애플리케이션 성능을 최적화하려면 NDB를 사용하는 것이 좋습니다. 예를 들어 애플리케이션이 캐시에 없는 값을 읽으면 읽는 데 다소 시간이 걸립니다. 데이터 저장소 작업을 다른 작업과 병행하거나, 몇 가지 데이터 저장소 작업을 병렬로 수행하면 애플리케이션 속도를 높일 수 있습니다.
NDB 클라이언트 라이브러리는 여러 가지 비동기(asynchronous, async) 함수를 제공합니다.
이러한 각 함수를 통해 애플리케이션은 Datastore에 요청을 보낼 수 있습니다. 이 함수는 Future 객체를 결과로 즉시 반환합니다. 애플리케이션은 Datastore가 요청을 처리하는 동안 다른 작업을 수행할 수 있으며,
Datastore가 요청을 처리한 후에 Future 객체에서 결과를 가져올 수 있습니다.
소개
애플리케이션의 요청 핸들러 중 하나가 요청 기록과 같이 무언가를 작성하기 위해 NDB를 사용해야 한다고 가정합니다. 또한 데이터 가져오기와 같은 다른 NDB 작업을 수행해야 한다고 가정합니다.
put() 호출을 비동기식인 put_async() 호출로 바꾸면 애플리케이션이 put()에서 차단되는 대신 다른 작업을 즉시 수행할 수 있습니다.
이렇게 하면 데이터 저장소에서 데이터를 기록하는 동안 다른 NDB 함수 및 템플릿 렌더링이 발생하도록 허용됩니다. 애플리케이션이 Datastore에서 데이터를 가져올 때까지 Datastore에서 차단되지 않습니다.
이 예시에서 future.get_result 호출은 큰 의미를 갖지 않습니다. 애플리케이션은 NDB의 결과를 사용하지 않기 때문입니다. 이 코드는 단지 NDB put이 종료되기 전에 요청 핸들러가 종료되지 않도록 하기 위한 것입니다. 요청 핸들러가 너무 일찍 종료되면 put이 수행되지 않습니다. 편의상 요청 핸들러를 @ndb.toplevel로 데코레이션할 수 있습니다. 이는 핸들러에게 비동기식 요청이 완료될 때까지 종료하지 말라고 지시합니다. 또한 사용자가 요청을 보낼 수 있게 해 주고 결과를 걱정할 필요가 없게 해줍니다.
전체 WSGIApplication을 ndb.toplevel로 지정할 수 있습니다. 이렇게 하면 결과를 반환하기 전에 WSGIApplication의 각 핸들러가 모든 비동기식 요청을 기다립니다.
모든 WSGIApplication의 핸들러를 'toplevel'하는 것이 아닙니다.
toplevel 애플리케이션을 사용하는 것이 모든 핸들러 함수를 사용하는 것보다 더 편리합니다. 하지만 핸들러 메서드가 yield를 사용하는 경우에는 메서드가 다른 데코레이터인 @ndb.synctasklet으로 래핑되어야 합니다. 그렇지 않으면 yield에서 실행을 중지하고 완료되지 않습니다.
비동기 API 및 Future 사용
거의 모든 동기식 NDB 함수에는 _async 대응 함수가 있습니다. 예를 들어 put()에는 put_async()가 있습니다.
비동기 함수의 인수는 항상 동기 버전의 함수의 인수와 동일합니다.
비동기 메서드의 반환 값은 항상 Future 또는 ('멀티' 함수의 경우) Future 목록입니다.
Future는 시작되었지만 아직 완료되지 않은 작업의 상태를 유지하는 객체입니다. 모든 비동기 API는 Futures를 1개 이상 반환합니다.
Future의 get_result() 함수를 호출하여 작업 결과를 요청할 수 있습니다. 그러면 필요한 경우 Future가 결과가 나올 때까지 차단했다가 결과를 제공합니다.
get_result()는 API의 동기 버전에서 반환되는 값을 반환합니다.
참고: Futures를 다른 프로그래밍 언어에서 사용해 보았다면 Future를 바로 결과로 사용할 수 있겠다고 생각할 수도 있습니다. 이 경우에는 그렇게 작동하지 않습니다.
다른 언어는 암시적 Future를 사용하지만 NDB는 명시적 Future를 사용합니다.
NDB Future의 결과를 가져오려면 get_result()를 호출하세요.
작업이 예외를 발생시키면 어떻게 될까요? 예외가 언제 발생하느냐에 따라 다릅니다. 요청(아마도 잘못된 유형의 인수)을 할 때 NDB가 문제를 발견하면 _async() 메서드가 예외를 발생시킵니다. 하지만 예외가 예를 들어 Datastore 서버에서 감지되면 _async() 메서드는 Future를 반환하고 애플리케이션이 get_result()를 호출할 때 예외가 발생합니다. 이 점은 너무 염려하지 않아도 됩니다. 어떤 경우든 결국 자연스럽게 동작하게 됩니다. 가장 큰 차이는 역추적을 인쇄하면 낮은 수준의 비동기 기계가 노출된다는 점입니다.
예를 들어 방명록 애플리케이션을 작성한다고 가정합니다. 사용자가 로그인하면 가장 최근의 방명록 게시물을 보여주는 페이지를 표시하려고 합니다. 이 페이지에는 사용자 본인의 닉네임도 표시됩니다. 이 애플리케이션에는 두 가지 정보, 즉 로그인한 사용자의 계정 정보와 방명록 게시물의 콘텐츠가 필요합니다. 애플리케이션의 '동기' 버전은 다음과 유사합니다.
여기에는 독립적인 I/O 작업이 두 개 있습니다. 하나는 Account 항목을 가져오는 것이고 다른 하나는 최근의 Guestbook 항목을 가져오는 것입니다. 동기 API를 사용하면 이러한 작업이 연이어 발생합니다. 이 경우 방명록 항목을 가져오기 전에 계정 정보를 수신하기를 기다립니다. 하지만 애플리케이션에는 계정 정보가 바로 필요하지 않습니다. 바로 이 점을 활용하여 비동기 API를 사용할 수 있습니다.
이 버전의 코드는 먼저 Futures 두 개(acct_future 및 recent_entries_future)를 만든 후 대기합니다. 서버는 두 요청을 동시에 처리합니다.
_async() 함수를 호출할 때마다 Future 객체가 생성되고 Datastore 서버에 요청이 전송됩니다. 서버는 즉시 요청의 처리를 시작할 수 있습니다. 서버 응답은 임의의 순서로 반환될 수 있으며, Future 객체 링크는 해당 요청에 응답합니다.
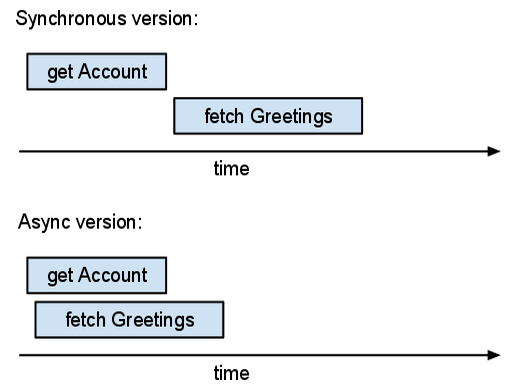
비동기 버전에서 사용되는 총 (실제) 시간은 대략 각 작업의 최대 시간과 일치합니다. 동기 버전에서 사용되는 총 시간은 작업 시간의 합계를 초과합니다. 더 많은 작업을 병렬로 실행할 수 있다면 비동기 작업이 더 유용합니다.
애플리케이션의 쿼리에 소요되는 시간 또는 애플리케이션이 초당 수행하는 I/O 작업의 개수를 확인하려면 앱 통계를 사용하세요. 이 도구는 라이브 앱의 계측에 따라 위의 그림과 유사한 차트를 보여줍니다.
tasklet 사용
NDB tasklet은 다른 코드와 동시에 실행될 수 있는 코드 조각입니다. tasklet을 작성하면 애플리케이션은 비동기 NDB 함수를 사용할 때처럼 tasklet을 사용할 수 있습니다. tasklet을 호출하면 Future가 반환되고 나중에 Future의 get_result() 메서드를 호출하여 결과를 가져옵니다.
tasklet은 스레드 없이 동시 함수를 작성하는 방법입니다. tasklet은 이벤트 루프에 의해 실행되며 I/O 또는 기타 작업에 yield 문을 사용하여 자신이 차단되는 것을 정지할 수 있습니다. 차단 작업의 개념은 Future 클래스로 추상화되지만 tasklet은 RPC가 완료될 때까지 기다리기 위해 RPC를 yield할 수도 있습니다.
tasklet에 결과가 있으면 이 결과가 ndb.Return 예외를 raise합니다. 그러면 NDB가 이 결과를 이전에 yield된 Future와 연결합니다.
NDB tasklet을 작성하면 yield와 raise를 일반적이지 않은 방식으로 사용하게 됩니다. 따라서 이러한 사용 방법의 예시를 찾아보면 NDB tasklet과 같은 코드가 보이지 않을 것입니다.
함수를 NDB tasklet으로 변환하는 방법은 다음과 같습니다.
- 함수를
@ndb.tasklet으로 데코레이션합니다. - 모든 동기 Datastore 호출을 Async Datastore 호출의
yield로 대체합니다. raise ndb.Return(retval)을 사용하여 함수가 반환 값을 '반환'하도록 합니다(함수가 아무 것도 반환하지 않는 경우에는 필요하지 않음).
애플리케이션은 tasklet을 사용하여 비동기 API를 더욱 세밀하게 제어할 수 있습니다. 예를 들어 다음과 같은 스키마를 사용하는 것이 좋습니다.
...
메시지를 표시할 때는 작성자의 닉네임을 표시하는 것이 좋습니다. 데이터를 가져와서 메시지 목록을 표시하는 '동기식' 방법의 예는 다음과 같습니다.
하지만 이 방식은 비효율적입니다. 앱 통계를 살펴보면 'Get' 요청이 연속으로 있는 것을 확인할 수 있습니다. 다음과 같은 '계단형' 패턴이 나타납니다.
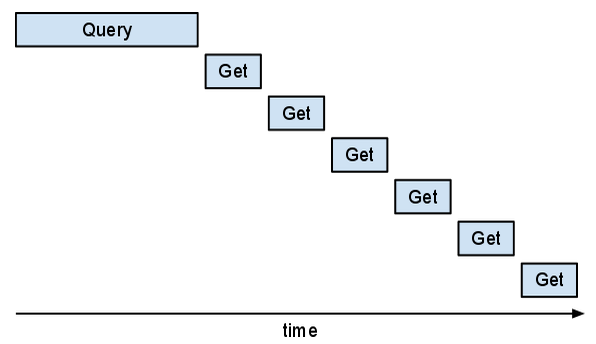
이러한 'Get'이 중복될 수 있으면 프로그램에서 이 부분의 속도가 빨라집니다.
get_async를 사용하도록 코드를 재작성할 수 있지만 어떤 비동기식 요청과 메시지가 서로에 속하는지 추적하기가 다소 어렵습니다.
애플리케이션은 tasklet을 생성하여 고유한 '비동기' 함수를 정의할 수 있습니다. 이렇게 하면 간단한 방식으로 코드를 구성할 수 있습니다.
또한 함수가 acct = key.get() 또는 acct = key.get_async().get_result()를 사용하는 대신 acct = yield key.get_async()를 사용해야 합니다.
이 yield는 NDB에 이 tasklet을 정지하고 다른 tasklet을 실행할 수 있는 적절한 지점을 알려줍니다.
생성기 함수를 @ndb.tasklet으로 데코레이션하면 함수가 생성기 객체 대신 Future를 반환합니다. tasklet 내에서 Future의 yield는 기다렸다가 Future 결과를 반환합니다.
예를 들면 다음과 같습니다.
get_async()가 Future를 반환하더라도 tasklet 프레임워크로 인해 yield 표현식이 Future 결과를 변수 acct에 반환합니다.
map()은 callback()을 여러 번 호출합니다.
하지만 callback()의 yield ..._async()는 NDB의 스케줄러가 이러한 호출이 종료되기를 기다리기 전에 여러 비동기식 요청을 전송할 수 있게 해줍니다.
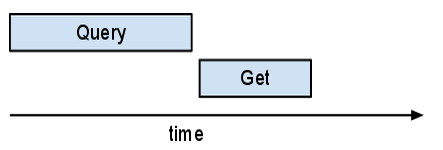
앱 통계에서 이 부분을 살펴보면 이러한 여러 Get이 겹칠 뿐만 아니라 이들 모두 동일한 요청을 거치는 것을 볼 수 있습니다. NDB는 '자동 일괄 처리기'를 구현합니다. 자동 일괄 처리기는 여러 개의 요청을 서버에 대한 단일 배치 RPC로 통합합니다. 수행할 다른 작업이 있으면(다른 콜백이 실행 중인 경우) 키를 수집하는 방식으로 그렇게 합니다. 결과 중 하나가 필요해지는 즉시 자동 일괄 처리기가 일괄 RPC를 전송합니다. 대부분의 요청과 달리 쿼리는 '일괄 처리'되지 않습니다.
tasklet이 실행되는 경우 tasklet은 tasklet이 생성된 시점의 기본값에서 또는 tasklet이 실행 중에 기본값에서 변경한 값에서 기본 네임스페이스를 가져옵니다. 다시 말하면 기본 네임스페이스는 환경설정에 연결되거나 저장되지 않으며, 특정 tasklet에서 기본 네임스페이스를 변경해도 해당 tasklet에 의해 생성된 tasklet를 제외하고 다른 tasklet의 기본 네임스페이스에는 영향을 미치지 않습니다.
Tasklet, 병렬 쿼리, 병렬 Yield
tasklet을 사용하여 여러 개의 쿼리가 동시에 레코드를 가져오도록 할 수 있습니다. 예를 들어 애플리케이션에 장바구니의 내용과 특별 쿠폰의 목록이 표시되는 페이지가 있다고 가정합니다. 스키마는 다음과 같습니다.
장바구니 항목과 특별 이벤트를 가져오는 '동기' 함수는 다음과 같습니다.
이 예시에서는 쿼리를 사용하여 장바구니 항목 및 쿠폰의 목록을 가져온 후 get_multi()를 사용하여 재고 항목의 세부정보를 가져옵니다.
이 함수는 get_multi()의 반환 값을 직접 사용하지 않습니다. get_multi()를 호출하여 모든 재고 세부정보를 캐시로 가져와서 나중에 빨리 읽을 수 있게 합니다. get_multi는 Get 여러 개를 요청 하나에 결합합니다. 하지만 쿼리 가져오기는 차례로 수행됩니다. 이러한 가져오기가 동시에 발생하게 하려면 다음 두 쿼리를 겹치게 합니다.
get_multi() 호출은 여전히 별개이며 쿼리 결과에 따라 달라지므로 이를 쿼리와 결합할 수 없습니다.
이 애플리케이션에 때때로 장바구니나 쿠폰, 또는 둘 다가 필요하다고 가정합니다. 그리고 장바구니를 가져오는 함수와 쿠폰을 가져오는 함수가 존재하는 코드를 구성하려고 합니다. 애플리케이션에서 이러한 함수를 함께 호출하면 이상적으로는 해당 쿼리가 '겹칠' 수 있습니다. 이렇게 하려면 다음과 같은 함수 tasklet을 만듭니다.
yield x, y는 중요하지만 간과하기 쉽습니다. 별개의 yield 문이 2개라면 연속으로 실행됩니다. 하지만 tasklet 튜플을 yield하는 것은 병렬 yield입니다. tasklet은 병렬로 실행될 수 있으며 yield는 모든 tasklet이 완료될 때까지 기다린 후 결과를 반환합니다. 일부 프로그래밍 언어에서는 이를 배리어라고 합니다.
코드 한 조각을 tasklet으로 변환해보면 곧 더 많은 코드를 이렇게 변환하고 싶어질 것입니다. tasklet을 사용하여 병렬로 실행할 수 있는 '동기식' 코드가 있을 경우 이러한 코드도 tasklet으로 만들면 유용할 수 있습니다.
그런 다음 병렬 yield를 사용하여 이를 병렬 처리할 수 있습니다.
요청 함수(webapp2 요청 함수, Django 보기 함수 등)를 tasklet으로 작성하면 원하는 대로 작동하지 않습니다. yield를 수행한 다음 실행이 중지됩니다. 이러한 경우에는 @ndb.synctasklet을 사용하여 함수를 데코레이션하는 것이 좋습니다.
@ndb.synctasklet은 @ndb.tasklet과 유사하지만 tasklet에서 get_result()를 호출하도록 변경됩니다.
이를 통해 tasklet이 결과를 일반적인 방식으로 반환하는 함수로 변환됩니다.
tasklet의 쿼리 반복자
tasklet에서 쿼리 결과를 반복하려면 다음 패턴을 사용합니다.
이 코드는 아래 코드의 tasklet 친화적인 버전입니다.
첫 번째 버전에서 굵게 표시된 세 줄은 두 번째 버전에서 굵게 표시된 한 줄의 tasklet 친화적인 버전입니다.
tasklet은 yield 키워드에서만 정지될 수 있습니다.
yield가 없는 for 루프를 사용하면 다른 tasklet이 실행되지 않습니다.
이 코드에서 qry.fetch_async()를 사용하여 모든 항목을 가져오는 대신에 쿼리 반복자를 사용하는 이유가 있습니다.
애플리케이션에 포함된 항목 수가 너무 많아 RAM에 맞지 않을 수 있습니다.
항목을 찾고 있는 경우 항목이 발견되면 반복을 중지할 수 있습니다. 하지만 쿼리 언어만으로는 검색 기준을 표현할 수 없습니다. 반복자를 사용하여 검사할 항목을 로드한 다음, 원하는 대상을 발견하면 루프를 중지할 수 있습니다.
NDB를 사용하는 비동기 Urlfetch
NDB Context에는 NDB tasklet과 원활하게 병렬 처리되는 비동기 urlfetch() 함수가 있습니다. 예를 들면 다음과 같습니다.
URL Fetch 서비스에는 자체 비동기식 요청 API가 있습니다. 이는 유용하지만 NDB tasklet과 함께 사용하기가 항상 쉽지는 않습니다.
비동기 트랜잭션 사용
트랜잭션도 비동기로 수행될 수 있습니다. 기존 함수를 ndb.transaction_async()에 전달하거나 @ndb.transactional_async 데코레이터를 사용할 수 있습니다.
다른 비동기 함수와 마찬가지로 이 경우도 NDB Future를 반환합니다.
또한 트랜잭션은 tasklet과 함께 작동합니다. 예를 들어 차단 RPC에서 대기하면서 update_counter 코드를 yield로 변경할 수 있습니다.
Future.wait_any() 사용
여러 개의 비동기식 요청을 만들고 첫 번째 요청이 완료되면 결과를 확인하려고 하는 경우가 있습니다.
ndb.Future.wait_any() 메서드를 사용하여 이 작업을 수행할 수 있습니다.
안타깝게도 이 작업을 tasklet으로 만들 수 있는 간편한 방법은 없습니다. 병렬 yield는 기다리지 않으려는 항목을 비롯해 모든 Future가 완료될 때까지 기다립니다.