Google Cloud
Computación de alto rendimiento
Descripción general
Infraestructura de HPC potente

Servicios y herramientas avanzados de HPC
Implementa la HPC con rapidez con los kit de herramientas de HPC de Cloud, que son prácticas recomendadas incluidas en los planos de HPC. Implementa módulos preconfigurados para Compute Engine, Google Kubernetes Engine, Batch o VM individuales.
Accede a los datos en Parallelstore, Filestore, Cloud Storage o en ofertas de almacenamiento de socios.
Acelera las cargas de trabajo estrechamente vinculadas a través de políticas de posición compactas, gVNIC y la imagen de VM de HPC.

HPC con optimización de costos
Administra los costos a medida que escalas con presupuestos y descuentos por compromiso de uso. Ahorra hasta un 91% con las VMs Spot para cargas de trabajo flexibles, tolerantes a errores y con puntos de control. Genera informes sobre los costos de forma detallada y con facilidad mediante las etiquetas integradas en el kit de herramientas de HPC de Cloud.

Cómo funciona
Las soluciones de HPC de Google Cloud son fáciles de usar, se basan en la tecnología más reciente y están optimizadas para costos para proporcionar una base de HPC flexible y poderosa.
El kit de herramientas de HPC de Cloud te permite iniciar fácilmente nuevos entornos de HPC.

Usos comunes
Descubrimiento de fármacos
Expande los horizontes
El descubrimiento de fármacos es una carga de trabajo desafiante, pero que puede salvar vidas en la computación de alto rendimiento. Google Cloud tiene las herramientas y la experiencia para ofrecer resultados en los momentos más importantes.
Nuestras soluciones de HPC facilitan y aceleran la realización de pruebas químicas computacionales, dinámicas moleculares y cargas de trabajo de evaluación virtual de fármacos.
Obtén información sobre cómo los clientes aceleraron sus cargas de trabajo de descubrimiento de fármacos en Google Cloud y conoce los planos de prácticas recomendadas del kit de herramientas de HPC de Cloud para las cargas de trabajo de descubrimiento de fármacos.



Consulta las demás pestañas para obtener más información sobre las cargas de trabajo de descubrimiento de fármacos.
Schrödinger
Los investigadores farmacéuticos y de descubrimiento de fármacos usan Google Cloud para ejecutar sus cargas de trabajo de investigación.
Schrödinger usa simulaciones basadas en la física que se realizan en la nube en combinación con el aprendizaje automático para acelerar el descubrimiento de nuevos fármacos y materiales.



Instructivos
Expande los horizontes
El descubrimiento de fármacos es una carga de trabajo desafiante, pero que puede salvar vidas en la computación de alto rendimiento. Google Cloud tiene las herramientas y la experiencia para ofrecer resultados en los momentos más importantes.
Nuestras soluciones de HPC facilitan y aceleran la realización de pruebas químicas computacionales, dinámicas moleculares y cargas de trabajo de evaluación virtual de fármacos.
Obtén información sobre cómo los clientes aceleraron sus cargas de trabajo de descubrimiento de fármacos en Google Cloud y conoce los planos de prácticas recomendadas del kit de herramientas de HPC de Cloud para las cargas de trabajo de descubrimiento de fármacos.
Consulta las demás pestañas para obtener más información sobre las cargas de trabajo de descubrimiento de fármacos.
Ejemplos de clientes
Schrödinger
Los investigadores farmacéuticos y de descubrimiento de fármacos usan Google Cloud para ejecutar sus cargas de trabajo de investigación.
Schrödinger usa simulaciones basadas en la física que se realizan en la nube en combinación con el aprendizaje automático para acelerar el descubrimiento de nuevos fármacos y materiales.
Servicios financieros
Simulación de riesgos e investigación cuantitativa
Los administradores cuantitativos dependen cada vez más del acceso a los recursos de computación de alto rendimiento (HPC) para desarrollar sus estrategias de inversión. Mientras que las empresas de compra usaban principalmente una infraestructura local en el pasado, los profesionales de análisis cuantitativos y riesgos pueden beneficiarse de la potencia de procesamiento de la nube.
Obtén más información sobre cómo Google Cloud permite que las organizaciones de servicios financieros aceleren sus cargas de trabajo más difíciles.



Goldman Sachs ofrece escalamiento, agilidad y confianza con Google
Goldman Sachs usa Google Cloud para habilitar el crecimiento seguro, la agilidad y la confianza de sus clientes. Con la entrega de su gran capacidad computacional y escala infinita, Google Cloud ayuda a la empresa global a enfocarse en desafíos nuevos, evolucionar rápido y entregar innovaciones nuevas para satisfacer las necesidades de sus clientes en una economía que cambia de forma constante.
“Cuando Goldman Sachs pensó en escalar su propio negocio y cuánto más intensa podría ser la actividad de administración de riesgos en el mundo, Google Cloud fue una elección obvia”.




Instructivos
Simulación de riesgos e investigación cuantitativa
Los administradores cuantitativos dependen cada vez más del acceso a los recursos de computación de alto rendimiento (HPC) para desarrollar sus estrategias de inversión. Mientras que las empresas de compra usaban principalmente una infraestructura local en el pasado, los profesionales de análisis cuantitativos y riesgos pueden beneficiarse de la potencia de procesamiento de la nube.
Obtén más información sobre cómo Google Cloud permite que las organizaciones de servicios financieros aceleren sus cargas de trabajo más difíciles.
Ejemplos de clientes
Goldman Sachs ofrece escalamiento, agilidad y confianza con Google
Goldman Sachs usa Google Cloud para habilitar el crecimiento seguro, la agilidad y la confianza de sus clientes. Con la entrega de su gran capacidad computacional y escala infinita, Google Cloud ayuda a la empresa global a enfocarse en desafíos nuevos, evolucionar rápido y entregar innovaciones nuevas para satisfacer las necesidades de sus clientes en una economía que cambia de forma constante.
“Cuando Goldman Sachs pensó en escalar su propio negocio y cuánto más intensa podría ser la actividad de administración de riesgos en el mundo, Google Cloud fue una elección obvia”.
Automatización del diseño electrónico
Diseño y verificación de chips en la nube
Las soluciones de HPC de Google Cloud pueden ayudar a las empresas de automatización de diseño electrónico (EDA) a acelerar sus ciclos de diseño y verificación, mejorar la calidad de los productos y reducir los costos. Google Cloud ofrece una amplia variedad de servicios y soluciones de HPC, que incluyen el kit de herramientas de HPC de Cloud, Batch y las integraciones de socios. Estas soluciones pueden usarse para crear entornos de HPC potentes y flexibles que puedan ejecutar cargas de trabajo de EDA de manera optimizada para licencias.



Instructivos
Diseño y verificación de chips en la nube
Las soluciones de HPC de Google Cloud pueden ayudar a las empresas de automatización de diseño electrónico (EDA) a acelerar sus ciclos de diseño y verificación, mejorar la calidad de los productos y reducir los costos. Google Cloud ofrece una amplia variedad de servicios y soluciones de HPC, que incluyen el kit de herramientas de HPC de Cloud, Batch y las integraciones de socios. Estas soluciones pueden usarse para crear entornos de HPC potentes y flexibles que puedan ejecutar cargas de trabajo de EDA de manera optimizada para licencias.
Ingeniería asistida por computadora
Dinámica de fluidos, mecánica estructural, exploración de energía
Ya sea que ejecutes simulaciones computacionales de dinámica de fluidos, análisis de elementos finitos, o simulaciones de yacimientos, la ingeniería asistida por computadora (CAE) es lo que necesitas. Ejecutar estas simulaciones de manera eficiente y oportuna es fundamental.
Google Cloud cuenta con las soluciones de HPC para satisfacer tus necesidades y entregar rendimiento a tiempo para superar a la competencia.




AirShaper
AirShaper es una plataforma de CFD basada en la nube que ayuda a los ingenieros y diseñadores a ejecutar simulaciones aerodinámicas con facilidad para mejorar el rendimiento y la eficiencia de los autos, drones, motocicletas y hasta de los propios atletas.


Instructivos
Dinámica de fluidos, mecánica estructural, exploración de energía
Ya sea que ejecutes simulaciones computacionales de dinámica de fluidos, análisis de elementos finitos, o simulaciones de yacimientos, la ingeniería asistida por computadora (CAE) es lo que necesitas. Ejecutar estas simulaciones de manera eficiente y oportuna es fundamental.
Google Cloud cuenta con las soluciones de HPC para satisfacer tus necesidades y entregar rendimiento a tiempo para superar a la competencia.
Ejemplos de clientes
AirShaper
AirShaper es una plataforma de CFD basada en la nube que ayuda a los ingenieros y diseñadores a ejecutar simulaciones aerodinámicas con facilidad para mejorar el rendimiento y la eficiencia de los autos, drones, motocicletas y hasta de los propios atletas.
Pronóstico del tiempo
Modelado climático en Google Cloud
Los pronósticos meteorológicos pueden ejecutar modelos de clima populares, como el sistema de modelado de investigación meteorológica y previsión (WRF), GFS FV3, ECMWF y más fácilmente en Google Cloud con el kit de herramientas de HPC de Google Cloud y lograr el rendimiento de una supercomputadora local por una fracción del precio.
Pon en marcha tus simulaciones del clima en Google Cloud en minutos y responde a los datos nuevos en tiempo récord.
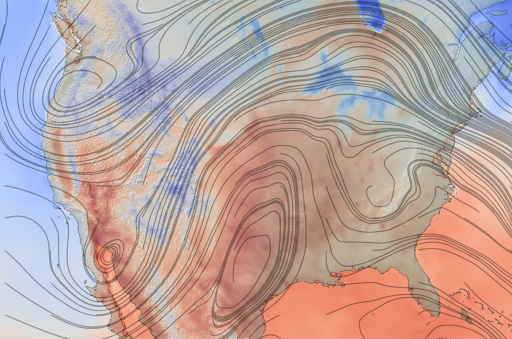



Instructivos
Modelado climático en Google Cloud
Los pronósticos meteorológicos pueden ejecutar modelos de clima populares, como el sistema de modelado de investigación meteorológica y previsión (WRF), GFS FV3, ECMWF y más fácilmente en Google Cloud con el kit de herramientas de HPC de Google Cloud y lograr el rendimiento de una supercomputadora local por una fracción del precio.
Pon en marcha tus simulaciones del clima en Google Cloud en minutos y responde a los datos nuevos en tiempo récord.
Ciencias biológicas y genómica
Haz nuevos descubrimientos
Las soluciones de HPC de Google Cloud pueden ayudar a los investigadores de ciencias biológicas y de genómica a realizar nuevos descubrimientos. Cuando se proporciona acceso a recursos de procesamiento potentes, Google Cloud puede ayudar a los investigadores a analizar grandes conjuntos de datos, ejecutar simulaciones y desarrollar nuevos tratamientos médicos de manera más rápida y eficiente. Google Cloud también ofrece una variedad de herramientas y servicios específicos de HPC y ciencias biológicas, como Batch y Google Multiomics Suite.



Centro de genómica y medicina personalizada de Stanford
SCGPM, que crea una canalización de análisis de variaciones genéticas a gran escala con Google Genomics y Google BigQuery, puede analizar cientos de genomas enteros en días y mostrar resultados de consultas en segundos, a la vez que brinda seguridad confiable. para los datos de ADN.



Instructivos
Haz nuevos descubrimientos
Las soluciones de HPC de Google Cloud pueden ayudar a los investigadores de ciencias biológicas y de genómica a realizar nuevos descubrimientos. Cuando se proporciona acceso a recursos de procesamiento potentes, Google Cloud puede ayudar a los investigadores a analizar grandes conjuntos de datos, ejecutar simulaciones y desarrollar nuevos tratamientos médicos de manera más rápida y eficiente. Google Cloud también ofrece una variedad de herramientas y servicios específicos de HPC y ciencias biológicas, como Batch y Google Multiomics Suite.
Ejemplos de clientes
Centro de genómica y medicina personalizada de Stanford
SCGPM, que crea una canalización de análisis de variaciones genéticas a gran escala con Google Genomics y Google BigQuery, puede analizar cientos de genomas enteros en días y mostrar resultados de consultas en segundos, a la vez que brinda seguridad confiable. para los datos de ADN.
Energía
Aceleración de las cargas de trabajo de energía
Google Cloud ayuda a las compañías eléctricas y de energía a obtener resultados más rápido con una variedad de socios, servicios y soluciones específicas líderes en la industria y en el sector energético.
Clientes como PGS, TGS y Schlumberger confían en Google Cloud para administrar sus cargas de trabajo esenciales y urgentes. Consulta la pestaña de ejemplos de clientes para obtener información sobre cómo PGS reemplazó sus 260,000 supercomputadoras Cray principales con Google Cloud.


PGS reemplaza 260,000 supercomputadoras Cray principales
Gracias al poder de la computación en la nube y la flexibilidad de elegir entre varios tipos de configuraciones de procesamiento y almacenamiento, PGS han llevado a su HPC a una transformación digital que pasa de un costoso pesado sistemas de supercomputadoras locales a una configuración escalable orientada a los gastos operativos en Google Cloud.


Instructivos
Aceleración de las cargas de trabajo de energía
Google Cloud ayuda a las compañías eléctricas y de energía a obtener resultados más rápido con una variedad de socios, servicios y soluciones específicas líderes en la industria y en el sector energético.
Clientes como PGS, TGS y Schlumberger confían en Google Cloud para administrar sus cargas de trabajo esenciales y urgentes. Consulta la pestaña de ejemplos de clientes para obtener información sobre cómo PGS reemplazó sus 260,000 supercomputadoras Cray principales con Google Cloud.
Ejemplos de clientes
PGS reemplaza 260,000 supercomputadoras Cray principales
Gracias al poder de la computación en la nube y la flexibilidad de elegir entre varios tipos de configuraciones de procesamiento y almacenamiento, PGS han llevado a su HPC a una transformación digital que pasa de un costoso pesado sistemas de supercomputadoras locales a una configuración escalable orientada a los gastos operativos en Google Cloud.
Kit de herramientas de HPC de Cloud
Aprende cómo funciona el kit de herramientas y, luego, implementa un plano
Lee los blogs de HPC más recientes
Diseña tu entorno de HPC
Conoce las prácticas recomendadas
Implementa un plano
Integración y socios
Socios de HPC de Google Cloud















































Programadores y plataformas
Integradores
Proveedores de software independientes
Almacenamiento
Preguntas frecuentes
¿Cómo debo elegir entre estos servicios de Google Cloud para ejecutar cargas de trabajo de computación de alto rendimiento (HPC): Compute Engine, Google Kubernetes Engine, Batch y Cloud Run?
El mejor servicio de Google Cloud para ejecutar cargas de trabajo de HPC depende de tus necesidades específicas. Hay una serie de factores que se deben considerar cuando se diseña el entorno de HPC. Algunos de esos factores incluyen los siguientes:
Control: ¿Cuánto control necesitas en tu entorno de HPC?
Escalabilidad: ¿Qué tan escalable debe ser tu entorno de HPC?
Costo: ¿Cuánto estás dispuesto a invertir en el entorno de HPC?
Facilidad de uso: ¿Qué tan fácil necesitas que sea usar tu entorno de HPC?
Una vez que consideres estos factores, puedes elegir el servicio de Google Cloud más adecuado para ti. A continuación, se incluye una breve descripción general de cada servicio y cómo se relacionan con los factores anteriores:
Compute Engine: Compute Engine es una oferta de infraestructura como servicio (IaaS) que proporciona máquinas virtuales (VMs) que se pueden usar para ejecutar cargas de trabajo de HPC. Con Compute Engine obtienes el mayor control y escalabilidad en comparación con el entorno de HPC.
Google Kubernetes Engine: Google Kubernetes Engine es un servicio administrado de Kubernetes que se puede usar para ejecutar cargas de trabajo de HPC en contenedores. Google Kubernetes Engine es una buena opción si deseas usar aplicaciones en contenedores o la facilidad de uso de Kubernetes para administrar tus recursos de procesamiento.
Batch: Batch es un servicio administrado para ejecutar trabajos por lotes. Batch es una buena opción si deseas ejecutar en Compute Engine, tienes una gran cantidad de trabajos de HPC que necesitas ejecutar con regularidad y no necesitas una personalización profunda de las políticas de infraestructura o programación.
Cloud Run: Cloud Run es una plataforma sin servidores que se puede usar para ejecutar cargas de trabajo de HPC pequeñas y sencillas. Cloud Run es una buena opción si deseas ejecutar cargas de trabajo de HPC sin tener que administrar infraestructura. Consulta los límites de recursos de Cloud Run para comprender las limitaciones.
No dudes en comunicarte con el equipo de HPC de Google Cloud para analizar tus requisitos en profundidad.
¿Cómo debo elegir entre el kit de herramientas de HPC de Cloud y un socio de plataforma de HPC como servicio para mis cargas de trabajo de HPC?
Elegir entre el kit de herramientas de HPC de Cloud y un socio de plataforma de HPC como servicio depende de tus necesidades específicas. Estos son algunos factores que debes considerar cuando elijas entre el kit de herramientas de HPC de Cloud y un socio de plataforma de HPC como servicio:
Control: ¿Cuánto control necesitas en tu entorno de HPC?
Facilidad de uso: ¿Qué tan fácil necesitas que sea usar tu entorno de HPC?
Costo: ¿Cuánto estás dispuesto a invertir en el entorno de HPC?
Experiencia: ¿Cuánta experiencia tienes en HPC?
Una vez que consideres estos factores, puedes elegir la opción más adecuada para ti. A continuación, se incluye una breve descripción general de cada opción:
Kit de herramientas de HPC de Cloud
El kit de herramientas de HPC de Cloud es un conjunto de herramientas de código abierto que se puede usar para implementar y administrar cargas de trabajo de HPC en Google Cloud. El kit de herramientas proporciona una serie de funciones, como la capacidad de ser de código abierto, Terraform y Cloud Foundation Toolkit, las cuales se pueden componer e integrar en los servicios de Google Cloud, además de herramientas y aplicaciones populares de HPC. El kit de herramientas de HPC de Cloud se puede usar a través de una interfaz de usuario basada en la Web con el frontend abierto.
El kit de herramientas de HPC de Cloud es una buena opción si quieres tener un alto grado de control sobre tu entorno de HPC. El kit de herramientas de HPC de Cloud se creó para que sea más fácil de usar que compilar entornos DIY de HPC. Proporciona una mayor configuración y requiere más de esta que una HPC usada como plataforma de servicio de un socio. Por lo tanto, es la opción más adecuada para usuarios con más experiencia en HPC.
HPC como plataforma de servicio de un socio.
Una HPC usada como plataforma de servicio de un socio. es una empresa de terceros que proporciona una plataforma de HPC administrada en Google Cloud. Por lo general, estas plataformas proporcionan varias funciones, como entornos de HPC preconfigurados, interfaces fáciles de usar y asistencia técnica.
Una HPC como plataforma de servicio de un socio es una buena opción si deseas comenzar a usar la HPC de forma fácil y rápida, o si deseas ofrecer a los usuarios una experiencia del usuario sencilla y basada en GUI. Sin embargo, pueden ser menos flexibles o incluir costos adicionales.
En general, el kit de herramientas de HPC de Cloud es una buena opción para los usuarios que tienen un alto nivel de experiencia en HPC y desean un alto grado de control sobre su entorno de HPC. Las HPC como plataformas de servicio de un socio son una buena opción para los usuarios que quieren comenzar a usar la HPC con rapidez y facilidad.












