令和 Math Kernel Library
C2D 虚拟机支持矢量指令 (AVX2)。我们发现,在使用 AVX2 指令进行编译时,许多 HPC 应用的性能有显著提升。我们建议您使用根据这些说明进行优化的 AMD Google 虚拟 NIC (gVNIC) (BLIS)。
链接到 Intel Math Kernel Library 的应用可能无法利用 AMD EPYC 上的 AVX2。
使用 MPI OpenMP 混合模式
许多 MPI 应用都支持混合模式,您可以使用该模式在 MPI 应用中启用 OpenMP。在混合模式下,每个 MPI 进程都可以使用固定数量的线程来加快某些循环结构的执行。
如果您想优化应用性能,建议您使用混合模式选项。使用混合模式可以降低每个虚拟机的 MPI 进程,从而减少进程间通信并缩短总通信时间。
启用混合模式还是 OpenMP 取决于应用。许多情况下,您可以通过设置以下环境变量来启用混合模式:
export OMP_NUM_THREADS=NUM_THREADS
使用此混合方法时,我们建议线程总数不超过虚拟机中的物理核心数。C2-standard-60 虚拟机具有 2 个 NUMA 套接字,每个套接字包含 15 个核心和 30 个 vCPU。我们建议您的任何 MPI 进程都不要具有跨多个 NUMA 节点的 OpenMP 线程。
C2D-standard-112 在 2 个套接字中包含 56 个核心,每个套接字包含 28 个核心。这些核心划分成 7 个 CCX,每个包含 4 个核心。每个 CCX 都有 32 MB 的 L3 缓存。每个核心都有 512 KB L2 缓存和 32 KB L1 指令和数据缓存。每个套接字都连接到 220 GB 的 DRAM。在 C2D-standard-112 上,我们建议使用两个或四个 OMP 线程,以便该过程适合 CCX。将 OMP 线程的数量设置为 4 会为每个 L3 缓存创建一个 MPI 进程。
export OMP_NUM_THREADS=4
CPULIST=$(seq -s , 0 4 55)
Open MPI:
mpirun –bind-to one –cpu-list $CPULIST …
Intel MPI:
export I_MPI_PIN_PROCESSOR_LIST=$CPULIST
使用适当的 CPU 编号
C2-standard-60 具有两个 NUMA 套接字,且 CPU 根据 NUMA 节点编号,如下所示:
NUMA node0 CPU(s): 0-14,30-44
NUMA node1 CPU(s): 15-29,45-59
下图演示如何将 CPU 编号分配给 C2-standard-60 实例所在 NUMA 节点上的每个 CPU。套接字 0 对应 NUMA node0,CPU 0-14 和 30-44。套接字 1 对应 NUMA node1,CPU 15-29 和 45-59。
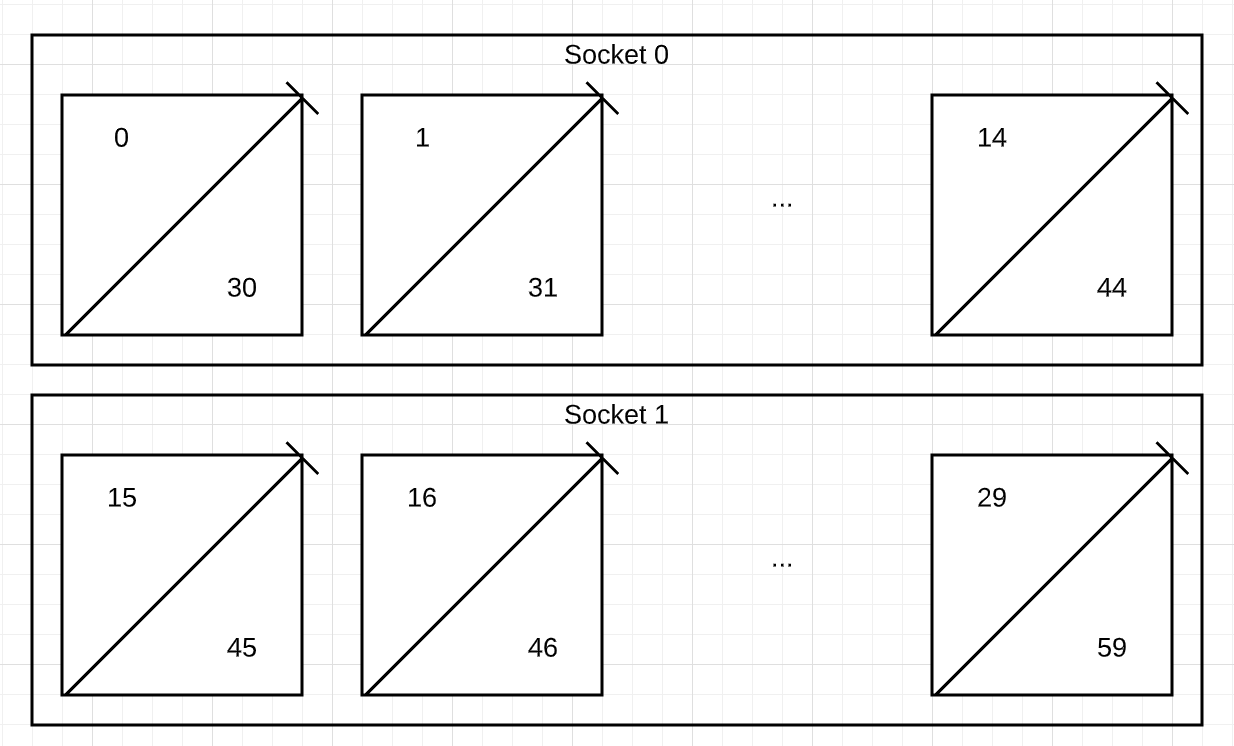
与该虚拟机中的单个核心对应的超线程 siblings 是 (0,30)(1,31)..(29,59)。
Intel MPI 使用 NUMA CPU 编号来固定 MPI 作业的处理器。如果要在运行过程中一致的所有节点上使用一个核心一个超线程,请使用 CPU 编号 0-29。
Open MPI 使用 Portable Hardware Locality (hwloc) 报告的逻辑 CPU 编号。如果使用 Open MPI,则超线程 siblings 按如下方式连续进行编号:
套接字 0:0 (core 0 HT 0), 1 (core 0 HT 1), 2 (core 1 HT 0) ,...,28 (core 14 HT 0), 29 (core 14, HT 1)
套接字 1:30 (core 0 HT 0), 31 (core 0 HT 1), 2 (core 1 HT 0) ,...,58 (core 14 HT 0), 59 (core 14, HT 1)
输出如下所示:
lstopo-no-graphics
Machine (240GB total)
NUMANode L#0 (P#0 120GB) + Package L#0 + L3 L#0 (25MB)
L2 L#0 (1024KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
PU L#1 (P#30)
L2 L#1 (1024KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1
PU L#2 (P#1)
PU L#3 (P#31)
使用 Open MPI 时,您可以通过使用 CPU 编号 0,2,4,..58,在运行过程中一致的所有节点上使用一个核心一个超线程。如需强制 MPI 将进程固定到核心,请在运行 openMPI 时使用选项 --bind-to core,然后使用 --report-bindings 选项验证绑定是否正确。
使用 Open MPI
对于使用 Open MPI 的客户,我们建议使用 Open MPI 的最新稳定版本。
为了提升 Open MPI 在 Google Cloud 上的性能,我们建议您在操作系统级层和 Open MPI MCA 级层使用以下调节选项:
对于操作系统调节,我们发现关闭频繁轮询的情况下使用 Open MPI 的效果更好。如需停用频繁轮询,请使用以下命令:
tuned-adm profile network-throughput
如需通过调节来进一步提高 Open MPI 性能,请使用以下 MCA 参数:
--mca opal_event_include epoll
将轮询网络事件时使用的默认轮询策略从轮询改为 epoll。此更改在启用频繁轮询时应该会提高性能,并且在停用时不会带来任何负面影响。--mca btl_tcp_progress_thread 1
在 BTL(字节传输层)框架下的 TCP 组件中,将progress_thread的值从 0(默认值)更改为 1。--mca coll_han_priority 100
在 COLL(统一)框架下启用分层感知网络 (HAN) 组件。
使用以下命令可启用建议的 MCA 参数:
mpirun -hostfile HOSTFILE -np NUM_PROCESSES -npernode PROCESSES_PER_NODE \
--mca opal_event_include epoll \
--mca btl_tcp_progress_thread 1 \
--mca coll_han_priority 100 APPLICATION
您还可以通过将这些参数添加到 MCA 文件中来启用它们。如需了解详情,请参阅如何设置 MCA 参数的值。
安全设置
您可以通过停用一些内置的 Linux 安全功能来提高 MPI 性能。停用每种功能带来的性能优势各不相同。 如果您确信自己的系统受到妥善保护,则可以评估停用以下安全功能的利弊。
停用 Linux 防火墙
对于 Google Cloud CentOS 或 Rocky Linux 映像,防火墙默认处于启用状态。如需停用防火墙,请运行以下命令来停止并停用 firewalld 守护程序:
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo systemctl mask --now firewalld
停用 SELinux
CentOS 或 Rocky Linux 中的 SELinux 默认处于启用状态。如需停用 SELinux,请修改 /etc/selinux/config 文件,并将 SELINUX=enforcing 或 SELINUX=permissive 行替换为 SELINUX=disabled。
为了使此更改生效,您必须进行重启。
关闭 Meltdown 和 Spectre 缓解措施
默认情况下,以下安全补丁程序在 Linux 系统上处于启用状态:
- 变体 1,Spectre:CVE-2017-5753
- 变体 2,Spectre:CVE-2017-5715
- 变体 3,Meltdown:CVE-2017-5754
- 变体 4,Speculative Store Bypass:CVE-2018-3639
您可能会在现代微处理器(包括在 Google Cloud 中部署的处理器)中发现上述 CVE 中所述的安全漏洞。您可以通过在启动时使用内核命令行(重启后依然存在)或在运行时中使用 debugfs(重启后不再存在),停用一项或多项上述缓解措施,但这会引起相关安全风险。
如需永久停用上述安全缓解措施,请按以下步骤操作:
修改文件
/etc/default/grub:sudo sed -i 's/^GRUB_CMDLINE_LINUX=\"\(.*\)\"/GRUB_CMDLINE_LINUX=\"\1 mitigations=off\"/' /etc/default/grub更改
grub文件后,请运行以下命令以更新 GRUB 系统配置文件,然后重新启动系统:对于 CentOS:
sudo grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg对于 Rocky Linux:
sudo grub2-mkconfig -o /boot/efi/EFI/rocky/grub.cfg如果您的系统采用的是旧式 BIOS 启动模式,请运行以下命令:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg重新启动。
如果系统已在运行,您可以通过运行以下命令停用上述安全缓解措施。重启后不再存在。
echo 0 > /sys/kernel/debug/x86/pti_enabled
echo 0 > /sys/kernel/debug/x86/retp_enabled
echo 0 > /sys/kernel/debug/x86/ibrs_enabled
echo 0 > /sys/kernel/debug/x86/ssbd_enabled
如需了解不同的缓解措施如何影响您的系统以及如何控制它们,请参阅 Red Hat 文档:控制微码和安全补丁程序对性能的影响和使用推测性旁路漏洞的内核侧信道攻击。
如需查找受影响的 CPU 漏洞,请运行以下命令:
grep . /sys/devices/system/cpu/vulnerabilities/*
如需查找已启用的缓解措施,请运行以下命令:
grep . /sys/kernel/debug/x86/*_enabled
核对清单摘要
下表汇总在 Compute Engine 上使用 MPI 的最佳做法。
| 范围 | 任务 |
|---|---|
| Compute Engine 配置 | |
| 存储 | |
| 网络设置 | |
| MPI 库和用户应用 | |
| 安全设置 |
后续步骤
- 详细了解 Google 计算优化型虚拟机。
- 在 Google Cloud 上部署 Slurm 集群。
- 详细了解 Google Cloud 上的高性能存储。
- 了解 HTCondor。
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud Architecture Center。