ID region
REGION_ID adalah kode singkat yang ditetapkan Google berdasarkan region yang Anda pilih saat membuat aplikasi. Kode ini tidak sesuai dengan negara atau provinsi, meskipun beberapa ID region mungkin tampak mirip dengan kode negara dan provinsi yang umum digunakan. Untuk aplikasi yang dibuat setelah Februari 2020, REGION_ID.r disertakan dalam URL App Engine. Untuk aplikasi lama yang dibuat sebelum tanggal tersebut, ID region bersifat opsional dalam URL.
Pelajari ID region lebih lanjut.
Pengembangan software semuanya berkaitan dengan kompromi dan juga microservice. Apa yang Anda peroleh dalam deployment kode dan independensi operasi, akan Anda bayar dalam overhead performa. Bagian ini memberikan beberapa rekomendasi langkah-langkah yang dapat Anda lakukan untuk meminimalkan dampak tersebut.
Mengubah operasi CRUD menjadi microservice
Microservice sangat cocok untuk entity yang diakses dengan pola buat, ambil, update, dan hapus (CRUD). Saat bekerja dengan entity tersebut, Anda biasanya hanya menggunakan satu entity pada satu waktu, misalnya pengguna, dan biasanya hanya melakukan salah satu tindakan CRUD pada satu waktu. Oleh karena itu, Anda hanya memerlukan satu panggilan microservice untuk operasi tersebut. Cari entity yang memiliki operasi CRUD serta sekumpulan metode bisnis yang dapat digunakan di banyak bagian aplikasi Anda. Entitas ini menjadi kandidat yang baik untuk microservice.
Menyediakan API batch
Selain API bergaya CRUD, Anda masih dapat memberikan performa microservice yang baik untuk grup-grup entity dengan menyediakan API batch. Misalnya, daripada hanya mengekspos metode GET API yang mengambil satu pengguna, sediakan API yang menggunakan sekumpulan ID pengguna dan menampilkan kamus pengguna yang sesuai:
Permintaan:
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789Respons:
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
App Engine SDK mendukung banyak API batch, seperti kemampuan untuk mengambil banyak entity dari Cloud Datastore melalui satu RPC, sehingga menyajikan jenis API batch ini bisa menjadi sangat efisien.
Menggunakan permintaan asinkron
Sering kali, Anda harus berinteraksi dengan banyak microservice untuk membuat respons.
Misalnya, Anda mungkin perlu mengambil preferensi pengguna yang login serta detail perusahaannya. Sering kali, informasi ini tidak bergantung satu sama lain dan Anda dapat mengambilnya secara paralel. Library Urlfetch di
App Engine SDK mendukung permintaan asinkron,
sehingga Anda dapat memanggil microservice secara paralel.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
Melakukan pekerjaan secara paralel sering kali berlawanan dengan struktur kode yang baik karena, dalam
skenario nyata, Anda sering menggunakan satu class untuk mengenkapsulasi metode preferensi
dan class lain untuk mengenkapsulasi metode perusahaan. Sangat sulit untuk memanfaatkan
panggilan Urlfetch asinkron tanpa merusak enkapsulasi ini. Solusi yang baik ada di paket NDB App Engine Python SDK: Tasklets.
Dengan Tasklet, Anda dapat mempertahankan enkapsulasi yang baik dalam kode sambil tetap menawarkan
mekanisme untuk mencapai panggilan microservice paralel. Perhatikan bahwa tasklet menggunakan
futures, bukan RPC, tetapi intinya serupa.
Menggunakan rute terpendek
Bergantung pada cara Anda memanggil Urlfetch, Anda dapat menyebabkan penggunaan infrastruktur dan rute yang berbeda. Untuk menggunakan rute berperforma terbaik, pertimbangkan rekomendasi berikut:
- Gunakan
REGION_ID.r.appspot.com, bukan domain kustom - Domain kustom menyebabkan penggunaan rute yang berbeda saat memilih rute melalui infrastruktur Google. Karena panggilan microservice Anda bersifat internal, hal ini mudah dilakukan dan memiliki performa yang lebih baik jika Anda menggunakan
https://PROJECT_ID.REGION_ID.r.appspot.com. - Tetapkan
follow_redirectskeFalse - Tetapkan
follow_redirects=Falsesecara eksplisit saat memanggilUrlfetch, karena hal ini menghindari layanan makin berat yang dirancang untuk mengikuti pengalihan. Endpoint API Anda tidak perlu mengalihkan klien, karena klien tersebut adalah microservice Anda sendiri, dan endpoint hanya boleh menampilkan respons seri HTTP 200, 400, dan 500. - Memilih layanan dalam suatu project daripada beberapa project
- Ada alasan bagus untuk menggunakan beberapa project saat membangun aplikasi berbasis microservice, tetapi jika performa adalah tujuan utama Anda, gunakan layanan dalam satu project. Layanan project dihosting di pusat data yang sama dan meskipun throughput di jaringan antarpusat data Google sangat baik, panggilan lokal lebih cepat.
Menghindari chatter selama penerapan keamanan
Penggunaan mekanisme keamanan yang melibatkan banyak komunikasi dua arah untuk mengautentikasi API panggilan akan berpengaruh buruk bagi performa. Misalnya, jika microservice Anda perlu memvalidasi tiket dari aplikasi dengan melakukan panggilan kembali ke aplikasi, Anda harus melakukan beberapa perjalanan bolak-balik untuk mendapatkan data.
Implementasi OAuth2 dapat melunasi biaya ini dari waktu ke waktu menggunakan token refresh dan meng-cache token akses di antara pemanggilan Urlfetch. Namun, jika token akses yang di-cache disimpan di memcache, Anda harus menimbulkan overhead memcache untuk mengambilnya. Untuk menghindari overhead ini, Anda sebaiknya meng-cache token akses dalam memori instance, tetapi Anda akan tetap sering mengalami aktivitas OAuth2, karena setiap instance baru menegosiasikan token akses; ingat bahwa instance App Engine sering menyala dan mati. Beberapa campuran memcache dan cache instance akan membantu mengurangi masalah ini, tetapi solusi Anda akan menjadi lebih kompleks.
Pendekatan lain yang memiliki performa baik adalah dengan berbagi token rahasia antaramicroservice, misalnya, yang dikirim sebagai header HTTP khusus. Dalam pendekatan ini, setiap microservice dapat memiliki token unik untuk setiap pemanggil. Biasanya, secret bersama merupakan pilihan yang dipertanyakan untuk implementasi keamanan, tetapi karena semua microservice berada dalam aplikasi yang sama, masalah tersebut menjadi tidak terlalu rumit, mengingat peningkatan performa. Dengan secret bersama, microservice hanya perlu melakukan perbandingan string secret yang masuk dengan kamus yang mungkin ada dalam memori, dan penerapan keamanannya sangat ringan.
Jika semua microservice Anda ada di App Engine, Anda juga dapat memeriksa header X-Appengine-Inbound-Appid yang masuk.
Header ini ditambahkan oleh infrastruktur Urlfetch saat membuat permintaan ke project App Engine lain dan tidak dapat ditetapkan oleh pihak eksternal. Bergantung pada persyaratan keamanan, microservice Anda dapat memeriksa header yang masuk ini untuk menerapkan kebijakan keamanan.
Melacak permintaan microservice
Saat mem-build aplikasi berbasis microservice, Anda mulai mengumpulkan overhead dari panggilan Urlfetch berturut-turut. Jika hal ini terjadi, Anda dapat menggunakan Cloud Trace untuk memahami panggilan apa yang dilakukan dan lokasi overhead-nya. Yang penting, Cloud Trace juga dapat membantu mengidentifikasi tempat microservice independen dipanggil secara serial, sehingga Anda dapat memfaktorkan ulang kode untuk melakukan pengambilan ini secara paralel.
Fitur berguna Cloud Trace dimulai saat Anda menggunakan beberapa layanan dalam satu project. Saat panggilan dilakukan di antara layanan microservice dalam project Anda, Cloud Trace akan menciutkan semua panggilan secara bersamaan menjadi satu grafik panggilan agar Anda dapat memvisualisasikan seluruh permintaan menyeluruh sebagai satu trace.
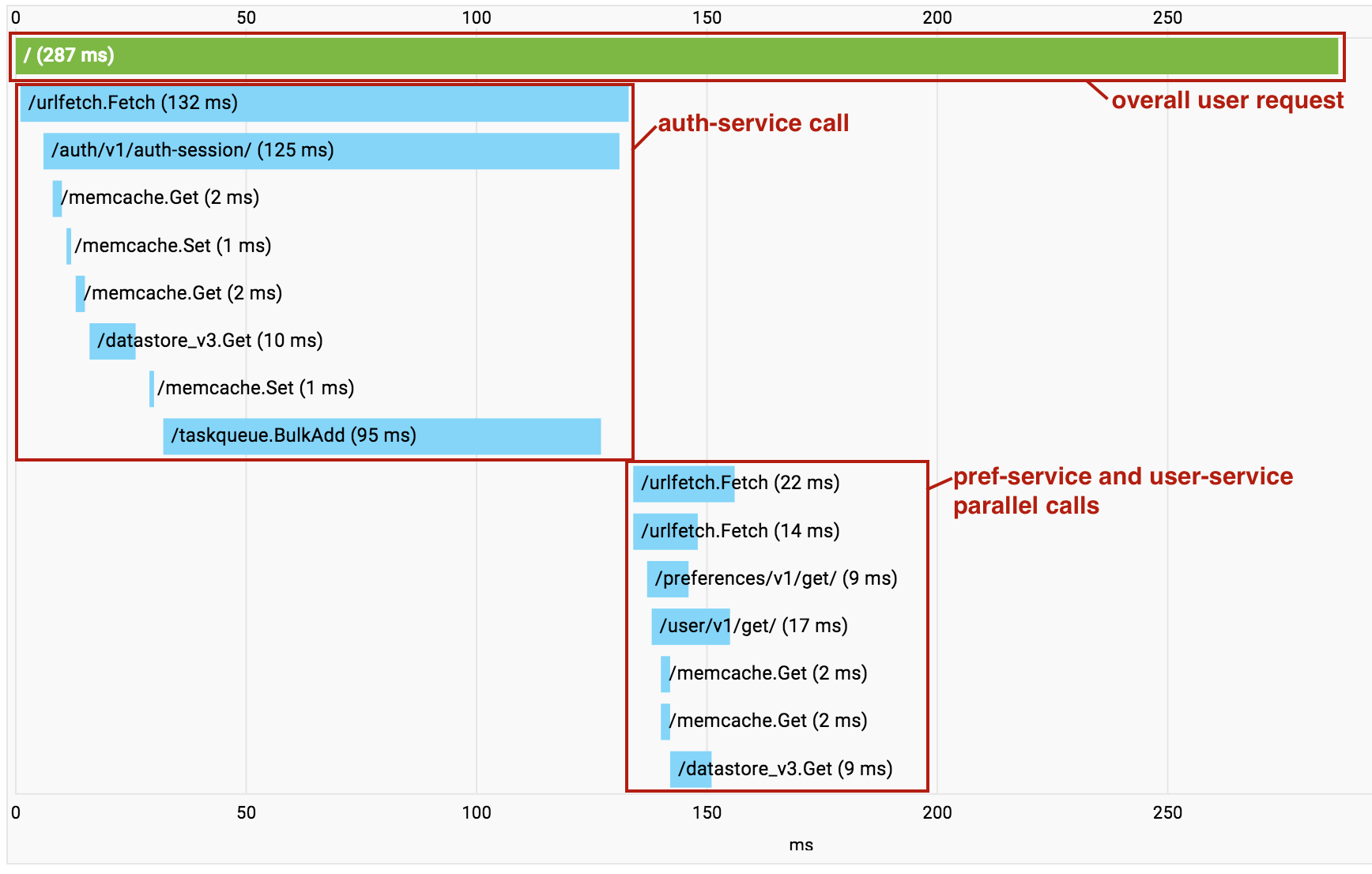
Perhatikan bahwa dalam contoh di atas, panggilan ke pref-service dan user-service dilakukan secara paralel menggunakan Urlfetch asinkron, sehingga RPC tampak acak dalam visualisasi.
Namun, hal ini masih merupakan alat yang berharga untuk mendiagnosis latensi.
Langkah selanjutnya
- Dapatkan ringkasan arsitektur microservice di App Engine.
- Pahami cara membuat dan menamai lingkungan pengembangan, pengujian, uji mutu, staging, dan produksi dengan microservice di App Engine.
- Pelajari praktik terbaik dalam mendesain API untuk berkomunikasi antara microservice.
- Pelajari cara Memigrasikan aplikasi monolitik yang ada ke aplikasi yang memiliki microservice.